

Тимофеев 2018 / ОС 5 лаб
.docxМИНОБРНАУКИ РОССИИ
Санкт-Петербургский государственный
электротехнический университет
«ЛЭТИ» им. В.И. Ульянова (Ленина)
Кафедра вычислительной техники
отчет
по лабораторной работе №5
по дисциплине «Операционные системы»
Тема: «ПРОЦЕССЫ И ПОТОКИ»
|
Студент гр. 6307 |
|
Лазарев С. О. |
|
Преподаватель |
|
Тимофеев А. В. |
Санкт-Петербург
2018
Цель работы: исследовать структуры данных процессов и потоков
Задание 5.3. Реализация многопоточного приложения с использованием функций Win32 API
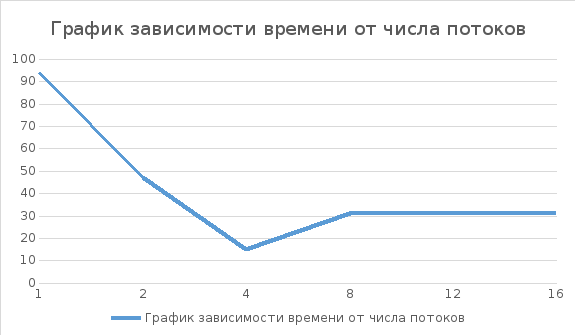
