12.8. Методы обнаружения и коррекции ошибок в цифровых звуковых сигналах
В
цифровых каналах связи средняя вероятность
появления ошибки составляет
![]() …
…![]() ,
а в отдельных случаях и
,
а в отдельных случаях и
![]() ,
поэтому влияние ошибок на качество
звукопередачи неизбежно. Это вызывает
необходимость применения помехоустойчивого
кодирования при передаче сигналов
3В.
,
поэтому влияние ошибок на качество
звукопередачи неизбежно. Это вызывает
необходимость применения помехоустойчивого
кодирования при передаче сигналов
3В.
Обнаружение и коррекция ошибок требуют введения в сигнал определенной избыточности. Для этой цели сигнал на выходе АЦП разделяется на блоки, в которые кроме основной информации, связанной с кодированием отсчетов, включаются дополнительные символы, необходимые для обнаружения и исправления ошибок. Перед цифро-аналоговым преобразованием эти блоки подвергаются дополнительной цифровой обработке, в процессе которой на этапе обнаружения определяется наличие ошибок. Для исправления ошибок необходимо определить место пораженных символов в блоке, чтобы заменить их на правильные. Исправление ошибок – задача гораздо более сложная, чем их обнаружение.
Помехоустойчивое кодирование основано на применении корректирующих кодов, в которые вносится некоторая избыточность, что приводит к увеличению требуемой пропускной способности канала связи. Различают коды для обнаружения ошибок и коды для исправления обнаруженных ошибок. Помехоустойчивые коды могут быть построены с любым основанием, однако наиболее простыми и часто используемыми являются двоичные коды.
Обнаружение ошибок в корректирующих кодах строится обычно на том, что для передачи используются не все кодовые слова кодового списка, а лишь их некоторая часть (разрешенные); остальные кодовые слова из этого списка являются запрещенными. Если переданное разрешенное кодовое слово вследствие ошибки преобразуется на приемной стороне тракта в запрещенное, то такая ошибка может быть обнаружена. Процедура исправления ошибок состоит в том, что комбинация, принятая ошибочно, заменяется той, принадлежащей также данному коду, расстояние до которой оказывается наименьшим.
Ошибки могут быть одиночными и сгруппированными в пакеты. Под пакетами понимают появление двух или большего числа ошибок в пределах одной m-разрядной кодовой комбинации. Если ошибки, возникающие при передаче сигналов, являются статистически независимыми, то вероятность появления пакета ошибок кратности q
![]() ,
(12.37)
,
(12.37)
где
![]() –
число сочетаний из т.
символов по q.
Для 10-разрядных кодовых слов вероятность
появления двойных ошибок при исходной
вероятности pош
=
–
число сочетаний из т.
символов по q.
Для 10-разрядных кодовых слов вероятность
появления двойных ошибок при исходной
вероятности pош
=
![]() составляет р1
= 5 •
составляет р1
= 5 •
![]() ,
а при рош
=
,
а при рош
=
![]() уже составляет р2
= 5 •
уже составляет р2
= 5 •
![]() .
Это соответствует появлению одной
двойной ошибки каждые 2.5...3 мин.
.
Это соответствует появлению одной
двойной ошибки каждые 2.5...3 мин.
Кроме того, в цифровых каналах передачи при средней вероятности появления ошибки рош = и выше возникают коррелированные ошибки, вызванные действием импульсных помех, несовершенством систем коммутации и т.д. Поэтому вероятность появления ошибок большой кратности возрастает. Особенно велика роль пакетов ошибок в каналах цифровой магнитной записи и в системе компакт-диска из-за возможных повреждений носителя записи. Системы исправления ошибок должны эффективно бороться не только с одиночными, но и с пакетами ошибок, заметность которых существенно выше. Чем больше кратность ошибки, тем больше должна быть избыточность, которую необходимо вносить в сигнал. Требуемая избыточность тем больше, чем большее число разрядов кодовой группы необходимо защищать. С учетом заметности искажений в системах цифровой передачи и записи ЗС обычно защищают от ошибок пять-шесть старших разрядов информационных символов кодируемых отсчетов, служебные комбинации, определяющие, например, номер шкалы квантования при почти мгновенном компандировании. Ошибки в младших разрядах, если частота их появления не слишком велика, достаточно обнаруживать и затем маскировать, используя методы интерполяции, о которых будет сказано ниже.
Выбор способа обнаружения ошибок, метода их маскирования и исправления, возможного только при помехоустойчивом кодировании, зависит как от среднего значения вероятности появления ошибки, так и от того, являются они одиночными или групповыми. Для тракта студийной аппаратной, а также трактов звукозаписи и первичного распределения программ 3В эти методы различны.
Простейшие методы обнаружения ошибки. Если цифровые аудиоданные передаются или считываются, то в приемнике нет возможности распознать, корректно ли принимаемое число (например, число 0101) либо один или несколько символов в принятом кодовом слове неверны. Для решения этой проблемы применяют коды. Самые простые из них коды с повторением. Каждый информационный символ можно, например, повторить п раз (обычно п нечетно и больше двух), т.е.
О < --- > 0 0 0 0 0......0,
1 < --- > 1 1 1 1 1......1.
Это (n,1)-код. Для него минимальное расстояние равно пив предположении, что большинство принятых битов совпадает с переданным информационным битом, может быть исправлено (п – 1)/2 ошибок. Если символы передать только дважды, а затем проверить, равны они или нет, чтобы при обнаружении ошибки сделать вывод, какое из двух чисел является правильным, то для принятия такого решения в данном случае нет точки опоры. Чтобы она появилась, каждое число нужно передать по крайней мере трижды и после сравнения распознать ошибочное. Такой метод неэффективен, он приводит к резкому увеличению требуемой скорости передачи. Нашли другие, более эффективные возможности.
Очень простыми являются коды с проверкой на четность. К информационным битам каждого кодового слова k-й разрядности добавляют (k+1)-й бит так, чтобы полное число единиц (или нулей) в кодовом слове было четным. Данный прием в цифровых устройствах из-за простоты используют очень часто. При этом дополнительный бит называется битом проверки на четность (паритетным битом). Например, для k = 4 имеем
0000 <---> 00000,
0001 <---> 00011,
0010 <---> 00101,
0011 <---> 00110.
