

- •Advanced CORBA® Programming with C++
- •Review
- •Dedication
- •Preface
- •Prerequisites
- •Scope of this Book
- •Acknowledgments
- •Chapter 1. Introduction
- •1.1 Introduction
- •1.2 Organization of the Book
- •1.3 CORBA Version
- •1.4 Typographical Conventions
- •1.5 Source Code Examples
- •1.6 Vendor Dependencies
- •1.7 Contacting the Authors
- •Part I: Introduction to CORBA
- •Chapter 2. An Overview of CORBA
- •2.1 Introduction
- •2.2 The Object Management Group
- •2.3 Concepts and Terminology
- •2.4 CORBA Features
- •2.5 Request Invocation
- •2.6 General CORBA Application Development
- •2.7 Summary
- •Chapter 3. A Minimal CORBA Application
- •3.1 Chapter Overview
- •3.2 Writing and Compiling an IDL Definition
- •3.3 Writing and Compiling a Server
- •3.4 Writing and Compiling a Client
- •3.5 Running Client and Server
- •3.6 Summary
- •Part II: Core CORBA
- •Chapter 4. The OMG Interface Definition Language
- •4.1 Chapter Overview
- •4.2 Introduction
- •4.3 Compilation
- •4.4 Source Files
- •4.5 Lexical Rules
- •4.6 Basic IDL Types
- •4.7 User-Defined Types
- •4.8 Interfaces and Operations
- •4.9 User Exceptions
- •4.10 System Exceptions
- •4.11 System Exceptions or User Exceptions?
- •4.12 Oneway Operations
- •4.13 Contexts
- •4.14 Attributes
- •4.15 Modules
- •4.16 Forward Declarations
- •4.17 Inheritance
- •4.18 Names and Scoping
- •4.19 Repository Identifiers and pragma Directives
- •4.20 Standard Include Files
- •4.21 Recent IDL Extensions
- •4.22 Summary
- •Chapter 5. IDL for a Climate Control System
- •5.1 Chapter Overview
- •5.2 The Climate Control System
- •5.3 IDL for the Climate Control System
- •5.4 The Complete Specification
- •Chapter 6. Basic IDL-to-C++ Mapping
- •6.1 Chapter Overview
- •6.2 Introduction
- •6.3 Mapping for Identifiers
- •6.4 Mapping for Modules
- •6.5 The CORBA Module
- •6.6 Mapping for Basic Types
- •6.7 Mapping for Constants
- •6.8 Mapping for Enumerated Types
- •6.9 Variable-Length Types and _var Types
- •6.10 The String_var Wrapper Class
- •6.11 Mapping for Wide Strings
- •6.12 Mapping for Fixed-Point Types
- •6.13 Mapping for Structures
- •6.14 Mapping for Sequences
- •6.15 Mapping for Arrays
- •6.16 Mapping for Unions
- •6.17 Mapping for Recursive Structures and Unions
- •6.18 Mapping for Type Definitions
- •6.19 User-Defined Types and _var Classes
- •6.20 Summary
- •Chapter 7. Client-Side C++ Mapping
- •7.1 Chapter Overview
- •7.2 Introduction
- •7.3 Mapping for Interfaces
- •7.4 Object Reference Types
- •7.5 Life Cycle of Object References
- •7.6 Semantics of _ptr References
- •7.7 Pseudo-Objects
- •7.8 ORB Initialization
- •7.9 Initial References
- •7.10 Stringified References
- •7.11 The Object Pseudo-Interface
- •7.12 _var References
- •7.13 Mapping for Operations and Attributes
- •7.14 Parameter Passing Rules
- •7.15 Mapping for Exceptions
- •7.16 Mapping for Contexts
- •7.17 Summary
- •Chapter 8. Developing a Client for the Climate Control System
- •8.1 Chapter Overview
- •8.2 Introduction
- •8.3 Overall Client Structure
- •8.4 Included Files
- •8.5 Helper Functions
- •8.6 The main Program
- •8.7 The Complete Client Code
- •8.8 Summary
- •Chapter 9. Server-Side C++ Mapping
