

Ответы к экзамену (2)
.pdf11
Архитектура с общей памятью
·Многовходовая память См. выше.
·Многопроцессорная ВС
·Топология типа “Butterfly”

12
4. Формы и характеристики параллелизма. Распараллеливание последовательных программ. Критерии и параметры сложности параллелизма.
Типы параллелизма
1.На уровне битов -- эта форма параллелизма основана на увлечении размера машинного слова
2.На уровне инструкций -- некоторые инструкции можно выполнять параллельно. Это понятие также включает в себя:
a.Конвейер комманд
b.Суперскалярность -- архитектура вычислительного ядра, использующая несколько декодеров команд, которые могут загружать работой множество исполнительных блоков. Планирование исполнения потока команд является динамическим и осуществляется самим вычислительным ядром.
3.Параллелизм данных -- одна операция выполняется сразу над всеми элементами массива данных. Различные фрагменты такого массива обрабатываются на векторном процессоре или на разных процессорах параллельной машины. Распределением данных между процессорами занимается программа. Векторизация или распараллеливание в этом случае чаще всего выполняется уже на этапе компиляции — перевода исходного текста программы в машинные команды. Роль программиста в этом случае обычно сводится к заданию настроек векторной или параллельной оптимизации компилятору, директив параллельной компиляции, использованию специализированных языков для параллельных вычислений.
4.Параллелизм задач -- Стиль программирования, основанный на параллелизме задач, подразумевает, что вычислительная задача разбивается на несколько относительно самостоятельных подзадач и каждый процессор загружается своей собственной подзадачей.
Характеристики паралеллизма
●Ускорение. C(N)=t(1)/t(N)
●Эффективность. E(N)=C(N)/N
●
Закон Амдаля. C(N)= |
a -- доля последовательных вычислений |
Формы параллелизма
Явный – существуют специальные средства ЯП для отражения параллелизма (распараллеливанием занимается программист)
Неявный – параллелизм функциональных или логических программ (распараллеливанием занимается сам программный инструмент)
Коммутативный – означает, что независимые элементы (операторы, функции, предгикаты и т.п.) могут выполняться в произвольном порядке, не меняя общего результата выполнения программы. Некоммутативный – напротив, предполагает, что только параллельное выполнение независимых элементов программы гарантирует правильность получения результата. Ограниченный – означает, что при любом выполнении программы (при любом применении ее к исходным данным) число ее компонентов, которые могут одновременно выполняться не превышает некоторое натуральное число, равное к.
Если такого к не существует, то программа имеет неограниченный параллелизм. Строгий параллелизм связан с теми компонентами программы, которые существенны для формирования результата ее выполнения.

13
Откладываемый параллелизм часто называют также упреждающим, относя его к тем независимым компонентам программ, о которых заранее нельзя сказать, результаты выполнения каких из них будут использоваться в дальнейшем
If p1(x)&p2(x) then f1(x) else f2(x)
Можно считать p1, p2, f1, f2 одновременно, причем f1 и f2 с упреждением. Детерминированный – статически заданный Недетерминированный – динамически порождаемый в процессе выполнения.
Синхронный - одновременность выполнения актов строго синхронизуется. Синхронизация по концу выполняется если А2 и А3 должны быть завершены к началу А4 Синхронному параллелизму в ЯП соответствует конструкция: А1; parbegin A2;A3; parend; A4 Асинхронный. Начало и конец А2 и А4 полностью не синхронизированные.
А2 и А4 – полностью асинхронны
Синхронный параллелизм просто реализуется, но его возможности ограничены. Асинхронный параллелизм более мощен, но его реализация сложнее.
Пространственный параллелизм основан на независимости различных компонентов программы. Временной параллелизм основан на конвейризации вычислений.
Конвейер – самая экономичная схема с точки зрения загрузки ресурсов (каждая единица всегда работает). Пространственный параллелизм более объемен.