Запустим 6 потоков и приостановим выполнение программы в процессе подсчета числа пи:
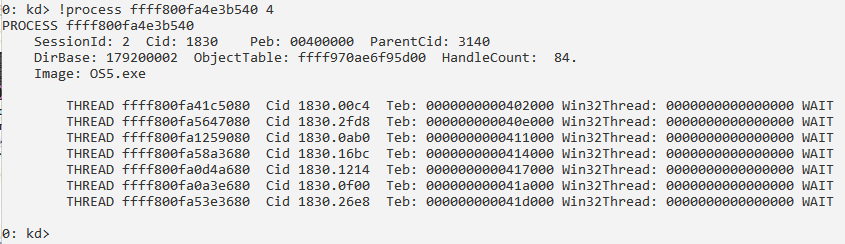
Потоки процесса.
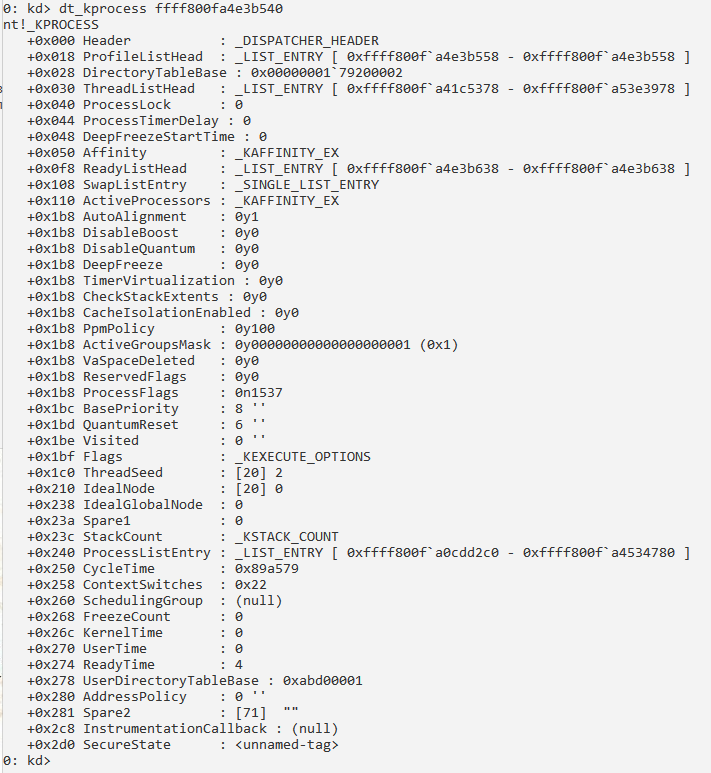
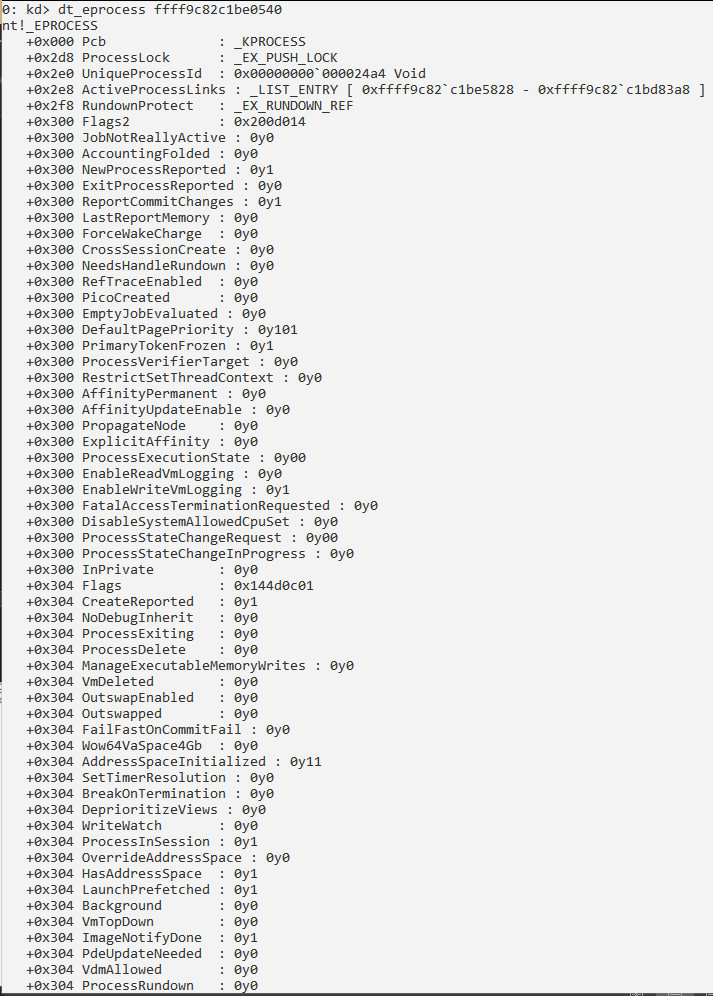
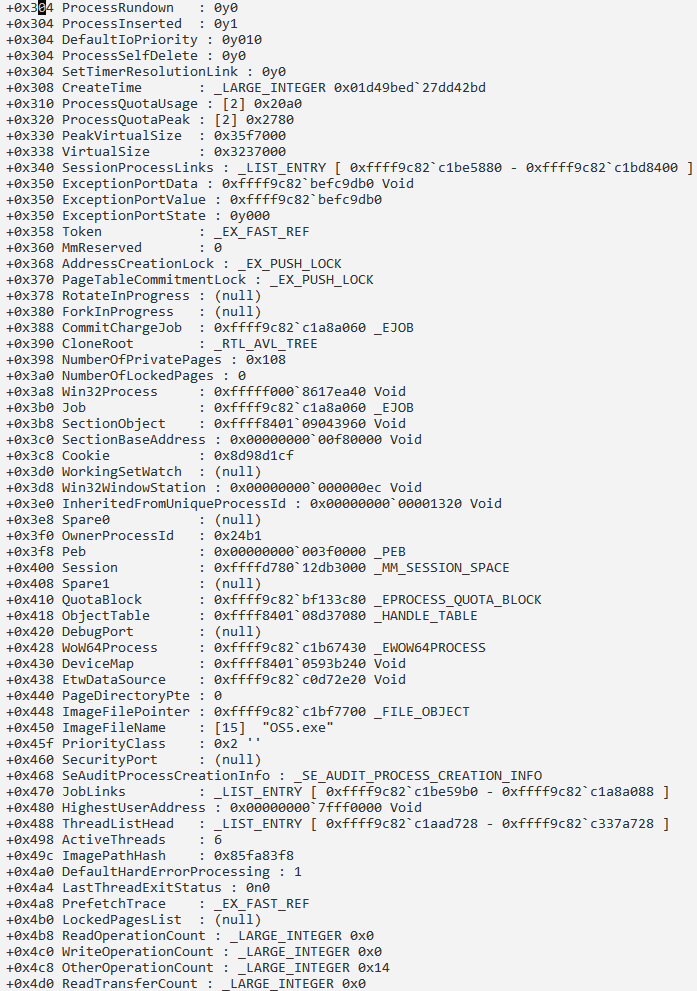
