

Пособие «Защита информации» (МФТИ)
.pdfЦифровая подпись. Эллиптические кривые |
Page 2 of 2 |
Множество точек эллиптической кривой вместе с нулевой точкой и с введенной операцией сложения будем называть «группой». Для каждой эллиптической кривой число точек в группе конечно, но достаточно велико. Оценка порядка (числа элементов) группы точек эллиптической кривой m такова:
где р — порядок поля, над которым определена кривая. Если в схеме Эль-Гамаля рекомендуется использовать число р порядка 2512, то в случае эллиптической кривой достаточно взять p > 2255.
Важную роль в алгоритмах подписи с использованием эллиптических кривых играют «кратные» точки. Точка Q называется точкой кратности k, если для некоторой точки P k раз выполнено равенство:
P = Q + Q + Q + … + Q = kQ
Если для некоторой точки P существует такое число k, что kP = 0, это число называют порядком точки P.
Кратные точки эллиптической кривой являются аналогом степеней чисел в простом поле. Задача вычисления кратности точки эквивалентна задаче вычисления дискретного логарифма. Собственно, на сложности вычисления «кратности» точки эллиптической кривой и основана надежность цифровой подписи. Хотя эквивалентность задачи дискретного логарифмирования и задачи вычисления кратности и доказана, вторая имеет большую сложность. Именно поэтому при построении алгоритмов подписи в группе точек эллиптической кривой оказалось возможным обойтись более короткими ключами по сравнению с простым полем при обеспечении большей стойкости.
Секретным ключом, как и раньше, положим некоторое случайное число x. Открытым ключом будем считать координаты точки на эллиптической кривой P, определяемую как P = xQ, где Q — специальным образом выбранная точка эллиптической кривой («базовая точка»). Координаты точки Q вместе с коэффициентами уравнения, задающего кривую, являются параметрами схемы подписи и должны быть известны всем участникам обмена сообщениями.
Выбор точки Q зависит от используемых алгоритмов и весьма непрост. Так, стандарт ГОСТ 34.10-2001 определяет, что точка Q должна иметь порядок q, где q — простое число с
«хорошими алгебраическими свойствами». Число q довольно велико (2254 < q < 2256). При построении конкретного алгоритма, реализующего вычисление цифровой подписи, американский стандарт предполагает использование алгоритма DSA. Новый российский стандарт использует модифицированную версию старого ГОСТ Р 34.10-94. Оказалось, оба они хорошо подходят для реализации в группе точек эллиптической кривой без особых модификаций. Некоторые специалисты отмечают даже, что описание алгоритма цифровой подписи Эль-Гамаля на эллиптической кривой «проще и естественней».
Для полного описания алгоритмов ECDSA и ГОСТ Р 34.10-2001 потребовалось расширить статью как минимум втрое, предположив, что читатель обладает приличной подготовкой в области высшей алгебры. Заинтересованного читателя отошлем к библиографии.
Алгоритмам и методам «эллиптической» криптографии посвящено замечательное пособие [2], а систематическое изложение основ алгебры можно найти в [1]. Полезно (а иногда и необходимо) обратиться к тексту стандартов.
40
http://www.osp.ru/os/2002/07-08/010_1_print.htm |
29.05.2004 |
Глава 21 Схемы идентификации
21.1 FEIGE-FIAT-SHAMIR
Схема цифровой подписи и проверки подлинности, разработанная Амосом Фиатом ( Amos Fiat) и Ади Шамиром (Adi Shamir), рассматривается в [566, 567]. Уриель Фейге (Uriel Feige), Фиат и Шамир модифицировали алгоритм, превратив его в доказательство подлинности с нулевым знанием [544, 545]. Это лучшее доказательство подлинности с нулевым знанием.
