

Excel. Занятие 4. Статистическая обработка данных
Цель занятия: Изучить использование Мастера функций и Пакета анализа Excel для выполнения статистической обработки данных.
Теория: В медицинской практике и в медицинских исследованиях часто приходится сталкиваться с необходимостью обработки данных.
Пакет Excel оснащен средствами статистической обработки данных. И хотя он значительно уступает специализированным пакетам обработки данных, тем не менее, в него включены основные наиболее часто используемые статистические процедуры: средства описательной статистики, критерии различия, корреляционные методы и другие, позволяющие проводить необходимый статистический анализ медицинских данных.
Методы эти реализованы в в Мастере функций и Пакете анализа Excel.
Определение основных статистических характеристик.
Задача 1.
Рассмотрим две группы больных тахикардией, одна из которых (контрольная) получала традиционное лечение, другая (исследуемая) получала лечение по новой методике.
Частота сердечных сокращений (ударов в минуту) для каждой группы:
Контроль |
Исследование |
162 |
135 |
156 |
126 |
144 |
115 |
137 |
140 |
125 |
121 |
145 |
112 |
151 |
130 |
Требуется провести статистический анализ этих данных.
Для данных двух выборок нам необходимо определить следующие статистические характеристики:
Среднее значение (Хс, М)- центр выборки, вокруг которого группируются элементы выборки.
Среднее квадратическое отклонение (стандартное отклонение) – параметр, характеризующий степень разброса элементов выборки относительно среднего значения.
Стандартное отклонение обычно обозначатся буквой «σ».
Среднее значение (математическое ожидание).
Создаем новый файл в Excel.

В ячейки В2:В8, С2:С8 вводим данные (можно просто скопировать данные из методички), в ячейку В9 с помощью Мастера функций вводим формулу для вычисления среднего значения. Для этого щелкаем на ячейке В9, нажимаем кнопку Вставка функций, выбираем категорию Статистические и функцию СРЗНАЧ. Нажимаем ОК. В поле Число 1 указываем диапазон ячеек В2:В8. Нажимаем ОК. Аналогичную формулу, но со ссылкой на диапазон С2:С8 вводим в ячейку С9.
Дисперсия

В ячейку В10 добавляем формулу для вычисления дисперсии. Щелкаем на ячейке В10, Мастер функций, Статистические, ДИСП, диапазон ячеек В2:В8. аналогичную формулу вводим в ячейку С10, но ссылка на диапазон С2:С8.
Стандартное отклонение (среднеквадратичное отклонение).
В той же таблице вычисляем стандартное
отклонение.
той же таблице вычисляем стандартное
отклонение.
В ячейке В11 находим стандартное отклонение для диапазона В2:В8 (контрольная группа). В ячейке С11 находим стандартное отклонение для диапазона С2:С8 (исследуемая группа).
Мастер функций, Статистические, СТАНДОТКЛОН, в поле Число1 указываем диапазон ячеек.
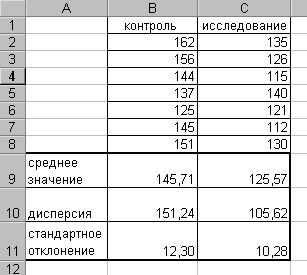
В результате получаем следующую таблицу:
Выявление достоверности различий
Следующей задачей статистического анализа в рассматриваемом примере является сравнение данных исследуемой группы с контрольной. Например, сопоставляя средние значения ЧСС контрольной группы больных (145,7) и исследуемой (125,6), можно видеть, что они отличаются. Можно ли по этим данным сделать вывод о большей эффективности нового препарата?
Для решения задач такого типа используются так называемые критерии различия, в частности, t — критерий Стьюдента.
Критерий Стьюдента (t) — наиболее часто используется для проверки гипотезы: «Средние двух выборок относятся к одной и той же совокупности». Критерий позволяет найти вероятность того, что оба средних относятся к одной и той же совокупности. Если эта вероятность р ниже уровня значимости (р < 0,05), то принято считать, что выборки относятся к двум разным совокупностям.
Уровень значимости — максимальное значение вероятности появления события, при котором событие считается практически невозможным. В медицине наибольшее распространение получил уровень значимости равный 0,05. Поэтому если вероятность, с которой интересующее событие может произойти случайным образом р < 0,05 , то принято считать это событие маловероятным, и если оно все же произошло, то это не было случайным.
Для оценки достоверности отличий по критерию Стьюдента принимается нулевая гипотеза, что средние выборок равны между собой. Затем вычисляется значение вероятности того, что изучаемые события (ЧСС больных в обеих выборках) произошли случайным образом.
Задача 2.
Используем данные предыдущей задачи.
Табличный курсор устанавливается в свободную ячейку (Вl4). Выбираем Вставка функции, в диалоговом окне Мастер функций выбираем категорию Статистические и функцию ТТЕСТ, после чего нажимаем кнопку ОК.

Указателем мыши вводим диапазон данных контрольной группы в поле Массив 1 (В2:В8). В поле Массив 2 вводим диапазон данных исследуемой группы (С2:С8). В поле Хвосты всегда вводится с клавиатуры цифра «2» (без кавычек), а в поле Тип с клавиатуры введем цифру «3».

