

Ответы к экзамену (2)
.pdf1
Вопросы к экзамену по ПС
1.Современные компьютеры, архитектура, технические характеристики, способы повышения быстродействия и производительности при выполнении программ. Примеры.
Технические характеристики устройств Методы повышения быстродействия процессора
2.Режимы работы компьютеров, планирование процессов и распределение ресурсов: процессоров, памяти, каналов.
Режимы работы компьютера Критерии планирования Алгоритмы планирования Память
3.Архитектура компьютерных систем; классификация, технические характеристики, организация коммуникаций. Примеры.
Класификация Флина Классификация по Кутепову Организация коммутации
4.Формы и характеристики параллелизма. Распараллеливание последовательных программ. Критерии и параметры сложности параллелизма.
Типы параллелизма Характеристики паралеллизма
5.Процессные модели. Сети Петри как модель параллельных процессов и ее расширения.
6.Язык граф-схемного потокового параллельного программирования. Модель параллельного выполнения программ. Сравнение с MPI.
Описание языка Пример граф-схемной программы
7.Средства параллельного программирования MPI, планирование выполнения MPI программ. Сравнение с другими языками и средствами параллельного программирования
(MULTITHREADING, ЯГСПП (см. вопрос 6), и др.)
8.Язык FPTL: синтаксис (операция композиции функций, задание данных), семантика. Модели параллельного вычисления значений функций.
9.Структурный анализ FPTL программ
10.Анализ вычислительной сложности FPTL программ
11.Распараллеливание последовательных программ путем трансляции в FPTL программы
12.Средства параллельного программирования MULTITHREADING. Модель параллельного выполнения программ, реализация на многоядерных компьютерах.
13.Технологии проектирования параллельных программ, сравнение с технологиями проектирования последовательных программ.
14.Сетевое представление FPTL программ. Приведение их к максимальной параллельной форме.
15.Управление параллельными процессами в компьютерах и компьютерных системах. Организация управления.
2.Разработка транслятора для трансформации инфиксной формы задания функций в принятую в FPTL схемную форму.
3.Разработка программных средств графического проектирования граф-схемных программ.
4.Разработка программных средств поддержки проектирования FPTL-программ.
5.Разработка FPTL-программ для задач синтаксического анализа. Исследование их эффективности на многоядерных компьютерах.
2
1. Современные компьютеры, архитектура, технические характеристики, способы повышения быстродействия и производительности при выполнении программ. Примеры.
В основе архитектуры современного компьютера лежит предложенная фон-Нейманом архитектура. Также Фон-Нейманом в 40х годах были сформулированы пять принципов логического конструирования вычислительных устройств, которые актуальны и в современных компьютерах:
1.Принцип двоичного кодирования. Согласно этому принципу, вся информация, поступающая в ЭВМ, кодируется с помощью двоичных сигналов (двоичных цифр, битов) и разделяется на единицы, называемые словами.
2.Принцип однородности памяти. Программы и данные хранятся в одной и той же памяти. Поэтому ЭВМ не различает, что хранится в данной ячейке памяти - число, текст или команда. Над командами можно выполнять такие же действия, как и над данными.
3.Принцип адресуемости памяти. Структурно основная память состоит из пронумерованных ячеек; процессору в произвольный момент времени доступна любая ячейка. Отсюда следует возможность давать имена областям памяти, так, чтобы к запомненным в них значениям можно было бы впоследствии обращаться или менять их в процессе выполнения программы с использованием присвоенных имен.
4.Принцип последовательного программного управления. Предполагает, что программа состоит из набора команд, которые выполняются процессором автоматически друг за другом в определенной последовательности.
5.Принцип жесткости архитектуры. Неизменяемость в процессе работы топологии, архитектуры, списка команд.
