

3 курс / 2 семестр / Методы изучения экологии животных и растений / Коэффициент сходства
.docxКоэффициент сходства (также мера сходства, индекс сходства) — безразмерный показатель, применяемый в биологии для количественного определения степени сходства биологических объектов. Также известен под названиями «мера ассоциации», «мера подобия» и др.
В более широком смысле говорят о мерах близости к которым относятся: меры разнообразия, меры концентрации (однородности), меры включения, меры сходства, меры различия (в том числе расстояния), меры совместимости событий, меры несовместимости событий, меры взаимозависимости, меры взаимонезависимости. Теория мер близости находится в стадии становления и потому существует множество различных представлений о формализации отношений близости.
Меры близости широко применяются в биологии, где наиболее часто сравниваются участки (районы, отдельные фитоценозы, зооценозы и т. п.). Также применяются в географии, социологии, распознавании образов, поисковых системах, сравнительной лингвистике, биоинформатике, хемоинформатике и др.
Большинство коэффициентов нормированы и находятся в диапазоне от 0 (сходство отстутствует) до 1 (полное сходство). Сходство и различие взаимодополняют друг друга (математически это можно выразить так: Сходство = 1 − Различие).
Коэффициенты сходства можно условно разделить на три группы в зависимости от того, какое число объектов рассматривается:
-
унарные — рассматривается один объект. В эту группу входят меры разнообразия, меры концентрации.
-
бинарные — рассматривается два объекта. Это наиболее известная группа коэффициентов.
-
n-арные (многоместные) — рассматривается n объектов. Эта группа наименее известна.
Унарные коэффициенты
При изучении биологических объектов широко используются меры изменчивости, как отдельных признаков, так и частот распределения случайных величин. В простейшем случае инвентаризационное (в пределах изучаемой биосистемы) разнообразие можно оценить видовым богатством, или числом видов.
Наиболее часто используются меры разнообразия[1] (коэффициент вариации, индексы параметрического семейства Реньи, включая индекс Шеннона; индексы семейства Хилла; индексы Маргалефа, Глизона и др.). Реже используются дополняющие их меры концентрации (например, семейство мер Колмогорова, мера диссонанса Розенберга).
Бинарные коэффициенты
Это
наиболее используемые в биологии и
географии коэффициенты[2].
Самый первый
коэффициент сходства
был предложен П.
Жаккаром
(Jaccard)
в 1901 г.[3] :
![]() ,
где а —
количество видов на первой пробной
площадке, b —
количество видов на второй пробной
площадке, с —
количество видов, общих для 1-й и 2-й
площадок. Впоследствии в самых различных
областях науки предлагались различные
коэффициенты (меры, индексы) сходства.
Наибольшее распространение получили
(обозначения те же):
,
где а —
количество видов на первой пробной
площадке, b —
количество видов на второй пробной
площадке, с —
количество видов, общих для 1-й и 2-й
площадок. Впоследствии в самых различных
областях науки предлагались различные
коэффициенты (меры, индексы) сходства.
Наибольшее распространение получили
(обозначения те же):
-
коэффициент Серенсена (Sörensen)[4] :
 ;
; -
коэффициент Кульчинского (Kulczinsky)[5] :
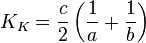 ;
; -
коэффициент Отиаи (Ochiai)[6]:
 ;
; -
коэффициент Шимкевича-Симпсона (Szymkiewicz[7], Simpson)[8]:
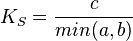 ;
; -
коэффициент Браун-Бланке (Braun-Blanquet)[9]:
 ;
;
Известна
альтернативная система обозначений
для таблицы сопряжённости
![]() от
Р. Р. Сокала (Sokal)
и П.Снита (Sneath)[10][11]:
от
Р. Р. Сокала (Sokal)
и П.Снита (Sneath)[10][11]:
|
|
Присутствие вида на 1-м участке |
Отсутствие вида на 1-м участке |
|
Присутствие вида на 2-м участке |
a |
b |
|
Отсутствие вида на 2-м участке |
c |
d |
где
а —
количество видов, встречаемых на обеих
площадках; b —
количество видов встреченных на первой
пробной площадке, но без учёта встречаемости
общих видов; с —
количество видов встреченных на второй
пробной площадке, но без учёта встречаемости
общих видов. Эта таблица создает большую
путаницу. Её часто путают с похожей
статистической таблицей сопряженности
![]() ;
обозначения таблицы Сокала-Снита путают
с классическими обозначениями (см.
