

5.2. Архитектура систем ввода-вывода
Существует два основных способа организации системы ввода вывода.
Прямой ввод-вывод (рис. 5.1).
Косвенный (канальный) ввод-вывод (рис. 5.2).

1 ОП

 Системная шина
Системная шина


 ЦП
ЦП

2



ОП Контроллер ВУ Контроллер ВУ








ВУ ВУ1 ВУ2 ВУ3

Механизм

Носитель информации
Рис.5.1
При прямом вводе-выводе работа внешних устройств и памяти управляется центральным процессором, и все они подключаются к одной системной шине, при этом в зависимости от варианта подключения памяти может быть: в случае 1 – одно пространство адресов памяти и портов внешних устройств, а в случае 2 – отдельные адреса обращения к памяти и внешним устройствам. Процесс взаимодействия внешних устройств и центральной части машины определяется интерфейсом ввода вывода, под которым понимается совокупность сигналов, линий связи и алгоритмов управления, обеспечивающих заданный протокол взаимодействия внешних устройств и процессора. Под протоколом понимается последовательность формирования прямых и квитирующих сигналов взаимодействия (ответный сигнал называется квитирующим).




ВУ1 ВУ2 ВУ3 ВУ4






Контроллер 1 Контроллер 2




 Канал
1
Канал
1
(Мультиплексный)


 ЦП
ОП
ЦП
ОП





 Канал
2 Контроллер ВУ
Канал
2 Контроллер ВУ
(Селекторный)
Рис. 5.2
На рис 5.2 показан процесс ввода-вывода по способу, называемому канальным.
Каналы делятся на следующие.
Мультиплексные (обслуживают много ВУ, но медленных).
Селекторные (обслуживают мало ВУ, но быстродействующих).
Отличительная особенность канального ввода-вывода - процессор освобождается от управления внешними устройствами, функция процессора заключается в инициализации запуска канальных программ и завершении операции ввода-вывода, выполняемой с помощью канала, по соответствующему признаку из канала (по существу это многопроцессорная система).
5.3. Способы выполнения операции передачи данных
На рис. 5.3 показаны способы выполнения передачи данных.