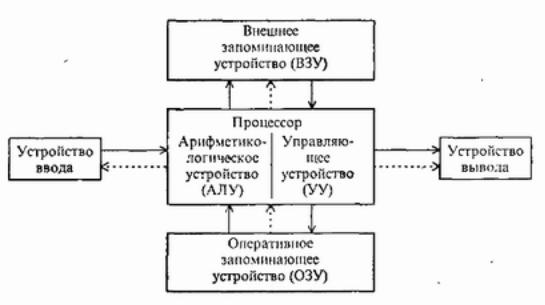
Классическая фон-Неймановская архитектура вычислительного устройства имела следующий вид, на ней строились ЭВМ первого и второго поколений
Альтернативной архитектуре фон-Неймана является Гарвардская архитектура. Гарвардская архитектура отличается от архитектуры фон Неймана тем, что программный код и данные хранятся в разной памяти. В такой архитектуре невозможны многие методы программирования (например, программа не может во время выполнения менять свой код; невозможно динамически перераспределять память между программным кодом и данными); зато гарвардская архитектура позволяет более эффективно выполнять работу в случае ограниченных ресурсов, поэтому она
3
часто применяется во встраиваемых системах.
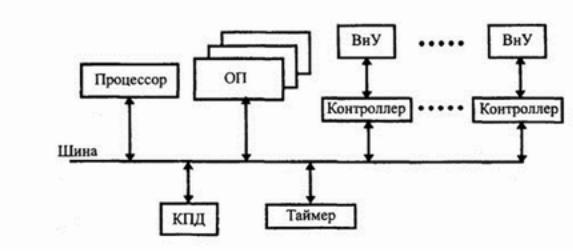
От первого поколения до четвертого архитектура ЭВМ претерпела некоторые изменения и приняла следующий вид:
Соединение всех устройств в единую машину обеспечивается с помощью общей шины, представляющей собой линии передачи данных, адресов, сигналов управления и питания. Единая система аппаратурных соединений значительно упростила структуру, сделав ее еще более децентрализованной. Все передачи данных по шине осуществляются под управлением сервисных программ.
Ядро ПЭВМ образуют процессор и основная память (ОП), состоящая из оперативной памяти и постоянного запоминающего устройства (ПЗУ). ПЗУ предназначается для записи и
постоянного хранения наиболее часто используемых программ управления. Подключение всех внешних устройств (ВнУ), дисплея, клавиатуры, внешних ЗУ и других обеспечивается через соответствующие адаптеры - согласователи скоростей работы сопрягаемых устройств или контроллеры - специальные устройства управления периферийной аппаратурой. Контроллеры в ПЭВМ играют роль каналов ввода-вывода. В качестве особых устройств следует выделить таймер - устройство измерения времени и контроллер прямого доступа к памяти (КПД) - устройство, обеспечивающее доступ к ОП, минуя процессор.
Способ формирования структуры ПЭВМ является достаточно логичным и естественным стандартом для данного класса ЭВМ.
Децентрализация построения и управления вызвала к жизни такие элементы, которые являются общим стандартом структур современных ЭВМ:
•модульность построения,
•магистральность,
•иерархия управления.
Технические характеристики устройств
Процессор:
●Тактовая частота – число синхроимпульсов, поступающих извне на вход за секунду. (1-3.9 ГГц)
●Разрядность шины данных – 16, 32, 64 – определяет разрядность двоичного числа с которым может работать процессор за один такт.
●Разрядность шины адреса - 16, 32, 64 – определяет максимальный разряд двоичного числа, которое является адресом ячейки памяти
●Энергопотребление (Ватт/ч)
●Входное напряжение (Вольт)

4
●Объем кешей: L1 <=128 Кб латентность 2-4 такта, L2 до 2Мб латентность 8-20 тактов, L3 до
10 Мб
Оперативная память:
●Объем памяти – 512 Мб-32Гб
●Латентность 2-9 тактов системной шины(до 1 мкС). Частота системной шины до 4Ггц
●Пропускная способность (частота шины * V данных) от 2 до 20 Гб/c
●Размер страницы памяти (обычно в 32х разрядных системах 2^12=4096 байт)
●Размер сегмента памяти (обычно в 32х разрядных системах 2^12*2^12=2^24=16 Мб) Жесткий диск:
●Количество оборотов в минуту 5600, 7200 10000 об/минуту
●Латентность доступа=движение головки от оси к дорожке, ожидание данных на дорожек (1- 2 мс)
●Объем (до 2 Тб)
Производительность-- Среднее число комманд(в многокомандном режиме)\програм в ед времени
FLOPS
Быстродейтвие -- как быстро можно выполнить одну программу
Методы повышения быстродействия процессора
Схема выполнения (команд) программы.
