

Пособие «Защита информации» (МФТИ)
.pdfki =F(xi)
Другими словами, первой тенью может быть значение многочлена при x = 1, второй тенью - значение многочлена при x = 2, и т.д.
Так как в квадратичных многочленах три неизвестных коэффициента , a, b и M, для создания трех уравнений можно использовать любые три цели. Одной или двух теней не хватит, а четырех или пяти теней будет много .
Например, пусть M равно 11. Чтобы создать пороговую схему (3, 5), в которой любые трое из пяти человек могут восстановить M, сначала получим квадратичное уравнение (7 и 8 - случайно выбранные числа chosen randomly):
F(x) = (7x 2 + 5x + 11) mod 13
Пятью тенями являются:
k1 = F(1) = 7 + 8 + 11≡ 0 (mod 13)
k2 = F(2) = 28 + 16 + 11≡ 3 (mod 13)
k3 = F(3) = 63 + 24 + 11≡ 7 (mod 13)
k4 = F(4) = 112 + 32 + 11≡ 12 (mod 13)
k5 = F(5) = 175 + 40 + 11≡ 5 (mod 13)
Чтобы восстановить M по трем теням, например, k2, k3 è k5, решается система линейных уравнений: a*22 + b*2 + M = 3 (mod 13)
a*32 + b*3 + M = 7 (mod 13)
a*52 + b*5 + M = 5 (mod 13)
Решением будут a = 7, b = 8 и M = 11. Итак, M получено.
Эту схему разделения можно легко реализовать для больших чисел . Если вы хотите разбить сообщение на 30 равных частей так, чтобы восстановить сообщение можно было, объединив любые шесть из них , выдайте каждому из 30 человек значения многочлена пятой степени .
F(x) = ax5 + bx4 + cx3 + dx2 + ex + M (mod p)
Шесть человек могут шесть неизвестных (включая M), но пятерым не удастся узнать ничего об M.
Наиболее впечатляющим моментом совместного использования секрета является то, что, если коэффицие н- ты выбраны случайным образом, пять человек даже при помощи бесконечных вычислительных мощностей не смогут узнать ничего, кроме длины сообщения (которая и так им известна) . Это также безопасно, как одноразовый блокнот, попытка выполнить исчерпывающий поиск (то есть, перебор всех возможных шестых теней) покажет, что любое возможное сообщение останется секретным . Это справедливо для всех представленных в этой книге схем разделения секрета.
Векторная схема
Джордж Блэкли (George Blakley) изобрел схему, использующую понятие точек в пространстве [182]. Сообщение определяется как точка в m-мерном пространстве. Каждая тень - это уравнение (m-1)-мерной гиперплоскости, содержащей эту точку.
Например, если для восстановления сообщения нужны три тени, то оно является точкой в трехмерном пр о- странстве. Каждая тень представляет собой иную плоскость . Зная одну тень, можно утверждать, что точка нах о- дится где-то на плоскости. Зная две тени - что она находится где-то на линии пересечения двух плоскостей . Зная три тени, можно точно определить, что точка находится на пересечении трех плоскостей .
Asmuth-Bloom
В этой схеме используются простые числа [65]. Для (m, n)-пороговой схемы выбирается большое простое число p, большее M. Затем выбираются числа, меньшие p - d1, d2, . . . dn, для которых:
1.Значения di упорядочены по возрастанию, di < di+1
2.Каждое di взаимно просто с любым другим di
3.d1*d2* . . .*dm > p*dn-m+2*dn-m+3*. . .*dn
Чтобы распределить тени, сначала выбирается случайное число r и вычисляется
70
M' = M + rp
Тенями, ki, являются
ki = M' mod di
Объединив любые m теней, можно восстановить M, используя китайскую теорему об остатках, но это невозможно с помощью любых m-1 теней. Подробности приведены в [65].
Karnin-Greene-Hellman
В этой схеме используется матричное умножение [818]. Выбирается n+1 m-мерных векторов, V0, V1, . . . Vn, так, что ранг любой матрицы размером m*m, образованной из этих векторов, равен m. Вектор U - это вектор размерности m+1.
M - это матричное произведение U·V0. Тенями являются произведения U·Vi, где i меняется от 1 до n.
Любые m теней можно использовать для решения системы линейных уравнений размерности m*m, неизвестными являются коэффициенты U. U·V0 можно вычислить по U. Используя любые m-1 теней, решить систему уравнений и, таким образом, восстановить секрет невозможно .