Передача данных
Синхронная Асинхронная
Несовмещенный Вв/выв по программному
вв/выв прерыванию
Вв/выв по аппаратному
п рерыванию
Рис 5.3
|
↓ |
← Команда вв/выв |
|
Передача 1 |
|
|
↓ |
← Команда вв/выв |
|
Переача 2 |
|
|
↓ |
|
Рис. 5.4
На рис. 5.4 показан самый быстрый способ передачи данных, но ненадежный – синхнонный
Организация выполнения условного и безусловного переходов.
a) Команда безусловного перехода
JMP операнд; 8086, безусловный переход
JMP передает управление в другую точку программы. Операндом может быть непосредственный адрес для перехода, а также регистр или переменная, содержащая адрес.
В зависимости от типа перехода различают:
переход типа short (короткий переход) – если адрес перехода находится в пределах от -127 до +128 байт от команды JMP;
переход типа near (ближний переход) – если адрес перехода находится в том же сегменте памяти, что и команда JMP;
переход типа far (дальний переход) – если адрес перехода находится в другом сегменте.
b) Команды условного перехода
Jcc операнд; 8086, переход по адресу, задаваемому операндом, если условие перехода сс истинно.
Команда Описание
JA Переход, если выше (CF = 0 и ZF = 0)
JAE Переход, если выше или равно (CF = 0)
JB Переход, если ниже (CF = 1)
JBE Переход, если ниже или равно (CF = 1 или ZF = 1)
JC Переход, если перенос (CF = 1)
JCXZ Переход, если регистр CX равен 0
JE Переход, если равно (ZF = 1)
JZ Переход, если 0 (ZF = 1)
JG Переход, если больше (ZF = 0 и SF = OF)
JGE Переход, если больше или равно (SF = OF)
JL Переход, если меньше (SF <> OF)
JLE Переход, если меньше или равно (ZF=1 или SF <> OF)
JNA Переход, если не выше (CF = 1 и ZF = 1)
JNAE Переход, если не выше или равно (CF = 1)
JNB Переход, если не ниже (CF = 0)
JNBE Переход, если не ниже или равно (CF=0 и ZF=0)
JNC Переход, если нет переноса (CF = 0)
JNE Переход, если не равно (ZF = 0)
JNG Переход, если не больше (ZF = 1 или SF <> OF)
JNGE Переход, если не больше или равно (SF <> OF)
JNL Переход, если не меньше (SF = OF)
JNLE Переход, если не меньше или равно (ZF=0 и SF=OF)
JNO Переход, если нет переполнения (OF=0)
JNP Переход, если нет контроля четности (PF = 0)
JP Переход, если контроль четности (PF = 1)
Команды условного перехода (за исключением команды JCXZ) проверяют флаги, которые были установлены предыдущей командой. Условия для каждой мнемонической формы команды даны в круглых скобках выше после каждого описания. Термины «меньше» и «больше» используются при сравнении целых со знаком; «выше» и «ниже» – для целых без знака. Если условие выполняется, то происходит переход по адресу, задаваемому операндом, иначе – выполняется команда, следующая за командой условного перехода. Использование данной команды наиболее эффективно, когда цель условного перехода находится в текущем кодовом сегменте и в пределах от -128 до +127 байт относительно первого байта следующей команды. Если цель команды условного перехода находится за пределами -128 до +127 байт относительно первого байта следующей команды, используйте команду с противоположным условием перехода в сочетании с командой безусловного перехода.
Команда JCXZ отличается от других команд условного перехода тем, что она проверяет не флаги, а содержимое регистра CX на равенство 0. Команда JCXZ полезна в начале условного цикла, который заканчивается командой условного перехода к началу цикла (например, LOOPNE метка цели). Команда JCXZ предотвращает нахождение в цикл при регистре CX, равном нулю, что может привести к выполнению цикла 64К раз вместо нуля раз.
Деление адресного пространства (обращение к ЗУ и к УВВ).
Внешние запоминающие устройства (ВЗУ) предназначены и широко применяются для запоминания, хранения и выдачи больших объёмов информации, таких как данные о нагрузке и ее изменениях, данные о повреждениях и т. д., поэтому ВЗУ называют накопителями. В качестве ВЗУ в настоящее время в основном используют накопители на магнитных лентах и на магнитных дисках.
По способу доступа к ячейкам различают ЗУ с произвольным, последовательным и циклическим доступом. При произвольном доступе обращение к любой ячейке ЗУ осуществляется независимо от её расположения в ЗУ. К таким ЗУ относятся СОЗУ, ОЗУ и ПЗУ. Данный способ является наиболее гибким и совершенным по отношению ко всем остальным способам доступа. Он обеспечивает наименьшее время поиска адреса требуемой ячейки ЗУ.
При последовательном доступе обращение к заданной ячейке ЗУ происходит в порядке позиционного расположения адресов ячеек в подобных ЗУ. Типичным представителем ЗУ с последовательным доступом служит накопитель на магнитной ленте (НМЛ). При работе с НМЛ для обращения к заданной ячейке (или заданной области ЗУ) необходимо предварительно обратиться ко всем ячейкам (областям), лежащим между той, к которой произошло обращение в данный момент, и требуемой ячейкой (областью). При последовательном доступе время поиска требуемой ячейки (области) может иметь довольно значительную величину. В данном случае оно зависит от местоположения адресуемой ячейки (области) на НМЛ. Если адресуемая ячейка (область) находится близко к началу ленты, время поиска относительно невелико; если же адресуемая ячейка (область) расположена ближе к концу ленты, то время поиска сильно возрастает, поэтому время поиска в НМЛ оценивают по величине среднего значения.
При циклическом доступе нужная ячейка периодически появляется под записывающими (считывающими) головками и в момент её появления осуществляется запись в данную ячейку или считывание из неё. Такой способ применяется в ВЗУ - накопителях на магнитном диске (НМД). Так как НМД представляет собой совокупность дорожек, каждая из которых разделяется на секторы, то время поиска требуемой ячейки складывается из времени нахождения определенной дорожки и сектора и времени поиска в последнем нужной ячейки. Это время превышает время поиска информации при способе с произвольным доступом и значительно меньше, чем при способе с последовательным доступом.