Параллельная обработка данных имеет две разновидности:
●конвейерная
●параллельная.
Параллельная обработка.
Если некое устройство выполняет одну операцию за единицу времени, то тысячу операций оно выполнит за тысячу единиц. Если предположить, что есть пять таких же независимых устройств, способных работать одновременно, то ту же тысячу операций система из пяти устройств может выполнить уже не за тысячу, а за двести единиц времени. Аналогично система из N устройств ту же работу выполнит за 1000/N единиц времени.
Условия для распараллеливания
1. in(O1) intersect out(O2) = NULL
2. in(O2) intersect out(O1)=NULL
3. out(O1) intersect out(O2) = NULL
Конвейерная обработка.
Конвейер был придуман Тейлором, а впервые применен Г.Фордом.
Обычно для выполнения команды надо осуществлять некоторое количество однотипных операций, каждую из которых сопоставляют одной ступени конвеера:
1.выборка команды
2.дешифровка команды
3.выборка операндов по указанным адресам
4.выполнение операции
5.сохранение результата
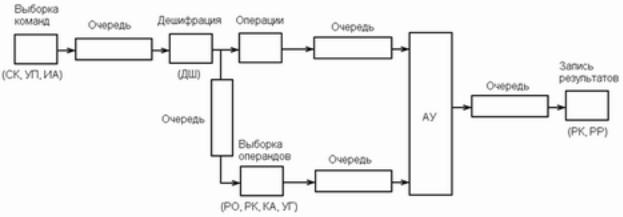
Рассмотрим схему выполнения программы, введение конвейера и анализ его работы:
5
Пояснения к схеме:
СК – счетчик команд; ИА – индексное устройство;
ДШ – дешифратор кода команд; УП – управление памятью; АУ – арифметическое устройство; РК – регистры команд; РО – регистры операнд;
РР – регистры результатов.
Идея конвейерной обработки заключается в выделении отдельных этапов выполнения общей операции, причем каждый этап, выполнив свою работу, передавал бы результат следующему, одновременно принимая новую порцию входных данных. Получаем очевидный выигрыш в скорости обработки за счет совмещения прежде разнесенных во времени операций. Конвейерную обработку можно заменить обычным параллелизмом, для чего продублировать основное устройство столько раз, сколько ступеней конвейера предполагается выделить, но, увеличивая в пять раз число устройств, мы значительно увеличиваем как объем аппаратуры, так и ее стоимость.
Пусть конвейер из n ступеней, тогда выполнение команды займет n единиц времени, без конвейера также n единиц времени. Но для m команд t=n*m-1, а в конвейере n+m единиц времени:
Tконвейера(m)=T0(разгон)+n∆t +(m-1) ∆t , ∆t – время выполнения ступени конвейера.

6
2. Режимы работы компьютеров, планирование процессов и распределение ресурсов: процессоров, памяти, каналов.
Режимы работы компьютера
1.Монопольный режим – один пользователь решает одну задачу. Это исторически первый режим работы ЭВМ. Первые машины были спроектированы только на такую работу. Этот режим отличается низким коэффициентом
использования аппаратных ресурсов. Многозадачность увеличивает загрузку аппаратных средств. Средняя скорость обработки задачи увеличивается, но падает скорость обработки конкретной задачи.
2.Пакетная обработка – в этом режиме пользователь отделён от компьютера. Пользователь формирует пакет заданий, а оператор его реализует. В задании определены ресурсы, что позволяет построить график решения
задачи. Пауз в работе меньше производительность увеличивается. Для решения повторяющихся задач – это оптимальный режим. Однако он неудобен для разработчиков программ, поскольку нет возможности непосредственной отладки программ.
3.Разделение времени – интерактивный многопользовательский режим. Организация интерактивной работы сразу многих пользователей, которые могут работать в диалоговом режиме с независимых терминалов
с распределением ресурсов между пользователями для создания иллюзии независимости работы – вытесняющая многозадачность. Машинное время делиться на кванты, и они предоставляются пользователям по определённому закону. При больших задачах этот режим не эффективен. В отличие от других режимов компьютер много тратит на поддержку данного режима. В настоящее время область применения режима сократилась.