- •9.1 Chapter Overview
- •9.2 Introduction
- •9.3 Mapping for Interfaces
- •9.4 Servant Classes
- •9.5 Object Incarnation
- •9.6 Server main
- •9.7 Parameter Passing Rules
- •9.8 Raising Exceptions
- •9.9 Tie Classes
- •9.10 Summary
- •Chapter 10. Developing a Server for the Climate Control System
- •10.1 Chapter Overview
- •10.2 Introduction
- •10.3 The Instrument Control Protocol API
- •10.4 Designing the Thermometer Servant Class
- •10.5 Implementing the Thermometer Servant Class
- •10.6 Designing the Thermostat Servant Class
- •10.7 Implementing the Thermostat Servant Class
- •10.8 Designing the Controller Servant Class
- •10.9 Implementing the Controller Servant Class
- •10.10 Implementing the Server main Function
- •10.11 The Complete Server Code
- •10.12 Summary
- •Chapter 11. The Portable Object Adapter
- •11.1 Chapter Overview
- •11.2 Introduction
- •11.3 POA Fundamentals
- •11.4 POA Policies
- •11.5 POA Creation
- •11.6 Servant IDL Type
- •11.7 Object Creation and Activation
- •11.8 Reference, ObjectId, and Servant
- •11.9 Object Deactivation
- •11.10 Request Flow Control
- •11.11 ORB Event Handling
- •11.12 POA Activation
- •11.13 POA Destruction
- •11.14 Applying POA Policies
- •11.15 Summary
- •Chapter 12. Object Life Cycle
- •12.1 Chapter Overview
- •12.2 Introduction
- •12.3 Object Factories
- •12.4 Destroying, Copying, and Moving Objects
- •12.5 A Critique of the Life Cycle Service
- •12.6 The Evictor Pattern
- •12.7 Garbage Collection of Servants
- •12.8 Garbage Collection of CORBA Objects
- •12.9 Summary
- •Part III: CORBA Mechanisms
- •Chapter 13. GIOP, IIOP, and IORs
- •13.1 Chapter Overview
- •13.2 An Overview of GIOP
- •13.3 Common Data Representation
- •13.4 GIOP Message Formats
- •13.5 GIOP Connection Management
- •13.6 Detecting Disorderly Shutdown
- •13.7 An Overview of IIOP
- •13.8 Structure of an IOR
- •13.9 Bidirectional IIOP
- •13.10 Summary
- •14.1 Chapter Overview
- •14.2 Binding Modes
- •14.3 Direct Binding
- •14.4 Indirect Binding via an Implementation Repository
- •14.5 Migration, Reliability, Performance, and Scalability
- •14.6 Activation Modes
- •14.7 Race Conditions
- •14.8 Security Considerations
- •14.9 Summary
- •Part VI: Dynamic CORBA
- •Chapter 15 C++ Mapping for Type any
- •15.1 Chapter Overview
- •15.2 Introduction
- •15.3 Type any C++ Mapping
- •15.4 Pitfalls in Type Definitions
- •15.5 Summary
- •Chapter 16. Type Codes
- •16.1 Chapter Overview
- •16.2 Introduction
- •16.3 The TypeCode Pseudo-Object
- •16.4 C++ Mapping for the TypeCode Pseudo-Object
- •16.5 Type Code Comparisons
- •16.6 Type Code Constants
- •16.7 Type Code Comparison for Type any
- •16.8 Creating Type Codes Dynamically
- •16.9 Summary
- •Chapter 17. Type DynAny
- •17.1 Chapter Overview
- •17.2 Introduction
- •17.3 The DynAny Interface
- •17.4 C++ Mapping for DynAny
- •17.5 Using DynAny for Generic Display
- •17.6 Obtaining Type Information
- •17.7 Summary
- •Part V: CORBAservices
- •Chapter 18. The OMG Naming Service
- •18.1 Chapter Overview
- •18.2 Introduction
- •18.3 Basic Concepts
- •18.4 Structure of the Naming Service IDL
- •18.5 Semantics of Names
- •18.6 Naming Context IDL
- •18.7 Iterators
