

Санкт-Петербургский Государственный
Электротехнический Университет
ФКТИ
Кафедра МОЭВМ
Дисциплина: Базы знаний и экспертные системы
Пояснительная записка
к курсовой работе на тему
«Поиск ассоциативных правил. Алгоритм Apriori.»
Выполнили:
Руководитель:
Санкт-Петербург
2007 г.
Содержание
Постановка задачи.
Используя среду разработки программных приложений Delphi7.0 и заданные классы, написать модуль экспертной системы, реализующий алгоритмApriori. Программа должна иметь удобный пользовательский интерфейс и обеспечивать действия пользователя в отдельном окне.
Данные для анализа должны храниться в объекте класса TDMInstances.
Работа с данными, выбор переменных и их значений осуществляются в окне, отдельном от окна главной формы экспертной системы.
Описание алгоритма.
Алгоритм Aprioriопределяет часто встречающиеся наборы за несколько этапов. Наi-м этапе определяются все часто встречающиесяi-элементные наборы. Каждый этап состоит из двух шагов: формирование кандидатов и подсчета поддержки кандидатов.
Рассмотрим i-й этап. На шаге формирования кандидатов алгоритм создает множество кандидатов изi-элементных наборов, чья поддержка пока не вычисляется. На шаге подсчета кандидатов алгоритм сканирует множество транзакций, вычисляя поддержку наборов-кандидатов. После сканирования отбрасываются кандидаты, поддержка которых меньше определенного пользователем минимума, и сохраняются только часто встречающиесяi-элементные наборы. Во время 1-го этапа выбранное множество наборов кандидатов содержит все 1-элементные частые наборы. Алгоритм вычисляет их поддержку во время шага подсчета кандидатов.
Описанный алгоритм можно записать в виде следующего псевдокода:

Опишем обозначения используемые в алгоритме:
Lk– множествоk-элементных частых наборов, чья поддержка не менье заданной пользователем. Каждый член множества имеет набор упорядоченных (ij<ip, еслиj<p) элементовFи значение поддержки набораSuppF >Suppmin:
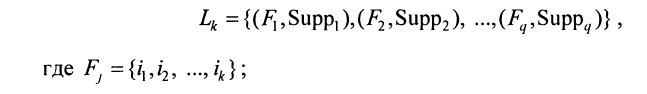
Ck– множество кандидатовk-элементных наборов потенциально частых. Каждый член множества имеет набор упорядоченных (ij<ip, еслиj<p) элементовFи значение поддержки набораSupp.
Опишем данный алгоритм по шагам:
Шаг 1.Присвоитьk=1 и выполнить отбор всех 1-элементных наборов, у которых поддержка больше минимально заданной пользователем.
Шаг 2.k = k+1.
Шаг 3.Если не удается создаватьk-элементные наборы, то завершить алгоритм, иначе выполнить следующий шаг.
Шаг 4.Создать множествоk-элементных
наборов кандидатов в частые наборы.
Для этого необходимо объединить вk-элементные кандидаты
(k-1) – элементные частые
наборы. Каждый кандидат с![]() Сkбудет формироваться путем добавления
к (k-1)- элементному частому
набору –pэлемента из
другого (k-1)- элементного
частого набора –q. Причем
добавляется последний элемент набораq, который по порядку выше,
чем последний элемент набораp(p.itemk-1<q.itemk-1).
При этом первые всеk-2
элемента обоих наборов одинаковы
(p.item1=q.item1,p.item2=q.item2,
…,
Сkбудет формироваться путем добавления
к (k-1)- элементному частому
набору –pэлемента из
другого (k-1)- элементного
частого набора –q. Причем
добавляется последний элемент набораq, который по порядку выше,
чем последний элемент набораp(p.itemk-1<q.itemk-1).
При этом первые всеk-2
элемента обоих наборов одинаковы
(p.item1=q.item1,p.item2=q.item2,
…,
p.itemk-2=q.itemk-2).
Это может быть записано в виде следующего SQL-подобного запроса.

Шаг 5. Для каждой транзакции Т из множестваDвыбрать кандидатов С1из множества Сk, присутствующих в транзакции Т. Для каждого набора из построенного множества Сk удалить набор, если хотя бы одно из его (k-1) множеств не является часто встречающимся, т.е. отсутствует во множествеLk-1. Это можно записать в виде следующего псевдокода:

Шаг 6. Для каждого кандидата из множестваCk увеличить значение поддержки на единицу.
Шаг 7.Выбрать только кандидатовLkиз множества Сk, у которых значение поддержки больше заданной пользователемSuppmin. Вернуться к шагу 2.
Результатом работы алгоритма является объединение всех множеств Lk для всехk.