

2.8. Приближенное вычисление собственных чисел и векторов корреляционной матрицы.
В задачах обработки часто возникает необходимость в определении собственных векторов корреляционной матрицы, соответствующих тем или иным собственным числам.
Как было оказано, для нахождения собственных чисел и векторов следует найти корни характеристического полинома порядка n относительно 1, i=1, …n следует найти свой собственный вектор, который мы обозначим как a1=(a1i,…ani)r, как решение однородной системы линейных уравнений относительно этого собственного вектора при ограничении на его длину
![]()
Но хорошо известно, что точные методы поиска корней полиномы и корней системы линейных уравнений представляют собой громоздкие процедуры при больших n, практически начиная с n3. Поэтому данная задача часто решается итерационными методами вычислительной математики. Итерационные методы для одновременного поиска всех собственных чисел и векторов представляют собой методы преобразования симметричной матрицы в диагональную форму.
При обработке данных на ЭВМ широко используется, в частности, программа EIGEN, включенная первоначально в состав библиотеки научных программ на языке ФОРТРАН (библиотека SSP) для ЭВМ IBM-360/370. В настоящее время данная программа в том или ином виде присутствует в составе математических библиотек (аналогов SSP либо новых разработок) практически для всех языков программирования высокого уровня на всех типах ЭВМ (в частности, на ПЭВМ). В этой программе реализован метод Якоби преобразования действительной симметричной матрицы в диагональную форму. При отсутствии математической библиотеки с данной программой можно использовать её опубликованный текст, переписав в соответствии с правилами выбранного языка программирования.
Часто требуется вычислить только максимальное собственное число и соответствующий ему собственный вектор. Рассмотрим известный итерационный метод приближенного вычисления максимального собственного числа и соответствующего собственного вектора.
Пусть все собственные числа различны и упорядочены 1>2>…>n>0. Пусть x=(x1,…xn)r – некоторый вектор. Совокупность собственных векторов a1, i=1,…n корреляционной матрицы R образует ортонормированный базис, в пространстве которого вектор x образуется в вектор у, где
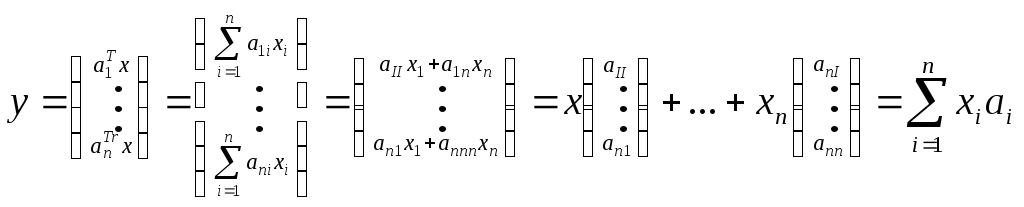
Тогда
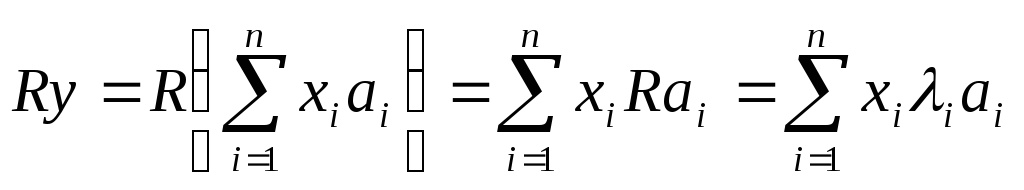
Выделим первое слагаемое
![]()
Умножим это равенство еще раз слева на R:
![]()
![]()
Т![]() огда
для некоторогоs
получим
огда
для некоторогоs
получим
![]()
Так
как 1>2>…>n>0
и
![]()
![]() ,
то
,
то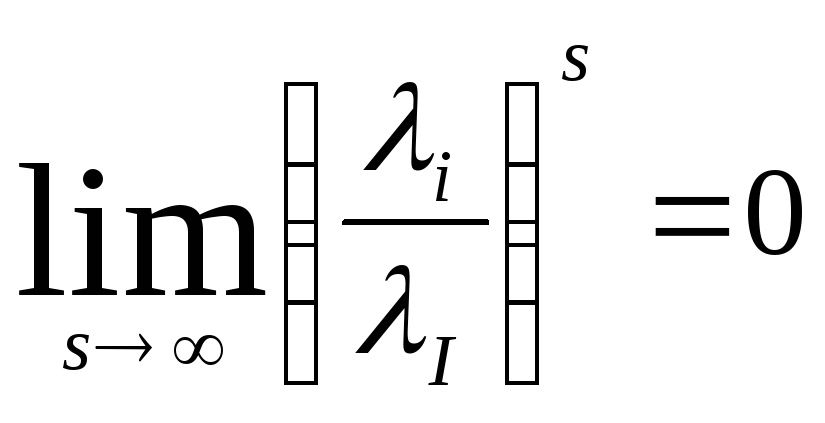 и
и![]()
Т![]() огда
при х10
первый собственный вектор определяется
достаточно далеким членом последовательности
y,
Ry, R2y,
…, Rsy,
…. Но при
1>1
получим, что
огда
при х10
первый собственный вектор определяется
достаточно далеким членом последовательности
y,
Ry, R2y,
…, Rsy,
…. Но при
1>1
получим, что
а
при 1<1
получим, что
![]()
![]()
Следовательно, векторRsy стремиться по направлению к вектору а1, но его длина значительно отличается от единичной.