и т.д.
Этот код является (k + 1,k)-кодом. Минимальное расстояние кода равно 2 и, следовательно, ошибки могут быть обнаружены, но никакие ошибки не могут быть исправлены. Если бит передается неправильно, то распознается появление ошибки в слове (ибо сумма всех единиц не будет равна четному числу, если ошибка одиночная). Однако позицию ошибки в кодовой комбинации определить невозможно. Таким образом данный код не позволяет исправить ошибки. В силу этого данный код используется только для обнаружения одиночных ошибок, но не для их исправления.
Впрочем можно распознать позицию единичных (отдельных) ошибок, если несколько слов предварительно объединить в матрицу, а контрольные разряды четности (дополнительные биты проверки на четность) добавить к информационным символам кодовых слов построчно и по столбцам, например:
Правильно Ошибка в первой строке, третий столбец
(выделена подчеркиванием)
0101 1 0111 1 (неправильная четность)
1001 1 1001 1
1101 0 1101 0
0010 0 0010 0
1100 1100

неправильная четность
Однако если в таком блоке одновременно появляется несколько ошибок, то такой метод не принесет пользы.
Маскирование ошибок. Если средняя вероятность появления ошибки не превышает pош = и источником ошибок является шум в канале передачи, то расчеты показывают, что одиночные ошибки появляются в среднем 2 раза в секунду, а двойные примерно 4 раза в сутки. В этих условиях достаточно учитывать только одиночные ошибки. Действие последних приводит к искажению величины отдельных отсчетов сигнала, и эффективным способом борьбы с ними является обнаружение ошибочно принятых кодовых слов с последующим маскированием искаженных отсчетов. Для обнаружения обычно используется уже описанный выше принцип проверки на четность, причем такой, чтобы число единиц в кодовом слове было четным. При приеме после выделения кодовых слов в каждом из них подсчитывается число единиц. Нечетное их число будет означать наличие ошибки в данном кодовом слове.
Вероятность p0 того, что при использовании данного метода ошибка не будет обнаружена, зависит как от вероятности pош её появления в канале, так и от числа разрядов (символов) т в кодовом слове, включая разряд четности. Величину p0 можно найти по формуле
![]() (12.38)
(12.38)
где
![]() –
число сочетаний т
символов по 2. Отсюда видно, что
использование длинных кодовых слов
ведет к росту вероятности необнаруженной
ошибки.
–
число сочетаний т
символов по 2. Отсюда видно, что
использование длинных кодовых слов
ведет к росту вероятности необнаруженной
ошибки.
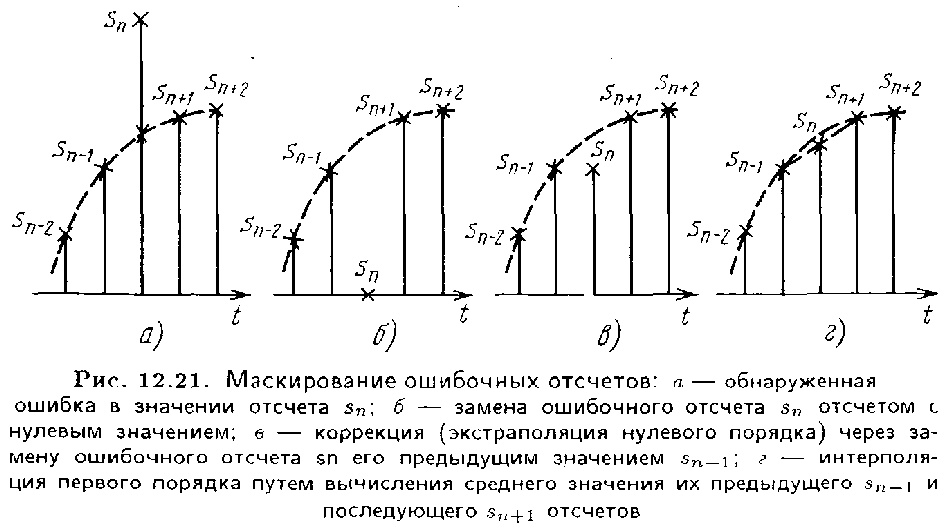
Если одиночная ошибка в кодовом слове обнаружена, то ее маскирование после этого состоит в замене искаженного отсчета. Обычные методы, используемые для этого процесса, показаны на рис. 12.21 На рис. 12.21,a отмечено ошибочное значение отсчета. Самым плохим наверняка является его замена на нуль, т.е. выбрасывание отсчета с ошибочным значением (рис. 12.21. б). Лучше, если ошибочный отсчет будет заменен на значение предыдущего отсчета (рис. 12.21,в). Еще лучше будет, если его значение получено как интерполяция значений двух соседних отсчетов, например путем вычисления среднего значения (рис. 12.21,г). Однако все же разность между восстановленным и истинным значениями отсчета может быть заметной на слух и намного превысить шаг квантования.
Поскольку слух человека инерционен, то метод маскирования оказывается эффективным, если число ошибок не превышает одной-двух в секунду. Это условие выполняется при вероятности появления ошибки в канале pош = . При т = 6 в этом случае получаем, что вероятность необнаруженной ошибки pо = 15* , что примерно соответствует требуемому значению.
Увеличение
pош
до значения
ведет
к резкому росту среднего числа ошибок
в секунду до 20. Метод интерполяции
первого порядка не обеспечивает полного
маскирования ошибок полезным сигналом,
они становятся уже заметными на слух.
Можно считать, что изложенный выше метод
маскирования применим, когда значение
pош
![]() .
.