9 июля 1986 года три автора подали заявку на получение патента США [1427]. Из-за возможного военного применения заявка была рассмотрена военными . Время от времени результатом работы Патентное бюро явл я- ется не выдача патента, а нечто, называемое секретным распоряжением . 6 января 1987 года, за три дня до исте- чения шестимесячного периода, по просьбе армии Патентное бюро издало такое распоряжение . Заявило, что "
. . . раскрытие или публикация предмета заявки . . . может причинить ущерб национальной безопасности . . ." Авторам было приказано уведомить всех граждан США, которые по тем или иным причинам узнали о пров о- димых исследованиях, что несанкционированное раскрытие информации может закончиться двумя годами т ю- ремного заключения, штрафом $10,000 или тем и другим одновременно. Более того, авторы должны были сообщить Уполномоченному по патентам и торговым знакам обо всех иностранных гражданах, которые получили доступ к этой информации.
Это было нелепо. В течение второй половины 1986 года авторы представляли свою работу на конференциях в Израиле, Европе и Соединенных Штатах . Они даже не были американским гражданами, и вся работа была выполнена в Институте Вейцмана (Weizmann) в Израиле.
Слухи об этом стали распространяться в научном сообществе и прессе . В течение двух дней секретное распоряжение было аннулировано. Шамир и его коллеги считают, что за отменой секретного распоряжения стояло NSA, хотя никаких официальных комментариев не было . Дальнейшие подробности этой причудливой истории приведены в [936].
Упрощенная схема идентификации Feige-Fiat-Shamir
Перед выдачей любых закрытых ключей арбитр выбирает случайный модуль , n, который является произведением двух больших простых чисел. В реальной жизни длина n должна быть не меньше 512 битов и лучше как можно ближе к 1024 битам. n может общим для группы контролеров . (Использование чисел Блюма (Blum) облегчит вычисления, но не является обязательным для безопасности .)
Для генерации открытого и закрытого ключей Пегги доверенный арбитр выбирает число v, являющееся квадратичным остатком mod n. Другими словами выбирается v так, чтобы уравнение x2 ≡ v (mod n) имело решение, и существовало v-1 mod n. Это v и будет открытым ключом Пегги. Затем вычисляется наименьшее s, для которого s ≡ sqrt (v-1) (mod n). Это будет закрытый ключ Пегги. Используется следующий протокол идентиф и- кации.
(1)Пегги выбирает случайное r, меньшее n. Затем она вычисляет x =-r2 mod n и посылает x Виктору.
(2)Виктор посылает Пегги случайный бит b.
(3)Если b = 0, то Пегги посылает Виктору r. Если b = 1, то Пегги посылает Виктору y = r*s mod n.
(4)Если b = 0, Виктор проверяет, что x = -r2 mod n, убеждаясь, что Пегги знает значение sqrt(x). Если b = 1, Виктор проверяет, что x = y2*v mod n, убеждаясь, что Пегги знает значение sqrt(v-1).
Это один этап протокола, называемый аккредитацией. Пегги и Виктор повторяют этот протокол t раз, пока Виктор не убедится, что Пегги знает s. Это протокол "разрезать и выбрать". Если Пегги не знает s, она может подобрать r так, что она сможет обмануть Виктора, если он пошлет ей 0, или она может подобрать r так, что она сможет обмануть Виктора, если он пошлет ей 1 . Она не может сделать одновременно и то, и другое. Вероятность, что ей удастся обмануть Виктора один раз, равна 50 процентам . Вероятность, что ей удастся обмануть его t раз, равна 1/2t.
Виктор может попробовать вскрыть протокол, выдавая себя за Пегги . Он может начать выполнение протокола с с другим контролером, Валерией. На шаге (1) вместо выбора случайного r ему останется просто использовать значение r, которое Пегги использовало в прошлый раз . Однако, вероятность того, что Валерия на шаге
(2) выберет то же значение b, которое Виктор использовал в протоколе с Пегги, равна 1/2 . Следовательно, вероятность, что он обманет Валерию, равна 50 процентам . Вероятность, что ему удастся обмануть ее t раз, равна 1/2t.
41
Чтобы этот протокол работал, Пегги никогда не должна использовать r повторно. В противном случае, если Виктор на шаге (2) пошлет Пегги другой случайный бит, то он получит оба ответа Пегги . Тогда даже по одному из них он сможет вычислить s, и для Пегги все закончится.
Схема идентификации Feige-Fiat-Shamir
В своих работах [544, 545], Фейге, Фиат и Шамир показали, как параллельная схема может повысить число аккредитаций на этап и уменьшить взаимодействия Пегги и Виктора .