П![]() оэтому
строят две другие последовательностиy0,
y1,
…ys,
… иz1,…zs,…,
гдеzs=Rys-1,
ys=zs/||zs||,
начиная с некоторого вектора у0единичной длины. Следовательно,||ys||=1
при любомs, а предел
последовательности{ys}
стремится по направлению к вектору
а1. Следовательно,
оэтому
строят две другие последовательностиy0,
y1,
…ys,
… иz1,…zs,…,
гдеzs=Rys-1,
ys=zs/||zs||,
начиная с некоторого вектора у0единичной длины. Следовательно,||ys||=1
при любомs, а предел
последовательности{ys}
стремится по направлению к вектору
а1. Следовательно,
тогда
![]()
![]()
![]() и
и![]()
![]() .
.
2.9. Понятие об измерении связи между качественными признаками. Статистический подход.
Как мы уже знаем, качественные признаки возникают при измерениях свойств объектов, например, в номинальной или ранговой шкалах. Пусть два качественных признака измерены в однотипных шкалах. Часто возникает вопрос о существовании или отсутствии связи между ними. Такая ситуация типична, например, при обработке результатов анкетирования. Рассмотрим измерение связи в номинальной шкале.
Пусть
N
– число наблюдений. Тогда, если в
номинальной шкале присутствует r
наименований, то Ni/N
– относительная частота i-го
значений, где
![]() .
.
Типичным является наглядное представление распределения объектов по группам в виде столбиковой диаграммы (гистограммы или полигона частот). В связи с таким представлением данных рассмотрим следующую статистическую задачу.
Пусть выдвинута гипотеза Н о том, что N измерений некоторого признака есть выборка N значений случайной величины с некоторым законом распределения. Если гипотеза Н справедлива, то дискретное распределение выборки можно считать статистической оценкой распределения всей генеральной совокупности. Из-за случайных колебаний эти два распределения не будут совпадать, но можно ожидать, что с ростом N распределение выборки будет приближаться к распределению генеральной совокупности. Тогда следует ввести некоторую меру несовпадения распределений и изучить свойства её выборочного распределения.
Такие меры несовпадения можно конструировать различными способами, но наиболее важной является мера, основанная на критерии 2 К.Пирсона.
Пусть
pi>0,
i=1,…r –
вероятности дискретных значений, где
![]() ,
образующие генеральный закон распределения
случайной величины. По методу наименьших
квадратов построим меру различия как
сумму квадратов отклонений наблюдаемых
частот от теоретических
,
образующие генеральный закон распределения
случайной величины. По методу наименьших
квадратов построим меру различия как
сумму квадратов отклонений наблюдаемых
частот от теоретических![]() ,
где сi
– произвольные коэффициенты. К.Пирсон
показал, что при сi=N/pi
получается
мера расхождения
,
где сi
– произвольные коэффициенты. К.Пирсон
показал, что при сi=N/pi
получается
мера расхождения
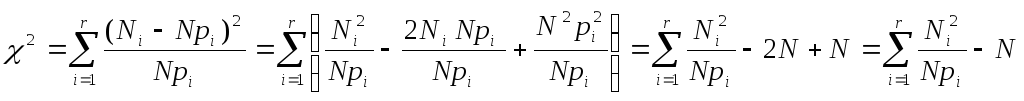 распределение
которой при N
стремится
к распределению 2.
распределение
которой при N
стремится
к распределению 2.
Вспомним
данное распределение. Пусть имеется r
независимых нормальных случайных
величин
x1…xr,
f(xi)=N(0,1),
i=1…r. Обозначим
![]() , а плотность распределения данной суммы
как2-распределение.
