

TPI 2 контрольные
.docКонтрольная работа №1



Контрольная работа №2


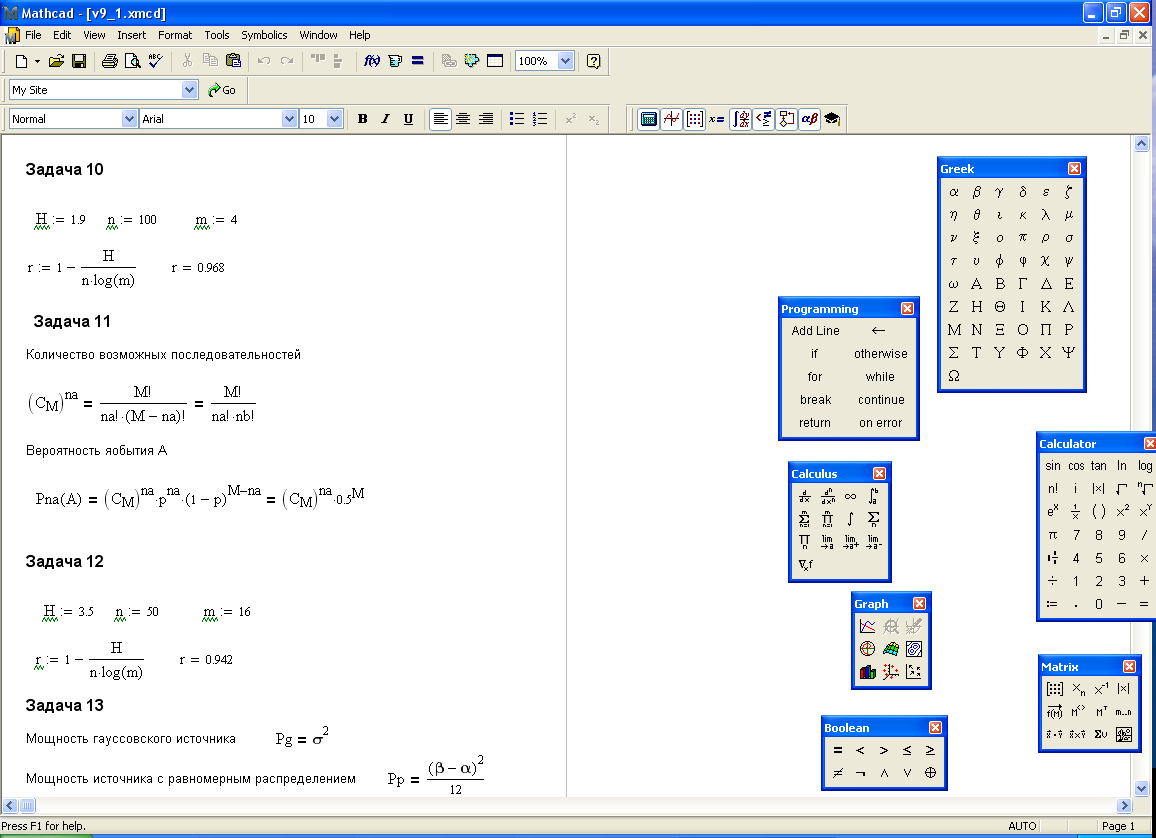
Задача 10
Статистическое кодирование слов
позволяет ещё больше уменьшить среднюю
длительность сообщений, так как алфавит
источника быстро увеличивается с
увеличением длины слова. Число возможных
кодовых слов (алфавит источника после
объединения букв) определяется выражением
m=kn, где k - алфавит
букв первичного сообщения. Пусть,
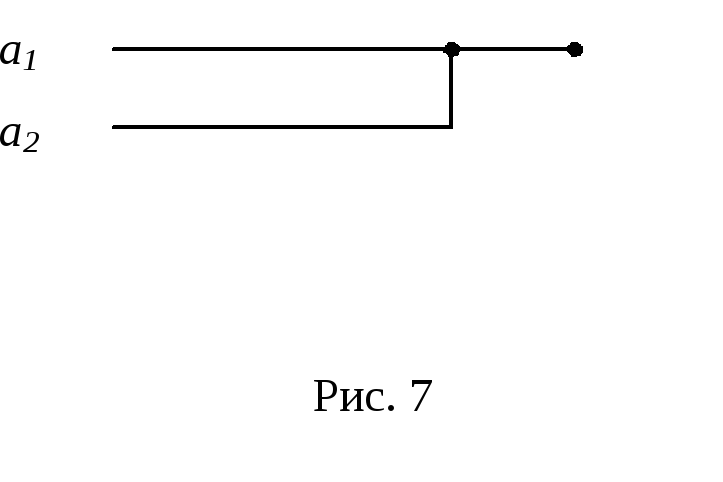
например, имеется двоичный источник,
дающий буквы а1 и а2
(например, “1” и “0”). При передаче этих
букв по каналу связи используются
сигналы длительностью э,
а
![]() .