Исправление ошибок. Если вероятность ошибки превышает pош = , то образуются пакеты ошибок и от их маскирования приходится переходить к исправлению. Для исправления ошибок применяют помехоустойчивое кодирование. При этом наиболее широкое распространение получили блочные линейные (m,k)-коды. У таких кодов передаваемая последовательность символов разделена на блоки, содержащие одинаковое число символов. Общее число символов (битов) в кодовом слове равно т, из них информационными являются первые k символов, а последние r = m – k символов – проверочными. Проверочные символы формируются в результате выполнения некоторых линейных операций над информационными символами. В частности, проверочные символы могут являться суммой по модулю 2 различных сочетаний информационных символов. Чем больше число проверочных символов, тем больше корректирующие возможности кода. Особенностью линейного кода является также то, что сумма (и разность) входящих в код кодовых слов также является кодовым словом, принадлежащим этому коду.
Корректирующие коды характеризуются избыточностью. Она определяется относительным увеличением длины блока из-за введения в него дополнительной проверочной информации и оценивается выражением
R = (m - k)/m, (12.39)
где R – избыточность кода.
Наиболее
известной разновидностью блочных
линейных (т,
k)-кодов
являются коды Хэмминга. Для каждого т
существует (![]() )-код
Хэмминга. Кроме параметров т
и k-
важным является минимальное расстояние
d,
определяющее меру различия двух наиболее
похожих кодовых слов. Расстоянием d
по Хэммингу между двумя q-ичными
последовательностями х
и у
длины п
называется число позиций, в которых
они различны. Это расстояние обозначается
d(х,у).
Например,
если х
=
10101 и у
=
01100, то имеем d(10101,01100)
= 3. При этом минимальное расстояние кода
равно наименьшему значению из всех
расстояний по Хэммингу между различными
парами кодовых слов в коде; (n,k)-код
с минимальным расстоянием d
называется также (n,k,d)-кодом.
)-код
Хэмминга. Кроме параметров т
и k-
важным является минимальное расстояние
d,
определяющее меру различия двух наиболее
похожих кодовых слов. Расстоянием d
по Хэммингу между двумя q-ичными
последовательностями х
и у
длины п
называется число позиций, в которых
они различны. Это расстояние обозначается
d(х,у).
Например,
если х
=
10101 и у
=
01100, то имеем d(10101,01100)
= 3. При этом минимальное расстояние кода
равно наименьшему значению из всех
расстояний по Хэммингу между различными
парами кодовых слов в коде; (n,k)-код
с минимальным расстоянием d
называется также (n,k,d)-кодом.
Из теории помехоустойчивого кодирования известно, что если произошло t ошибок и расстояние от принятого слова до каждого другого больше t, то декодер исправит эти ошибки, приняв ближайшее к принятому кодовое слово в качестве действительного переданного. Это будет всегда так, если
![]() (12.40)
(12.40)
Например, для обнаружения одиночной ошибки d = 2. Это означает, что достаточно информационные кодовые группы увеличить на один разряд. Для исправления одиночных ошибок каждую кодовую группу необходимо увеличить уже на три разряда. С ростом кратности ошибок объем требуемой дополнительной информации резко возрастает. Так, для числа k битов аудиоданных требуется следующее число контрольных (дополнительных, проверочных) бит г в коде Хэмминга, чтобы ошибка была бы исправлена:
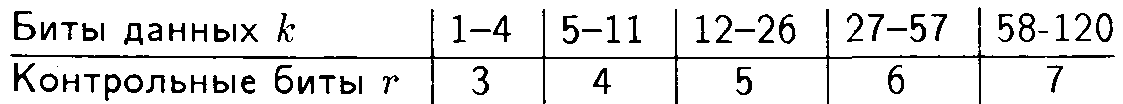
Контрольные
биты рассчитываются (вычисляются) путем
сложений по модулю 2. В них участвуют
информационные биты аудиоданных по
меньшей мере дважды. Чтобы с большой
вероятностью обнаружить ошибку в потоке
данных, информационные слова и контрольные
слова охватываются совместно в блоки.
Эти блоки затем снова рассматриваются
как отдельные единицы информации и
далее кодируются (блочный код). Иногда
удается исправлять конфигурацию из t
ошибок даже в том случае, если неравенство
(12.40) не выполняется. Однако если
![]() то
исправление любых t
ошибок не может быть гарантировано,
так как оно зависит от передаваемого
слова и конфигурации из t
ошибок, возникших внутри блока.
то
исправление любых t
ошибок не может быть гарантировано,
так как оно зависит от передаваемого
слова и конфигурации из t
ошибок, возникших внутри блока.
При
кодовом расстоянии d
= 3 коды Хэмминга имеют длину
![]() При двух проверочных символах r
= 2 существует код Хэмминга (3,1); при r
=
3 – код (7,4); при r
= 4 – код (15,11) и т.д. Коды, для которых d
=
3, могут исправлять одиночную ошибку.
Для нахождения места этой ошибки
необходимо выполнить r
проверок, представляющих собой операции
суммирования по модулю 2. Технически
это реализуется достаточно просто.
