

Введение в многомерный статистический анализ / page175-212 / part2 / part2
.doc6.5. Классификация наблюдений в случае двух
многомерных нормальных генеральных совокупностей,
параметры которых оцениваются по выборке
6.5.1. Критерий классификации. До сих пор мы предполагали, что распределения обеих генеральных совокупностей известны точно. Но в большинстве приложений этой теории эти распределения являются неизвестными, но они могут быть получены из выборок, по одной из каждой генеральной совокупности. Сейчас мы рассмотрим случай, когда у нас есть выборка из каждой нормальной генеральной совокупности, и нам нужно использовать эту информацию для того, чтобы решить, над какой из этих двух генеральных совокупностей произведено другое наблюдение.
Пусть
![]() и
и
![]() —
выборки
из совокупностей N(
—
выборки
из совокупностей N(![]() )
и
)
и
![]() соответственно. На основе этой информации
нам нужно классифицировать наблюдение
х
как
наблюдение над
соответственно. На основе этой информации
нам нужно классифицировать наблюдение
х
как
наблюдение над
![]() ,
или над
,
или над
![]() .
Очевидно,
наилучшими оценками
.
Очевидно,
наилучшими оценками
![]() и
и
![]() (2)
являются соответственно
(2)
являются соответственно
![]() и
и
![]() ,
а лучшей оценкой матрицы
,
а лучшей оценкой матрицы
![]() является матрица S,
определяемая
из условия
является матрица S,
определяемая
из условия
![]() (1)
(1)
Подставив эти оценки параметров в (5) § 6.4, получим
![]() .
(2)
.
(2)
Первый член (2) является дискриминантной функцией, полученной по двум выборкам
[предложено Фишером [5]]. Это — линейная функция, имеющая наибольшую «дисперсию между выборками» относительно «дисперсии внутри выборок. Мы предлагаем использовать (2) в качестве критерия классификации таким же образом, как используется (5) § 6.4.
В случае, когда распределения, соответствующие генеральным совокупностям, известны, можно доказать, что критерий классификации является наилучшим в том смысле, что он дает минимум математического ожидания потерь в случае известных априорных вероятностей, и образует класс допустимых методов, когда априорные вероятности неизвестны. Использование (2) не может быть оправдано таким же образом. Интуитивно, однако, кажется разумным, что (2) дает хороший результат. В § 6.5.5 предлагается другой критерий.
Предположим,
что x1
. . .,xN
есть
выборка либо из
![]() ,
либо
из
,
либо
из
![]() 2,
и нам нужно классифицировать эту выборку
как целое. Определим S
уравнением
2,
и нам нужно классифицировать эту выборку
как целое. Определим S
уравнением
![]() (3)
(3)
где
![]() .
(4)
.
(4)
Тогда величина, дающая критерий, будет такой:
![]() .
(5)
.
(5)
Можно показать, что чем больше N, тем меньше вероятности ошибочной классификации.
6.5.2.
0
распределении величины V.
Пусть для случайных X,
![]() ,
,
![]() и
S
и
S
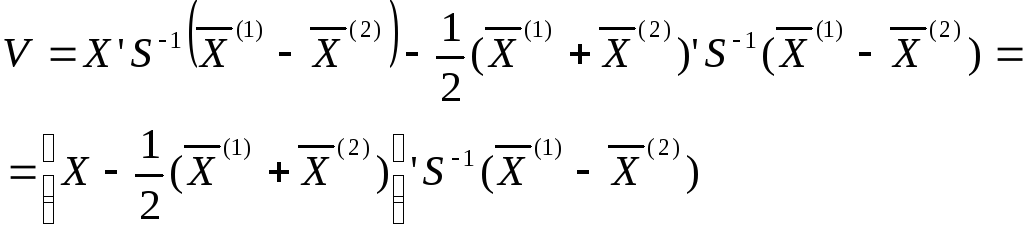 .
(6)
.
(6)
Распределение
величины V
слишком
сложно. Оно зависит от объемов выборок
и неизвестного параметра
![]() .
Пусть
.
Пусть
![]() , (7)
, (7)
Y
=![]() .
(8)
.
(8)
Тогда
V = Z'S-1Y. (9)
Математическое
ожидание Y
равно
![]() ,
а ковариационная матрица есть
[(1/N
,
а ковариационная матрица есть
[(1/N![]() )+(1/N
)+(1/N![]() )]
)]![]() .
Вектор Z
распределен нормально со средним
значением
.
