

принцип кодирования по Хаффману
.doc
ФЕДЕРАЛЬНОЕ ГОСУДАРСТВЕННОЕ ОБРАЗОВАТЕЛЬНОЕ
УЧРЕЖДЕНИЕ ВЫСШЕГО ПРОФЕССИОНАЛЬНОГО ОБРАЗОВАНИЯ
НАЦИОНАЛЬНЫЙ ИССЛЕДОВАТЕЛЬСКИЙ ТЕХНОЛОГИЧЕСКИЙ УНИВЕРСИТЕТ
«МИСиС»
Институт ИТАСУ
Кафедра АСУ
Лабораторная работа №3
«Принцип кодирования Д.Хаффмана»
Выполнила:
Студентка группы МИТ-14-2
Николаева Галина
Проверил:
Доцент, к.т.н.
Гончаренко А.Н.
Москва, 2016 г.
Сжатие данных производится в два этапа. На первом этапе считываются данные, которые должны подвергнуться сжатию; на втором определяется частота встречаемости отдельных байтов данных, которые могут принимать значения от 0 до 255.
Пусть требуется закодировать строку с именем, отчеством, фамилией, датой местом рождения.
Николаева Галина Леонидовна,10 октября 1996 года,город Чебоксары
|
Таблица 1 «Частота символов»
|
Таблица 2 «Частота повторяемости символов»
|
Построим таблицу частоты повторяемости символов, деля число повторений символа на длину сообщения (64) – таблицы 1,2.
Произведем ряд последовательных преобразований исходной таблицы, складывая строки с наименьшей частотой и проводя их сортировку по убыванию (таблицы 3-11):
Таблица 3 «Шаг 1» Таблица 4 «Шаг 2»
|
1 |
0.125 |
|
2 |
0.109375 |
|
3 |
0.09375 |
|
4 |
0.0625 |
|
12,13 |
0.0625 |
|
14,15 |
0.0625 |
|
16,17 |
0.0625 |
|
18,19,20,21 |
0.0625 |
|
5 |
0.046875 |
|
6 |
0.046875 |
|
7 |
0.046875 |
|
8 |
0.046875 |
|
9 |
0.046875 |
|
10 |
0.046875 |
|
11 |
0.046875 |
|
22,23 |
0.03125 |
|
1 |
0.125 |
|
2 |
0.109375 |
|
3 |
0.09375 |
|
4 |
0.0625 |
|
5 |
0.046875 |
|
6 |
0.046875 |
|
7 |
0.046875 |
|
8 |
0.046875 |
|
9 |
0.046875 |
|
10 |
0.046875 |
|
11 |
0.046875 |
|
12 |
0.03125 |
|
13 |
0.03125 |
|
14 |
0.03125 |
|
15 |
0.03125 |
|
16 |
0.03125 |
|
17 |
0.03125 |
|
18,19 |
0.03125 |
|
20,21 |
0.03125 |
|
22,23 |
0.03125 |
Таблица 5 «Шаг 3»
Таблица 6 «Шаг 4»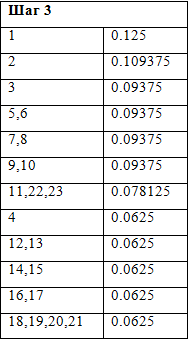

Таблица 6 «Шаг 5»
Таблица 8 «Шаг 6»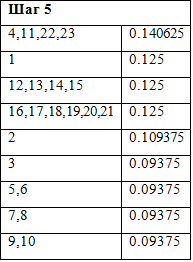
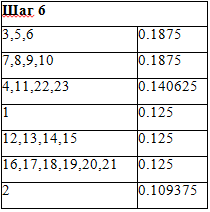
Таблица 9 «Шаг 7»

Таблица 10 «Шаг 8»

Таблица 11 «Шаг 9»

Теперь, пользуясь таблицами в обратной последовательности, построим дерево кодирования (рис.1). Из вершины начинаются две ветви, соответствующие значениям вероятности появления в сообщении данной группы символов.
Ветви помечаются значениями 0 (левая, с меньшим значением слагаемого вероятности) и 1 (правая, с большим). Дерево закончится каждым символом алфавита сообщения, а значения, приписанные ветвям дерева на пути от вершины к данному символу, образуют двоичный код данного символа.
|
|
|
Таблица
12 «Кодирование символов»
№ п/п
Символ Двоичный
код
1
О 100
2
А 000
3
Пробел 1111
4
Н 001
5
И 00011
6
К 10011
7
Л 01011
8
Е 11011
9
Г 00111
10
Д 10111
11
Р 1101
12
В 01010
13
Б 11010
14
Я 00110
15
1 10110
16
9 01110
17
,
(запятая) 11110
18
Ч 000010
19
С 100010
20
Т 010010
21
Ы 110010
22
0 00101
23
6
10101 |
Подсчитаем полученную степень сжатия, умножая длину кода на сумму символов, кодируемых кодом данной длины:
3(8+7+4) + 4(6+3) +5(3+3+3+3+3+3+3+2+2+2+2+2+2+2) + 6(1+1+1+1+1+1) = 279 бит (34.875 байт)
Таким образом, имеем коэффициент сжатия К1=64/35=1,8
Набираем эту же строку в редакторе «Блокнот» и сохраняем текст в txt-формате. Количество байт в файле точно соответствует числу знаков.
Применяем к файлу архиватор. Степень сжатия – 143 байта. Таким образом, имеем коэффициент сжатия К2=64/143=0,448.
К1>К2, следовательно, алгоритм Хаффмана эффективнее сжимает файл.