- •18.8 Pitfalls in the Naming Service
- •18.9 The Names Library
- •18.10 Naming Service Tools
- •18.11 What to Advertise
- •18.12 When to Advertise
- •18.13 Federated Naming
- •18.14 Adding Naming to the Climate Control System
- •18.15 Summary
- •Chapter 19. The OMG Trading Service
- •19.1 Chapter Overview
- •19.2 Introduction
- •19.3 Trading Concepts and Terminology
- •19.4 IDL Overview
- •19.5 The Service Type Repository
- •19.6 The Trader Interfaces
- •19.7 Exporting Service Offers
- •19.8 Withdrawing Service Offers
- •19.9 Modifying Service Offers
- •19.10 The Trader Constraint Language
- •19.11 Importing Service Offers
- •19.12 Bulk Withdrawal
- •19.13 The Admin Interface
- •19.14 Inspecting Service Offers
- •19.15 Exporting Dynamic Properties
- •19.16 Trader Federation
- •19.17 Trader Tools
- •19.18 Architectural Considerations
- •19.19 What to Advertise
- •19.20 Avoiding Duplicate Service Offers
- •19.21 Adding Trading to the Climate Control System
- •19.22 Summary
- •Chapter 20. The OMG Event Service
- •20.1 Chapter Overview
- •20.2 Introduction
- •20.3 Distributed Callbacks
- •20.4 Event Service Basics
- •20.5 Event Service Interfaces
- •20.6 Implementing Consumers and Suppliers
- •20.7 Choosing an Event Model
- •20.8 Event Service Limitations
- •20.9 Summary
- •Part VI: Power CORBA
- •Chapter 21. Multithreaded Applications
- •21.1 Chapter Overview
- •21.2 Introduction
- •21.3 Motivation for Multithreaded Programs
- •21.4 Fundamentals of Multithreaded Servers
- •21.5 Multithreading Strategies
- •21.6 Implementing a Multithreaded Server
- •21.7 Servant Activators and the Evictor Pattern
- •21.8 Summary
- •22.1 Chapter Overview
- •22.2 Introduction
- •22.3 Reducing Messaging Overhead
- •22.4 Optimizing Server Implementations
- •22.5 Federating Services
- •22.6 Improving Physical Design
- •22.7 Summary
- •Appendix A. Source Code for the ICP Simulator
- •Appendix B. CORBA Resources
- •Bibliography

IT-SC book: Advanced CORBA® Programming with C++
CORBA does not have a built-in mechanism that lets a server detect when a client loses interest in an object. In particular, CORBA does not provide automatic distributed garbage collection. If you require such a mechanism, you must implement it yourself (we discuss some options for doing this in Chapter 12).
18.8 Pitfalls in the Naming Service
Following are some pitfalls you may encounter when using the Naming Service. You should avoid these snares because they compromise portability. (Different implementations of the Naming Service may have different behavior.)
Nil references As mentioned on page 787, the OMG Naming Service permits you to advertise a nil reference even though it is rather pointless. You should make it a habit never to advertise nil references. However, you cannot rely on other developers exercising the same diligence, so when you resolve a name, it is good practice to test whether the reference returned by resolve is nil.
Transient references You should advertise only persistent references in the Naming Service. If you advertise transient references and your server shuts down, the bindings created by the server will dangle and make life difficult for clients.