Крупнозернистый – мелкозернистый. Характеризует глубину параллелизма в программе при реализации на конкретной вычислительной системе.
Глубина распараллеливания - Глубина распараллеливания формально отражает используемое в параллельном программировании понятие granularity (зернистость). Введем следующие обозначения пусть d - глубина распараллеливания, а функцию, определяющую коэффициент ускорения будем обозначать c(x1…xn, d, k), вводя d в качестве ее параметра. 1/d - степень распараллеливания, которая характеризует усредненное количество компонентов параллельной программ, выполняемых одновременно.
Определение. Глубиной распараллеливания d назовем усредненную вычислительную сложность компонентов, которые рассматриваются в параллельной программе как самостоятельные процессы, идентифицируемые и планируемые при ее выполнении на ВС.
Обратную к d величину определим как степень распараллеливания, характеризующую усредненное количество компонентов параллельной программы, которые могут выполняться одновременно.
Ширина максимального яруса определяет наименьшее количество компьютеров ВС, который позволяет выполнять параллельный алгоритм без задержек из-за недостатка ресурсов. Эффективность использования ресурсов – показывает, насколько эффективно используются ресурсы сети. Часто используют C(x1…xn, k)/k <= 1.
14
5. Процессные модели. Сети Петри как модель параллельных процессов и ее расширения.
Процесс — выполнение пассивных инструкций компьютерной программы на процессоре ЭВМ. Стандарт ISO 9000:2000 Definitions определяет процесс как совокупность взаимосвязанных и взаимодействующих действий, преобразующих входящие данные в исходящие.
Процесс - дискретное выполнение заранее определенного множества элементарных действий. (а->b->...).
Время выполнения такого действия может быть измерено с какой то точностью. (Дискретная шкала времени).
6. Язык граф-схемного потокового параллельного программирования. Модель параллельного выполнения программ. Сравнение с MPI.
Язык граф-схемного параллельного потокового программирования (ЯГСПП) ориентирован на крупноблочное (модульное) потоковое программирование задач. Он также может эффективно применяться для моделирования распределенных систем, систем массового обслуживания и др., то есть систем, информационные связи между компонентами которых структурированы и управляются потоками данных, передаваемых по этим связям.
Язык позволяет эффективно и единообразно представлять в программах три вида параллелизма:
-параллелизм информационно-независимых фрагментов;
-потоковый параллелизм, обязанный своим происхождением конвейерному принципу обработки данных;
-параллелизм множества данных (SIMD параллелизм в классификации Флинна).
Важными с позиции программирования особенностями ЯГСПП являются возможности визуального графического представления программы и простого структурирования, отражения декомпозиционной иерархии при ее построении путем использования отношения «схемаподсхема».
Описание языка
ЯГСПП формально можно представить в виде пары языков ЯГС, ЯИ , где ЯГС – язык представления граф-схем, ЯИ –язык интерпретации. Таким образом, граф-схемная параллельная программа (ГСПП) задается ввиде двух компонентов ГС, I , где ГС – граф-схема программы на ЯГС, отражающая в модульной форме декомпозиционную структуру задачи, и I – интерпретация, сопоставляющая каждому модулю ГС подпрограмму на одном из ЯИ.
1.1. О п р е д е л е н и е Г С. Пусть М = { mi, ini, outj | i = l, 2, …} – не более чем счетное множество модулей (базисное множество), где mi – имя модуля, ini и outi – упорядоченные множества
или кортежи входных точек (входов) и выходных точек (выходов) модуля mi.
В общем случае у модуля может быть несколько групп входов. В связи с представлением в ГСПП условных конструкций входные и выходные точки модулей разделяются на две группы, образуя два кортежа безусловных и условных входов. Точки кортежа безусловных входов изображаются в виде круглых точек, а точки безусловного кортежа – в виде квадратных точек. ???