Сначала, как и в предыдущем примере, генерируется n, произведение двух больших простых чисел . Для генерации открытого и закрытого ключей Пегги сначала выбирается k различных чисел: v1, v2, . . . vk, где каждое vi является квадратичным остатком mod n. Иными словами, vi выбираются так, чтобы x2 ≡ vi (mod n) имело решение, и существовало vi-1 mod n. Строка, v1, v2, . . . vk, служит открытым ключом. Затем вычисляются наименьшие si, для которых si ≡ sqrt (vi-1) (mod n). Строка s1, s2, . . . sk, служит закрытым ключом.
Выполняется следующий протокол:
(1)Пегги выбирает случайное r, меньшее n. Затем она вычисляет x =-r2 mod n и посылает x Виктору.
(2)Виктор посылает Пегги строку из k случайных битов: b1, b2, . . . bk.
(3) Пегги вычисляет y = r *( s b1 |
*s |
b2 *K*s bk )mod n. (Она перемножает вместе значения si, соответствующие |
1 |
2 |
k |
bi=1. Если первым битом Виктора будет 1, то s1 войдет в произведение, а если первым битом будет 0, то нет, и т.д.) Она посылает y Виктору.
(4) Виктор проверяет, что x = y2*( v1b1 * v2 b2 * *v bk ) mod n. (Он перемножает вместе значения vi, основываясь
K k
га случайной двоичной строке. Если его первым битом является 1, то v1 войдет в произведение, а если первым битом будет 0, то нет, и т.д.)
Пегги и Виктор повторяют этот протокол t раз, пока Виктор не убедится, что Пегги знает s1, s2, . . . sk.
Вероятность, что Пегги удастся обмануть Виктор t раз, равна 1/2kt. Авторы рекомендуют использовать вероятность мошенничества 1/220 и предлагают значения k = 5 и t = 4. Если у вас склонность к мании преследования, увеличьте эти значения.
Пример
Взглянем на работу этого протокола небольших числах . Если n = 35 (два простых числа - 5 и 7), то возможными квадратичными остатками являются :
1: x2 ≡ 1 (mod 35) имеет решения: x = 1, 6, 29, 34. 4: x2 ≡ 4 (mod 35) имеет решения: x = 2, 12, 23, 33. 9: x2 ≡ 9 (mod 35) имеет решения: x = 3, 17, 18, 32.
11: x2 ≡ 11 (mod 35) имеет решения: x = 9, 16, 19, 26.
14:x2 ≡ 14 (mod 35) имеет решения: x = 7, 28.
15:x2 ≡ 15 (mod 35) имеет решения: x = 15, 20.
16:x2 ≡ 16 (mod 35) имеет решения: x = 4, 11, 24, 31.
21:x2 ≡ 21 (mod 35) имеет решения: x = 14, 21.
25:x2 ≡ 25 (mod 35) имеет решения: x = 5, 30.
29:x2 ≡ 29 (mod 35) имеет решения: x = 8, 13, 22, 27.
30:x2 ≡ 30 (mod 35) имеет решения: x = 10, 25.
Обратными значениями (mod 35) и их квадратными корнями являются:
v |
v-1 |
s=sqrt(v-1) |
1 |
1 |
1 |
4 |
9 |
3 |
9 |
4 |
2 |
11 |
16 |
4 |
42
16 |
11 |
9 |
29 |
29 |
8 |
Обратите внимание, что у чисел 14, 15, 21, 25 и 30 нет обратных значений mod 35, так как они не взаимно просты с 35. Это имеет смысл, так как должно быть (5 - 1) * (7 - 1)/4 квадратичных остатков mod 35, взаимно простых с 35: НОД(x, 35) = 1 (см. раздел 11.3).
Итак, Пегги получает открытый ключ, состоящий из k = 4 значений: {4,11,16,29}. Соответствующим закрытым ключом является {3,4,9,8}. Вот один этап протокола.
(1)Пегги выбирает случайное r=16, вычисляет 162 mod 35 = 11 и посылает его Виктору.