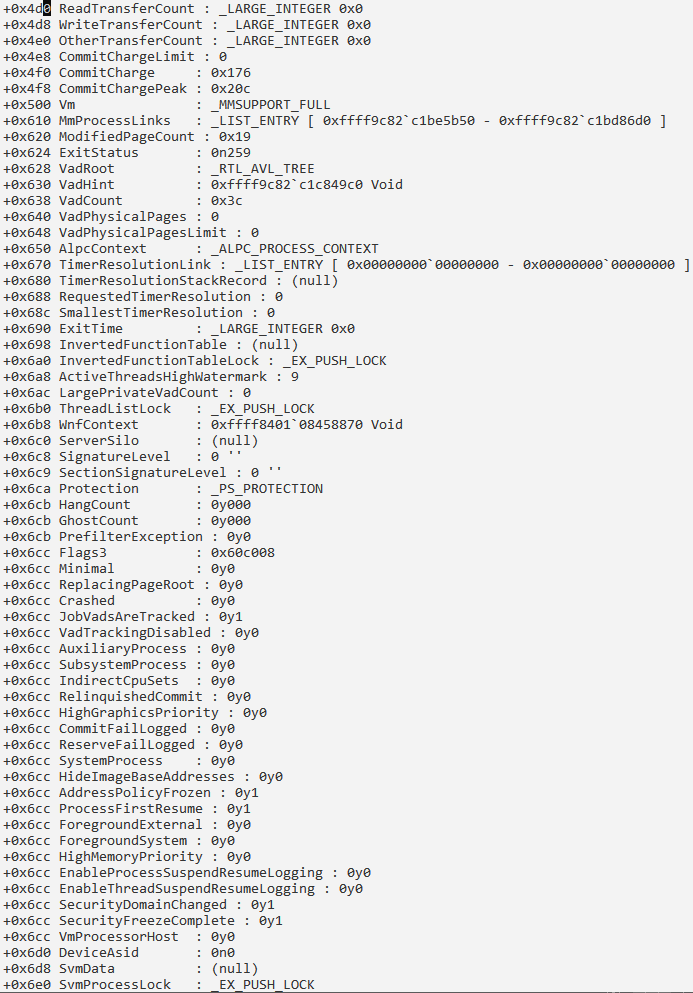
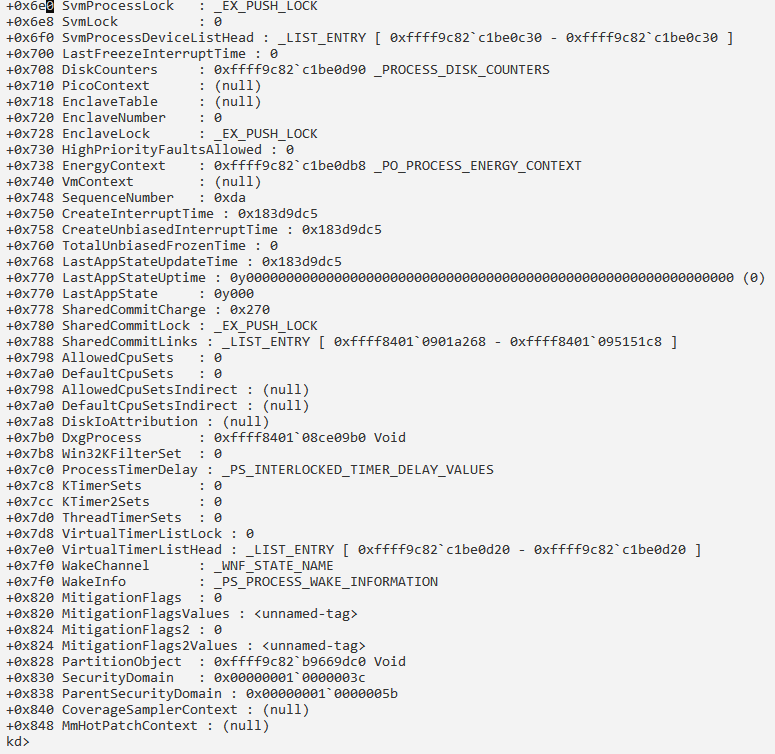
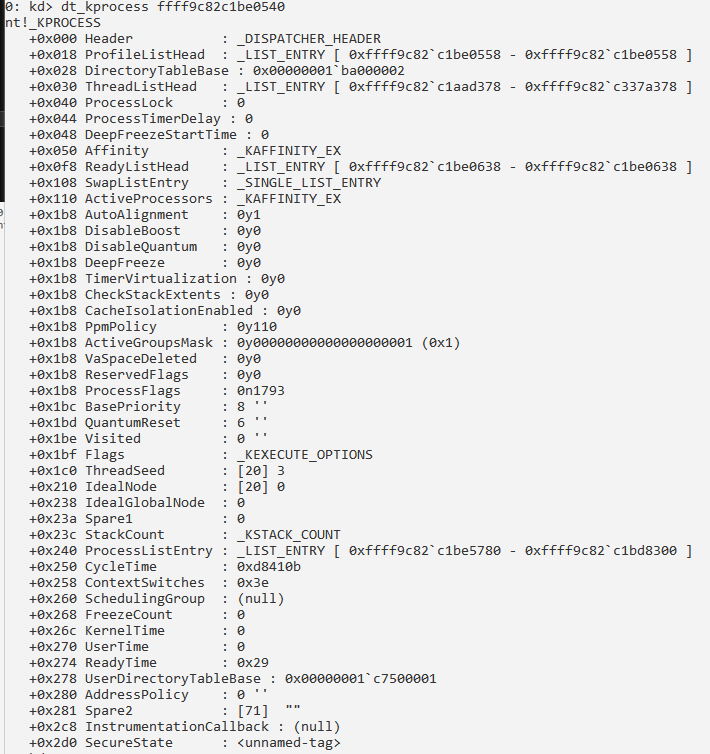
Сведения о процессе и его потоках:
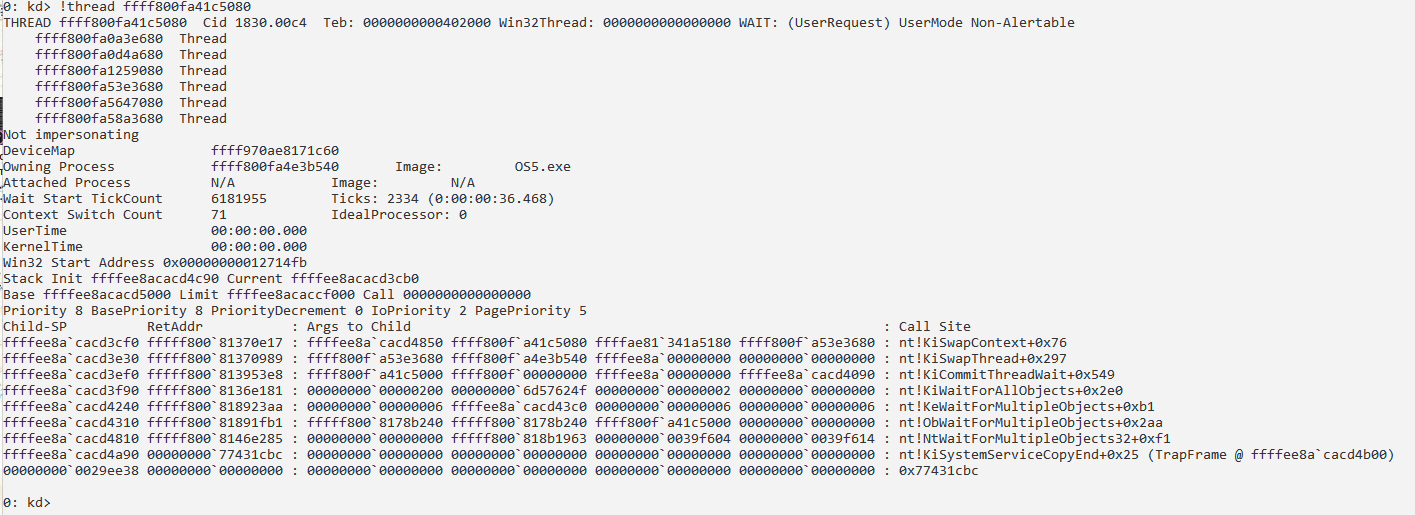
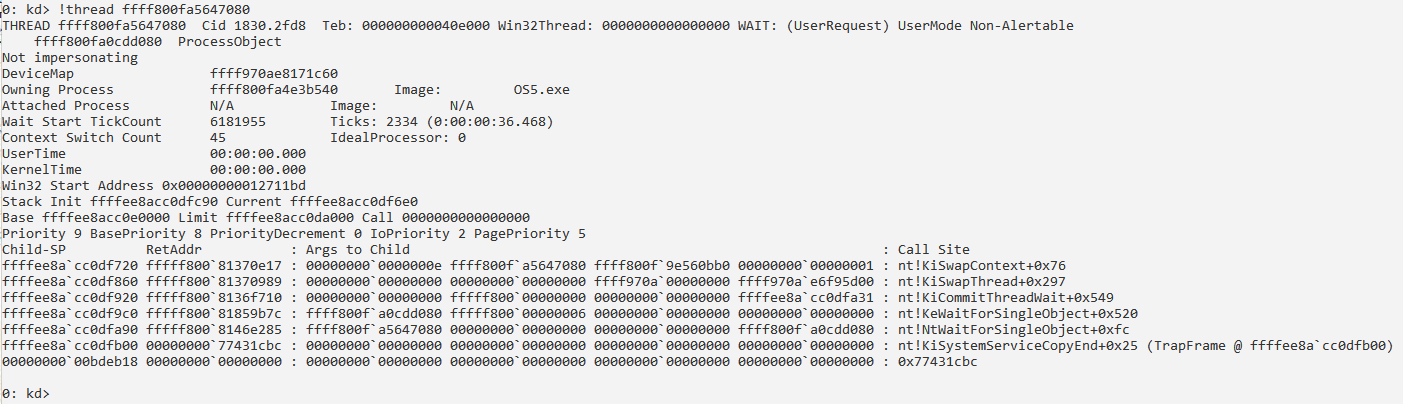
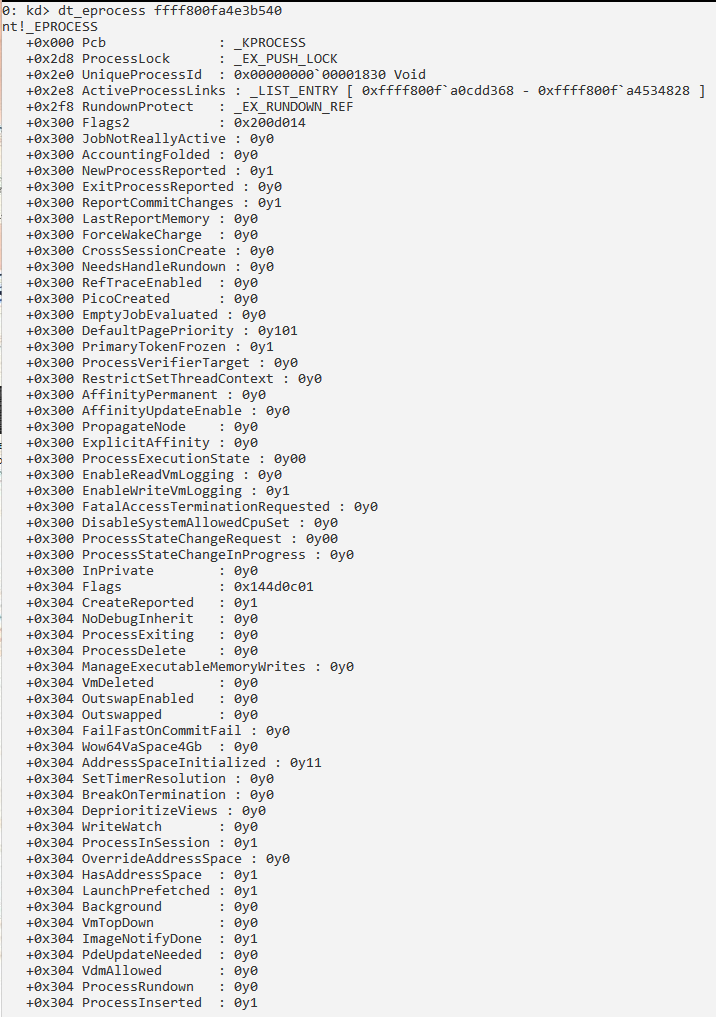