Представление и форматы данных.

Целые числа
Целые числа могут занимать байт, слово или двойное слово. Они могут быть знаковыми и беззнаковыми. В знаковых целых самый старший бит байта, слова или двойного слова, занимаемого числом, отводится для индикации знака числа. Нуль соответствует плюсу, 1 — минусу. Таким образом, возможный диапазон представляемых значений для знаковых целых составляет: от –128 до +127 для байтовых величин, от –32768 до +32767 для слов, от –231 до 231-1 для двойных слов. Беззнаковые целые могут принимать значения: от 0 до 255 для байтовых величин, от 0 до 65535 для слов, от 0 до 232-1 для двойных слов.
Двоично-десятичные целые числа
Двоично-десятичные целые — это набор четырехбитовых беззнаковых величин, каждая из которых может принимать значения от 0 до 9. Двоично-десятичные числа могут быть в обычном или упакованном формате. Обычный формат использует только младшие четыре бита байта, в этом формате каждая цифра представляется одним байтом так же, как и целочисленные беззнаковые значения от 0 до 9. Упакованный формат предусматривает использование старших четырех бит байта для представления более старшей значащей цифры десятичного числа, т.е. в упакованном формате требуется в два раза меньше байт для представления десятичных чисел одинаковой разрядности.
Битовые поля
Битовые поля — это непрерывные последовательности битов, которые могут располагаться в любом месте памяти и начинаться с любого бита любого байта по любому адресу. Началом битового поля считается самый младший используемый бит самого младшего байта. Битовые поля могут иметь длину до 32 бит.
Строки
Строки — это непрерывные последовательности битов, байтов, слов или двойных слов в памяти. Битовые строки могут располагаться в любом месте памяти и начинаться с любого бита любого байта по любому алресу. Максимальная длина битовых строк 232-1 бит. Строки байт, слов и двойных слов могут занимать до 232-1 байт (4 Гб).
Стек, принципы его организации, запись в стек и чтение из стека
Стек – структура данных, в которой доступ к элементам организован по принципу «последний пришел - первый вышел». В выч. технике используется для отслеживания точек возврата из подпрограмм.
PUSH – положить элемент в стек; POP – получить элемент из стека.
В процессоре имеется специальный регистр для хранения адреса вершины стека – Указатель Стека. Он содержит адрес верхушки стека.
|
|
Запись в стек:
Чтение из стека:
|