(2)Виктор посылает Пегги строку случайных битов: {1, 1, 0, 1}
(3)Пегги вычисляет 16*(31*41*90*81) mod 35 = 31 и посылает его Виктору.
(4)Виктор проверяет, что 312*(41*111*160*291) mod 35 =11.
Пегги и Виктор повторяют этот протокол t раз, каждый раз с новым случайным r, пока Виктор будет убежден.
Небольшие числа, подобные использованным в примере, не обеспечивают реальной безопасности . Но когда длина n равна 512 и более битам, Виктор не сможет узнать о закрытом ключе Пегги ничего кроме того факта, что Пегги действительно знает его.
Улучшения
В протокол можно встроить идентификационные данные . Пусть I - это двоичная строка, представляющая идентификатор Пегги: имя, адрес, номер социального страхования, размер головного убора, любимый сорт прохладительного напитка и другая личная информация . Используем однонаправленную хэш-функцию H(x) для вычисления H(I,j), где j - небольшое число, добавленное к I. Найдем набор j, для которых H(I,j) - это квадратич- ный остаток по модулю n. Эти значения H(I,j) становятся v1, v2, . . . vk (j не обязаны быть квадратичными остатками). Теперь открытым ключом Пегги служит I и перечень j. Пегги посылает I и перечень j Виктору перед шагом (1) протокола (или Виктор загружает эти значения с какой-то открытой доски объявлений ), И Виктор генерирует v1, v2, . . . vk èç H(I,j).
Теперь, после того, как Виктор успешно завершит протокол с Пегги, он будет убежден, что Трент, которому известно разложение модуля на множители, сертифицировал связь между I и Пегги, выдав ей квадратные корни из vi, полученные из I. (См. раздел 5.2.) Фейге, Фиат и Шамир добавили следующие замечания [544, 545]:
Для неидеальных хэш-функций можно посоветовать рандомизировать I, добавляя к нему длинную случайную строку R. Эта строка выбирается арбитром и открывается Виктору вместе с I.
В типичных реализациях k должно быть от 1 до 18. Большие значения k могут уменьшить время и трудности связи, уменьшая количество этапов.
Длина n должна быть не меньше 512 битов. (Конечно, с тех пор разложение на множители заметно продвинулось .)
Если каждый пользователь выберет свое собственное n и опубликует его в файле открытых ключей, то можно обойтись и без арбитра. Однако такой RSA-подобный вариант делает схему заметно менее удобной .
Схема подписи Fiat-Shamir
Превращение этой схемы идентификации в схему подписи - это, по сути, вопрос превращения Виктора в хэш-функциию. Главным преимуществом схемы цифровой подписи Fiat-Shamir по сравнению с RSA является ее скорость: для Fiat-Shamir нужно всего лишь от 1 до 4 процентов модульных умножений, используемых в RSA. В этом протоколе снова вернемся к Алисе и Бобу .
Смысл переменных - такой же, как и в схеме идентификации . Выбирается n - произведение двух больших простых чисел. Генерируется открытый ключ, v1, v2, . . . vk, и закрытый ключ, s1, s2, . . . sk, ãäå si ≡ sqrt (vi-1) (mod n).
(1)Алиса выбирает t случайных целых чисел в диапазоне от 1 до n - r1, r2, . . ., rt - и вычисляет x1, x2, . . . xt, такие что xi = ri2 mod n.
(2)Алиса хэширует объединение сообщения и строки xi, создавая битовый поток: H(m, x1, x2, . . . xt). Она использует первые k*t битов этой строки в качестве значений bij, где i пробегает от1 до t, а j от 1 до k.
(3) Алиса вычисляет y1, y2, . . . yt,, ãäå yi = ri *( s bi 1 |
* s bi 2 |
*K*s bik ) mod n |
1 |
2 |
k |
(Для каждого i она перемножает вместе значения si, в зависимости от случайных значений bij. Åñëè bij=1, òî si участвует в вычислениях, если bij=0, òî íåò.)
(4)Алиса посылает Бобу m, все биты bij, и все значения yi. У Боба уже есть открытый ключ Алисы: v1, v2, . . .
vk.
