

Лабы / Методы анализа данных Лаб2
.docxМИНИСТЕРСТВО ОБРАЗОВАНИЯ И НАУКИ РОССИЙСКОЙ ФЕДЕРАЦИИ
ФЕДЕРАЛЬНОЕ ГОСУДАРСТВЕННОЕ БЮДЖЕТНОЕ ОБРАЗОВАТЕЛЬНОЕ УЧРЕЖДЕНИЕ ВЫСШЕГО ОБРАЗОВАНИЯ
«НОВОСИБИРСКИЙ ГОСУДАРСТВЕННЫЙ ТЕХНИЧЕСКИЙ УНИВЕРСИТЕТ»
ФАКУЛЬТЕТ АВТОМАТИКИ И ВЫЧИСЛИТЕЛЬНОЙ ТЕХНИКИ
КАФЕДРА АВТОМАТИЗИРОВАННЫХ СИСТЕМ УПРАВЛЕНИЯ
Отчет по лабораторной работе №2
по дисциплине «Методы анализа данных»
на тему «Поиск ассоциативных правил в среде Deductor»
Выполнили студенты группы АВТ-412:
Лазаревич М.М.
Евтушенко Н.С.
Проверила доцент кафедры АСУ:
Ганелина Н. Д.
г. Новосибирск, 2017
Цель работы:
Изучить процесс построения ассоциативных правил в программе Deductor.
Постановка задачи:
Провести поиск ассоциативных правил, проверить влияние параметров (поддержка, достоверность) на формирование правил.
Описание алгоритма:
Основным алгоритмом, который применяется
для получения ассоциативных правил,
является алгоритм apriori. Его автором
является Ракеш Агравал.
Алгоритм
Apriori предназначен для поиска всех частых
множеств признаков. Он является
поуровневым, использует стратегию
поиска в ширину и осуществляет его
снизу-вверх.
Алгоритм перебора
следующий:

 Основная
особенность алгоритма — свойство
антимонотонности.
Apriori использует
одно из свойств поддержки, гласящее:
поддержка любого набора элементов не
может превышать минимальной поддержки
любого из его подмножеств. Например,
поддержка 3-элементного набора {Хлеб,
Масло, Молоко} будет всегда меньше или
равна поддержке 2-элементных наборов
{Хлеб, Масло}, {Хлеб, Молоко}, {Масло,
Молоко}. Дело в том, что любая транзакция,
содержащая {Хлеб, Масло, Молоко}, также
должна содержать {Хлеб, Масло}, {Хлеб,
Молоко}, {Масло, Молоко}, причем обратное
не верно.
Благодаря этому свойству
перебор не является «жадным» и позволяет
обрабатывать большие массивы информации
за секунды.
Классический алгоритм
apriori уже был несколько раз модифицирован,
работы по улучшению скорости ведутся
и сейчас.
Основная
особенность алгоритма — свойство
антимонотонности.
Apriori использует
одно из свойств поддержки, гласящее:
поддержка любого набора элементов не
может превышать минимальной поддержки
любого из его подмножеств. Например,
поддержка 3-элементного набора {Хлеб,
Масло, Молоко} будет всегда меньше или
равна поддержке 2-элементных наборов
{Хлеб, Масло}, {Хлеб, Молоко}, {Масло,
Молоко}. Дело в том, что любая транзакция,
содержащая {Хлеб, Масло, Молоко}, также
должна содержать {Хлеб, Масло}, {Хлеб,
Молоко}, {Масло, Молоко}, причем обратное
не верно.
Благодаря этому свойству
перебор не является «жадным» и позволяет
обрабатывать большие массивы информации
за секунды.
Классический алгоритм
apriori уже был несколько раз модифицирован,
работы по улучшению скорости ведутся
и сейчас.
Процедура применения метода:
Данный алгоритм был применён к массиву данных чеков из демонстрационного примера программы Deductor studio. Данный массив содержит 5000 записей вида Id Item, где Id – идентификатор чека, Item – наименование товара.
Применим алгоритм со следующими параметрами: поддержка 1-20, достоверность 25-40.
В результате получается 46 правил. Правила характеризуются следующими показателями:
Условие – основной набор товаров, вместе с которым с определённой частотой(достоверность) покупается другой набор товаров – следствие.