Вектор Z
распределен нормально со средним
значением
![]() , (10)
, (10)
если
X
принадлежит генеральной совокупности
![]() ,
и
,
и
![]() , (11)
, (11)
если
X
принадлежит генеральной совокупности
![]() 2.
Ковариационная матрица в любом случае
равна [1+l/(4/N
2.
Ковариационная матрица в любом случае
равна [1+l/(4/N![]() )+1/(4N2)]
)+1/(4N2)]![]() .
Ковариация между векторами Z
и Y
равна
.
Ковариация между векторами Z
и Y
равна
![]() (12)
(12)
Если
![]() =
N2,
то
эта ковариация равна нулю. Легко видеть,
что в этом случае распределение V
для
X
из
=
N2,
то
эта ковариация равна нулю. Легко видеть,
что в этом случае распределение V
для
X
из
![]() совпадает с распределением — V
для X
из
совпадает с распределением — V
для X
из
![]() 2.
Поэтому, если V
2.
Поэтому, если V![]() 0
есть
область классификации наблюдения как
наблюдения над
0
есть
область классификации наблюдения как
наблюдения над
![]() ,
то вероятность ошибочной классификации
при условии, что X
принадлежит
,
то вероятность ошибочной классификации
при условии, что X
принадлежит
![]() ,
равна
вероятности ошибочной классификации
при условии, что X
принадлежит
,
равна
вероятности ошибочной классификации
при условии, что X
принадлежит
![]() 2.
2.
Распределение V рассмотрено Андерсоном [4], Ситгривесом [1] и Вальдом [2].
6.5.3.
Асимптотическое
распределение
величины V.
В
случае, когда объемы N![]() и
N2
выборок, произведеных из совокупностей,
распределенных N(
и
N2
выборок, произведеных из совокупностей,
распределенных N(![]() )
и
)
и
![]() ,
велики, то можно использовать предельные
распределения. Поскольку
,
велики, то можно использовать предельные
распределения. Поскольку
![]() есть
среднее значение выборки, состоящей из
есть
среднее значение выборки, состоящей из
![]() независимых
наблюдений над совокупностью,
распределенной N(
независимых
наблюдений над совокупностью,
распределенной N(![]() ),
то, как известно,
),
то, как известно,
![]() . (13)
. (13)
Точное
определение (13) следующее: для любых
положительных
![]() и
и
![]() можно найти такое N,
что для всех N
можно найти такое N,
что для всех N![]() N
N
![]() (14)
(14)
(см. задачу 12 главы 3). Это можно доказать, используя неравенство Чебышева. Аналогично
![]() . (15)
. (15)
plimS
=
![]() , (16)
, (16)
когда
![]() ,
N2
,
N2![]() ,
или
когда и N1
и N2
,
или
когда и N1
и N2![]() .
Из (16) получаем
.
Из (16) получаем
plimS![]() . (17)
. (17)
так как пределы сумм, разностей, произведений и отношений случайных величин по вероятности равны суммам, разностям, произведениям и отношениям соответствующих пределов, если только предел каждого знаменателя отличен от нуля (Крамер, [2], стр. 281). Далее
![]() (18)
(18)
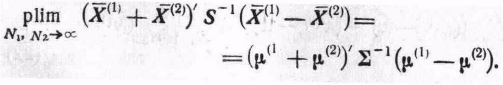 (19)
(19)
Отсюда
следует, что предельное распределение
V
является
распределением U.
Для
достаточно больших выборок из
![]() и
и
![]() 2
величину можно использовать так же, как
если бы мы точно знали распределение
генеральных совокупностей, и при этом
мы допускаем лишь небольшую ошибку.
(Этот результат впервые был получен
Вальдом [2].)
2
величину можно использовать так же, как
если бы мы точно знали распределение
генеральных совокупностей, и при этом
мы допускаем лишь небольшую ошибку.
(Этот результат впервые был получен
Вальдом [2].)
Теорема
6.5.1. Пусть
величина V
определена равенством (6),
где
![]() —
среднее значение выборки объема n
—
среднее значение выборки объема n
![]() из
совокупности N(
из
совокупности N(![]() ),
),
![]() — среднее
значение выборки объема N2
из
совокупности N (
— среднее
значение выборки объема N2
из
совокупности N (![]() ),
S
— оценка
),
S
— оценка
![]() ,
полученная
по объединенной выборке. Тогда предельным
распределением V
при N1
,
полученная
по объединенной выборке. Тогда предельным
распределением V
при N1![]() и
и
![]() будет
будет
![]() ,
если
X
распределен N(
,
если
X
распределен N(![]() ),
и
),
и
![]() ,
если
X
распределен
,
если
X
распределен
![]() .
.