Данные,
15
поступающие на входные точки модуля безусловного кортежа его входов, однозначно связываются с кортежем входных параметров подпрограммы, сопоставляемой модулю в интерпретации (см. далее). По данным булевского типа, поступающим на условные входы модуля, определяется
необходимость применения сопоставленной ему подпрограммы к кортежу данных на безусловных входах модуля. Условием этого является значение “истина” на всех условных входах модуля. На рис. 1 приведено графическое изображение модуля с i_м количеством групп входов, у каждой из них по два кортежа входных точек, один из которых представляет безусловные входы, а другой – условные.
ГС в базисе M определяется в виде четверки М', C, Pвх, Pвых . Здесь M' – конечное подмножество модулей из M, C – функция-предикат, задающая связи между выходными и входными точками модулей: C: OUT × IN → {0, 1}, где IN и OUT – множества всех входных и выходных точек
модулей из M'. Для in IN и out OUT C(out, in) = 1, если существует связь между выходной точкой out некоторого модуля ГС и входной точкой in другого (возможно, того же самого) модуля; в противном случае C(out, in) = 0.
В определении ГС Pвх IN* и Рвых OUT*, обозначают кортежи входных (безусловных) и выходных (безусловных) точек ГС. Кортежи входных точек ГС используются для задания данных, к которым должна применяться ГСПП, а кортеж выходных точек идентифицирует выходные точки модулей ГС, на которые поступают результаты выполнения ГСПП.
Отметим, что кортежи Pвх и Pвых ГС, так же, как и кортежи входных и выходных точек модулей, могут быть пустыми. Модули с пустым кортежем входных точек в интерпретации выполняют роль генераторов данных, которые в принципе могут считываться подпрограммой модуля с указанного носителя данных, а модули без выходных точек используются как фиксаторы результатов выполнения ГСПП, в частности их подпрограммы запоминают эти результаты
на соответствующих устройствах КС, на которой выполняется ГСПП. Также отметим, что при изображении связей между модулями ГС невозможно избежать пересечений, поэтому принято соглашение, что если на пересекающихся связях указана точка, то все эти связи рассматриваются как идентичные в том смысле, что любое данное, возникающее на одной из связей при выполнении ГСПП, одновременно передается по всем связям. Если на пересечении связей точка отсутствует, они считаются различными.
1.2. И н т е р п р е т а ц и я Г С. В интерпретации каждому кортежу безусловных входов каждой группы входов каждого модуля ГС сопоставляется подпрограмма на одном из последовательных языков программирования (C, C++, ФОРТРАН и др.), причем для описания разных подпрограмм могут использоваться различные языки, в том числе с возможностью задания параллелизма в них другими средствами, например, используя MULTITHREADING. Таким образом, интерпретацией модулю сопоставляется в общем случае множество подпрограмм (функций), число которых равно числу групп входов модуля.
Поскольку при выполнении ГСПП она может применяться к потоку входных данных, в том числе генерируемому в реальном времени, перемещаемые по связям между модулями данные снабжаются целочисленными метками или тегами. Тегирование позволяет устанавливать однозначное соответствие между входными данными, генерируемыми в общем случае в виде потоков, и результатами применения к ним ГСПП при одновременном асинхронном выполнении
множества копий подпрограмм различных модулей ГСПП. С этой целью заголовок подпрограммы имеет вид P(integer: tag; t1: x1, t2: x2, …, tm: xm), и переменной tag при инициализации выполнения подпрограммы присваивается тег, которым были снабжены данные, поступившие на безусловные входы соответствующей этой подпрограмме группы входов модуля. При этом кортеж

16
входных точек этой группы входных точек модуля и кортеж формальных параметров подпрограммы x1, x2, …, xm с указанными в заголовке их типами имеют одинаковую длину и между ними устанавливается поэлементное взаимно однозначное соответствие в порядке перечисления
элементов кортежей. Для большей информативности входные точки модуля ГС могут сопровождаться указанием типов поступающих на них данных. При этом типы выходных точек совпадают с типами связанных с ними входных точек модуля.