Unusual names The Naming Service specification places no restrictions on the characters that can be contained in a name component, and it even permits the empty string as a legal value of the id and kind fields. Despite this, you should restrict yourself to simple names composed of printable characters and should avoid metacharacters such as "*," "?,""/," "," and "'" because some implementations have problems handling such characters correctly. In addition, if you avoid metacharacters it is easier to use command-line tools to administer the service.
Orphaned contexts Take care when destroying a context. You must both destroy the context and unbind it from its parent context. Failure to destroy the context leaves an orphaned context, and failure to unbind the context leaves a dangling binding. Be careful to use the correct name for rebind, and avoid using rebind_context.
Iterator pileup If you iterate over a naming context, make sure that you call destroy when you are finished with the iterator. This practice makes life easier for the server because you are not tying up server-side resources for longer than necessary. If you create an iterator, use it promptly. This minimizes the likelihood of having your iterator destroyed if the server encounters a resource shortage.
Iterator lifetime Although the specification does not require this, most implementations of the Naming Service are likely to use a POA with the TRANSIENT policy for iterators. This means that you cannot expect iterator references to survive shut-down of the Naming Service.
699

IT-SC book: Advanced CORBA® Programming with C++
Implementation limits Many implementations of the Naming Service have restrictions on the length of a name component or the number of bindings per context. If you expect to be able to store a name component containing a 1MB id field, you may well stretch the implementation beyond its design limits. Similarly, if you create a million bindings in the same context, you may exceed an implementation limit or end up with very poor performance.
Another aspect worth examining is the scalability of the service. Some implementations give very good performance even if you have millions of bindings stored in the service, whereas others bog down and perform poorly when there are more than a few thousand bindings. If you need your Naming Service to store large numbers of references, inquire with the vendor to see whether the implementation meets your needs.
Intervendor federation If you federate Naming Services from different vendors, you must check that all services can store all the names you use. If one vendor places limits on the characters that may occur in a name component or on the maximum length of a component, you may encounter interoperability problems between the implementations.
18.9 The Names Library
The OMG Naming Service specification also describes a Names Library. The interface to the Names Library (expressed in pseudo-IDL) allows you to treat names as programming language objects. However, name objects are implemented as library code and cannot be sent over the wire, so their use is limited to the local address space.
The Names Library adds almost no value to the functionality of the basic Naming Service IDL, so we do not show its use (see [21] for the complete definition). Also, not all vendors provide an implementation of the Names Library, so you should probably avoid using it.[7]
[7]The revised Naming Service will most likely drop the Names Library.
18.10Naming Service Tools
Vendors usually provide a number of tools with their Naming Service. Typically, these tools include one or more clients that allow you to manipulate the naming graph from the command line. Such tools are useful for system administration and for use in installation scripts. Some vendors also provide tools that allow you to locate and rebind orphaned contexts and to detect dangling bindings. In addition, some vendors provide a tool that allows you to manipulate a naming graph via a graphical user interface that is similar to a file manager.
Naming Service tools are not required or specified by CORBA, so we do not cover them here. However, you should take a close look at the level of tool support if you decide to buy a Naming Service. As is typical for infrastructure software, the tools provided by your vendor can be as important as the infrastructure itself.
700
IT-SC book: Advanced CORBA® Programming with C++
18.11 What to Advertise
Clearly, the Naming Service allows you advertise your application objects. The question is, which objects should you advertise? For example, for the climate control system you could simply advertise the controller object, or you could also choose to create a binding for each thermometer and thermostat. Either approach can be useful, and each has its advantages and disadvantages.
Advertising only the controller has the advantage of simplicity—there is less code to write. In addition, if the CCS server never talks to the Naming Service, performance will be better.
Advertising all devices in the Naming Service has the advantage that you need not provide collection manager operations, such as list and find. On the other hand, if you implement these operations yourself, they will likely be faster than the Naming Service because clients must communicate only with the CCS server instead of having to contact two servers. In addition, you can use efficient data structures for the implementation of list and find to make these operations very fast. However, the list and find operations are non-standard, whereas you can assume that all CORBA clients will be familiar with the Naming Service.