Поддержка – доля чеков, включающих в себя условие и следствие данного правила.
Лифт – отношение поддержки полного набора(условие и следствие) к произведению отдельных поддержек условия и следствия когда они встречаются отдельно друг от друга, достаточно важный показатель, позволяющий оценить полезность правила, если следствие встречается вне набора так же часто, как и в наборе, значит зависимость между условием и следствием скорее всего отсутствует, в таком случае лифт будет иметь значение 1, чем больше единицы значения лифта, тем существеннее связь между предметами, для ситуаций, когда лифт меньше нуля связь между предметами приобретает обратный характер, то есть для A->B можно сказать, что при lift(A->B)<1 товары B скорее всего не будут куплены вместе с товарами A.
Среди полученных результатов достаточно много неочевидных правил с большим значениям лифта, что свидетельствует о преобладании обоих совокупностей товаров вместе над их сочетаниями с другими товарами.
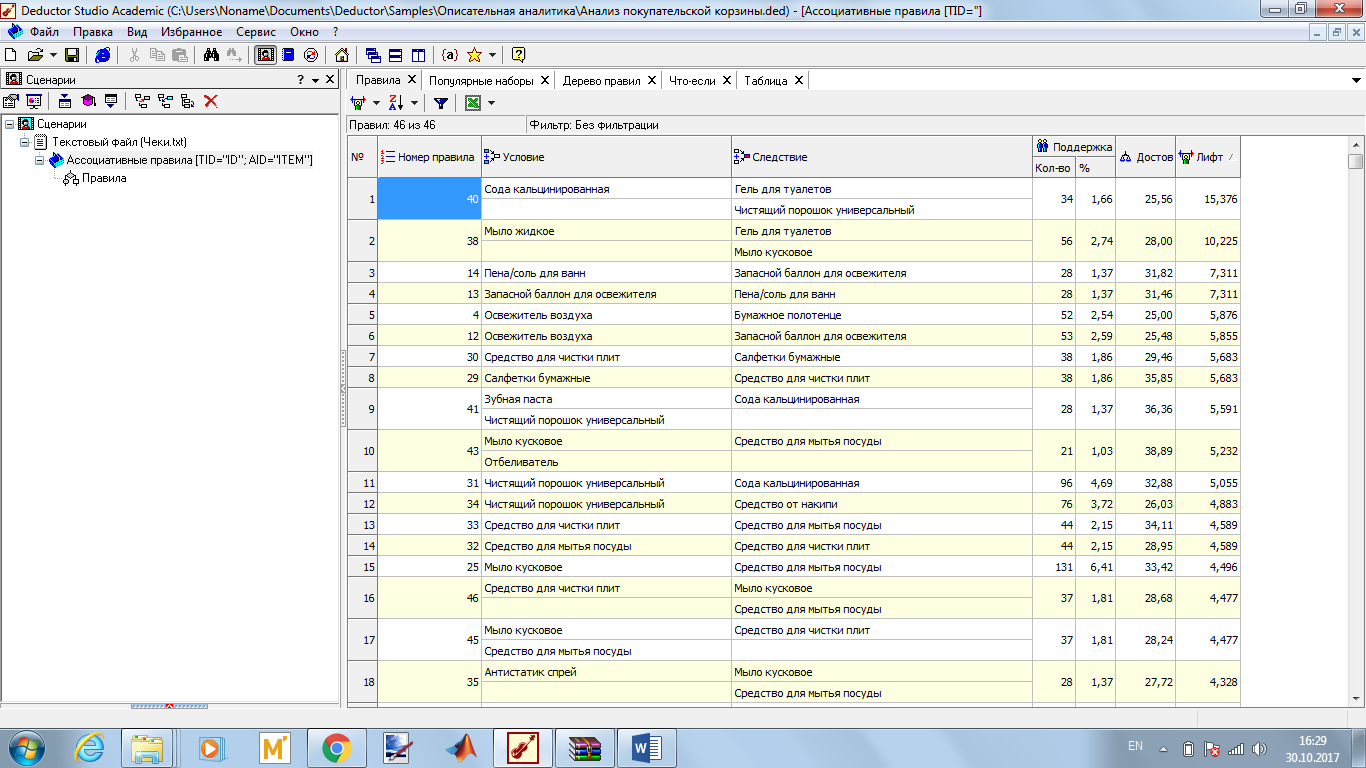
Рисунок 1. Правила..