.
Рассмотрим пример, когда p(а1)=0,8 и p(а2)=0,2 (если вероятности p(а1) и p(а2) равны между собой, никакое кодирование не может уменьшить среднюю длительность сообщения).
Энтропия
Образуем из элементов а1 и а2
слова из одной буквы(n=1)
![]() .
.
Образуем из элементов а1 и а2 слова из двух букв(n=2), беря различные сочетания из этих букв. Если источник с независимым выбором элементов сообщений, то
p(а1а1)=0,80,8=0,64;
p(а1а2)= p(а2а1)=0,80,2=0,16;
p(а2а2)=0,20,2=0,04.
Применяя к полученным словам кодирование по методу Шеннона‑Фано, получаем кодовое дерево (рис.), из которого видно, что новые комбинации неравномерного кода имеют длительность э, 2э и 3э.
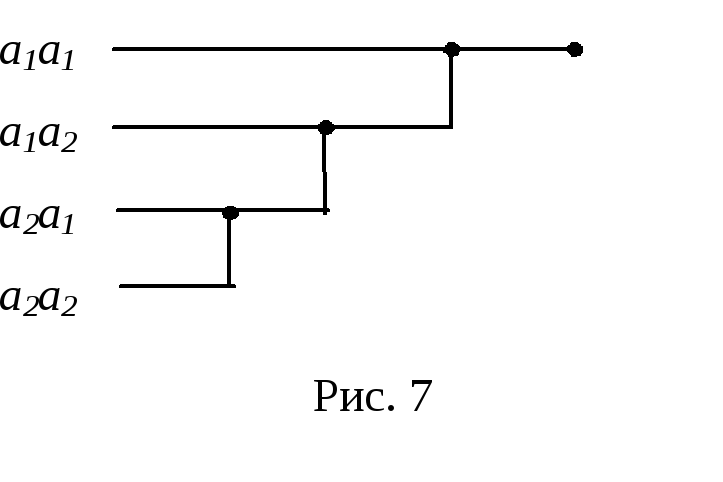
Средняя длина кодового слова
![]() .
.
Но так как каждое слово содержит
информацию о двух буквах первичного
сообщения, то в расчёте на 1 букву получаем
![]() .
Отсюда видно, что средняя длина элемента
сообщения сократилась по сравнению с
первоначальной в 1/0,78=1,38 раза.
.
Отсюда видно, что средняя длина элемента
сообщения сократилась по сравнению с
первоначальной в 1/0,78=1,38 раза.
Если усложнить кодирование и использовать
n=3, то в этом случае
получим
![]() .
Это – уже почти предел, дальше уменьшать
.
Это – уже почти предел, дальше уменьшать
![]() уже нецелесообразно. Чтобы убедиться
в этом, рассчитаем производительность
источника сообщений для всех трёх
случаев.
уже нецелесообразно. Чтобы убедиться
в этом, рассчитаем производительность
источника сообщений для всех трёх
случаев.
Энтропия источника
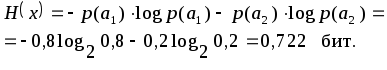 .
.
При отсутствии статистического
кодирования
![]() ,
,
![]() бит/с.
бит/с.
При кодировании слов по две буквы
![]() ,
,
![]() бит/с.
бит/с.
При кодировании по три буквы
![]()
![]() бит/с.
бит/с.
Последняя величина близка к предельно возможной величине 1/э.