43
(5) Боб вычисляет z1, z2, . . . zt, ãäå zi = y2*( v bi 1 |
*v bi 2 |
*K*v bik ) mod n |
1 |
2 |
k |
(И снова Боб выполняет умножение в зависимости от значений bij.) Также обратите внимание, что zi должно быть равно xi.
(6) Боб проверяет, что первые k*t битов H(m, z1, z2, . . . zt) - это значения bij, которые прислала ему Алиса.
Как и в схеме идентификации безопасность схемы подписи пропорциональна l/2kt. Она также зависит от сложности разложения n на множители. Фиат и Шамир показали, что подделка подписи облегчается, если сложность разложения n на множители заметно меньше 2kt. Кроме того, из-за вскрытия методом дня рождения (см. раздел 18.1), они рекомендуют повысить k*t от 20 по крайней мере до 72, предлагая k = 9 и t = 8.
Улучшенная схема подписи Fiat-Shamir
Сильвия Микали (Silvia Micali) и Ади Шамир улучшили протокол Fiat-Shamir [1088]. Они выбирали v1, v2,
. . . vk так, чтобы они были первыми k простыми числами. То есть v1= 1, v2= 3, v3= 5, è ò.ä.
Это открытый ключ. Закрытым ключом, s1, s2, . . . sk, служат случайные квадратные корни, определяемые
êàê
si = sqrt (vi-1) (mod n)
В этой версии у каждого участника должен быть свой n. Такая модификация облегчает проверку подписей , не влияя на время генерации подписей и их безопасность.
Другие улучшения
На основе алгоритма Fiat-Shamir существует и N-сторонняя схема идентификации [264]. Два других улуч- шения схемы Fiat-Shamir в [1218]. Еще один вариант - в [1368].
Схема идентификации Ohta-Okamoto
Этот протокол является вариантом схемы идентификации Feige-Fiat-Shamir, его безопасность основана на трудности разложения на множители [1198, 1199]. Эти же авторы разработали схему с несколькими подписями (см. раздел 23.1), с помощью которой различные люди могут последовательно подписывать [1200]. Эта схема была предложена для реализации на интеллектуальных карточках [850].
Патенты
Fiat-Shamir запатентован [1427]. При желании получить лицензию на алгоритм свяжитесь с Yeda Research and Development, The Weizmann Institute of Science, Rehovot 76100, Israel.
21.2 GUILLOU-QUISQUATER
Feige-Fiat-Shamir был первым практическим протоколом идентификации . Он минимизировал вычисления, увеличивая число итераций и аккредитаций на итерацию . Для ряда реализаций, например, для интеллектуал ь- ных карточек, это не слишком подходит . Обмены с внешним миром требуют времени, а хранение данных для каждой аккредитации может быстро исчерпать ограниченные возможности карточки .
Луи Гиллу (Louis Guillou) и Жан-Жак Кискатр (Jean-Jacques Quisquater) разработали алгоритм идентификации с нулевым знанием, который больше подходит для подобных приложений [670, 1280]. Обмены между Пегги и Виктором, а также параллельные аккредитации в каждом обмене сведены к абсолютному минимуму : для каждого доказательства существует только один обмен, в котором - только одна аккредитация . Для достижения того же уровня безопасности при использовании схемы Guillou-Quisquater потребуется выполнить в три раза больше вычислений, чем при Feige-Fiat-Shamir. И, как и Feige-Fiat-Shamir, этот алгоритм идентификации можно превратить в алгоритм цифровой подписи .