выше); почти всегда не учитывают того
факта, что таблица рассматривает только
вероятности.
В процессе математической
формализации объектов и связей между
ними возникла универсальная
теоретико-множественная запись для
коэффициентов сходства. Впервые такого
рода запись появляется в работах
А. С. Константинова[12],
М. Левандовского и Д. Винтер[13].
Так коэффициент сходства Жаккара может
быть записан следующим образом:
;
обозначения таблицы Сокала-Снита путают
с классическими обозначениями (см.
выше); почти всегда не учитывают того
факта, что таблица рассматривает только
вероятности.
В процессе математической
формализации объектов и связей между
ними возникла универсальная
теоретико-множественная запись для
коэффициентов сходства. Впервые такого
рода запись появляется в работах
А. С. Константинова[12],
М. Левандовского и Д. Винтер[13].
Так коэффициент сходства Жаккара может
быть записан следующим образом:
![]() или
или
![]() .
.
Наиболее
простым коэффициентом сходства является
мера абсолютного сходства, которая по
сути является числом общих признаков
двух сравнимаемых объектов:
![]() [14].
При нормировке этой меры значения меры
сходства заключены между 0 и 1 и коэффициент
известен как «мера процентного сходства»
при использовании относительных единиц
измерения (в процентах) и как меры
пересечения в промежуточных расчетах
относительных мер сходства[15].
[14].
При нормировке этой меры значения меры
сходства заключены между 0 и 1 и коэффициент
известен как «мера процентного сходства»
при использовании относительных единиц
измерения (в процентах) и как меры
пересечения в промежуточных расчетах
относительных мер сходства[15].
В 1973 году Б. И. Сёмкиным была предложена общая формула на основе формулы среднего Колмогорова, объединяющая большую часть известных коэффициентов сходства в непрерывный континуум мер[16][17]:
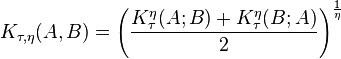 ,
,
где
![]() ;
;
![]() ;
;
![]() ;
;
![]() ;
;
![]() ;
;
![]() .
Например, значения
.
Например, значения
![]() для
вышеприведённых коэффициентов имеют
следующий вид: [1,-1] (коэффициент Жаккара);
[0,-1] (коэффициент Серенсена); [0,1]
(коэффициент Кульчинского); [0,0] (коэффициент
Отиаи); [0,
для
вышеприведённых коэффициентов имеют
следующий вид: [1,-1] (коэффициент Жаккара);
[0,-1] (коэффициент Серенсена); [0,1]
(коэффициент Кульчинского); [0,0] (коэффициент
Отиаи); [0,
![]() ]
(коэффициент Шимкевича-Симпсона); [0,
]
(коэффициент Шимкевича-Симпсона); [0,![]() ] (коэффициент Браун-Бланке). Обобщающая
формула позволяет определить классы
эквивалентных и неэквивалентных
коэффициентов[18],
а также предотвратить создание новых
дублирующих коэффициентов.
] (коэффициент Браун-Бланке). Обобщающая
формула позволяет определить классы
эквивалентных и неэквивалентных
коэффициентов[18],
а также предотвратить создание новых
дублирующих коэффициентов.
Основная статья: Мера включения
Специфическим
типом коэффициентов сходства являются
меры
включения.