4.Режим реального времени. Во всех предыдущих режимах физическое время не влияло на выполнение задачи. Но компьютеры часто работают с реальными объектами. Существует ряд задач, где лимитировано
время отклика. Для этого режима выпускаются специальные компьютеры – промышленные в особом исполнении. При этом процессор может оставаться универсальным, но могут применяться и специальные процессоры. Также применяются устройства связи с объектом (УСО). Ядро у таких систем простое, а периферия огромна – содержит множество датчиков и исполнительных устройств.
Критерии планирования
●Справедливость – гарантировать каждому заданию или процессу определенную часть времени использования процессора в компьютерной системе, стараясь не допустить возникновения ситуации, когда процесс одного пользователя постоянно занимает процессор, в то время как процесс другого пользователя фактически не начинал выполняться.
●Эффективность(Балансировка) – постараться занять процессор на все 100% рабочего времени, не позволяя ему простаивать в ожидании процессов, готовых к исполнению. В реальных вычислительных системах загрузка процессора колеблется от 40 до 90%.
●Сокращение полного времени выполнения ( turnaround(оборотное) time ) – обеспечить минимальное время между стартом процесса или постановкой задания в очередь для загрузки и его завершением.
●Сокращение времени ожидания ( waiting time ) – сократить время, которое проводят процессы в состоянии готовность и задания в очереди для загрузки.
●Сокращение времени отклика ( response time ) – минимизировать время, которое требуется процессу в интерактивных системах для ответа на запрос пользователя.
Алгоритмы планирования
●(Пакетная)First-Come, First-Served(FCFS) +: Справедливость, Простота - Процесс, ограниченный возможностями процессора может затормозить более быстрые процессы, ограниченные устройствами ввода/вывода.
●(пакетная)Shortest Job First(SJF) Уменьшение оборотного времени.Длинный процесс занявший процессор, не пустит более новые краткие процессы, которые пришли позже.
●(интерактивная)Round Robin(RR).+: Простата. Справедливость (как в очереди покупателей, каждому только по килограмму) -:Если частые переключения (квант - 4мс, а время переключения равно 1мс), то происходит уменьшение производительности.Если редкие переключения (квант - 100мс, а время переключения равно 1мс), то происходит увеличение времени ответа на запрос.
●(интерактивная)Приоритентное планирование
○Лотерейное планирование -- у разных процессов разное кол-во лотерейных билетов
○Статический приоритет

7
○Динамический приоритет -- обратно пропорциональный части использованного кванта. Таким образом приоритеты ограниченные вводом\выводом имеют больший приоритет
●(интерактивные)Разделение процессов на группы
○Группы с разным квантом времени Сначала процесс попадает в группу с наибольшим приоритетом и наименьшим квантом времени, если он использует весь квант, то попадает во вторую группу и т.д. Самые длинные процессы оказываются в группе наименьшего приоритета и наибольшего кванта времени.
●(интерактивные)Гарантированное планирование. Каждому 1\н времени.
●(интерактивные)Справедливое. Процессам каждого юзера 1\(кол во юзеров)
●(СРВ)Rate Monotonic Scheduling -- Для систем реального времени. Приоритет пропорционален частоте запуска
●(СРВ)Earliest Dedline First -- приоритетный тот у кого скорее дедлайн
Память
В современных компьютерах используется виртуальная память, которая отображается на физическую оперативную память и жесткий диск. Виртуальная память – теоретически доступная пользователю, объем которой определяется разрядностью шины адреса и разрядностью адресной части процессорной команды. Виртуальная память имеет сегментно-страничную организацию, адрес памяти содержит адрес сегмента, адрес страницы в сегменте и смещение внутри страницы. В 32х разрядных ОС обычно выделяется 8 разрядов под номер сегмента, 12 разрядов под номер страницы, и 12 разрядов под смещение внутри страницы.
●Статитическое выделение памяти -- вся память необходимая для работы программы выделятся сразуже. Основной минус: фрагментация
●Динамическое выделение памяти -- память выделяется по мере необходимости Виртуальная память - технология управления памятью ЭВМ, разработанная для многозадачных операционных систем. При использовании данной технологии для каждой программы используются
независимые схемы адресации памяти, отображающиеся тем или иным способом на физические адреса
впамяти ЭВМ. Позволяет увеличить эффективность использования памяти несколькими одновременно работающими программами, организовав множество независимыхадресных пространств англ ), и обеспечить защиту памяти между различными приложениями. Также позволяет программисту использовать больше памяти, чем установлено в компьютере, за счет откачки неиспользуемых страниц на вторичное хранилище (см. Подкачка страниц).