Более сложные пороговые схемы
В предыдущих примерах показаны только простейшие пороговые схемы : секрет делится на n теней так, чтобы, объединив любые m из них, можно было раскрыть секрет . На базе этих алгоритмов можно создать намного более сложные схемы. В следующих примерах будет использоваться алгоритм Шамира, хотя будут работать и все остальные.
Чтобы создать схему, в которой один из участников важнее других, ему выдается больше теней . Если для восстановления секрета нужно пять теней, и у кого-то есть три тени, а у всех остальных - по одной , этот человек вместе с любыми двумя другими может восстановить секрет . Без его участия для восстановления секрета потр е- буется пять человек.
По несколько теней могут получить два человека и более . Каждому человеку может быть выдано отличное число теней. Независимо от того, сколько теней было роздано, для восстановления секрета потребуется любые m из них. Ни один человек, ни целая группа не смогут восстановить секрет, обладая только m-1 тенями.
Для других схем представим сценарий с двумя враждебными делегациями . Можно распределить секрет так, чтобы для его восстановления потребовалось двое из 7 участников делегации A и трое из 12 участников делегации B. Создается многочлен степени 3, который является произведением линейного и квадратного выражений . Каждому участнику делегации A выдается тень, которая является значением линейного выражения, а участн и- кам делегации B выдаются значения квадратичного выражения .
Для восстановления линейного выражения достаточны любые две тени участников делегации A, но независимо от того, сколько других теней есть у делегации , ее участники не смогут ничего узнать о секрете . Аналогич- но для делегации B: ее участники могут сложить три тени, восстанавливая квадратное выражение, но другую информацию, необходимую для восстановления секрета в целом, они получить не смогут . Только перемножив свои выражения, участники двух делегаций смогут восстановить секрет .
В общем случае, может быть реализована любая мыслимая схема разделения секрета . Потребуется только написать систему уравнений, соответствующих конкретной системе. Вот несколько прекрасных статей на тему обобщенных схем разделения секрета [1462, 1463, 1464].
Разделение секрета с мошенниками
Этот алгоритм изменяет стандартную пороговую схему (m, n) для обнаружения мошенников [1529]. Я покажу его использование на базе схемы Лагранжа , но алгоритм работает и с другими схемами . Выбирается простое число p, большее n и большее
(s - 1)(m - 1)/e + m
где s - это самый большой возможный секрет, а e - вероятность успеха мошенничества. e можно сделать настолько малым, насколько это необходимо, это просто усложнит вычисления . Постройте тени как раньше, но вместо использования 1, 2, 3, . . . , n для xi, выберите случайным образом числа из диапазона от 1 до p-1.
Теперь, если Мэллори при восстановлении секрета заменит свою часть подделкой , его тень с высокой вероятностью окажется невозможной. Невозможный секрет, конечно же, окажется подделанным секретом . Математика этой схемы приведена в [1529].
К сожалению, хотя мошенничество Мэллори и будет открыто, ему удастся узнать секрет (при условии, что все остальные нужные тени правильны). От этого защищает другой протокол, описанный в [1529, 975]. Основ-
71
Неофициальный сервер Геологического ф-та МГУ >> М. .. Page 1 of 1
4.2.3 Схема Брикелла -- МакКарли [BM91]
Эта схема была разработана в Национальной лаборатории США Sandia.
Пусть -- параметр безопасности ( ), а |
и -- простые числа, |
|||
такие что |
, |
, |
, но |
. Пусть также -- элемент |
порядка |
группы |
, а |
|
-- криптографически |
стойкая односторонняя хэш-функция. Параметры 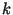 ,
, 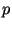 ,
, 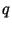 ,
, 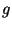 и хэш-
и хэш-
функция 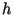 могут быть выбраны центром обеспечения безопасности. В отличие от схемы Шнорра общедоступными являются только
могут быть выбраны центром обеспечения безопасности. В отличие от схемы Шнорра общедоступными являются только 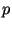 ,
, 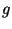 и
и 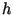 , а
, а 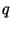
должно быть секретным. Подписывающий выбирает секретный ключ
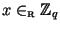 и вычисляет открытый ключ
и вычисляет открытый ключ 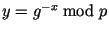 . Пространством сообщений в данной схеме является
. Пространством сообщений в данной схеме является 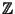 . Для генерации подписи для
. Для генерации подписи для
сообщения нужно выбрать |
|
и вычислить |
, |
и |
. Искомой подписью является пара |
|
|
. Параметр должен быть секретным и может быть уничтожен после |
|||
генерации подписи. Проверка подписи |
для сообщения сводится к |
|
|
проверке равенства |
|
. |
|
Вера в стойкость схемы Брикелла -- МакКарли основана на (гипотетической) сложности задачи дискретного логарифмирования по основанию 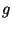 . По-видимому, незнание противником порядка
. По-видимому, незнание противником порядка 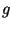 усложнит
усложнит
для него дискретное логарифмирование по основанию 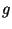 и повысит стойкость схемы.