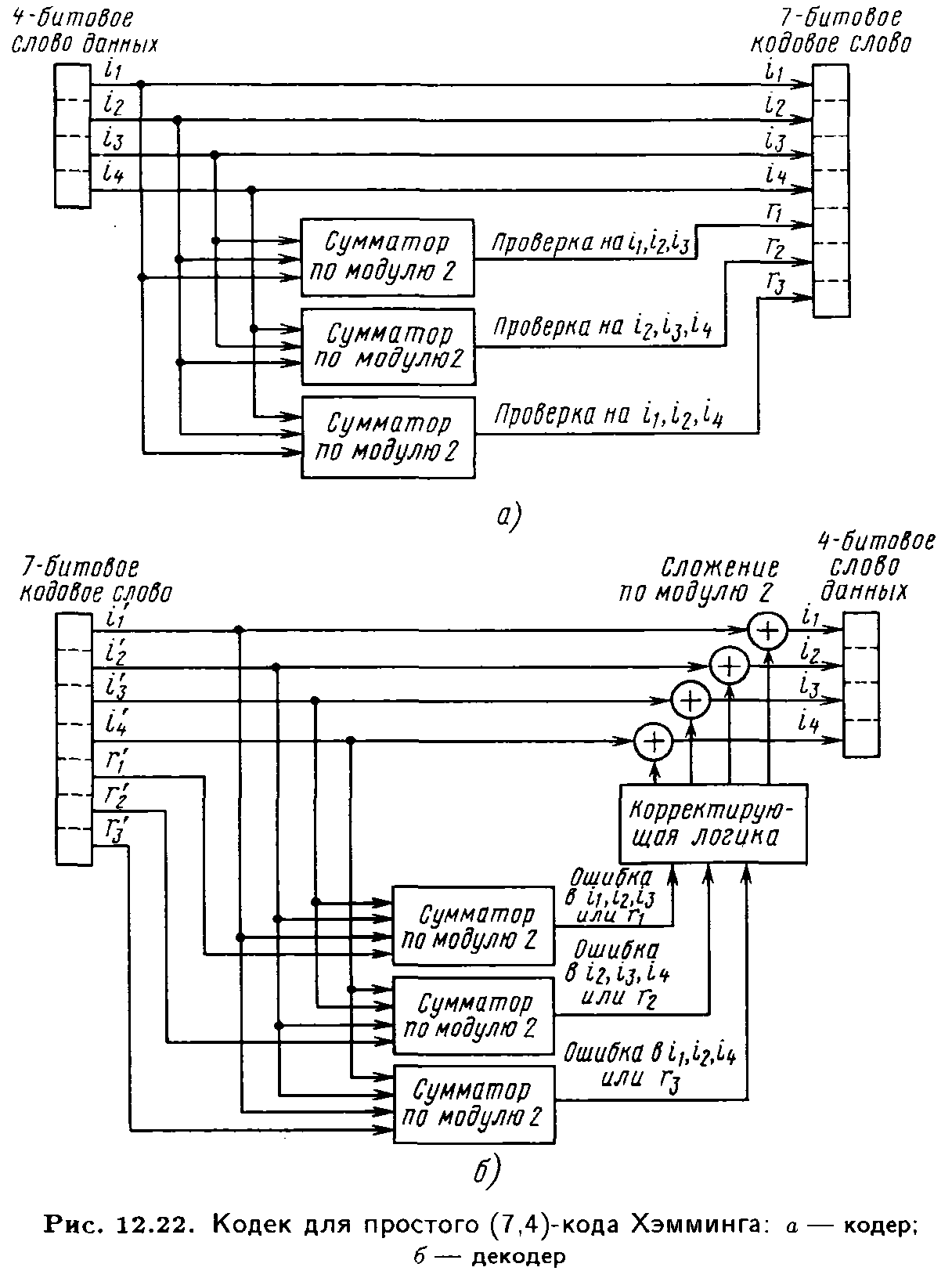
Например, (7,4)-код Хэмминга можно описать
с помощью реализации, приведенной на
рис. 12.22,а. При заданных четырех
информационных битах данных (i1,
i2, i3, i4)
каждое кодовое слово дополняется тремя
проверочными битами, задаваемыми
равенствами
При двух проверочных символах r
= 2 существует код Хэмминга (3,1); при r
=
3 – код (7,4); при r
= 4 – код (15,11) и т.д. Коды, для которых d
=
3, могут исправлять одиночную ошибку.
Для нахождения места этой ошибки
необходимо выполнить r
проверок, представляющих собой операции
суммирования по модулю 2. Технически
это реализуется достаточно просто.
Например, (7,4)-код Хэмминга можно описать
с помощью реализации, приведенной на
рис. 12.22,а. При заданных четырех
информационных битах данных (i1,
i2, i3, i4)
каждое кодовое слово дополняется тремя
проверочными битами, задаваемыми
равенствами
r 1 = i1+ i2+ i3,
r 2 = i2+ i3+ i4, (12.42
r 3 = i1+ i2+ i4,)
Знак «+» здесь означает сложение по модулю 2: 0 + 0 = 0, 0 + 1 = 1, 1+0=1, 1+1=0. Шестнадцать разрешенных кодовых слов (7,4)-кода Хэмминга имеют вид (i1, i2, i3, i4, r1, r2, r3):
0000000 1000101
0001011 1001110
0010110 1010011
0010110 1011000
0011101 1100010
0100111 1101001
0101100 1110100
0110001 1 111111
0111010
Пусть при передаче в принятом слове v = (i`1, i`2, i`3, i`4, r`1, r`2, r`3). По изображенному на рис. 12. 22,б коду вычисляются биты
s 1 = r`1+ i`1+ i`2+i`3,
s 2 = r`2+ i`2+ i`3+i`4, (12.42)
s 3 = r`3+ i`1+ i`2+i`4
Трехбитовая последовательность (s 1, s 2, s 3) называется синдромом. Она зависит только от конфигурации ошибок. Всего имеется восемь возможных синдромов: один для случая отсутствия ошибки и по одному для каждой из семи возможных одиночных ошибок, при этом каждая ошибка имеет только свой единственный синдром. Несложно сконструировать цифровую логику, которая по синдрому локализует соответствующий ошибочный бит. После исправления ошибки проверочные символы опускаются. При наличии двух и более ошибок код будет ошибаться:
он предназначен для исправления только одной одиночной ошибки в кодовом слове группы.
При
d
= 4 коды Хэмминга имеют длину т
=
![]() и записываются соответственно как
(4,1); (8,4); (16,11) и т.д. Они получаются из
кодов Хэмминга с минимальным расстоянием
d
=
3 добавлением к каждому кодовому слову
[см. (12.43)] одного проверочного символа,
равного сумме по модулю 2 всех остальных
символов как информационных, так и
проверочных для каждого кодового слова
исходного (7,4)-кода Хэмминга.
и записываются соответственно как
(4,1); (8,4); (16,11) и т.д. Они получаются из
кодов Хэмминга с минимальным расстоянием
d
=
3 добавлением к каждому кодовому слову
[см. (12.43)] одного проверочного символа,
равного сумме по модулю 2 всех остальных
символов как информационных, так и
проверочных для каждого кодового слова
исходного (7,4)-кода Хэмминга.
