

Формат команды процессора i486 и адресация операндов
.doc28. Формат команды процессора i486 и адресация операндов.
Пространство памяти предназначено для хранения кодов команд и данных, для доступа к которым имеется богатый выбор методов адресации (около 24). Операнды могут находиться во внутренних регистрах процессора (наиболее удобный и быстрый вариант). Они могут располагаться в системной памяти (самый распространенный вариант). Наконец, они могут находиться в устройствах ввода/вывода (наиболее редкий случай). Определение места положения операндов производится кодом команды. Причем существуют разные методы, с помощью которых код команды может определить, откуда брать входной операнд и куда помещать выходной операнд. Эти методы называются методами адресации. Эффективность выбранных методов адресации во многом определяет эффективность работы всего процессора в целом.
Прямая или абсолютная адресация. Физический адрес операнда содержится в адресной части команды. Формальное обозначение:
Операндi = (Аi),
где Аi – код, содержащийся в i-м адресном поле команды.

Рис. 9.1 Прямая адресация
Пример: mov al,[2000] – передать операнд, который содержится по адресу 2000h в регистр AL.
Add R1,[1000] – сложить содержимое регистра R1 с содержимым ячейки памяти по адресу 1000h и результат переслать в R1.
Допускается использование прямой адресации при обращении, как к основной, так и к регистровой памяти.
Непосредственная адресация. В команде содержится не адрес операнда, а непосредственно сам операнд.
Операндi= Аi.
![]()
Рис. 9.2 Непосредственная адресация
Непосредственная адресация позволяет повысить скорость выполнения операции, так как в этом случае вся команда, включая операнд, считывается из памяти одновременно и на время выполнения команды хранится в процессоре в специальном регистре команд (РК). Однако при использовании непосредственной адресации появляется зависимость кодов команд от данных, что требует изменения программы при каждом изменении непосредственного операнда.
Пример: mov eax,0f0f0f0f0 – загрузить константу 0f0f0f0f0h в регистр eax.
Косвенная (базовая) адресация. Адресная часть команды указывает адрес ячейки памяти (рис. 7.3,а) или номер регистра (рис. 7.3,б), в которых содержится адрес операнда:
Операндi = ((Аi)).

Рис. 9.3 Косвенная адресация
Применение косвенной адресации операнда из оперативной памяти при хранении его адреса в регистровой памяти существенно сокращает длину поля адреса, одновременно сохраняя возможность использовать для указания физического адреса полную разрядность регистра. Недостаток этого способа – необходимо дополнительное время для чтения адреса операнда. Вместе с тем он существенно повышает гибкость программирования. Изменяя содержимое ячейки памяти или регистра, через которые осуществляется адресация, можно, не меняя команды в программе, обрабатывать операнды, хранящиеся по разным адресам. Косвенная адресация не применяется по отношению к операндам, находящимся в регистровой памяти.
Пример: mov al,[ecx] – передать в регистр AL операнд (содержимое) ячейки памяти, адрес которой находится в регистре ECX.
Предоставляемые косвенной адресацией возможности могут быть расширены, если в системе команд ЭВМ предусмотреть определенные арифметические и логические операции над ячейкой памяти или регистром, через которые выполняется адресация, например увеличение или уменьшение их значения на единицу (и не только на 1).
В этом случае речь идет о базовой адресации со смещением.
Пример: mov eax,[eci+4] – передать в EAX операнд, который содержится по адресу ECI со смещением плюс 4.
Иногда, адресация, при которой после каждого обращения по заданному адресу с использованием механизма косвенной адресация, значение адресной ячейки автоматически увеличивается на длину считываемого операнда, называется автоинкрементной. Адресация с автоматическим уменьшением значения адресной ячейки называется автодекрементной.
Регистровая адресация. Предполагается, что операнд находится во внутреннем регистре процессора.
Например: mov eax,cr0 – передать в EAX содержимое CR0 или
mov ecx,ecx – сбросить регистр ECX.
Индексная адресация (со смещением) – содержимое РОН используется в качестве компоненты эффективного адреса (как правило, работа с массивами).
Пример: sub array [esi],2 – вычесть 2 из элемента массива, на который указывает регистр ESI.
Относительная адресация. Этот способ используется тогда, когда память логически разбивается на блоки, называемые сегментами. В этом случае адрес ячейки памяти содержит две составляющих: адрес начала сегмента (базовый адрес) и смещение адреса операнда в сегменте. Адрес операнда определяется как сумма базового адреса и смещения относительно этой базы:
Операндi = (базаi + смещениеi).
Для задания базового адреса и смещения могут применяться ранее рассмотренные способы адресации. Как правило, базовый адрес находится в одном из регистров регистровой памяти, а смещение может быть задано в самой команде или регистре.
Рассмотрим два примера.
Адресное поле команды состоит из двух частей, в одной указывается номер регистра, хранящего базовое значение адреса (начальный адрес сегмента), а в другом адресном поле задается смещение, определяющее положение ячейки относительно начала сегмента. Именно такой способ представления адреса обычно и называют относительной адресацией.

Рис. 9.4 Относительная адресация
Первая часть адресного поля команды также определяет номер базового регистра, а вторая содержит номер регистра, в котором находится смещение. Такой способ адресации чаще всего называют базово-индексным.