и повысит стойкость схемы.
72
http://geo.com.ru/db/msg.html?mid=1161287&uri=node34.html 29.05.2004

Переполнение Буффера
Организация процессов в памяти
Чтобы понять, что такое буферы в стеке необходимо сначала представлять себе, как происходит организация процессов в памяти. Адресное пространства процесса можно разделить на 3 сегмента: сегмент кода(Text), сегмент данных(Data) и сегмент стека(Stack).Мы будем рассматривать в основном сегмент стека, но для начала сделаем небольшой обзор остальных сегментов. Сегмент кода является неизменной частью программы и содержит непосредственно инструкции машинного кода. Этот сегмент, как правило, доступен только для чтения, и попытка записи в его адресное пространство вызывает segmentation violation.
Сегмент данных содержит проинициализированные и не проинициализированные данные. Здесь хранятся статические переменные.Размер этого сегмента может быть изменен с помощью системного вызова brk(). Если размер пользовательских данных(data-bss) или стека, определенного пользователем, по мере работы процесса превышает объем первоначально выделенной процессу памяти, то он блокируется и возобновляет свою работу в новом пространстве, для которого ОС выделяет дополнительную память. Она распределяется между сегментами данных и стека.
|
|
|
|
|
|
исполнимый код |
|
нижние адреса памяти |
|
|
|
|
|
|
|
(проинициализированные) |
|
|
|
|
Данные |
|
|
|
|
(непроинициализированные) |
|
|
|
|
|
|
|
|
Рис. 1 Структура |
Стек |
|
верхние адреса памяти |
|
памяти процесса |
|
|
|
|
Для чего применяется стек?
Стек применяется для динамического размещения локальных переменных в функциях, передачи параметров в функцию и получения результатов ее работы.
Сегмент стека
Регистр SP (stack pointer - указатель стека) указывает на вершину стека, адрес которой меняется. Основание стека - фиксированный адрес памяти.Размер стека динамически контролируется ядром. Операции push и pop непосредственно реализованы в процессоре. Стек логически подразделяется на фреймы, которые состоят из параметров, передающихся в функцию, локальных переменных функции и данных, необходимых для возврата в основную функцию. В зависимости от реализации, стек может расти либо вверх, либо вниз ( используя адреса памяти в сторону уменьшения ).В наших примерах будет подразумеваться, что стек растет вниз
Итак,SP будет указывать на вершину стека (наименьшее значение из адресов памяти, используемых под стек).Часто удобно иметь указатель на какой-либо адрес внутри фрейма(FP frаme pointer). Некоторые источники называют его LB(local base ponter). Вообще, абсолютный адрес в стеке локальных переменных может быть получен с помощью смещения относительно SP. Однако по мере записи и чтения из стека эти смещения изменяются.
Поэтому многие компиляторы используют второй регистр ,FP, для ссылки на локальные переменные и параметры, так как их смещение относительно FP не изменяется по мере использования операций push и pop.В процессорах Intel для этой цели используется
73
регистр BP( EBP ). Поскольку в нашем случае стек растет вниз, то смещения для доступа к параметрам будут положительными, а для локальных переменных относительно FP отрицательными. Первое, что должна сделать функция, после своего вызова - сохранить предыдущее значение FP, иначе оно не сможет быть восстановлено после того, как она отработает. Затем происходит копирование SP в FP с целью создания нового FP и уменьшается значение SP для резервирования места под локальные переменные функции.Этот алгоритм называет входом в процедуру.После завершения работы функции стек должен иметь первоначальный вид.Рассмотрим, как он выглядит на простом примере:
example1.c:
-----------------------------------------------------------------------------
-
void function(int a, int b, int c) { char buffer1[5];
char buffer2[10];
}
void main() { function(1,2,3);
}
-----------------------------------------------------------------------------
-
код, в который была транслирована функция function(). Чтобы разобраться в том, что программа делает при вызове function(), мы скомпилируем ее gcc c опцией -S ,которая дает на выходе ассемблерный код.