При выборе кода важно определить мощность кода М, т.е. максимальное число кодовых слов в двоичном коде длиной т (множество двоичных слов длины m) при заданном кодовом расстоянии d. Обычно при d = 3
![]() (12.45)
(12.45)
Следовательно, (3,1)-код Хэмминга состоит всего лишь из двух кодовых слов. Для увеличения числа кодовых слов необходимо увеличить длину кодового слова: для (7,4)-кода Хэмминга уже имеется 16 кодовых слов. С увеличением т растет сложность декодирования. Коды Хэмминга в силу этой причины целесообразно использовать для исправления одиночных независимых ошибок при небольшом числе возможных информационных символов. В частности, коды Хэмминга используют для передачи трехсимвольных комбинаций, определяющих номер шкалы квантования при кодировании ЗС с применением почти мгновенного компандирования.
Достаточно простой процедурой кодирования и декодирования обладают линейные циклические коды (CRC-коды), где разрешенные кодовые слова формируются из других разрешенных слов циклическим сдвигом символов на один шаг вправо. Цикличность позволяет уменьшить объем памяти устройств, осуществляющих кодирование и исправление ошибок, а возможность записи кодовых слов в виде степенных полиномов сводит процедуры кодирования и декодирования к операциям умножения и деления полиномов, легко реализуемых технически.
Кодовое
слово Z
=
(а0,
а1, а2,....ап-1),
состоящее из n
символов определяется полиномом У(х)
–
а0
+ а1X + а2![]() +...ап-1
+...ап-1![]() Среди
всех полиномов, соответствующих кодовым
словам циклического кода, имеется
ненулевой полином наименьшей степени.
Он называется порождающим,
степень его к
= п – k(k-
– число информационных символов, n
– число символов в кодовом слове), а
свободный член равен единице. Основная
особенность порождающего полинома
заключается в том, что он полностью
определяет циклический код (все кодовые
слова циклического кода) и является
делителем всех полиномов, соответствующих
кодовым словам циклического кода.
Среди
всех полиномов, соответствующих кодовым
словам циклического кода, имеется
ненулевой полином наименьшей степени.
Он называется порождающим,
степень его к
= п – k(k-
– число информационных символов, n
– число символов в кодовом слове), а
свободный член равен единице. Основная
особенность порождающего полинома
заключается в том, что он полностью
определяет циклический код (все кодовые
слова циклического кода) и является
делителем всех полиномов, соответствующих
кодовым словам циклического кода.
Процесс
кодирования при использовании циклического
кода состоит в следующем. Полином
G(х)
степени (k
–
1), характеризующий k-разрядное
передаваемое информационное кодовое
слово, умножается на
![]() .
Полученный полином G(х)
степени
k+r–1
делится на порождающий полином F(х).
В результате деления образуется остаток
q(х)
степени не более r
–
1. Полином Q(x)
=
G(х)+q(х),
делящийся на F(х)
без
остатка, определяет каждое разрешенное
кодовое слово циклического кода.
Члены полинома Q(x)
со
степенью r
+
1 и выше соответствуют информационным
символам, смещенным на г
разрядов в результате операции
умножения, а остаток q(х)
от
деления – поверочным символам. Для
обнаружения или исправления ошибок в
циклическом коде обычно используют
операцию деления полинома Q1(x)
принятого
кодового слова на заранее известный
порождающий полином F(х).
Если остаток от деления не равен нулю,
то принятое кодовое слово считается
ошибочным. Место ошибки определяется
детектором ошибки в результате сравнения
остатка от деления с эталонным полиномом,
хранящимся в памяти. Биты избыточности,
полученные изложенным выше способом,
передаются совместно с первоначальными
битами данных.
.
Полученный полином G(х)
степени
k+r–1
делится на порождающий полином F(х).
В результате деления образуется остаток
q(х)
степени не более r
–
1. Полином Q(x)
=
G(х)+q(х),
делящийся на F(х)
без
остатка, определяет каждое разрешенное
кодовое слово циклического кода.
Члены полинома Q(x)
со
степенью r
+
1 и выше соответствуют информационным
символам, смещенным на г
разрядов в результате операции
умножения, а остаток q(х)
от
деления – поверочным символам. Для
обнаружения или исправления ошибок в
циклическом коде обычно используют
операцию деления полинома Q1(x)
принятого
кодового слова на заранее известный
порождающий полином F(х).
Если остаток от деления не равен нулю,
то принятое кодовое слово считается
ошибочным. Место ошибки определяется
детектором ошибки в результате сравнения
остатка от деления с эталонным полиномом,
хранящимся в памяти. Биты избыточности,
полученные изложенным выше способом,
передаются совместно с первоначальными
битами данных.
Пример. Последовательность из п = 10 битов можно представить степенным полиномом, например, вида Р(х) = х9 + x5 + х2 + 1, который представляет собой информационное кодовое слово 1000100101. Разделим теперь Р(x) на порождающий полином, называемый также генераторным полиномом G(х). Результатом деления будет частное Q(x) и остаток R(x).
Возьмем в качестве генераторного полинома G(х) = x5 + x4 + x2 + 1, представляющий двоичное число 110101. Перемножим Р(х) и первый член полинома G(x), имеющий наивысшую степень, а полученный результат затем разделим на G(x);
![]()
Rest R(x) = x+1.
В ыполним
эти вычисления
ыполним
эти вычисления
Передаваемое кодовое слово D(х) в этом случае имеет вид D(x)=Р(x)+R(x),
в примере соответственно 100010010100011. Декодирующее устройство делит эти биты данных на G(x), и если новый остаток R'(х) = 0, то передача свободна от ошибок (без ошибок). В противном случае из остатка можно локализовать ошибку.
В качестве примера на рис. 12.23 показаны структурные схемы кодирующего и декодирующего устройств с использованием циклического кода (29,24). Порождающий многочлен этого кода имеет вид F1(x) = x5 + x2 + 1. Первоначально (рис. 12.23,а) ключ К замкнут и на вход схемы последовательно подаются информационные символы. Одновременно эти же символы поступают на выход. Кодер представляет собой здесь многотактный линейный фильтр Хаффмена, состоящий из элементов 1–5 сдвигового регистра и двух сумматоров С1 и С2 Данное устройство выполняет деление полинома x5G(x) на порождающий полином F1(х). После 24 тактов работы кодера в его регистра образуется остаток q(x) от деления. На 25-м такте ключ К перебрасывается в верхнее положение и символы остатка (поверочные символы) один за другим поступают на выход кодера. За пять тактов на выход поступают пять проверочных символов и происходит обнуление регистра. Затем происходит кодирование следующей группы информационных символов.