В целях найти большее количество правил максимум поддержки был поднят до 40.
Алгоритм был применён со следующими параметрами: поддержка 1-40, достоверность 25-40.
Как и следовало ожидать, количество выделенных правил не уменьшилось и даже увеличилось.
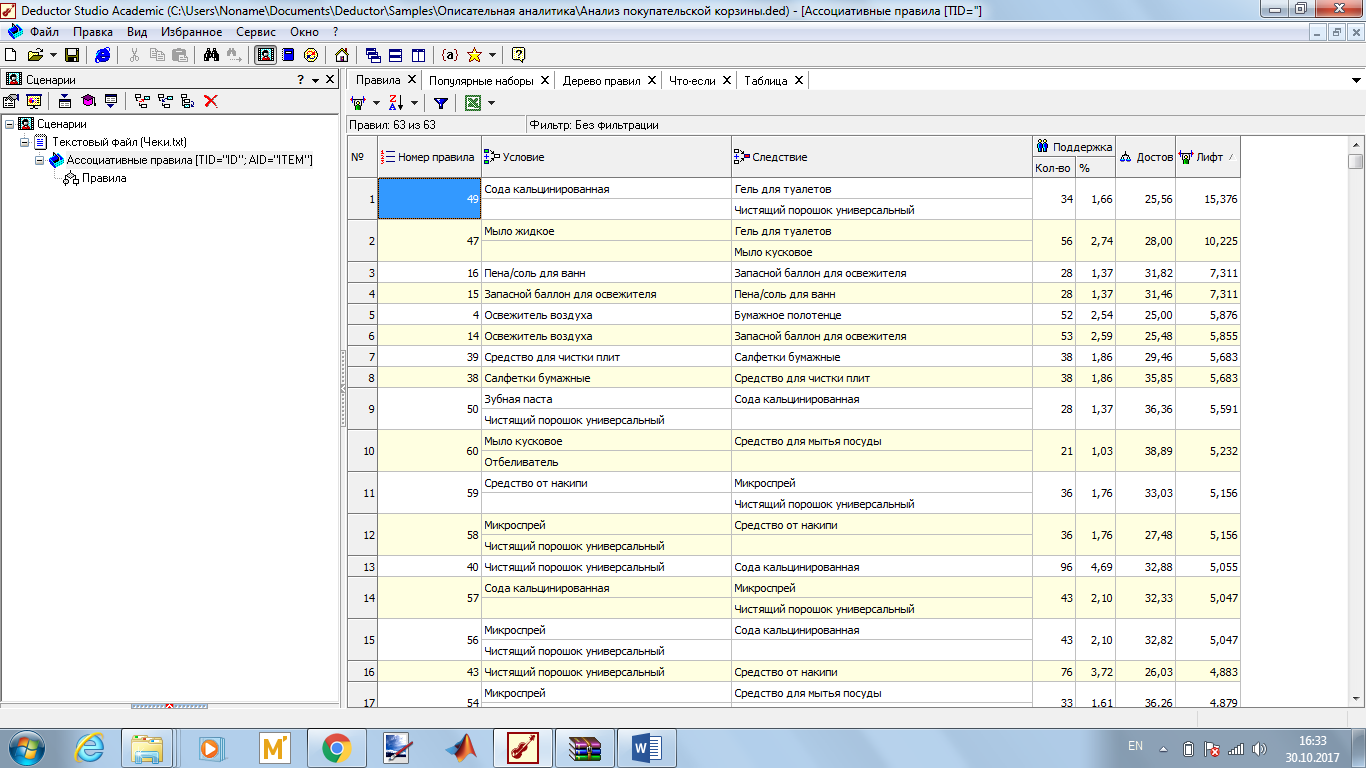
Рисунок 2. Правила.
Так, например, появилось правило: если куплено средство от накипи, то с достоверностью 33,03% будет куплен микроспрей с чистящим порошком(универсальным).
Изменим границы поддержки и достоверности следующим образом: поддержка 4-30, достоверность 25-60.

Рисунок 3. Правила.