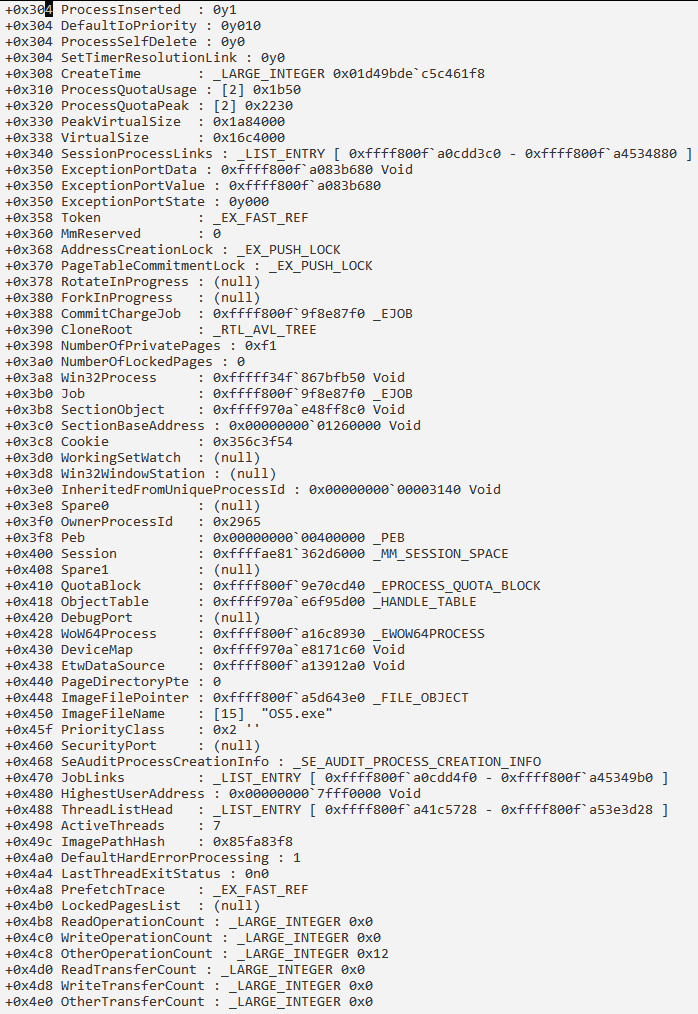
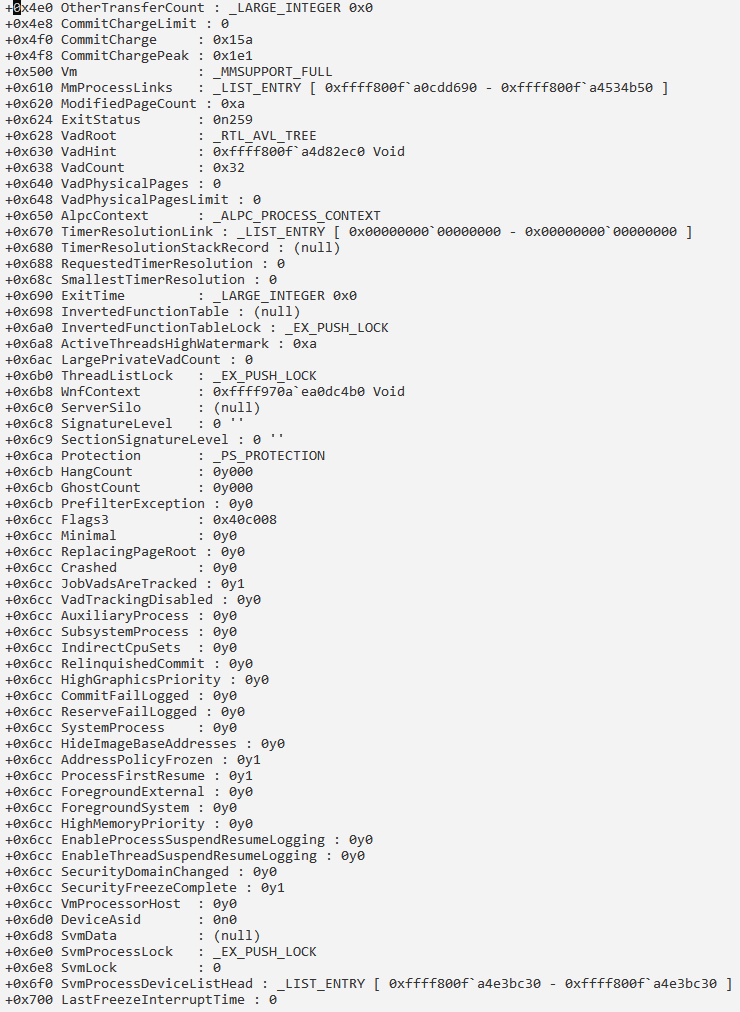
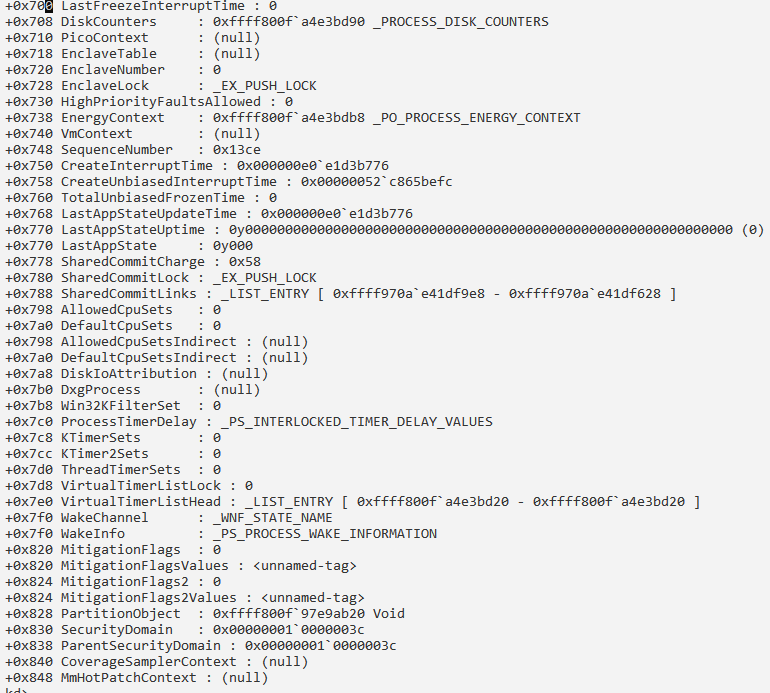
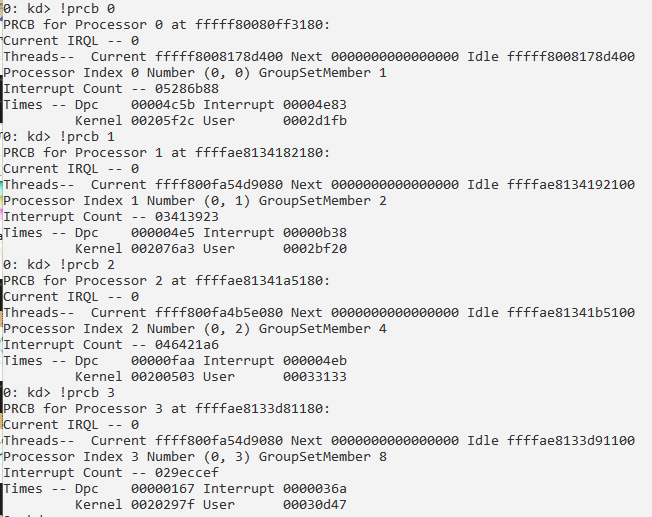
Получение информации о структуре PRCB:
Первого процессора по адресу fffff80080ff3180:
![]()
![]()
Второго процессора по адресу ffffae8134182180
![]()
![]()
Третьего процессора по адресу ffffae81341a5180
![]()
![]()
Четвертого процессора по адресу ffffae8133d81180
![]()
![]()
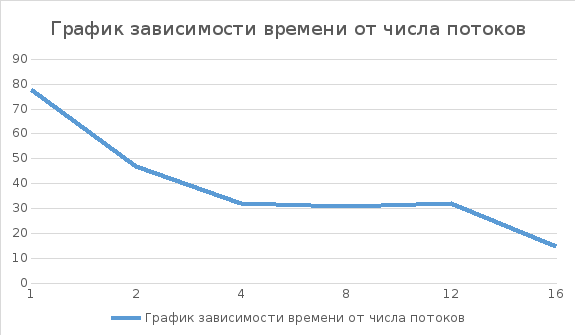
Вывод: Использование нескольких потоков позволяет существенно увеличить быстродействие программы.