Принятый декодером (рис. 12.23,б) входной сигнал запоминается регистром сдвига РС и одновременно через ключ К поступает на устройство деления УД, подобное тому, которое имеется в кодере. После поступления в УД 29-ти символов (блок данного кода) ключ К перебрасывается в нижнее положение и поступление входного сигнала на УД прекращается. Одновременно с выхода УД сигнал поступает на детектор ошибки. Если принятое кодовое слово не имеет ошибок, то на выходе УД имеется нулевой сигнал, что и фиксирует детектор, разрешая без коррекции информационным символам покидать РС через сумматор
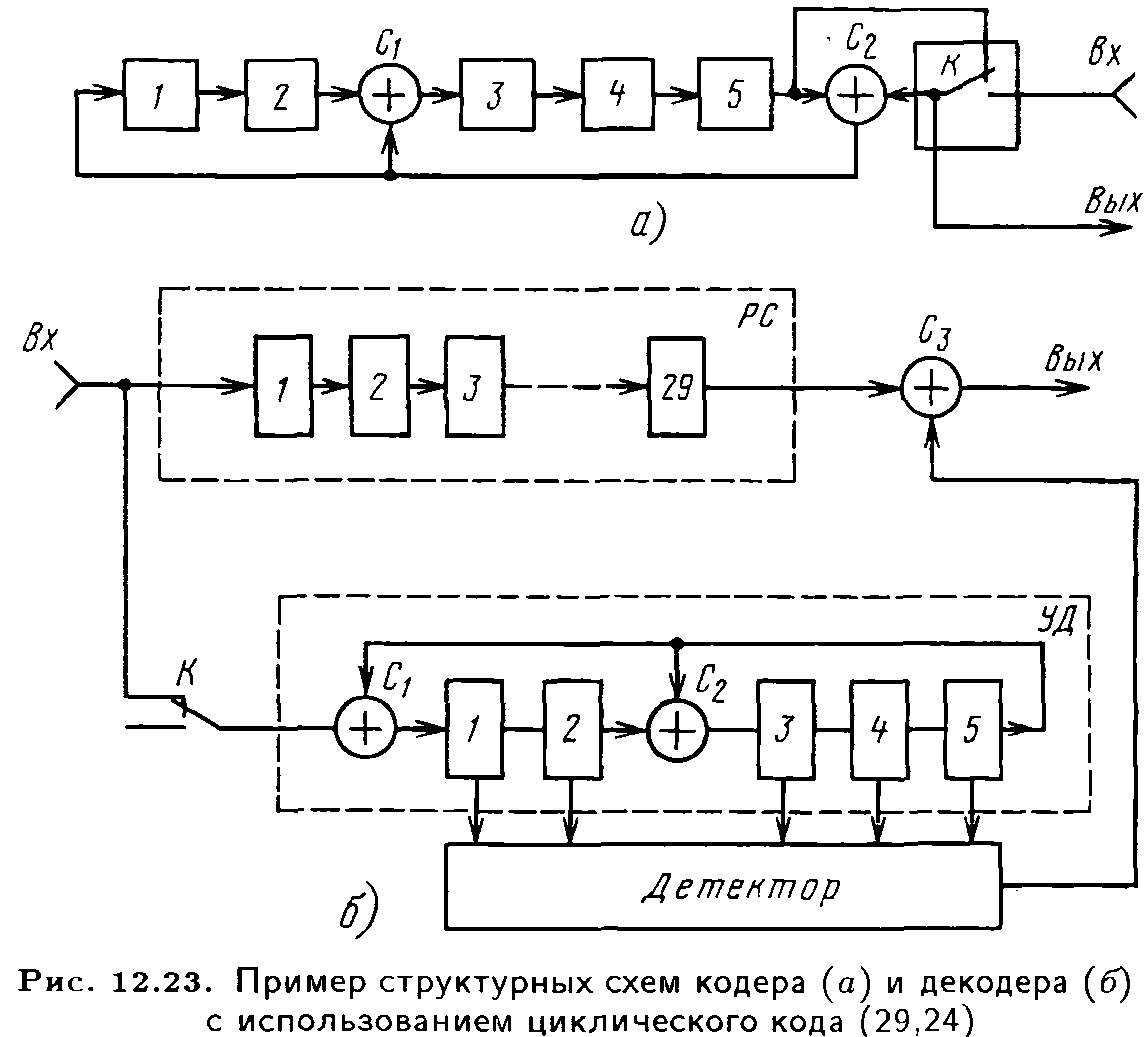
С3. Если принято ошибочное кодовое слово, то на выходе УД имеется ненулевой сигнал. В этом случае продолжающийся тактовый сдвиг разрядов сигнала в регистре УД приводит к появлению кодового слова, соответствующего эталонному полиному. В тот же момент в детекторе формируется исправляющий сигнал, который соответствует положению ошибки в информационных символах, проходящих через сумматор С3 Исправляющий символ, поступающий от детектора ошибок, исправляет ошибочный информационный символ.
Подклассом циклических кодов являются широко распространенные коды БЧХ (Боуза–Чоудхори-Хоквингема). Для них справедливо правило: для любых значений s и q < (2s – 1)/2 существует двоичный циклический код длиной п= 2s –1, исправляющий все комбинации из ^ или меньшего числа ошибок и содержащий не более чем sq проверочных символов. Так, код БЧХ (63,44), используемый в системе спутникового цифрового радиовещания, позволяет исправить две или три ошибки, обнаружить и замаскировать пять или четыре ошибки на каждый кодовый блок из 63 символов. При вероятности ошибки pош =10-3 означает появление одной необнаруженной ошибки в час. Избыточность данного кода составляет R = (63 - 44)/63 = 0,33 (33 %). Такой же избыточностью обладают и циклические коды Рида-Соломона. Двойной код Рида-Соломона с перемежением символов (CIRC-код) как наиболее эффективный при исправлении ошибок большой кратности нашел применение в системе компакт-диска и цифровой магнитной записи.