$ gcc -S -o example1.s example1.c
Ассемблерный код: pushl $3
pushl $2 pushl $1 call function
Здесь три аргумента сначала заносятся в стек, затем происходит вызов функции (call), который также записывает значение IP(instruction pointer)в стек.Это значение мы будем называть адресом возврата(RET).Первое, что делает вызванная функция - реализует описанный алгоритм входа:
pushl %ebp movl %esp,%ebp subl $20,%esp
Здесь происходит запись EBP в стек, копирование SP в EBP (создается новый FP, который мы назовем SFP).Затем уменьшением значения SP, резервируется место под локальные переменные. Мы должны помнить, что память в стеке адресуется словами (в нашем случае слово - 32 бита), т.е. чтение и запись происходит блоками по 4 байта.Поэтому буфер из 5 байт потребует 8 байт (два слова) памяти, из 10 байт - соответственно 12 байт (три слова).Вот почему из SP вычитается 20.С учетом всего этого, стек при вызове function() выглядит следующим образом (каждый пробел обозначает байт):
нижние адреса памяти
верхние адреса памяти |
|
|
|
|
|
|
|
buffer2 |
buffer1 |
sfp |
ret |
a |
][ |
b |
c |
<------ [ |
][ |
][ |
][ |
][ |
][ |
] |
|
верхушка стека |
|
|
|
|
|
основание стека |
|
Переполнение буфера.
Переполнение буфера - результат помещения в буфер объема данных большего, чем тот,
74
на который он рассчитан. Как же эту ошибку можно использовать для исполнения произвольного кода в контексте программы? Вот пример:
example2.c
-----------------------------------------------------------------------------
-
void function(char *str) { char buffer[16];
strcpy(buffer,str);
}
void main() {
char large_string[256]; int i;
for( i = 0; i < 255; i++) large_string[i] = 'A';
function(large_string);
}
-----------------------------------------------------------------------------
-
В этой программе присутствует типичная ошибка переполнения буфера. В функции происходит копирование переданную ей строку без проверки ее размера (используется strcpy() вместо strncpy()).В результате мы получаем segmentation violation. Давайте посмотрим на стек: 1
нижние адреса памяти |
|
|
|
верхние адреса памяти |
|
<------ |
buffer |
sfp |
ret |
][ |
*str |
[ |
][ |
][ |
] |
||
верхушка стека |
|
|
|
|
основание стека |
Что здесь происходит? Почему мы получаем segmentation violation? Объясняется все просто: strcpy() копирует содержимое *str(larger_string[]) в буфер buffer[], пока не встретится null byte ('\0').Размер buffer[] меньше, чем *str(16 байт против 256).Это значит, что 250 байт памяти ,идущие за буфером и не имеющих никакого к нему отношения, будут перезаписаны.В их число войдут SFP, RET и даже *str. Мы заполнили large_string символами 'А'(шестнадцатеричное значение 0х41).Это значит, что адрес возврата теперь 0x41414141.Это значение выходит за пределы адресного пространства процесса.Вот почему, когда происходит возврат из функции ,то попытка выполнить очередную инструкцию по этому адресу приводит к segmentation violation.
Таким вот образом переполнение буфера позволяет изменить адрес возврата из функции и становится возможным изменить ход выполнения программы.
75

Архитектура IPSec
IP Security - это комплект протоколов, касающихся вопросов шифрования, аутентификации и обеспечения защиты при транспортировке IP-пакетов. Первоначально IPsec включал в себя 3 алгоритмо-независимые базовые спецификации, опубликованные в качестве RFC-документов "Архитектура безопасности IP", "Аутентифицирующий заголовок (AH)", "Инкапсуляция зашифрованных данных (ESP)". Кроме этого, существуют несколько алгоритмо-зависимых спецификаций, использующих протоколы
MD5, SHA, DES.
Рис. 1 – Архитектура IPSec.
Рабочая группа IP Security Protocol разрабатывает также и протоколы управления ключевой информацией. Гарантии целостности и конфиденциальности данных в спецификации IPsec обеспечиваются за счет использования механизмов аутентификации и шифрования соответственно.
По сути, IPSec, который станет составной частью IPv6, работает на третьем уровне, т. е. на сетевом уровне. В результате передаваемые IP-пакеты будут защищены прозрачным для сетевых приложений и инфраструктуры образом. В отличие от SSL (Secure Socket Layer), который работает на четвертом (т. е. транспортном) уровне и теснее связан с более высокими уровнями модели OSI, IPSec призван обеспечить низкоуровневую защиту.