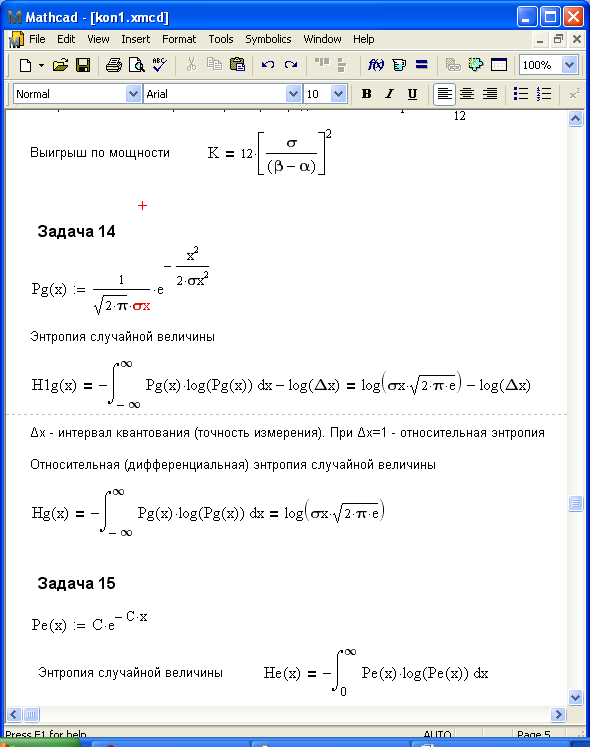
Задача 14
Структурная схема декодера рекуррентного кода приведена ниже.
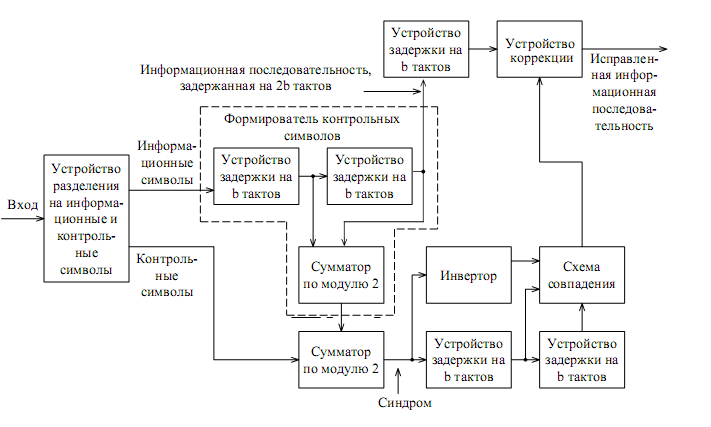

Рекуррентный код строится поступивший из канала следующий
![]()
Где проверочные символы при кодировании образуются по правилу
![]() ,
,
s - шаг сложения.
Разделим последовательность на информационные и проверочные символы.
Исх.
посл.
![]()
|
|
1 |
0 |
0 |
1 |
0 |
1 |
1 |
1 |
0 |
1 |
0 |
1 |
0 |
0 |
0 |
1 |
1 |
1 |
1 |
1 |
1 |
0 |
1 |
1 |
1 |
1 |
1 |
1 |
0 |
0 |
0 |
0 |
|
A |
1 |
|
0 |
|
0 |
|
1 |
|
0 |
|
0 |
|
0 |
|
0 |
|
1 |
|
1 |
|
1 |
|
1 |
|
1 |
|
1 |
|
0 |
|
0 |
|
|
B |
|
0 |
|
1 |
|
1 |
|
1 |
|
1 |
|
1 |
|
0 |
|
1 |
|
1 |
|
1 |
|
0 |
|
1 |
|
1 |
|
1 |
|
0 |
|
0 |
Поскольку s=3 то из информационных символов получаем b(k) – последовательность С. Просуммировав по модулю 2 последовательность С с последовательностью В получим исправляющую последовательность y.
|
A |
1 |
|
0 |
|
0 |
|
1 |
|
0 |
|
0 |
|
0 |
|
0 |
|
1 |
|
1 |
|
1 |
|
1 |
|
1 |
|
1 |
|
0 |
|
0 |
|
|
C |
|
0 |
|
0 |
|
0 |
|
1 |
|
1 |
|
1 |
|
0 |
|
1 |
|
1 |
|
1 |
|
0 |
|
1 |
|
1 |
|
1 |
|
1 |
|
1 |
|
B |
|
0 |
|
1 |
|
1 |
|
1 |
|
1 |
|
1 |
|
0 |
|
1 |
|
1 |
|
1 |
|
0 |
|
1 |
|
1 |
|
1 |
|
0 |
|
0 |
|
y |
|
0 |
|
1 |
|
1 |
|
0 |
|
0 |
|
0 |
|
0 |
|
0 |
|
0 |
|
0 |
|
0 |
|
0 |
|
0 |
|
0 |
|
1 |
|
1 |
Таким образом, декодированная последовательность
|
1 |
|
0 |
|
0 |
|
1 |
|
0 |
|
0 |
|
0 |
|
0 |
|
1 |
|
1 |
|
1 |
|
1 |
|
1 |
|
1 |
|
0 |
|
0 |
|