, а плотность распределения данной суммы
как2-распределение.
![]() ,
,
где: x=2- аргумент распределения f(x);
Kr-
константа
для выполнения условия нормировки
![]()
I(n) – гамма-функция, где для целых n>0:
I(1)=1,
I(n+1)=n! и
![]()
![]() ;
;
r – число степеней свободы.
Вид 2 – распределение полностью определяется числом r, а при r>30 практически переходит в нормальное N(r, 2r). Для некоторых распределение r имеет вид (Рис.2.2):
r=1,
![]()
r=2,
![]()
r=3,
![]()
r=4,
![]()
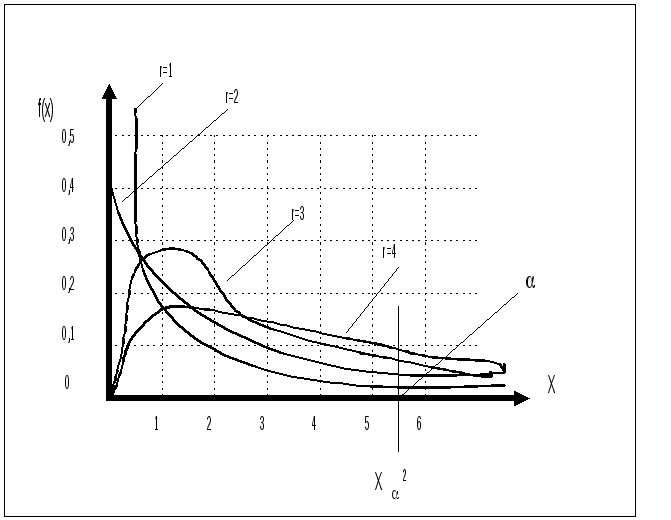
Рис.2.2. Распределение Пирсона
Пусть
![]() -
значимое значение2
с r-1
степенью свободы. Оно определяется так,
чтобы вероятность для наблюденного
значения 2
превысить 2
равнялось величине
-
значимое значение2
с r-1
степенью свободы. Оно определяется так,
чтобы вероятность для наблюденного
значения 2
превысить 2
равнялось величине
![]() .
.
Пусть настолько мало, что можно считать практически достоверным, что при одном испытании событие с вероятностью не произойдет. Если гипотеза Н верна, то практически невозможно в единственном эксперименте получить значение 2 >2. Если это так, то мы должны признать значит отклонение от гипотезы Н и её отвергнуть.
Вероятность ошибки (отвергнута справедливая гипотеза Н) есть вероятность Р(2>2)=. Это так называемая ошибка первого рода.
Измерим связь между двумя признаками. Статистическая интерпретация силы связи номинальных признаков основана на критерии 2. Пусть даны два таких признака и построены их гистограммы, не обязательно графически, а, например, в виде числового ряда. Совместимое распределение N наблюдений одновременно по r значениям первого признака Х и по s значениям второго признака Y образуют таблицу сопряженности (Рис.2.3), где

Ni и Nj – маргинальные частоты, то есть частоты независимого распределения значений каждого из данных двух признаков.
-
X/Y
y1 y2 … yj … ys
x1
x2
…
xi
…
xr
N11 N12 … Nij … N1s
N21 N22 … N2j … N2s
Ni1 Ni2 … Nij … Nis
Nr1 Nr2 … Nrj … Nrs
N1
N2
Ni
Nr
N1 N2 … Nj … Ns
N
Рис.2.3. Таблица сопряженности двух признаков.
Для такой таблицы требуется проверить гипотезу Н о статистической независимости признаков. Пусть pij – вероятность того, что значение xi признака Х соответствует значению yj признака Y. Тогда при справедливости гипотезы Н о независимости соблюдается соотношение
 для
r+s
постоянных
маргинальных вероятностей pi
и p
j.
Тогда
совместное распределение двух признаков
определяется r+s-2
неизвестными
параметрами, где из r+s
параметров
р
i
и p
j
параметры
р
r
и p
s
можно
выразить через остальные .
для
r+s
постоянных
маргинальных вероятностей pi
и p
j.
Тогда
совместное распределение двух признаков
определяется r+s-2
неизвестными
параметрами, где из r+s
параметров
р
i
и p
j
параметры
р
r
и p
s
можно
выразить через остальные .