Задание 5.4. Реализация многопоточного приложения с использованием технологии OpenMP
Запустим 6 потоков и приостановим выполнение программы в процессе подсчета числа пи:
Потоки процесса.
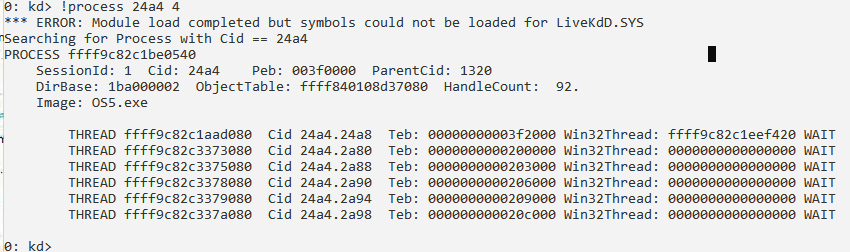
Сведения о процессе и его потоках:
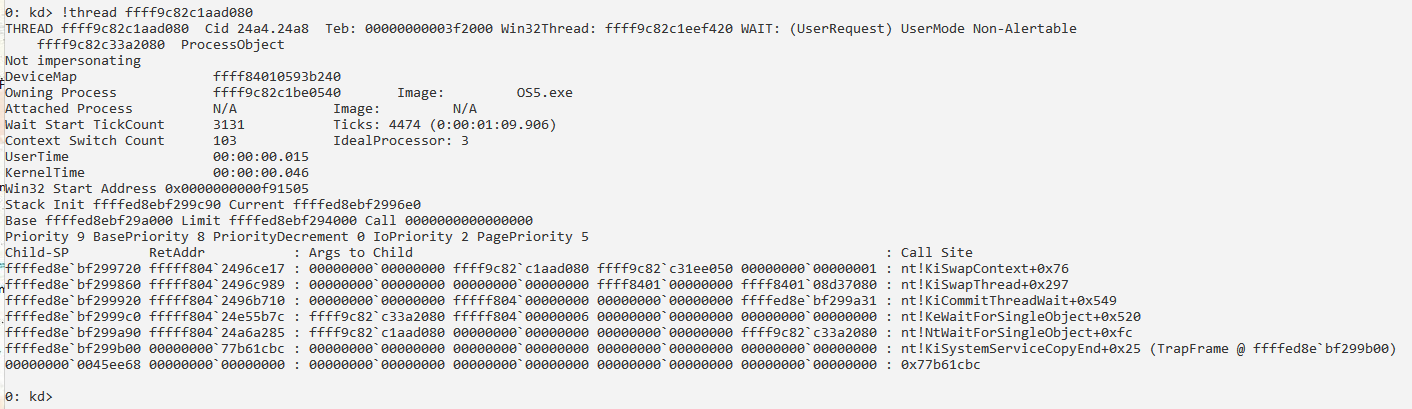
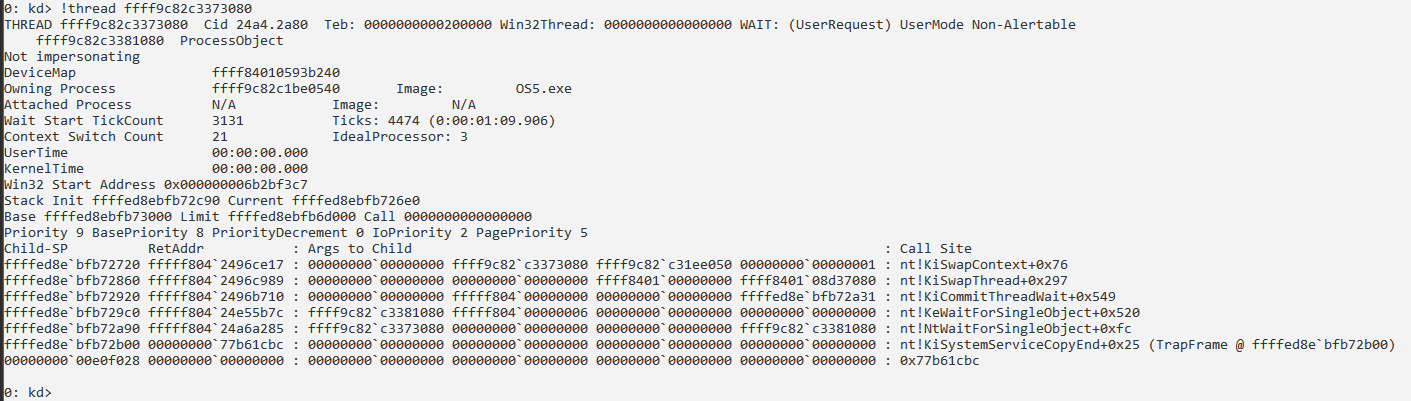

Получение информации о структуре PRCB
Первого процессора по адресу fffff804245d0180:
![]()
![]()
Второго процессора по адресу ffffd78012786180
![]()
![]()
Третьего процессора по адресу ffffd780127a9180
![]()
![]()
Четвертого процессора по адресу ffffd78012385180
![]()
![]()
Вывод: Использование OpenMp позволяет использовать преимущество многопоточности, минуя сложность её программной реализации и экономя время программисту
#include <iostream>
#include <iomanip>
#include <windows.h>
#include <string>
#include <omp.h>
// openmp в визуалке подрубите, кто будет списывать(в свойствах проекта -> Язык)
using namespace std;
void menu();
void mWinAPI();
DWORD WINAPI lpStartAddress(LPVOID);
double mOpenMp();
double calculating(long);
const long N = 10000000;
const long BLOCK_SIZE = 10000;
DWORD tlsIndex;
CRITICAL_SECTION CriticalSection;
double totalPi = 0;
DWORD qThreads = 0;
HANDLE* threadArray;
void main()
{
while (true)
menu();
}
void mWinAPI()
{
cout << "\nNumber threads: ";
cin >> qThreads;
threadArray = new HANDLE[qThreads];
DWORD *lpThreadId = new DWORD[qThreads];
tlsIndex = TlsAlloc();
InitializeCriticalSection(&CriticalSection);
for (int i = 0; i < qThreads; ++i)
threadArray[i] = CreateThread(nullptr, 0, lpStartAddress, new long{ i * BLOCK_SIZE }, CREATE_SUSPENDED, lpThreadId + i);
unsigned int start = GetTickCount();
for (int i = 0; i < qThreads; ++i)
ResumeThread(threadArray[i]);