If you advertise all thermometers and thermostats in the Naming Service, you have a convenient way for clients to locate devices via a standard interface. If you have a very large number of devices, you can take advantage of a hierarchical context structure to provide various namespaces for different devices. If you require such a hierarchical arrangement, the Naming Service is probably a better choice than writing custom collection manager operations yourself. The additional development effort is rarely worth it.
The major drawback of advertising everything is the potential maintenance problem. If the CCS server crashes at the wrong moment, it may leave a binding to an already destroyed device in the Naming Service. Conversely, if the Naming Service crashes, the CCS server can no longer create or remove bindings. In that case, it is probably best for the CCS server to deny service; it should not allow clients to create or destroy devices until the Naming Service becomes available again. (Otherwise, any inconsistencies between which devices exist and which devices are advertised will become worse.)
Which option you choose for your applications depends on your requirements. Clearly, you can achieve the best reliability and performance by using the Naming Service as little as possible. Against this, you must consider the cost of providing equivalent functionality yourself.
Most applications advertise only a few key objects in the Naming Service and use customized collection manager operations (such as find) for other application objects. This design minimizes dependence on the Naming Service and avoids the problems that can be caused by dangling bindings, and that in turn simplifies error recovery.
701

IT-SC book: Advanced CORBA® Programming with C++
One way to deal with dangling bindings is to write your clients so that they unbind dangling references. When a client receives an object reference from the service, it invokes a ping operation on the object (see page 255). If the operation raises OBJECT_NOT_EXIST, the client removes the binding. You can also periodically ping objects that are bound into the Naming Service by using a separate client program written especially for that purpose (some vendors provide a tool that does this).
As almost always in distributed systems design, there are no hard and fast rules, only guidelines. Ultimately, you must make your own decision depending on your requirements.
18.12 When to Advertise
Exactly when to add and remove advertisements for your objects again depends on which objects you advertise. If you advertise only a few key objects, it is typically easiest to do it once only during installation and configuration of your software. For added safety, you can also provide a simple tool that re-creates the bindings for an installed application, thereby enabling recovery from corruption of or loss of the Naming Service.
If you advertise all your objects, it is typically best to link the creation and removal of bindings to the life cycle operations for the objects. For example, in the climate control system, the factories for thermometers and thermostats can also take care of advertising each object in the Naming Service, and the remove operation can call unbind to ensure that the name for an object disappears from the Naming Service when the object is destroyed. However, if you care about robustness, this approach also requires an errorhandling strategy to deal with a non-functional Naming Service. (Typically, it is easiest to raise an exception and deny service if a factory or remove operation cannot reach the Naming Service.)
18.13 Federated Naming
Each binding in the Naming Service is provided by an IOR, so you can easily create a federated service. A federated service provides a single logical service to clients but consists of a number of physical servers, possibly in different remote locations. Federated services offer a number of advantages.
Each server in a federation provides a subset of the complete graph. This arrangement improves reliability because if a single server fails, only bindings in the failed server become inaccessible. The portions of the graph maintained by other servers in the federation are still visible to clients.
Servers in a federation share the processing load of the logical service. This improves performance because different servers can work in parallel to resolve bindings on behalf of different clients.
702
IT-SC book: Advanced CORBA® Programming with C++
Federated servers spread the persistent storage for the graph over a number of machines, and that improves scalability.
Federation of a service permits you to maintain distinct administrative domains while still providing a single logical service. For example, all the names for objects in each part of an organization can be stored locally in each organization's Naming Service, but the names for objects in all parts of the organization are visible to clients.