Вычислим величину 2 как величину
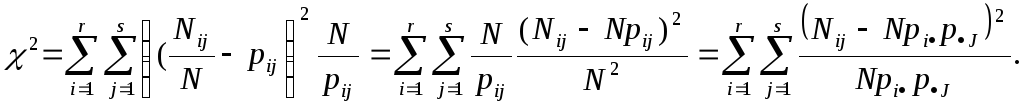
Если справедлива исходная гипотеза Н, то по условию независимости оценки маргинальных частот определяются как р i =Ni/N, p j=Nj /N. Тогда получим
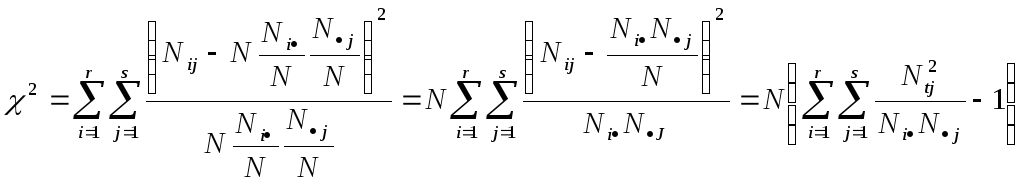
Так
как для таблицы сопряженности размером
![]() имеется rs
переменных
значений и
r+s-2
параметров, то предельное распределение
2,
N
имеет
k=rs-(r=s-2)-1
степеней
свободы k=rs-r-s+2-1=rs-r-s+1=r(s-1)-(s-1)=(s-1)(r-1).
имеется rs
переменных
значений и
r+s-2
параметров, то предельное распределение
2,
N
имеет
k=rs-(r=s-2)-1
степеней
свободы k=rs-r-s+2-1=rs-r-s+1=r(s-1)-(s-1)=(s-1)(r-1).
Для таблицы размером 2х2 число степеней свободы к=1. Тогда значение 2 с 1 степенью свободы на уровне значимости =0,001 определяет вероятность p(2>20,001)=0,001, где 20,001=10,827 (найдено по таблице). Следовательно, значение 210,827 встретится только один раз из 1000 при справедливости гипотезы H о независимости признаков. Поэтому при справедливости гипотезы H крайне мало вероятно (p<0,001), что наблюдаемые и ожидаемые частоты отличаются на столько, величина оценки окажется 210,827. Если же это так, то гипотезу H следует отвергнуть.
Таким образом, с помощью теста 2 можно оценить степень риска (вероятность ошибки первого рода), предполагая существование связи между признаками. Большие значения 2 говорят о значимом отклонении от гипотезы независимости, т.е. о связи.
Но
в то же время тест 2
не дает возможности измерить силу связи.
Поэтому для измерения силы связи логично
использовать некоторую характеристику,
принимающую минимальное значение при
отсутствии связи, и максимальное значение
при максимальной связи. Критерий 2
зависит
от объема выборки N.
Поэтому Пирсон использовал в качестве
меры связи между двумя признаками
величину среднеквадратичной сопряженности
2=2/N.
При
независимости 2=0.
Действительно, из
![]() следует
следует
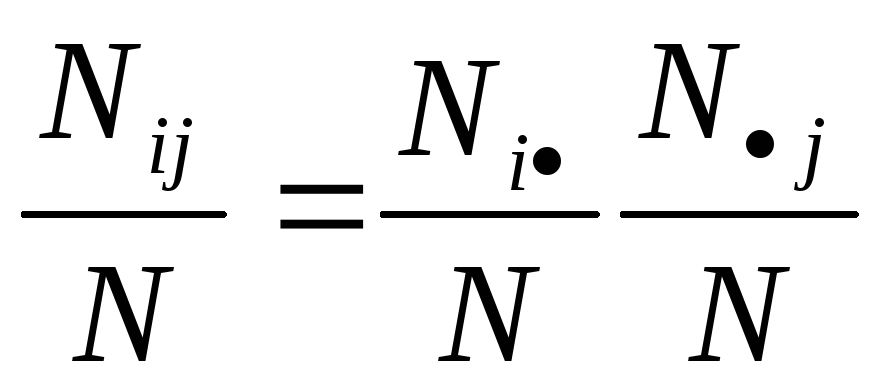 и
и
![]() .
.