В последнее время стали использоваться также сверточные коды. В них обрабатывается непрерывная последовательность символов без разделения ее на независимые блоки. Поверочные символы в каждой группе из nо символов сверточного кода определяются не только kо информационными символами этой группы, но и информационными символами предшествующих групп. Поэтому он не является блочным кодом длины nо. Недостатком сверточных кодов является возможное размножение ошибок, т.е. появление нескольких ошибок на выходе декодера, если одиночные ошибки оказались не исправленными при декодировании. Сверточные коды в сочетании с двойным кодом Рида-Соломона с перемежением символов предлагается использовать в системе непосредственного цифрового радиовещания.
Перемежение символов. Этот способ широко применяется для защиты от пакетов ошибок длиной в сотни разрядов, например в аппаратуре цифровой записи сигналов. В принципе имеются три возможности перемежения: перемежение разрядов в пределах кодового слова, соответствующего одному отсчету ЗС, перемежение между разрядами разных отсчетов сигнала 3В и рассредоточенное размещение цифрового сигнала в канальных интервалах цикла цифровой системы передачи.
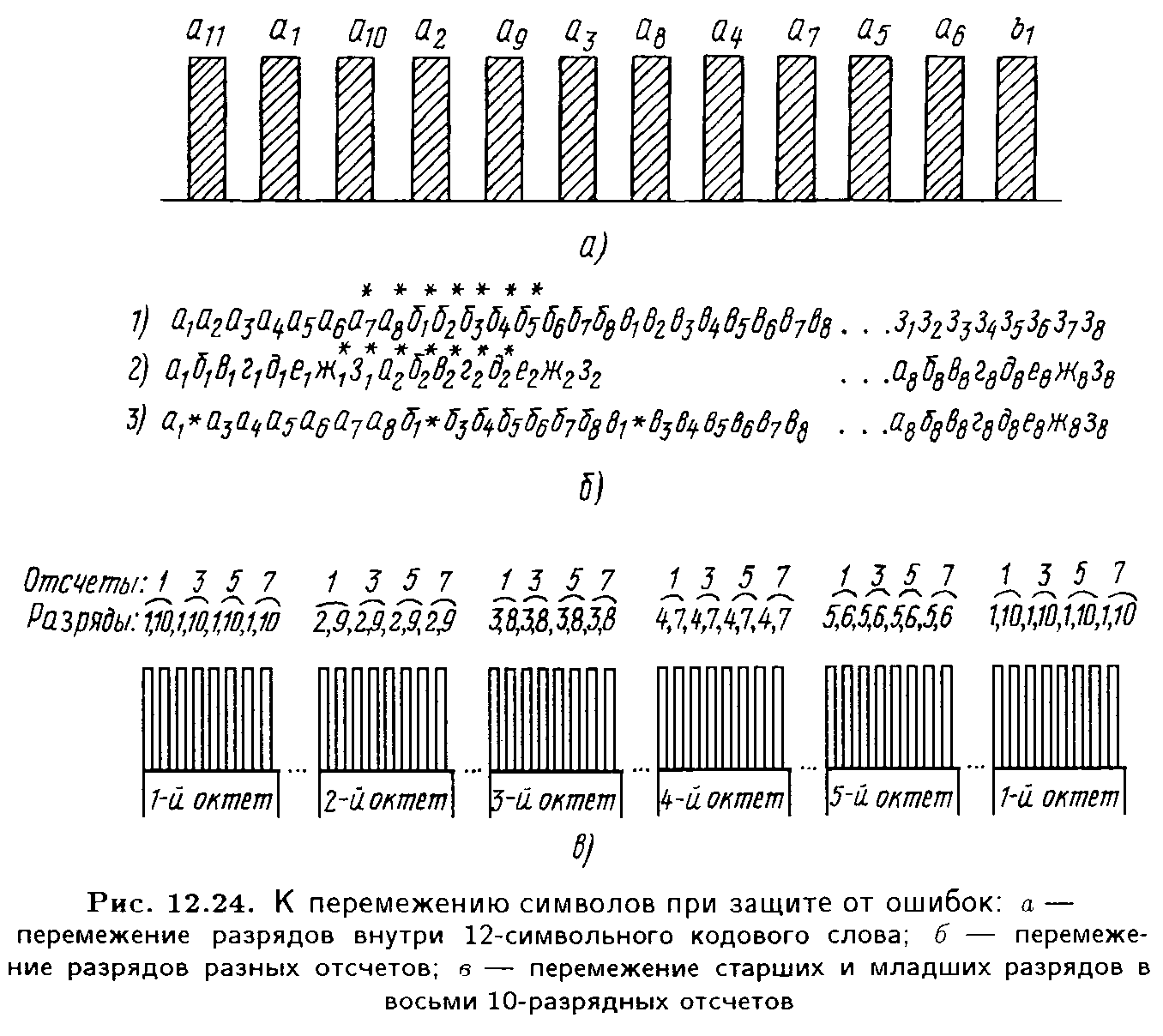
Перемежение старших и младших разрядов в пределах одного отсчета используется очень часто. При этом младшие разряды, число которых обычно равно или составляет более половины всех разрядов отсчета, размещаются равномерно между старшими разрядами (рис. 12.24,а) Здесь кодовое слово является 12-символьным, из которых 11 информационных разрядов (а1, а2,..., а11) и один (b1) – поверочный, определяемый как сумма по модулю 2 пяти старших информационных разрядов (а1, а2,..., а5). Поверочный разряд находится на последней позиции, а самый младший 11-й разряд – на первой.
В этом случае пакеты ошибок, состоящие из двух символов, и около 40 % пакетов ошибок длительностью в три символа приводят к появлению одиночной (односимвольной) ошибки на выходе декодера.