Модель выполнения ГСПП (см. разд. 3) предполагает возможность одновременного применения копий подпрограммы любого модуля ко всем кортежам поступивших одинаково тегированных данных при условии наличия значений истина на всех условных входах модуля с тем же тегом, что и у данных на безусловных входах (фактических параметрах подпрограммы). Для реализации передачи тегированных данных между модулями ГСПП при ее выполнении, а также для управления из подпрограммы модуля потоком входных данных в ЯГСПП введены системные команды.
Команда WRITE (tag, (номер выхода, переменная), (номер выхода, переменная), …, (номер выхода, переменная)) передает при выполнении подпрограммы на указанные выходы модуля значения, присвоенные указанным переменным, с тегом, присвоенным переменной tag.
Команда READ 1 (группа входов, tag, (номер входа, переменная), (номер входа, переменная), …, (номер входа, переменная)) позволяет “прочитать” поступившие на входы группы входов моду_ ля данные с тегом tag, присваивая их соответствующим переменным. Если данные не поступили, выполнение команды READ1 задерживается до момента поступления запрашиваемых данных.
Команда READ2 (группа входов, tag, переменная 1, (номер входа, переменная), (номер входа, переменная), …, (номер входа, переменная)) дает возможность подпрограмме проверить посту_ пили или нет на входы указанной группы входов модуля данные с тегом tag. При этом, если данные поступили, они присваиваются перечисленным в команде переменным и управление воз_ вращается подпрограмме. В противном случае переменной “переменная!" присваивается значение ложь (0) и управление возвращается подпрограмме.
Команда SAVE ((tag, переменная), (tag, переменная), …, (tag, переменная)) используется для передачи управлению результатов выполнения ГСПП, снабжая каждую переменную, идентифицирующую результат, соответствующим тегом.
Еще одна системная команда STOP (имя ГСПП, имя модуля) предназначена для контроля завершения ГСПП. Параметры “имя ГСПП”, “имя модуля” позволяют управлению определить окончание выполнения ГСПП и ссылку на завершающий модуль.
Для инициализации ГСПП в реализации языка применяется команда ЕХЕСиТЕ(имя ГСПП, адрес хранения, имя модуля: (вход, (tag, значение), …, (tag, значение)); имя модуля: (вход, (tag, значение), …, (tag, значение)), …, имя модуля: (вход, (tag, значение), …, (tag, значение))). Здесь пара (вход, (tag, значение)) указывает, на какой вход модуля при инициализации ГСПП должно быть передано значение с тегом tag.
17
Завершение выполнения ГСПП контролируется либо по команде STOP, либо по условию завершения всех инициализированных подпрограмм модулей и отсутствию готовых для выполнения новых процессов. Важно отметить, что после выполнения команд WRITE и READ2 управление сразу возвращается к следующей за ними команде подпрограммы. Выполнение команды
READ1 приостанавливается, если затребованные ею данные еще не поступили, и только после того, как все данные получены, присвоены указанным переменным, управление передается следующей за READ1 команде в подпрограмме.
Таким образом, команды READ1 и READ2 позволяют управлять потоком поступающих на вход модуля данных. Команда READ2, дает возможность реализации большей асинхронности при управлении потоками данных, проверяя поступили они или нет, и в соответствии с этим принимать решение о выполнении тех или иных действий в подпрограмме.
С целью достижения большей асинхронности и обеспечения возможности чтения картежей данных, поступающих на входы модуля, в командах READ1 и READ2 нулевое значение тега используется как указатель на возможность чтения данных, поступивших на все безусловные входы
модуля с произвольным тегом. В этом случае, выполняя команды READ1 или READ2 с нулевым тегом, управление присваивает переменной tag в списке параметров подпрограммы значение тега считываемого кортежа данных. Таким образом, выполняя команды READ1 и READ2, подпрограмма получает необходимую информацию о данных, к которым она применяется.