Рис. 9.5 Базово-индексная адресация
Главный недостаток относительной адресации – большое время вычисления физического адреса операнда. Но существенное преимущество этого способа адресации заключается в возможности создания "перемещаемых" программ – программ, которые можно размещать в различных частях памяти без изменения команд программы. То же относится к программам, обрабатывающим по единому алгоритму информацию, расположенную в различных областях ЗУ. В этих случаях достаточно изменить содержимое базового адреса начала команд программы или массива данных, а не модифицировать сами команды. По этой причине относительная адресация облегчает распределение памяти при составлении сложных программ и широко используется при автоматическом распределении памяти в мультипрограммных вычислительных системах.
30. Кластерные архитектуры и проблема связи процессоров в кластерной системе
Кластерная архитектура
Кластер представляет собой два или больше компьютеров (часто называемых узлами), объединяемых при помощи сетевых технологий на базе шинной архитектуры или коммутатора и предстающих перед пользователями в качестве единого информационно-вычислительного ресурса. В качестве узлов кластера могут быть выбраны серверы, рабочие станции и даже обычные персональные компьютеры. Преимущество кластеризации для повышения работоспособности становится очевидным в случае сбоя какого-либо узла: при этом другой узел кластера может взять на себя нагрузку неисправного узла, и пользователи не заметят прерывания в доступе. Возможности масштабируемости кластеров позволяют многократно увеличивать производительность приложений для большего числа пользователей. технологий (Fast/Gigabit Ethernet, Myrinet) на базе шинной архитектуры или коммутатора. Такие суперкомпьютерные системы являются самыми дешевыми, поскольку собираются на базе стандартных комплектующих элементов ("off the shelf"), процессоров, коммутаторов, дисков и внешних устройств. Кластеризация может быть осуществлена на разных уровнях компьютерной системы, включая аппаратное обеспечение, операционные системы, программы-утилиты, системы управления и приложения. Чем больше уровней системы объединены кластерной технологией, тем выше надежность, масштабируемость и управляемость кластера.
Проблемы выполнения сети связи процессоров в кластерной системе.
Архитектура кластерной системы (способ соединения процессоров друг с другом) в большей степени определяет ее производительность, чем тип используемых в ней процессоров. Критическим параметром, влияющим на величину производительности такой системы, является расстояние между процессорами. Так, соединив вместе 10 персональных компьютеров, мы получим систему для проведения высокопроизводительных вычислений, проблема, однако, будет состоять в нахождении наиболее эффективного способа соединения стандартных средств друг с другом, поскольку при увеличении производительности каждого процессора в 10 раз производительность системы в целом в 10 раз не увеличится.
Рассмотрим для примера задачу построения симметричной 16-ти процессорной системы, в которой все процессоры были бы равноправны. Наиболее естественным представляется соединение в виде плоской решетки, где внешние концы используются для подсоединения внешних устройств.
Схема соединения процессоров в виде плоской решетки
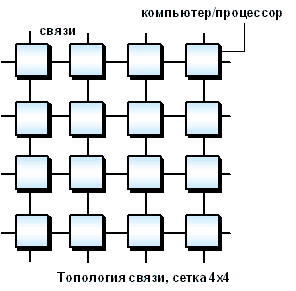
При таком типе соединения максимальное расстояние между процессорами окажется равным 6 (количество связей между процессорами, отделяющих самый ближний процессор от самого дальнего). Теория же показывает, что если в системе максимальное расстояние между процессорами больше 4, то такая система не может работать эффективно. Поэтому, при соединении 16 процессоров друг с другом плоская схема является не эффективной. Для получения более компактной конфигурации необходимо решить задачу о нахождении фигуры, имеющей максимальный объем при минимальной площади поверхности. В трехмерном пространстве таким свойством обладает шар. Но поскольку нам необходимо построить узловую систему, то вместо шара приходится использовать куб (если число процессоров равно 8) или гиперкуб, если число процессоров больше 8. Размерность гиперкуба будет определяться в зависимости от числа процессоров, которые необходимо соединить. Так, для соединения 16 процессоров потребуется 4-х мерный гиперкуб. Для его построения следует взять обычный 3-х мерный куб, сдвинуть в еще одном направлении и, соединив вершины, получить гиперкуб размером 4.
Примеры гиперкубов


Архитектура гиперкуба является второй по эффективности, но самой наглядной. Используются и другие топологии сетей связи: трехмерный тор, "кольцо", "звезда" и другие.
Архитектура кольца с полной связью по хордам (Chordal Ring)

Наиболее эффективной является архитектура с топологией "толстого дерева" (fat-tree). Архитектура "fat-tree" (hypertree) предложена Лейзерсоном (Charles E. Leiserson) в 1985 году. Процессоры локализованы в листьях дерева, в то время как внутренние узлы дерева скомпонованы во внутреннюю сеть. Поддеревья могут общаться между собой, не затрагивая более высоких уровней сети.
Кластерная архитектура "Fat-tree"

Кластерная архитектура "Fat-tree" (вид сверху на предыдущую схему)

Поскольку способ соединения процессоров друг с другом больше влияет на производительность кластера, чем тип используемых в ней процессоров, то может оказаться более рентабельным создать систему из большего числа дешевых компьютеров, чем из меньшего числа дорогих. В кластерах, как правило, используются операционные системы, стандартные для рабочих станций, чаще всего, свободно распространяемые - Linux, FreeBSD, вместе со специальными средствами поддержки параллельного программирования и балансировки нагрузки. При работе с кластерами, также как и с MPP системами, используют так называемую Massive Passing Programming Paradigm - парадигму программирования с передачей данных (чаще всего - MPI). Дешевизна подобных систем оборачивается большими накладными расходами на взаимодействие параллельных процессов между собой, что сильно сужает потенциальный класс решаемых задач.