Страничная организация памяти
Один из видов организации виртуальной памяти. Идея состоит в том, чтобы разбить всё виртуальное адресное пространство на фиксированные блоки – страницы (размер страницы зависит от конкретной реализации) и физическое адресное пространство на блоки такого же размера. В качестве одного из вариантов реализации стр. орг. памяти, можно хранить данные о
Одновременно в ОП находится фиксированное количество страниц, так называемое рабочее множество процесса. Это наиболее часто используемые процессом страницы.
При обращении к памяти транслятор (memory management unit) преобразует виртуальный адрес в физический. Если участок памяти находится на незагруженной странице, происходит ошибка отсутствия страницы. В этом случае из памяти выгружается некоторая страница (существуют различные алгоритмы её определения), на её место загружается требуемая, повторяется исполнение команды, вызвавшей ошибку. Этот механизм называется вызовом страниц по требованию.
В процессоре хранится таблица с описанием, какие страницы находятся в ОП, какие на диске. Виртуальный адрес состоит из номера страницы и смещения внутри страницы.
Организация прерываний в ЭВМ
Прерывание – это изменение в потоке управления, вызванное не самой программой, а внешними условиями. При возникновении прерывания выполнение текущей программы приостанавливается, и управление передаётся подпрограмме обработке прерывания. После завершения обработки, управление возвращается прерванной программе.
Примерный алгоритм возникновения и обработки прерывания:
Контроллер устройства выставляет на линию прерывания сигнал
ЦП, по мере готовности, выставляет на шине признак готовности к обработке
Контроллер выставляет на шину вектор прерывания
ЦП считывает его и сохраняет; запоминает в стеке текущее состояние
В таблице векторов прерываний ЦП считывает адрес подпрограммы обработки прерывания и записывает его в регистр команд
Выполняется программа обработки прерывания
Восстанавливается прежнее состояние
Данный алгоритм описывает одноуровневую систему прерываний. Существуют также многоуровневые системы. В них присутствует несколько линий прерывания, некоторые приоритетные, а также контроллер прерываний, обеспечивающий правильную работу по обработке.
Различают также программные и аппаратные прерывания (по способу их возникновения). В ЦП можно установить бит запрета прерываний.
При поиске источника прерывания может быть использован циклический опрос или опрос по приоритетам.
Взаимодействие центрального процессора и сопроцессора
Сопроцессор – отдельный специализированный процессор. Применяется для повышения быстродействия, выполняя сложные трудоёмкие операции (например, операции с плавающей точкой или работа с графикой). Может быть установлен в отдельном корпусе, в виде подключаемой платы или непосредственно на микросхеме.
Сопроцессор управляется ЦП. Он может выполнять как некоторые из команд ЦП, так и свои собственные.
Пример работы:
в специальные функционально ориентированные регистры ЦП записываются операнды
ЦП передаёт сопроцессору команду на обработку этих операндов
ЦП продолжает свою работу параллельно с работой сопроцессора
По завершению обработки данных, сопроцессор сообщает о завершении ЦП (прерывание, признак, …)
ЦП обрабатывает полученные от сопроцессора данные
КЭШ-память в иерархической системе памяти ЭВМ.
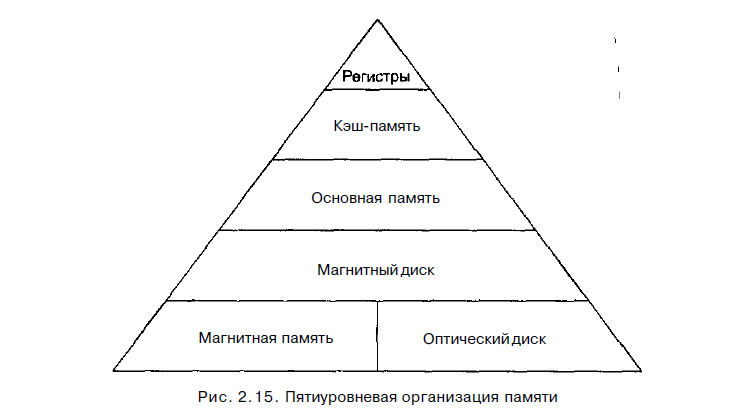
Иерархическая система памяти
Иерархическая структура памяти является традиционным решением проблемы
хранения большого количества данных Она изображена на рис. 2.15. На самом
верху находятся регистры процессора. Доступ к регистрам осуществляется быст-
рее всего. Дальше идет кэш-память, объем которой сейчас составляет от 32 Кбайт
до нескольких мегабайт. Затем следует основная память, которая в настоящее время может вмещать от 16 Мбайт до десятков гигабайтов. Далее идут магнитные
диски и, наконец, накопители на магнитной ленте и оптические диски, которые
используются для хранения архивной информации.
По мере продвижения по структуре сверху вниз возрастают три параметра. Во-
первых, увеличивается время доступа. Доступ к регистрам занимает несколько
наносекунд, доступ к кэш-памяти — немного больше, доступ к основной памяти —
несколько десятков наносекунд. Дальше идет большой разрыв: доступ к дискам
занимает по крайней мере 10 мке, а время доступа к магнитным лентам и оптичес-
ким дискам вообще может измеряться в секундах (поскольку эти накопители ин-