6.5.4. Другой вывод критерия. Удобный мнемонический метод вывода критерия основан на использовании регрессии фиктивной величины (предложено Фишером [5]). Пусть
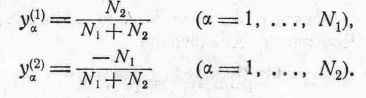
Найдем
формально регрессию на величины
![]() ,
выбрав
такой вектор b,
который
дает минимум величины
,
выбрав
такой вектор b,
который
дает минимум величины
![]() (20)
(20)
где
![]() (21)
(21)
«Нормальные уравнения» будут такими:
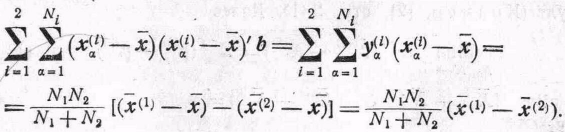
(22)
Матрицу, которая умножается на b, можно записать в виде
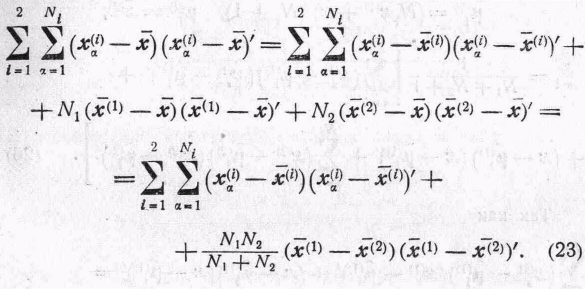
Поэтому (22) можно записать в следующем виде:
![]() (24)
(24)
где
![]() (25)
(25)
Так
как (![]() )'b—
скаляр,
то вектор b,
являющийся
)'b—
скаляр,
то вектор b,
являющийся
решением
(24), пропорционален вектору
![]() .
.
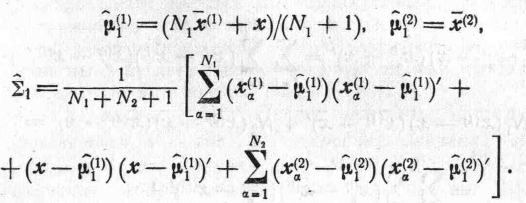 (26)
(26)![]() есть
выборка из совокупности
есть
выборка из совокупности
![]() и
и
![]() — выборка
из совокупности
— выборка
из совокупности
![]() .
Конкурирующая составная гипотеза
состоит в том, что
.
Конкурирующая составная гипотеза
состоит в том, что
![]() — выборка
из совокупности
— выборка
из совокупности
![]() ,
а х,
,
а х,
![]() — выборка из совокупности
— выборка из совокупности
![]() ;
;
![]() ,
,
![]() и
и
![]() неизвестны. Если справедлива первая
гипотеза, то оценками наибольшего
правдоподобия для
неизвестны. Если справедлива первая
гипотеза, то оценками наибольшего
правдоподобия для
![]() ,
,
![]() и
и
![]() будут
будут
Так как
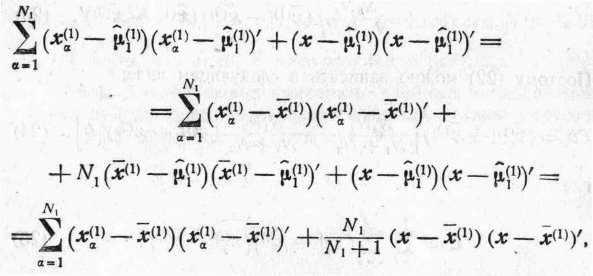
(27)
то
![]() ,
можно выразить таким образом:
,
можно выразить таким образом:
![]() (28)
(28)
где С определяется по формуле (25). Если предположить, что справедлива конкурирующая гипотеза, то (вследствие симметрии) получим следующие оценки наибольшего правдо подобия для параметров: .........
 (29)
(29)
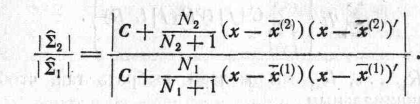
Следовательно, отношение правдоподобия равно (N1 +N2 +1)/2-й степени
(30)
Это отношение может быть записано также в виде
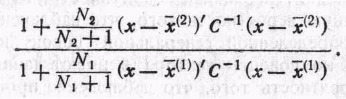 (31)
(31)
Область,
при попадании в которую наблюдение
классифицируется как выборка из
![]() ,
состоит
из тех точек, для которых отношение
(31) больше заданного числа.
,
состоит
из тех точек, для которых отношение
(31) больше заданного числа.