LRU (least recently used) - наиболее давно не использовавшийся;
FIFO - самый давний по пребыванию в ОЗУ;
Random - случайным образом.
8
Впервые механизм виртуальной памяти был реализован в 1959 г. на компьютере "Атлас", разработанном в Манчестерском университете.
3. Архитектура компьютерных систем; классификация, технические характеристики, организация коммуникаций. Примеры.
Класификация Флина
●SISD(single instruction stream/ single data stream)
●SIMD
●MISD
●MIMD
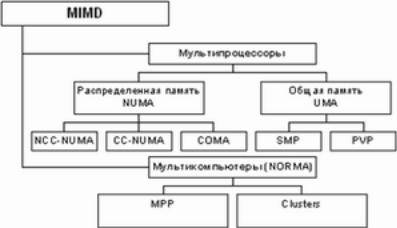
Большинство современных КС относятся к классу MIMD Рассмотрим его более детально
●Мультироцессоры -- КС имеющая более одного процессора. При этом они разделяют общую память
○UMA(однородный доступ к памяти Все микропроцессоры в UMA-архитектуре используют физическую память одновременно. При этом время запроса к данным из памяти не зависит ни от того, какой именно процессор обращается к памяти, ни от того, какой именно чип памяти содержит нужные данные. Однако каждый микропроцессор может использовать свой собственныйкэш
■SMP(симметричная мультипроцессрование)-- архитектура многопроцессорных компьютеров, в которой два или более одинаковых процессоров подключаются к общей памяти. Большинство многопроцессорных систем сегодня используют архитектуру SMP.
SMP-системы позволяют любому процессору работать над любой задачей независимо от того, где в памяти хранятся данные для этой задачи; при должной поддержкеоперационной системой SMP-системы могут легко перемещать задачи между процессорами, эффективно распределяя нагрузку. С другой стороны, память гораздо медленнее процессоров, которые к ней обращаются; даже однопроцессорным машинам приходится тратить значительное время на получение данных из памяти. В SMP ситуация ещё более усугубляется, так как только один процессор может обращаться к памяти в данный момент времени.
■PVP -- несколько векторных процессоров(аналогично SMP)
○NUMA -- неоднородный доступ к памяти
■ccNUMA -- NUMA c когерентностью кэша. Большинство современных NUMA систем.
■nccNUMA -- без когерентности кэша. Такую систему легко создать, но становится предельно сложно программировать под нее

9
■COMA(cache only memory architecture)-- отличие от предыдущих при использовании блока памяти находящигося в “зоне влияния” другого процессора данные НЕ копируются, а мигрируют в “зону влияния” процессора, которым они будут использоваться. К плюсам можно отнести то, что уменьшается количество ненужных копий информации, и нет необходимости поддерживать ее когерентность. К минусам -- сложнее найти нужный кусок данных.
●Мультикомпьютеры -- КС без общего доступа к памяти.
○MPP --Система строится из отдельных узлов англ node), содержащих процессор, локальный банк оперативной памяти, коммуникационные процессоры или сетевые адаптеры, иногда — жёсткие диски и другие устройства ввода-вывода. Доступ к банку оперативной памяти данного узла имеют только процессоры из этого же узла. Узлы соединяются специальными коммуникационными каналами.Очень хорошо масштабируется (кол во процессоров 10 000)
○Кластера -- Это дешевый вариант MPP часто в качестве узлов используются ПК
Классификация по Кутепову
1.По распределенности памяти
a.многопроцессорные
b.многокомпьютерные
2.Однородность
a.однородные
b.неоднородные
3.По связанности
a.Сильносвязанные
b.Слабосвязанные
4.По централизации управления
a.централизованные
b.смешанные
c.децентрализованные
Организация коммутации
·Одна общая шина
·Несколько шин + коммутатор

10
·Коммутатор кольцевого типа
· |
Коммутатор в виде полного графа Коммутатор “звезда” |
Коммутатор решетка |
|
Коммутатор “Гиперкуб” |
|
Fat tree