WaitForMultipleObjects(qThreads, threadArray, TRUE, INFINITE);
unsigned int end = GetTickCount();
cout << "\n\tpi: "
<< setprecision(10)
<< totalPi;
cout << "\n\tTime: " << end-start << "ms\n";
DeleteCriticalSection(&CriticalSection);
for (int i = 0; i < qThreads; ++i)
CloseHandle(threadArray[i]);
delete[] threadArray;
threadArray = nullptr;
totalPi = 0;
TlsFree(tlsIndex);
}
DWORD WINAPI lpStartAddress(LPVOID lpParameter)
{
long InitProgress = *(reinterpret_cast<long*>(lpParameter));
long Progress = InitProgress;
double tlPi = 0;
TlsSetValue(tlsIndex, (LPVOID)&tlPi);
bool end = false;
for (int i = 1; !end; ++i)
{
tlPi = calculating(Progress);
TlsSetValue(tlsIndex, (LPVOID)&tlPi);
EnterCriticalSection(&CriticalSection);
{
totalPi += tlPi;
Progress = qThreads * BLOCK_SIZE * i + InitProgress;
if (Progress >= N)
end = true;
}
LeaveCriticalSection(&CriticalSection);
}
return 0;
}
double calculating(long NumberOf)
{
double xi = 0;
double pi = 0;
for (long i = NumberOf; i < NumberOf + BLOCK_SIZE && i < N; ++i)
{
xi = (i + 0.5)*(1.0 / N);
pi += ((4.0 / (1.0 + xi * xi)) * (1.0 / N));
}
return pi;
}
double mOpenMp()
{
cout << "\nNumber threads: ";
cin >> qThreads;
double pi = 0;
unsigned int start = GetTickCount();
#pragma omp parallel for schedule(dynamic, BLOCK_SIZE) num_threads(qThreads) reduction(+: pi)
for (int i = 0; i < N; ++i)
{
double xi = (i + 0.5)*(1.0 / N);
pi += ((4.0 / (1.0 + xi * xi)) * (1.0 / N));
}
unsigned int end = GetTickCount();
cout << "\n\tpi: "
<< setprecision(10)
<< pi;
cout << "\n\tTime: " << end-start << "ms\n";
return pi;
}
void menu()
{
cout << "\n\t1. WinAPI"
<< "\n\t2. OpenMp"
<< "\n\t3. Exit\n";
int c;
cin >> c;
switch (c)
{
case 1:
mWinAPI();
break;
case 2:
mOpenMp();
break;
case 3:
return;
}
}