С одной стороны, повышение минимальной поддержки должно уменьшить число не обоснованных правил, хотя при слишком большом значении пропадут и другие правила, повышение максимальной границы достоверности увеличивает количество тривиальных правил, то есть те случаи, когда причина связи между товарами вполне понятна и нахождение этих правил бесполезно, что и подтверждается результатами применения алгоритма. Из 4 полученных правил интерес представляет только последнее: если куплен чистящий порошок(универсальной), то с достоверностью 44,86% также будет куплен микроспрей.
Попробуем теперь выделить правила, представляющие интерес, применив алгоритм со следующими параметрами: поддержка 2-30, достоверность 25-30.
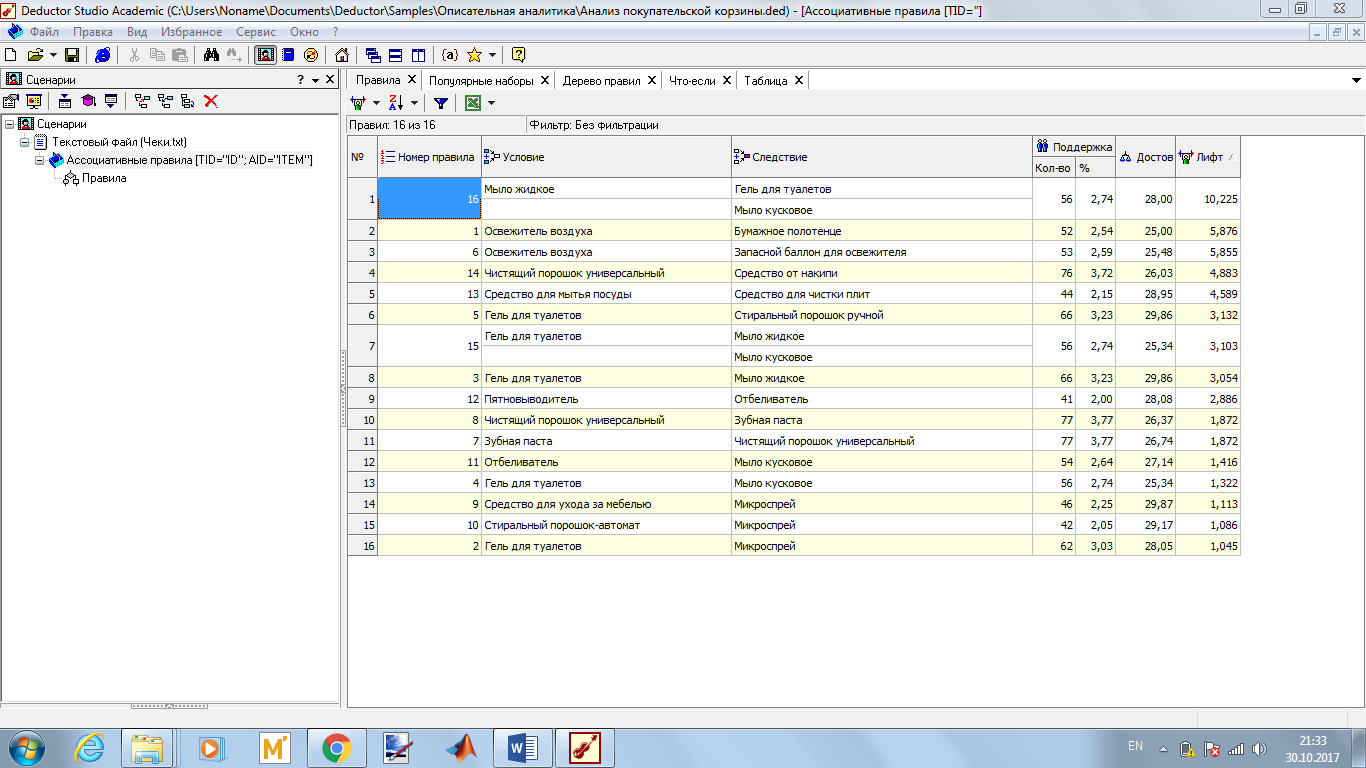
Рисунок 4. Правила.
Как видно, количество правил не так велико, но они могут быть с пользой использованы магазинами.
Вывод:
Проанализировав результаты, мы обнаружили, что для выделения наиболее полезных правил следует стремится к повышению минимума поддержки и понижению максимума достоверности, а обоснованием правдоподобности правила служит величина лифта.