Схема идентификации Guillou-Quisquater
Пегги - это интеллектуальная карточка, которая собирается доказать свою подлинность Виктору . Идентификация Пегги проводится по ряду атрибутов, представляющих собой строку данных содержащих название ка р- точки, период действия, номер банковского счета и другие, подтверждаемые ее применимость, данные . Эта битовая строка называется J. (В реальности строка атрибутов может быть очень длинной, и в качестве J используется ее хэш-значение. Это усложнение никак не влияет на протокол .) Эта строка аналогична открытому ключу . Другой открытой информацией, общей для всех "Пегги", которые могут использовать это приложение, является показатель степени v и модуль n, где n - это произведение двух хранящихся в секрете простых чисел . Закрытым
44

ГОСТ Р 34.11 – 94. Функция хэширования. Краткий анализ
Шефановский Д.Б.1
Май 2001
Обозначения
{01} - множество двоичных строк произвольной конечной длины;
{01}n - множество двоичных строк длиной n бит;
{ |
} |
n - двоичная строка из n нулей; |
|
0 |
|
| |
A | - длина слова A в битах; |
|
A B - побитное сложение слов A и B по mod 2 , или попросту XOR; |
||
A |
B - сложение слов A и B по mod 2256 ; |
|
← оператор присвоения; |
||
|| - конкатенация; |
||
GF |
2 - поле Галуа характеристики 2. |
|
|
|
( ) |
Введение
Криптографические хэш функции играют фундаментальную роль в современной криптографии. Говоря в общем хэш функция h отображает двоичные строки произвольной конечной длины в выходы небольшой (например, 64, 128, 160,192, 224, 256, 384, 512) фиксированной длины называемые хэш величинами за полиномиальное время:
h : {01} →{01}n ,
где {01} i {01}i (в ГОСТ Р 34.11 – 94 n = 256 ). Основная идея криптографических
функций состоит в том, чтобы хэш величины служили как компактный репрезентативный образ входной двоичной строки, и их можно использовать как если бы они однозначно отождествлялись с этой строкой, хотя для области определения D и области значений R
с D
 R (имеются ввиду мощности множеств), функция типа “множество – один”
R (имеются ввиду мощности множеств), функция типа “множество – один”
подразумевает, что существование столкновений (пары входов с одинаковым выходом) неизбежно. Область применения хэш функции четко не оговорена: используется “для реализации процедур электронной цифровой подписи (ЭЦП), при передаче, обработке и хранении информации в автоматизированных системах”.
Сообщения с произвольной длины можно сжать используя хэш функцию с фиксированным размером входа при помощи двух методов:
−последовательного (итерационного);
1Учебный центр «ИНФОРМЗАЩИТА» 127018, г. Москва, ул. Образцова, 38 а/я 55 (095) 289-4232, 289-8998, 289-3162, 219-3188
shefanovski@infosec.ru
45
− параллельного.
Создатели ГОСТ Р 34.11 – 94 пошли по первому пути и использовали метод последовательного хэширования использующий хэш функцию с фиксированным
размером входа h : |
{ |
} |
2n → |
{ |
} |
n (см. Рис. 1), то есть функцию сжатия с коэффициентом |
|||||||||||||||
|
|
01 |
|
|
01 |
|
|||||||||||||||
2. |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
m1 |
|
|
|
|
m2 |
|
|
|
|
|
ml |
|
|
|||
|
|
IV |
|
|
|
|
h |
|
|
h2 |
hl−1 |
|
|
h |
|||||||
|
|
|
|
|
|
|
|
|
|
||||||||||||
|
|
|
|
|
|
|
|
|
|||||||||||||
|
|
|
|
|
H |
|
|
1 |
|
H |
|
|
|
|
|
H |
итог |
||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
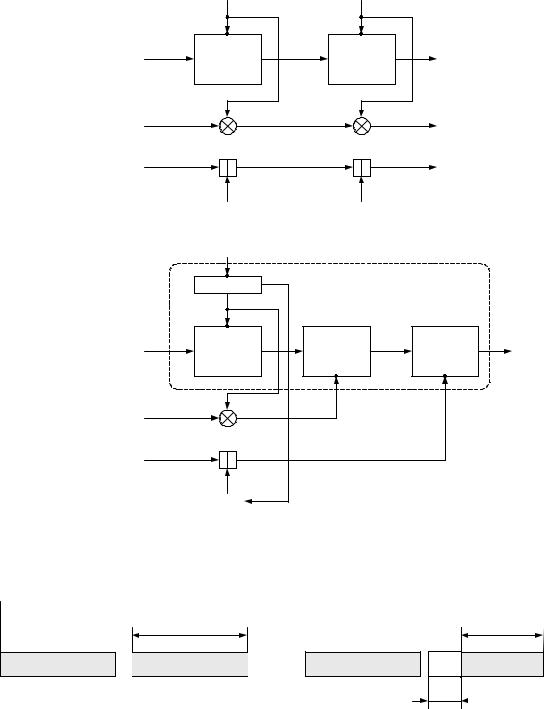
Рис. 1 Метод последовательного хэширования
Если необходимо хэшировать сообщение m =(m1, m2 ,…, ml ), то хэширование
выполняется следующим образом: h0 ← IV ,
hi ← H (mi , hi−1 ), дляi =1, 2,…,l
hитог ←hl .