Это несимметричные меры (![]() и
и
![]() ),
которые показывают степень сходства
(включение) одного объекта относительно
другого. Более привычные (симметричные)
коэффициенты близости можно получить
путём осреднения двух взаимодополняющих
несимметричных мер включения, то есть
каждой симметричной мере сходства
соответствуют две определённые
несимметричные меры сходства. Например,
для меры
Сёренсена
это
),
которые показывают степень сходства
(включение) одного объекта относительно
другого. Более привычные (симметричные)
коэффициенты близости можно получить
путём осреднения двух взаимодополняющих
несимметричных мер включения, то есть
каждой симметричной мере сходства
соответствуют две определённые
несимметричные меры сходства. Например,
для меры
Сёренсена
это
![]() и
и
![]() ),
а для меры
Жаккара
это
),
а для меры
Жаккара
это
![]() и
и
![]() .
В общем, две несимметричные меры включения
лучше оценивают сходство объектов чем
одна осреднённая симметричная мера
сходства.
.
В общем, две несимметричные меры включения
лучше оценивают сходство объектов чем
одна осреднённая симметричная мера
сходства.
Спорным и неоднозначным является вопрос о сравнении объектов по весовым показателям. В экологии это показатели учитывающие обилие. Наиболее последовательными схемами формализации таких типов являются: схема Б. И. Сёмкина на основе дескриптивных множеств и схема А.Чао (Chao) с основанными на обилии индексами (abundance-based indices)[19]. Также в зарубежной литературе устоялось представление индексах на основе инцидентности (incidence-based index), то есть индексах для булевых данных типа присутствие/отсутствие (presence/absence) признака. По сути, и те и другие могут быть описаны как частные случаи дескриптивных множеств.
Дискуссионными остаются: сравнение случайных событий (например, встречаемость) и информационных показателей. В схеме формализации отношений близости Б. И. Сёмкина предлагается выделять ряд аналитических интерпретаций для различных отношений близости: множественная, дескриптивная, вероятностная, информационная. Формально принадлежность к мерам сходства определяется системой аксиом (здесь E — произвольное множество):
-
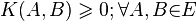 (неотрицательность);
(неотрицательность); -
 (симметричность);
(симметричность); -
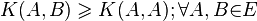 («целое
больше части»);
(«целое
больше части»); -
 (субаддитивность).
(субаддитивность).
Системы аксиом для мер сходства предлагали: А. Реньи[20], Ю. А. Воронин[21][22], А.Тверски[23], А. А. Викентьев, Г. С. Лбов[24], Г. В. Раушенбах[25], Б. И. Сёмкин[26][27] и др.
Основная статья: Матрица мер конвергенции
Как правило, совокупность мер близости представляют в виде матриц типа «объект-объект». Это, например, матрицы сходства, матрицы расстояний (в широком смысле — различия), матрицы совместных вероятностей, матрицы информационных функций. Большинство из них могут быть построены на основе: абсолютных или относительных мер, а они в свою очередь могут быть симметричными или несимметричными (последние часто называются мерами включения).
Многоместные коэффициенты
Такого рода коэффициенты используются для сравнения серии объектов. К ним относятся: среднее сходство Алёхина, индекс биотической дисперсии Коха, коэффициент рассеяния (дисперсности) Шенникова, мера бета-разнообразия Уиттекера, мера гомотонности и двойственная ей мера гетеротонности Миркина-Розенберга, коэффициент сходства серии описаний Сёмкина. В зарубежной литературе меры этого типа встречаются под названиями: многомерные коэффициенты, n-мерные коэфициенты, multiple-site similarity measure, multidimensional coefficient, multiple-community measure[28].[29][30]. Наиболее известный коэффициент был предложен Л.Кохом[31]:
![]() ,
,
где
![]() ,
то есть сумма числа признаков каждого
из объектов;,
,
то есть сумма числа признаков каждого
из объектов;,
![]()
то есть общее число признаков;
![]() — совокупность
n
множеств (объектов).
— совокупность
n
множеств (объектов).