К IP-данным, готовым к передаче по виртуальной частной сети, IPSec добавляет заголовок для идентификации защищенных пакетов. Перед передачей по Internet эти пакеты инкапсулируются в другие IP-пакеты. IPSec поддерживает несколько типов шифрования,
в том числе Data Encryption Standard (DES) и Message Digest 5 (MD5).
Чтобы установить защищенное соединение, оба участника сеанса должны иметь возможность быстро согласовать параметры защиты, такие как алгоритмы аутентификации и ключи. IPSec поддерживает два типа схем управления ключами, с помощью которых участники могут согласовать параметры сеанса.
С текущей версией IP, IPv4, могут быть использованы или Internet Secure Association Key Management Protocol (ISAKMP), или Simple Key Management for Internet Protocol.
76

Заголовок AH
Аутентифицирующий заголовок (AH) является обычным опциональным заголовком и, как правило, располагается между основным заголовком пакета IP и полем данных. Наличие AH никак не влияет на процесс передачи информации транспортного и более высокого уровней. Основным и единственным назначением AH является обеспечение защиты от атак, связанных с несанкционированным изменением содержимого пакета, и в том числе от подмены исходного адреса сетевого уровня.
Формат AH достаточно прост и состоит из 96-битового заголовка и данных переменной длины, состоящих из 32-битовых слов. Названия полей достаточно ясно отражают их содержимое: Next Header указывает на следующий заголовок, Payload Len представляет длину пакета, SPI является указателем на контекст безопасности и Sequence Number Field содержит последовательный номер пакета.
Рис. 3 – Формат заголовка AH.
Последовательный номер пакета, значение этого поля формируется отправителем и служит для защиты от атак, связанных с повторным использованием данных процесса аутентификации.
Средство защиты от внесения целенаправленных изменений − это, то что в процессе формирования AH последовательно вычисляется хэш-функция от объединения самого пакета и некоторого предварительно согласованного ключа, а затем от объединения полученного результата и преобразованного ключа.
Заголовок ESP
В случае использования инкапсуляции зашифрованных данных заголовок ESP является последним в ряду опциональных заголовков, "видимых" в пакете. Поскольку основной целью ESP является обеспечение конфиденциальности данных, разные виды информации могут требовать применения существенно различных алгоритмов шифрования. Следовательно, формат ESP может претерпевать значительные изменения в зависимости от используемых криптографических алгоритмов. Тем не менее, можно выделить следующие обязательные поля: SPI, указывающее на контекст безопасности и Sequence Number Field, содержащее последовательный номер пакета. Поле "ESP Authentication Data" (контрольная сумма), не является обязательным в заголовке ESP. Получатель пакета ESP расшифровывает ESP заголовок и использует параметры и данные применяемого алгоритма шифрования для декодирования информации транспортного уровня.
77
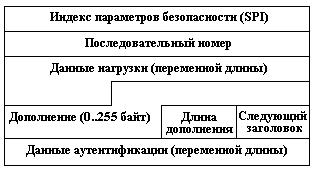
Рис. 4 – Формат заголовка ESP.
Различают два режима применения ESP и AH (а также их комбинации) - транспортный и туннельный.
Транспортный режим
Транспортный режим используется для шифрования поля данных IP пакета, содержащего протоколы транспортного уровня (TCP, UDP, ICMP), которое, в свою очередь, содержит информацию прикладных служб. Примером применения транспортного режима является передача электронной почты. Все промежуточные узлы на маршруте пакета от отправителя к получателю используют только открытую информацию сетевого уровня и, возможно, некоторые опциональные заголовки пакета (в IPv6). Недостатком транспортного режима является отсутствие механизмов скрытия конкретных отправителя и получателя пакета, а также возможность проведения анализа трафика. Результатом такого анализа может стать информация об объемах и направлениях передачи информации, области интересов абонентов, расположение руководителей.