Здесь Hi - функция сжатия, а hi - переменная сцепления.
Если последний блок меньше чем n бит, то он набивается одним из существующих методов до достижения длины кратной n . В отличие от стандартных предпосылок, что сообщение разбито на блоки и произведена набивка последнего блока (форматирование входа априори), если необходимо, до начала хэширования, то в ГОСТ Р 34.11 – 94 процедура хэширования ожидает конца сообщения (форматирование входного сообщения постериори). Набивка производится следующим образом: последний блок сдвигается вправо, а затем набивается нулями до достижения длины в 256 бит.
На первый взгляд алгоритм хэширования по ГОСТ Р 34.11 – 94 можно классифицировать как устойчивый к столкновениям ( n = 256 , следовательно атака по парадоксу дней
рождения потребует приблизительно 2256 / 2 операций хэширования) код выявляющий модификации (Collision Resistant Hash Function, CRHF), см. Замечание 4. Нельзя забывать, что хэш функцию по ГОСТ Р 34.11 – 94 можно легко преобразовать в код аутентификации сообщения любым известным методом (например, HMAC [1], методом секретного префикса, суффикса, оболочки и т.д.). Однако конструкторы предусмотрели дополнительные меры защиты: параллельно рассчитываются контрольная сумма представляющая собой сумму всех блоков сообщения (последний суммируется уже
набитым) по правилу A+ B mod 2k , где k =| A |=| B |, а | A | и | B | битовые длины слов A и B (далее на рисунках и в тексте эту операцию будем обозначать значком ), и битовая длина хэшируемого сообщения приводимая по mod 2256 (MD - усиление), которые в финальной функции сжатия используются для вычисления итогового хэша (см. Рис. 2).
Учебный центр “Информзащита” |
2 |
46 |
|
m1 |
|
m2 |
|
|
|
IV |
H* |
h1 |
H* |
h2 |
... |
|
|
|
|
||||
{0}256 |
|
Σ1 |
Σ2 |
|
... |
|
{0}256 |
|
L1 |
L2 |
|
... |
|
|
(256)10 |
(256)10 |
|
|
|
|
|
ml |
|
|
|
|
|
|
набивка |
|
Функция сжатия |
|
||
|
финальной итерации |
|
||||
... hl−1 |
H* |
|
H* |
|
H* |
hитог |
... Σl−1 |
|
|
|
|
|
|
... Ll−1 |
|
|
|
|
|
|
|
| ml |
| |
|
|
|
|
Рис. 2 Общая схема функции хэширования по ГОСТ Р 34.11 – 94 |
||||||
Замечание 1 (набивка) Указывать в передаваемом сообщении сколько было добавлено нулей к последнему блоку не требуется, так как длина сообщения участвует в хэшировании.
|
256 |
|
|
m1 |
m2 |
... |
ml−1 |
Рис. 3 Набивка сообщения
|
| ml | |
00...0 |
ml |
0 |
256−|ml | |
{ } |
|
Замечание 2 (начальный вектор IV ) Согласно ГОСТ Р 34.11 – 94 IV - произвольное фиксированное слово длиной 256 бит ( IV {01}256 ). В таком случае, если он априорно не
известен верифицирующему целостность сообщения, то он должен передаваться вместе с сообщением с гарантией целостности. При небольших сообщениях можно усложнить задачу противнику, если IV выбирается из небольшого множества допустимых величин (но при этом увеличивается вероятность угадывания хэш величины противником). Также он может задаваться в рамках организации, домена как константа (обычно как в тестовом примере).