Перемежение разрядов разных отсчетов сигнала в принципе позволяет исправлять пакеты ошибок любой длительности. Ошибки здесь также преобразуются в одиночные (рис. 12.24,б). На строке 1 условно записана исходная последовательность кодовых слов по восемь символов в каждом. Символы кодовых слов обозначены буквами от а до ж с цифровыми индексами, определяющими порядковый номер (место) разряда в слове. Перед передачей или записью порядок следования символов в последовательности изменяется, например, так, как это показано в строке 2. В начале передаются первые разряды всех кодовых слов, затем вторые, третьи и т.д. При приеме (воспроизведении) порядок следования символов восстанавливается (строка 3 на рис. 12.24,б). Пусть при передаче или считывании возник пакет ошибок в этой последовательности. Места ошибок обозначены звездочками. В отсутствии перемежения (строка 1) эти ошибки исказят подряд символы а7, а8, б1, б2, б3, б4, б5. Если же пакет ошибок возник у сигнала, подвергнутого перемежению (строка 2), то из строки 3 видно, что после операции, обратной перемежению, пакет ошибок превратился в совокупность одиночных ошибок, с которым можно бороться уже описанными выше способами.
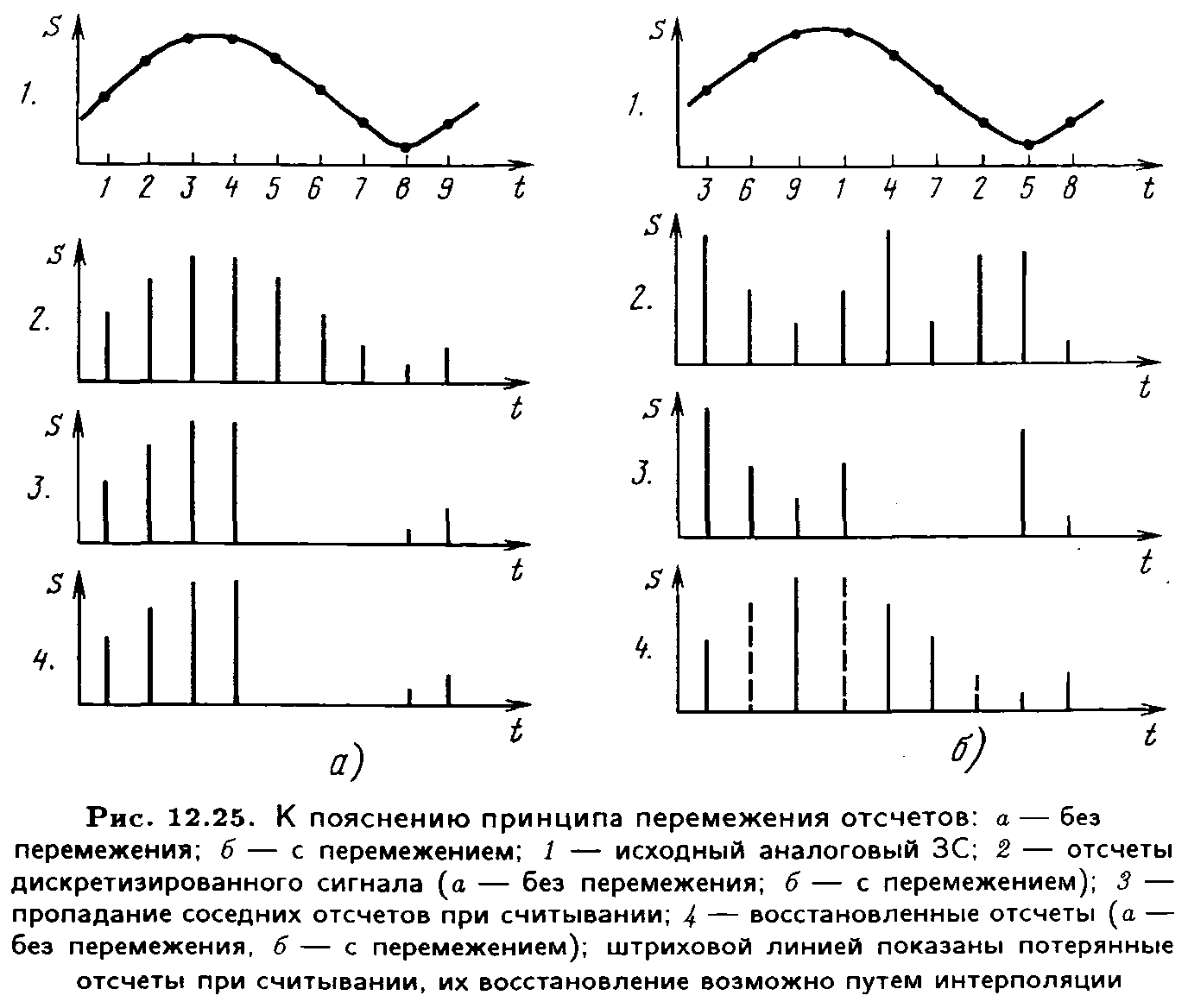
Благодаря перемежению ошибочно восстановленные отсчеты уже не следуют друг за другом (рис. 12.25,б), поэтому они могут быть скорректированы путем интерполяции, о которой говорилось уже выше.
При отсутствии перемежения после считывания в восстановленном сигнале (рис. 12.25,а,4) появился бы ряд отсутствующих отсчетов. Рисунок не требует дополнительного пояснения.
Эффективность данного метода особенно высока, если перемежение символов в пределах одного блока информации дополняется перемежением самих блоков, как это, например, принято в цифровых магнитофонах. Однако при исправлении пакетов ошибок большой длительности усложняются устройства перемежения в связи с необходимостью запоминать большое число отсчетов. Кроме того, увеличиваются длина цикла передачи и время задержки сигнала.
Размещение цифрового ЗС в канальных интервалах цикла цифровой системы передачи обычно производят емкостью в один октет. Для примера на рис. 12.24,в показано перемежение восьми 10-разрядных отсчетов. В первом октете размещены 1-й и 10-й разряды первых четырех нечетных отсчетов, во втором октете – 2-й и 9-й разряды тех же отсчетов и т.д. Затем подобным же образом перемежаются разряды четырех четных отсчетов. При разделении отсчетов на четные и нечетные пакет ошибок длительностью в восемь символов не приводит к одновременному искажению соседних отсчетов. Последнее позволяет использовать далее интерполяцию нулевого или первого порядка при коррекции восстановленных отсчетов.