В заключение отметим, что в реализации ЯГСПП, в частности, созданной среде проектирования, анализа и оптимизации ГСПП [8, 9], ее модули могут снабжаться описательной информацией, касающейся задания типов данных на входах и выходах модулей ГС, особенностей подпрограмм модулей, в частности, используемых в них методов, их вычислительной сложности, применяемого языка программирования для описания подпрограмм и т.п.
Пример граф-схемной программы
Рассмотрим пример построения следующей последовательной подпрограммы: begin
real array x, y[l–n]; integer n;
for i = 1 step 1 until n do begin
x[i] = считать i_e данное(имя носителя, имя файла); y[i] = F(x[i]);
print (y[i]); end
end,
где F(x) = if p(x) then f(x) else F(g(f1(x), f2(x))).
Здесь команда “считать” считывает по очереди элементы массива, хранящиеся в виде файла на указанном носителе.
На рис. 2 приведена ГС, а ниже дана интерпретация для модулей ГСПП, построенной для этой последовательной программы и названной G.
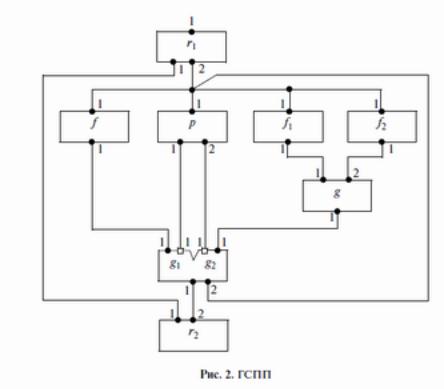
18
Интерпретация:
I(ri): subprogram Sr1(integer tag, n) //при инициализации ГСПП на вход модуля r1 real array x[i–n]; real у; //задается значение п с нулевым тегом.
begin
WRITE(tag, (1, n));
for i = 1 step 1 until n do begin
x[i] = считать i_e данное (имя носителя, имя файла); WRITER (2, x[i]));
end
end
end,
I(f): subprogram Sf (integer tag, real x) real y;
begin
y = f(x);
WRITE (tag,(1, y)); end
end,
I(p): subprogram Sp (integer tag, real x) integer t1, t2;
begin
t1 = l; t2 = 0;
if p(x) then WRITE(tag, (1, t1), (2, t2)) else WRITE(tag, (1, t2), (2, t1)); end
end,
I(f1): subprogram Sf1 (integer tag, real x) begin
x = f1(x);
WRITE (tag, (1, x)); end
end,
19
I(f2): subprogram Sf2 (integer tag, real x) begin
x = f2(x); WRITE(tag, (1, x)); end
end,
I(g): subprogram Sg (integer tag, real x1, x2) real y;
begin
y = g(x1, x2); WRITE(tag, (1, y)); end
end,
I(g1): subprogram Sg1 (integer tag, real x) begin
WRITE(tag, (1, x)); end
end
I(g2): subprogram Sg2 (integer tag, real x) begin
WRITE(tag, (2, x)); end
end,
I(r2): subprogram Sr2(integer tag, n, real x) begin
SAVE(tag, x);
for i = 1 step 1 until n_1 do begin
READl(0, (2, x)); SAVE(tag, x); end
STOP(G, r2); end
end.
Сделаем краткие пояснения для данной ГСПП. Во-первых, в ней мы попытались полностью выразить существующий в исходной последовательной программе параллелизм: пространственный (возможность одновременного выполнения функций f, p, f1 и f2) и потоковый, вытекающий
из возможности независимого вычисления элементов y[i] нового массива. Кроме того, в ГСПП
значения функций f, f1, и f2 вычисляются подпрограммами соответствующих модулей с упреждением, тем самым увеличивая параллелизм программы. Поскольку элементы y[i] поступают на
вход 2 модуля r2 в общем случае в произвольном порядке, запоминаемые командой SAVE значения можно затем упорядочить, используя теги согласно принятому порядку хранения в памяти элементов массива.