формации еще нужно взять и поместить в соответствующее устройство).
Во-вторых, увеличивается объем памяти. Регистры могут содержать в лучшем
случае 128 байтов, кэш-память — несколько мегабайтов, основная память — десятки
тысяч мегабайтов, магнитные диски — от нескольких гигабайтов до нескольких
десятков гигабайтов. Магнитные ленты и оптические диски хранятся автономно
от компьютера, поэтому их объем ограничивается только финансовыми возмож-
ностями владельца.
В-третьих, увеличивается количество битов, которое вы получаете за 1 доллар.
Стоимость объема основной памяти измеряется в долларах за мегабайт1, объем
магнитных дисков — в пенни за мегабайт, а объем магнитной ленты — в долларах за гигабайт или еще дешевле.
Организация кэш-памяти
Использование кэш-памяти основано на свойстве локальности программ, заключающемся в том, что в течение достаточно длительных интервалов времени исполняемая программа использует сравнительно небольшой диапазон адресов команд и/или небольшой диапазон адресов данных. Это обусловлено наличием в программе циклов и подпрограмм, а также необходимостью длительной обработки одного или нескольких массивов данных.
Идея использования кэша как буферной памяти заключается в наличии двух видов памяти:
быстрой памяти малой емкости М1 (n1, tобр1) и медленной памяти большой емкости М2 (n2, tобр2), параметры которых число ячеек - ni и время обращения tобрi характеризуются неравенствами:
n1 << n2 и t обр1 << t обр2.
Пусть 0 < << 1 – вероятность отсутствия данного в быстрой памяти (обычно 0.02…0.05). Тогда среднее время обращения для такой системы буферизованной памяти будет
М {t обр} = (1 - ) * t обр1 + * (t обр1 + t обр2) = t обр1 +* t обр2 t обр1
Если данные имеются в кэш-памяти, то они выбираются за время t обр1, а если отсутствуют, то за время t обр1 + t обр2; данные выбираются из основной памяти и одновременно подгружаются в кэш-память.
Применяется несколько способов отображения основной памяти на кэш-память.
КЭШ-память прямого отображения
Кэш с прямым отображение адресов
Отображение основной памяти на кэш-память происходит блоками. При прямом отображении адрес блока (строки) i кэш-памяти, на которую может быть отображен блок j ОП, однозначно определяется выражением i = j mod m , где m – общее число строк кэш-памяти. Пусть m = 128 и число блоков ОП равно 16384(14К), тогда на блок кэш-памяти с номером i будут отображаться 128 блоков ОП с номерами i , i +128, i +256, … , i +16256.
|
127 |
|
127, 255, 383, …, 16383 |
|
126 |
|
126, 254, 382, …, 16382 |
|
…
|
… |
… |
|
5 |
|
|
|
4 |
|
|
|
3 |
|
|
|
2 |
|
2, 130, 258, …, 16258 |
|
1 |
|
1, 129, 257, …, 16257 |
|
0 |
|
0, 128, 256, …, 16256 |
Строка Поле тегов Номера отображаемых блоков ОП
Для задания конкретного блока ОП из такой последовательности в кэш-памяти используется специальное поле тегов. В свою очередь, 14-битный адрес блока ОП разбивается на два поля: 7-битный тег (7 старших разрядов адреса) и 7-битный номер строки кэш-памяти, на которую может быть отображен этот блок ОП. При этом поле тега определяет, какой из списка блоков ОП, закрепленных за данной строкой кэша, сейчас адресуется. Когда блок ОП фактически заносится в соответствующую строку кэш-памяти, в поле тегов этой строки нужно записать тег именно этого блока, в качестве тега служат 7 старших разрядов адреса блока.
При несомненной простоте прямого отображения его существенным недостатком является жесткое закрепление строки кэша за определенными блоками ОП. Поэтому при поочередном обращении программы к словам из двух блоков, отображаемых на одну и ту же строку кэша, постоянно будет происходить обновление этой строки, резко снижающее скорость доступа к памяти. Кэш с прямым отображением ввиду своей экономичности используется для построения вторичных кэшей сравнительно большого объема.
КЭШ-память с множественным доступом
Как было сказано выше, различные строки основной памяти конкурируют за право занять одну и ту же область в кэш-памяти. Если программе, которая применяет кэш-память, изображенную на рис. 4.26, а, часто требуются слова с адресами 0 и 65 536, то будут иметь место постоянные конфликты и каждое обращение потенциально повлечет за собой вытеснение какой-то определенной строки кэш-памяти. Чтобы разрешить эту проблему, нужно сделать так, чтобы в каждом элементе кэш-памяти помещалось по две и более строк. Кэш-память с n возможными элементами для каждого адреса называется n-входовой ассоциативной кэш-памятью. Четырех-входовая ассоциативная кэш-память изображена на рис. 4.27.