Тогда
![]()
Найдем максимальное значение 2. Очевидно, что справедливо соотношения
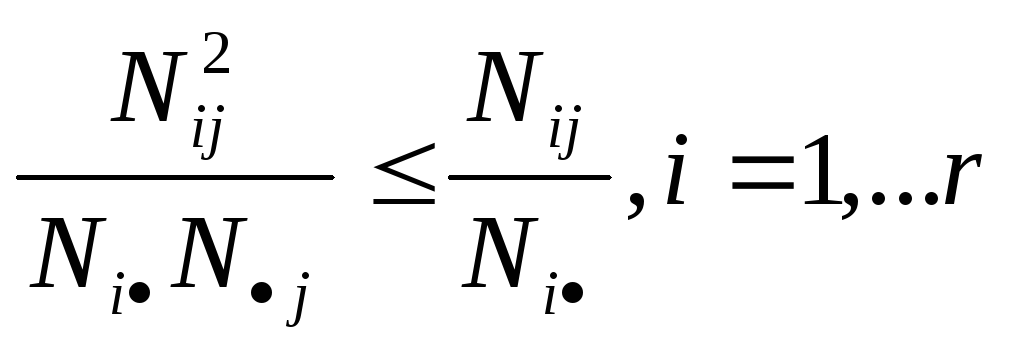 и
и
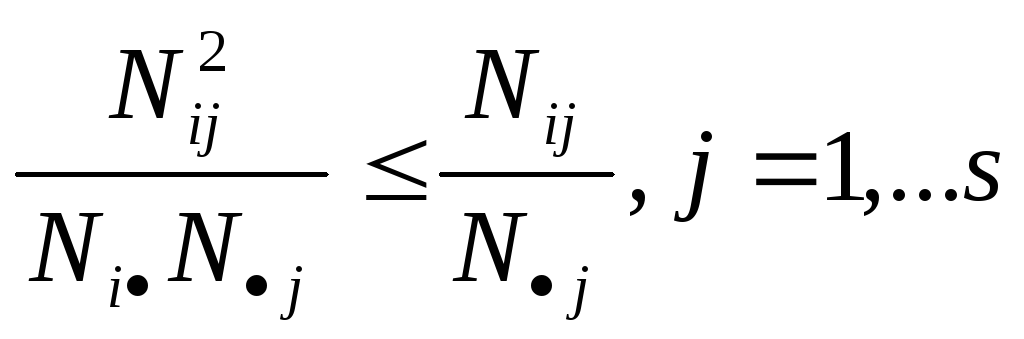
Тогда выполняется соотношения
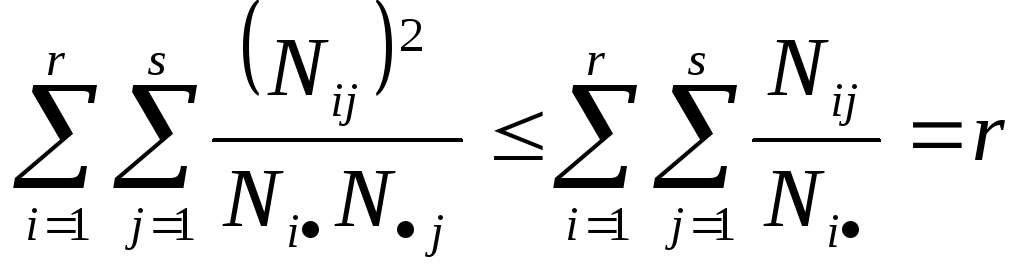 ,
,
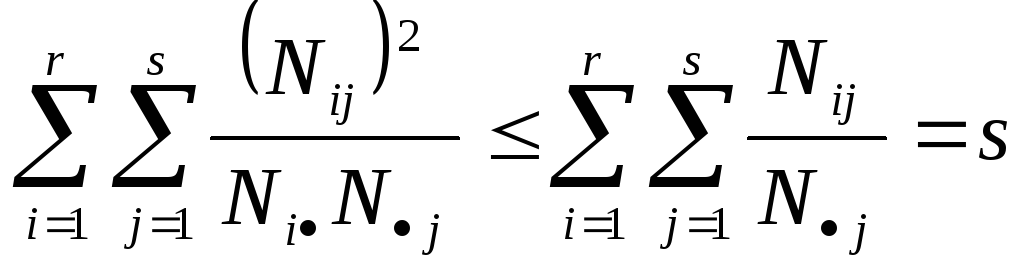 и
и
Тогда 2 N[min(r,s)-1] = N[min(r-1,s-1)] и окончательно 02ьшт(r-1,s-1)
Недостаток такой характеристики в том, что при r>2 или s>2 2>1. Поэтому А.А.Чупровым был предложен коэффициент
![]() где
0T21.
где
0T21.
В свою очередь, коэффициент Чупрова T2=1 только при r=s. Если rs, то даже при полной связи T2<1. Поэтому Г.Крамером был предложен коэффициент
![]() где
0V21.
где
0V21.
Коэффициент Крамера изменяется в данных пределах независимо от размера таблицы сопряженности.