To federate servers, you must get a reference to the initial naming context of one server across to another server. The question is, how do you achieve this? If the two servers are in different administrative domains and if no references exist from one domain into other, you cannot use a remote CORBA call to copy a reference from one domain into the other. The answer is that at least once, you must copy a stringified reference for an initial naming context across domains by out-of-band means, such as e-mail. After you have created the first binding from one Naming Service to another, further references become available across domains via the now federated Naming Service.[8]
[8] The revised Naming Service will allow you to configure one ORB domain to access another domain's Naming Service without the need to exchange stringified references. Instead, knowledge of a machine name in the target domain will be sufficient.
18.13.1 Fully Connected Federation Structure
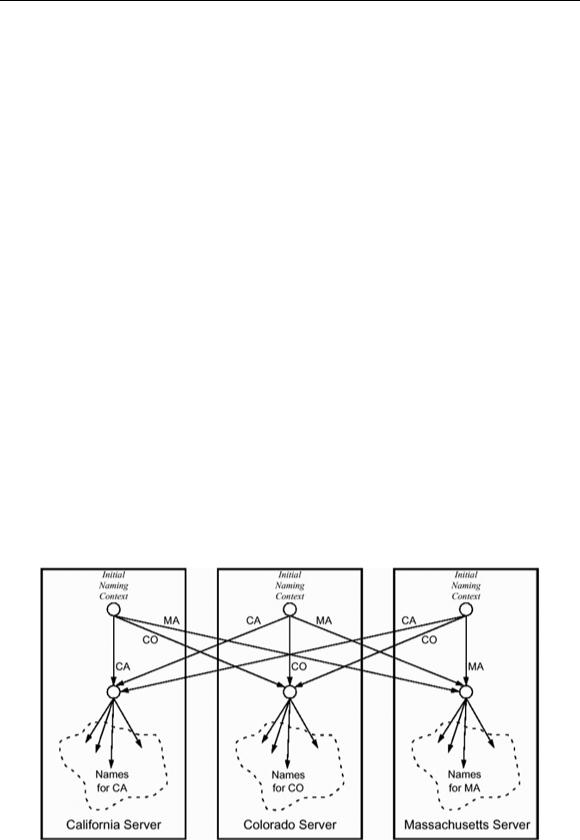
Figure 18.8 shows one way to provide a federated Naming Service. Assume that our famous Acme Corporation has branches in three states: California, Colorado, and Massachusetts. Each branch runs its own Naming Service, but clients want uniform names for all Acme objects regardless of their location.
Figure 18.8 Fully connected federation structure with uniform names.
With the configuration in Figure 18.8, each server's initial naming context contains a binding named with that server's location. In addition, each server contains bindings to its
703
IT-SC book: Advanced CORBA® Programming with C++
neighbors that are labeled with the neighbors' locations. The net effect is that the same name denotes the same object, regardless of which initial naming context is used.
Such a fully connected federation structure has the advantage that it provides uniform names to all clients. The major drawback is that it is difficult to administer: every time you add a new server, you must update all other servers in the federation. If there are more than five or so servers, maintenance becomes difficult because the number of crosslinks at the top level grows as O(n2).
18.13.2 Hierarchical Federation Structure
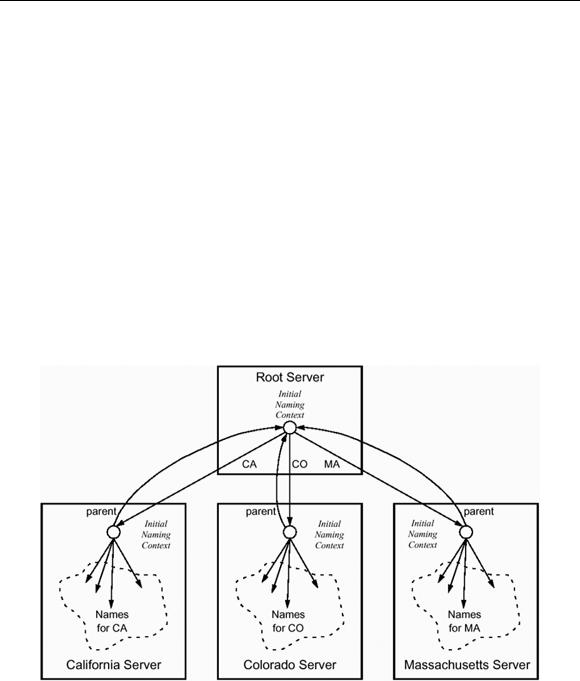
An alternative to a fully connected federation is to put servers into a hierarchical structure, as shown in Figure 18.9. A hierarchical structure is easier to maintain because you need to add only two bindings when you add a new server to the federation regardless of how many servers already exist in the federation.