Учебный центр “Информзащита” |
3 |
47 |

Детальное рассмотрение 1. Функция сжатия внутренних итераций (по ГОСТ “шаговая функция
хэширования”)
Функция сжатия внутренних итераций χ отображает два слова длиной 256 бит в одно слово длиной 256 бит:
χ: {01}256 × {01}256 →{01}256 ,
исостоит из трех процедур (см. Рис. 4):
−Перемешивающего преобразования (по существу модифицированной схемы Фейстеля),
−Шифрующего преобразования;
−Генерирования ключей.
mi
256
hi−1 |
перемешивающее |
||
преобразование |
|||
|
|
χ(hi−1, mi , si ) |
|
256 |
|||
|
|||
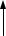 si
si
 шифрующее преобразование, генерирование
шифрующее преобразование, генерирование
ключей
H*
hi
256
Рис. 4 Структура функции сжатия в ГОСТ Р 34.11 – 94
а) Перемешивающее преобразование
Здесь использована модифицированная для хэширования перестановка Фейстеля, где n -
битный вход разделяется на k |
блоков по r бит, так чтобы kl = n : |
||||||||||||||||||||||
|
|
|
|
F : |
01 |
|
r × × |
{ |
01 |
r → |
{ |
01 |
r × × |
{ |
01 r , |
||||||||
|
|
|
|
p |
{ |
} |
|
|
|
} |
|
|
} |
|
|
|
|
|
} |
||||
|
|
|
|
|
|
|
|
|
l |
|
|
|
( 1 |
|
|
l ) |
|
l |
|
|
|
|
|
где p - входное сообщение. Пусть вход |
A = |
|
|
|
{ } |
n , а выход |
|||||||||||||||||
|
A ,…, A |
|
01 |
|
|||||||||||||||||||
B = |
B ,…, B |
|
01 n , тогда F |
A описывается следующим образом: |
|||||||||||||||||||
|
( 1 |
l ) |
|
{ } |
|
p ( |
|
) |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
← A |
f |
A , …, A |
, |
|
|
|
||||||||||
|
|
|
|
|
|
B |
|
|
|
||||||||||||||
|
|
|
|
|
|
l |
|
|
1 |
|
|
p ( |
2 |
|
|
l |
) |
|
|
|
|
||
|
|
|
|
|
|
|
|
← A , …, B |
← A . |
|
|
|
|
|
|||||||||
|
|
|
|
|
|
B |
−1 |
|
|
|
|
|
|||||||||||
|
|
|
|
|
|
l |
|
|
l |
|
|
1 |
|
2 |
|
|
|
|
|
||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
Схематически модифицированная функция Фейстеля представлена на Рис. 5 (без претензий на общность).
Учебный центр “Информзащита” |
4 |
48 |
Al |
... |
A2 A1 |
|
|
... |
Fp |
...
Bl Bl−1 |
B1 |
Рис. 5 Модифицированная схема Фейстеля для хэширования
Перемешивающее преобразование имеет вид
hi = χ(mi , hi−1, si )= ψ61 (hi−1 ψ(mi ψ12 (si ))),
где ψj - j -я степень преобразования ψ. Схематически данное преобразование представлено на Рис. 6.
mi
|
|
|
|
si |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
ψ12 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
ψ |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
hi |
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||
|
|
|
|
hi−1 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
ψ61 |
|
|
||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Рис. 6 Перемешивающее преобразование ГОСТ Р 34.11 – 94 |
||||||||||||||||||||||
Заметим (см. Рис. 6), что si |
выводится из hi−1 |
(см. Рис. 4). Функция |
||||||||||||||||||||||||
ψ: |
{ |
01 256 |
→ |
01 256 преобразует слово η |
|| |
|
|
|| η , η |
|
|
01 16 |
,i = |
|
в слово |
||||||||||||
|
|
i |
1,16 |
|||||||||||||||||||||||
|
} |
|
{ } |
|
16 |
|
|
|
|
1 |
|
|
|
{ } |
|
|
|
|
|
|||||||
η1 η2 η3 η4 η13 η16 || η16 || η15 || || η2 |
|
(см. Рис. 7). |
|
|
|
|
|
|
||||||||||||||||||
Учебный центр “Информзащита” |
5 |
49 |