Рис. 4.27. 4-входовая ассоциативная кэш-память
Ассоциативная кэш-память с множественным доступом по сути гораздо сложнее, чем кэш-память прямого отображения, поскольку хотя элемент кэш-памяти и
можно вычислить из адреса основной памяти, требуется проверить п элементов
кэш-памяти, чтобы узнать, есть ли там нужная нам строка. Тем не менее практика показывает, что двувходовая или четырехвходовая ассоциативная кэш-память
дает хороший результат, поэтому внедрение этих дополнительных схем вполне
оправданно.
Выбор элемента КЭШ-памяти для замены. Обновление КЭШ-памяти и основной памяти.
Использование ассоциативной кэш-памяти с множественным доступом ставит
разработчика перед выбором. Если нужно поместить новый элемент в кэш-память,
какой именно из старых элементов нужно убрать? Для многих целей хорошо под-
ходит алгоритм LRU (Least Recenly Used — алгоритм удаления наиболее давно
использовавшихся элементов). Имеется определенный порядок каждого набора
ячеек, которые могут быть доступны из данной ячейки памяти. Всякий раз, когда
осуществляется доступ к любой строке, в соответствии с алгоритмом список обновляется и маркируется элемент, к которому произведено последнее обращение.
Когда требуется заменить какой-нибудь элемент, убирается тот, который находится
в конце списка, то есть тот, который использовался давно по сравнению со всеми
другими.
Возможна также 2048-входовая ассоциативная кэш-память, которая содержит
один набор из 2048 элементов. Здесь все адреса памяти располагаются в этом наборе, поэтому при поиске требуется сравнивать нужный адрес со всеми 2048 тегами в кэш-памяти. Отметим, что для этого каждый элемент кэш-памяти должен
содержать специальную логическую схему. Поскольку поле ≪СТРОКА≫ в данный
момент имеет длину 0, поле ≪ТЕГ≫ — это весь адрес за исключением полей ≪СЛОВО≫
и ≪БАЙТ≫. Более того, когда строка кэш-памяти замещается, все 2048 ячеек являются возможными кандидатами на смену. Для сохранения упорядоченного списка
потребовался бы громоздкий учет использования системных ресурсов, поэтому
применение алгоритма LRU становится недопустимым. (Помните, что этот список следует обновлять при каждой операции с памятью.) Интересно, что кэш-память с высокой ассоциативностью часто не сильно превосходит по производительности кэш-память с низкой ассоциативностью, а в некоторых случаях работает даже хуже. Поэтому ассоциативность выше четырех встречается редко.
Наконец, особой проблемой для кэш-памяти является запись. Когда процессор записывает слово, а это слово находится в кэш-памяти, он, очевидно, должен или обновить слово, или отбросить данный элемент кэш-памяти. Практически во всех разработках используется обновление кэш-памяти. А что же можно сказать об обновлении копии в основной памяти? Эту операцию можно отложить на потом до того момента, когда строка кэш-памяти будет готова к замене алгоритмом LRU. Выбор труден, и ни одно из решений не является предпочтительным.
Немедленное обновление элемента основной памяти называется сквозной записью. Этот подход обычно гораздо проще реализуется, и к тому же, он более надежен, поскольку современная память всегда может восстановить предыдущее состояние, если произошла ошибка. К сожалению, при этом требуется передавать больший поток информации к памяти, поэтому в более сложных проектах стремятся использовать альтернативный подход — обратную запись.
С процессом записи связана еще одна проблема: а что происходит, если нужно
записать что-либо в ячейку, которая в текущий момент не находится в кэш-памяти? Должны ли данные переноситься в кэш-память или просто записываться в основную память? И снова ни один из ответов не является во всех отношениях лучшим. В большинстве разработок, в которых применяется обратная запись, данные переносятся в кэш-память. Эта технология называется заполнением по записи (write allocation). С другой стороны, в тех разработках, где применяется сквозная запись, обычно элемент в кэш-память при записи не помещается, поскольку эта возможность усложняет разработку. Заполнение по записи полезно только в том случае, если имеют место повторные записи в одно и то же слово или в разные слова в пределах одной строки кэш-памяти.