Figure 18.9 Hierarchical naming structure.
In such a hierarchical structure, clients can still use the same name to denote the same object everywhere. However, clients must resolve names via the initial naming context of the root server and not via the initial naming context of their local server. This requirement can create a scalability problem because in a large federation, the root server can become a performance bottleneck. Hierarchical structures are also less resilient to failure than fully connected structures: if the root server fails, clients can no longer resolve names.
There is also the question of how clients get the initial naming context of the root server. In Figure 18.9, we have added parent bindings to the initial naming context of each
704
IT-SC book: Advanced CORBA® Programming with C++
regional server. Clients can use this binding to locate the root and then use root-relative names for all objects.
Despite their slightly worse reliability and performance, hierarchical federation structures are used more often than fully connected structures. In part, this stems from the fact that hierarchical structures do not suffer the maintenance problems of fully connected structures. In addition, many real-world naming systems are naturally hierarchical.
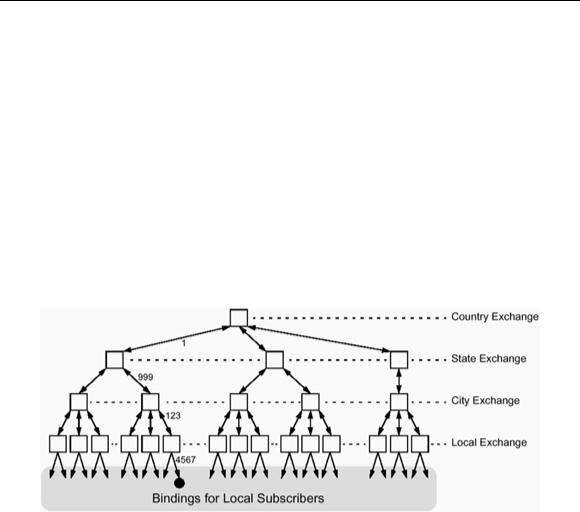
Telephone numbers are a classic example of hierarchical naming. You can model naming in such a hierarchy by installing naming servers at each level of the hierarchy, as shown in Figure 18.10. We show a path through the hierarchy corresponding to the number 1-999-123-4567.
Figure 18.10 Hierarchical structure modeling telephone exchanges.
In such a structure, each server's initial naming context also contains a parent binding up to the initial naming context of the next-higher server. We use doubleheaded arrows to show these bindings in Figure 18.10. In the downward direction, each binding is labeled with a number, whereas in the upward direction, each binding has the label parent.
When a subscriber dials a local number, the client uses the initial naming context of its local server to resolve it. If the number is not local, the client navigates via the parent bindings up to the server at the appropriate level and then uses the initial naming context of that server to resolve the number. The advantage of this arrangement is that local calls cause activity only in local servers, and only non-local calls involve servers higher up in the hierarchy. This improves both performance and fault tolerance. Servers at higher levels in the hierarchy are less likely to form a performance bottleneck, and failure of a high-level server does not prevent resolving of bindings for local calls.
18.13.3 Hybrid Structures
There is nothing to prevent you from arranging federated servers into topologies other than fully connected or tree structures. In fact, any arrangement of servers is allowed (you even can include loops in the federation structure). This flexibility is a major advantage
705