В качестве параметра подпрограммы модуля r1, который должен задать с помощью команды EXECUTE программист перед выполнением ГСПП, используется целочисленная переменная n – размер массива. Задаваемое значение тега у этой переменной равно 0. Поэтому в подпрограмме модуля r2 перед его первым выполнением в качестве входных параметров применяется значение n с нулевым тегом и поступившее первым на его вход 2 значение x с произвольным тегом.
У повторяющейся команды READ1 в подпрограмме модуля r2 нулевое значение тега позволяет считывать со входа 2 поступающие данные с произвольным тегом, обеспечивая таким образом большую асинхронность и параллелизм при выполнении ГСПП. Отметим, что данная ГСПП не имеет выходов, а ее окончание контролируется командой STOP в подпрограмме модуля r2.
20
7. Средства параллельного программирования MPI, планирование выполнения MPI программ. Сравнение с другими языками и средствами параллельного программирования (MULTITHREADING, ЯГСПП (см. вопрос 6), и др.)
Message Passing Interface (MPI, интерфейс передачи сообщений) — программный интерфейс API) для передачи информации, который позволяет обмениваться сообщениями между процессами, выполняющими одну задачу. Разработан Уильямом Гроуппом, Эвином Ласком англ ) и другими.
MPI является наиболее распространённым стандартом интерфейса обмена данными в параллельном программировании, существуют его реализации для большого числа компьютерных платформ. Используется при разработке программ для кластеров и суперкомпьютеров. Основным средством коммуникации между процессами в MPI является передача сообщений друг другу. Стандартизацией MPI занимается MPI Forum. В стандарте MPI описан интерфейс передачи сообщений, который должен поддерживаться как на платформе, так и в приложениях пользователя. В настоящее время существует большое количество бесплатных и коммерческих реализаций MPI. Существуют реализации для языков Фортран 77/90, Си и Си++.
Впервую очередь MPI ориентирован на системы с распределенной памятью, то есть когда затраты на передачу данных велики, в то время как OpenMP ориентирован на системы с общей памятью (многоядерные с общим кэшем). Обе технологии могут использоваться совместно, дабы оптимально использовать в кластере многоядерные системы.
ВMPI 1.1 (опубликован 12 июня 1995 года, первая реализация появилась в 2002 году) поддерживаются следующие функции:
●передача и получение сообщений между отдельными процессами;
●коллективные взаимодействия процессов;
●взаимодействия в группах процессов;
●реализация топологий процессов;
ВMPI 2.0 (опубликован 18 июля 1997 года) дополнительно поддерживаются следующие функции:
●динамическое порождение процессов и управление процессами;
●односторонние коммуникации (Get/Put);
●параллельный ввод и вывод;
●расширенные коллективные операции (процессы могут выполнять коллективные операции не только
внутри одного коммуникатора, но и в рамках нескольких коммуникаторов).
азовым механизмом связи между MPI процессами является передача и приём сообщений. Сообщение несёт в себе передаваемые данные и информацию, позволяющую принимающей стороне осуществлять их выборочный приём:
●отправитель — ранг (номер в группе) отправителя сообщения;
●получатель — ранг получателя;
●признак — может использоваться для разделения различных видов сообщений;
●коммуникатор — код группы процессов.
Операции приёма и передачи могут быть блокирующимися и не блокирующимися. Для не блокирующихся операций определены функции проверки готовности и ожидания выполнения операции.
Другим способом связи является удалённый доступ к памяти (RMA), позволяющий читать и изменять область памяти удалённого процесса. Локальный процесс может переносить область памяти удалённого процесса (внутри указанного процессами окна) в свою память и обратно, а также комбинировать данные, передаваемые в удалённый процесс с имеющимися в его памяти данными (например, путём суммирования). Все операции удалённого доступа к памяти не блокирующиеся, однако, до и после их выполнения необходимо вызывать блокирующиеся функции синхронизации.