Туннельный режим
Туннельный режим предполагает шифрование всего пакета, включая заголовок сетевого уровня. Туннельный режим применяется в случае необходимости скрытия информационного обмена организации с внешним миром. При этом, адресные поля заголовка сетевого уровня пакета, использующего туннельный режим, заполняются межсетевым экраном организации и не содержат информации о конкретном отправителе пакета. При передаче информации из внешнего мира в локальную сеть организации в качестве адреса назначения используется сетевой адрес межсетевого экрана. После расшифровки межсетевым экраном начального заголовка сетевого уровня пакет направляется получателю
78
О новом подходе к распределению ключей было рассказано в [68], в одной статье говорилось о телефонах, "перепрограммируемых раз в год по безопасному телефонному каналу ", что весьма вероятно предполагает использование протокола проверки сертификатов, аналогичного описанному [в разделе 24.3], который минимизирует для телефонов необх о- димость общаться с центром управления ключами . Последние известия были более информативными , в них рассказывалось о системе управления ключами, названной FIREFLY, которая [1341] "разработана на базе технологии открытых ключей и используется для распределения ключей шифрования попарного трафика". И это описание, и свидетельские показания, данные Конгрессу США Ли Ньювиртом (Lee Neuwirth) из Cylink [1164] предполагают использование комбинации обмена ключами и сертификатами, аналогичного используемому в безопасных телефонах ISDN. Весьма вероятно, что FIREFLY также основана на возведении в степень.
STU-III производятся AT&T и GE. За 1994 год было выпущено 300000-400000 штук . Новая версия, Secure Terminal Equipment (STE, Безопасный терминал), будет работать по линиям ISDN.
24.5 KERBEROS
Kerberos представляет собой разработанный для сетей TCP/IP протокол проверки подлинности с доверенной третьей стороной. Служба Kerberos, работающая в сети, действует как доверенный посредник, обеспечивая безопасную сетевую проверку подлинности, дающую пользователю возможность работать на нескольких маш и- нах сети. Kerberos на симметричной криптографии (реализован DES, но вместо него можно использовать и другие алгоритмы). При общении с каждым объектом сети Kerberos использует отличный общий секретный ключ, и знание этого секретного ключа равносильно идентификации объекта .
Kerberos был первоначально разработан в МТИ для проекта Афина . Модель Kerberos основана на протоколе Needham-Schroeder с доверенной третьей стороной (см. раздел 3.3) [1159]. Оригинальная версия Kerberos, Версия 4, определена в [1094, 1499]. (Версии с 1 по 3 были внутренними рабочими версиями .) Версия 5, модификация Версии 4, определена в [876, 877, 878]. Лучшим обзором по Kerberos является [1163]. Другие обзорные статьи - [1384, 1493], использование Kerberos в реальном мире хорошо описано в [781, 782].
Модель Kerberos
Базовый протокол Kerberos был схематично описан в разделе 3.3. В модели Kerberos существуют расположенные в сети объекты - клиенты и серверы . Клиентами могут быть пользователи, но могут и независимые пр о- граммы, выполняющие следующие действия : загрузку файлов, передачу сообщений, доступ к базам данных, доступ к принерам, получение административных привилегий , и т.п.
Kerberos хранит базу данных клиентов и их секретных ключей . Для пользователей-людей секретный ключ является зашифрованным паролем. Сетевые службы, требующие проверки подлинности, и клиенты, которые хотят использовать эти службы, регистрируют в Kerberos свои секретные ключи.
Так как Kerberos знает все секретные ключи, он может создавать сообщения, убеждающие один объект в подлинности другого. Kerberos также создает сеансовые ключи, которые выдаются клиенту и серверу (или двум клиентам) и никому больше. Сеансовый ключ используется для шифрования сообщений, которыми обменив а- ются две стороны, и уничтожается после окончания сеанса .
Для шифрования Kerberos использует DES. Kerberos версии 4 обеспечивал нестандартный, слабый режим проверки подлинности - он не мог определить определенный изменения шифротекста (см. раздел 9.10). Kerberos версии 5 использует режим CBC.
|
|
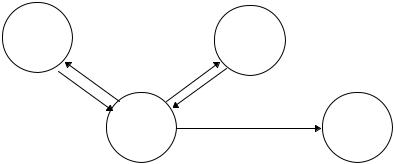
1. |
Запрос мандата на выделение мандата |
|
|
|
2. |
Мандат выделения мандата |
|
Kerberos |
TGS |
3. |
Запрос мандата сервера |
|
4. |
Мандат сервера |
|||
|
|
|||
|
|
5. |
Запрос услуги |
23
1 |
4 |
|
|
|
|
Клиент |
5 |
Сервер |
|
Рис. 24-1. Этапы проверки подлинности Kerberos
Как работает Kerberos
В этом разделе рассматривается Kerberos версии 5. Ниже я обрисую различия между версиями 4 и 5 . Протокол Kerberos прост (см. 23rd). Клиент запрашивает у Kerberos мандат на обращение к Службе выделения мандатов (Ticket-Granting Service, TGS). Этот мандат, зашифрованный секретным ключом клиента, посылается
79