Нажимаем кнопку ОК. В ячейке Вl2 появится значение вероятности — 0,006295.
Поскольку величина вероятности случайного появления анализируемых выборок (0,006295) меньше уровня значимости (р=0,05), то нулевая гипотеза отвергается. Следовательно, различия между выборками не случайные и средние выборок считаются достоверно отличающимися друг от друга. Поэтому на основании применения критерия Стьюдента можно сделать вывод о большей эффективности нового препарата (р<0,05).
При использовании t-критерия можно выделить два случая. В первом случае его применяют для проверки гипотезы о равенстве генеральных средних двух независимых, несвязанных выборок (так называемый двухвыборочный t-критерий). В этом случае есть контрольная группа и опытная группа, состоящие, например, из разных пациентов, количество которых в группах может быть различно. При заполнении диалогового окна ТТЕСТ при этом указывается Тип 3.
Во втором же случае, когда одна и та же группа объектов порождает числовой материал для проверки гипотез о средних, используется так называемый парный t-критерий. Выборки при этом называют зависимыми, связанными (при заполнении диалогового окна ТТЕСТ указывается Тип 1). Например, измеряется содержание лейкоцитов у здоровых животных, а затем у тех же самых животных после облучения определенной дозой излучения.
Задача 3.
Имеется температура (0С) двух групп больных:
37,3 |
37,1 |
37,3 |
37,2 |
37,4 |
37,3 |
37,5 |
37,4 |
37,6 |
37,5 |
Необходимо определить достоверность различия между группами при двух вариантах постановки задачи: 1) группы состоят из различных больных (тип 3); 2) группы состоят из одних и тех же больных, но первая — до приема жаропонижающего, а вторая — после (тип 1).
В ячейки С1:С5 вводим температуру больных первой группы. В ячейки D1:D5 вводим температуру больных второй группы.
1) Табличный курсор устанавливается в свободную ячейку (С6). Вставка функции, Статистические, ТТЕСТ, ОК. Указателем мыши ввести диапазон данных первой группы в поле Массив 1 (С1:С5). В поле Массив 2 ввести диапазон данных второй группы (D1:D5). В поле Хвосты всегда вводится цифра «2», а в поле Тип введем цифру «3». Нажать кнопку ОК. В ячейке С6 появится значение вероятности — 0,228053.

Поскольку величина вероятности случайного появления анализируемых выборок (0,228053) больше уровня значимости (р=0,05), то нулевая гипотеза не может быть отвергнута (принимается). Следовательно, различия между выборками могут быть случайными и средние выборок не считаются достоверно отличающимися друг от друга. Поэтому на основании применения критерия Стьюдента нельзя сделать вывод о достоверности отличий двух групп больных по их температуре (р>0,05).
2) Табличный курсор устанавливается в свободную ячейку (D6). Вставка функции, Статистические, ТТЕСТ, ОК. Указателем мыши ввести диапазон данных первой группы в поле Массив 1 (С1:С5). В поле Массив 2 ввести диапазон данных второй группы (D1:D5). В поле Хвосты всегда вводится цифра «2», а в поле Тип введем цифру «1». Нажать кнопку ОК. В ячейке С6 появится значение вероятности— 0,003883.
Поскольку величина вероятности случайного появления анализируемых выборок (0,003883) меньше уровня значимости (р=0,05), то нулевая гипотеза отвергается. Следовательно, различия между выборками не могут быть случайными и средние выборок считаются достоверно отличающимися друг от друга. Поэтому на основании применения критерия Стьюдента можно сделать вывод о том, что в двух группах больных выявлены достоверные отличия по температуре (р<0,05), что явилось результатом действия жаропонижающего.
Таким образом, можно видеть, что применение различных типов критерия Стьюдента может приводить к различным результатам на основании одних и тех же исходных данных. Можно предложить следующий приблизительный способ выбора типа критерия: если не ясно, какой тип критерия выбирать, выбирается тип 3; если очевидно, что выборки зависимы, связаны (например, это одни и те же больные), то следует выбирать Тип 1.
Критерий согласия χ2
Бывают ситуации, когда необходимо сравнить две относительные или выраженные в процентах величины. Например, в случае проверки эффективности действия вакцины. Пусть во время эпидемии в контрольной группе заболело 60 человек, а в вакцинированной 40 (обе группы включали но 100 человек). Для проверки достоверности различий здесь критерий Стьюдента применить не удастся. В таких задачах обычно используют критерий χ2 (хи-квадрат).
Здесь, как и в случае с критерием Стьюдента, принимается нулевая гипотеза, что средине выборок равны между собой. Кроме того, определяется ожидаемое значение результата. Обычно это среднее значение между выборками. В примере (60+40)/2=50, т. е. мы ожидали, что разницы между группами нет и в обоих случаях должно было заболеть по 50 человек. Затем вычисляется значение вероятности того, что изучаемые события (заболевания в обеих выборках) произошли случайным образом. Для этого вводим данные в рабочую таблицу: 60 — в ячейку Е1, 40 — в F1, 50 — в E2,F2. Табличный курсор устанавливается в свободную ячейку (ЕЗ). Вставка функции, Статистические, ХИ2-ТЕСТ , ОК. Указателем мыши ввести диапазон данных наблюдавшейся заболеваемости в поле Фактический интервал (Е1:F1). В поле Ожидаемый интервал ввести диапазон данных предполагаемой заболеваемости (E2:F2). Нажать кнопку ОК. В ячейке ЕЗ появится значение вероятности - 0,0455.

Поскольку величина вероятности случайного появления анализируемых выборок (0,0455) меньше уровня значимости (р=0,05), то нулевая гипотеза отвергается. Следовательно, различия между выборками не могут быть случайными и выборки считаются достоверно отличающимися друг от друга. Поэтому на основании применения критерия хи-квадрат можно сделать вывод о том, что в двух группах пациентов выявлены достоверные отличия по заболеваемости (р<0,05), что явилось результатом вакцинации.