

Преобразование цифра-аналог и восстановление континуального сигнала
Обратное преобразование сигнала из цифровой в континуальную форму производится с помощью двух устройств: ЦАП и синтезирующего фильтра.
В ЦАП имеется набор источников фиксированных напряжений, соответствующих каждому из rразрядов, и устройство для синхронного подключения (или отключения) этих напряжений к сумматору в зависимости от поступающих из АЦП символов (имеется в виду схема на рис. 1.11, а).Напряжение на выходе ЦАП максимальное, когда со всех элементов поступают единицы. Пусть, например, число разрядов r=4 и, следовательно, число дискретных уровней L=24=16, а максимальное напряжение сигнала условно равно 1 В. Тогда цена самого младшего разряда 1/16 В, следующего за ним 1/8 В, затем 1/4 и 1/2 В. При кодовом слове, поступающем от АЦП в виде 0,1111, напряжение на выходе ЦАП будет 1/2+1/4+1/8+1/1=15/16 В (максимальное значение), а при слове 0,0001 1/16 (минимальное значение). Кодовому слову 0,0010 соответствует напряжение 2/16 В, слову 0,1000 1/2 В и т. д.
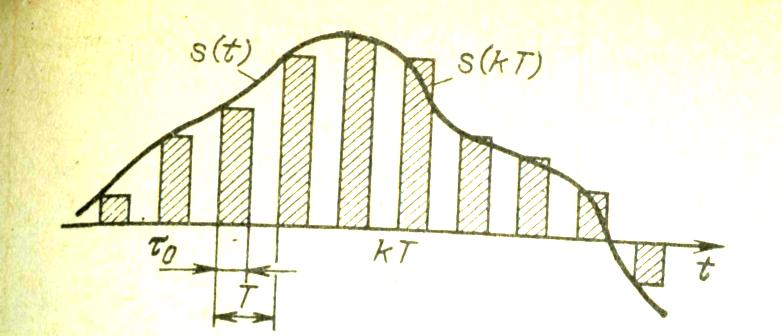
Рис. 1.14. Выборки в виде прямоугольных импульсов
Рис. 1.15. Тактовый импульс
Указанные напряжения поддерживаются на выходе ЦАП в течение времени τ0<T, а иногда вплоть до поступления новой кодовой группы (τ0=Т). В результате при фильтрации сигнала s(t) на выходе ЦАП появляется напряжение в виде импульсной последовательности, представленной на рис. 1.14 (при τ0<Т). Амплитуды прямоугольных импульсов равны соответствующим отсчетам, поступающим (в закодированном виде) от АЦП.
Спектр такой последовательности имеет сложную структуру. Фильтр на выходе ЦАП с полосой пропускания, меньшей или равной частоте f1/2 (где f1=1/Т - частота повторения импульсов), выделяет основной частотный интервал, в котором содержится вся информация о сигнале s(t) (спектр которого должен быть не шире fm=f1/2). На этом и заканчивается процедура восстановления континуальной формы профильтрованного сигнала. Следует, однако, иметь в виду, что спектр последовательности «толстых» импульсов, показанных на рис. 1.14, может существенно отличаться от спектра для тонких импульсов (теоретически δ-функция).
Кодирование информации в системах связи.Назначение и классификация кодов
В этой главе рассматривается кодирование сообщений, передаваемых в дискретном канале, или кодирование в узком смысле. Дискретный канал образуется из непрерывного путем включения в канал модема. На вход модулятора и с выхода демодулятора поступают дискретные кодовые символы (например, в форме импульсов), одинаковые или различные. Будем обозначать кодовые символы числами 0, 1, ..., q—1, где q— основание кода.
Пусть источник выдает некоторое дискретное сообщение а, которое можно рассматривать как последовательность кодовых символов сообщений ai(i=0, 2, ..., n-1). Совокупность кодовых символов {ai} — алфавит источника. Кодирование заключается в том, что последовательность кодовых символов источникаа заменяется кодовым словом, т. е. последовательностью b кодовых символов. Такое преобразование сообщения в кодовое слово (если не учитывать воздействия помех), как правило, является взаимно-однозначным, что и позволяет осуществить декодирование, т. е. восстановить сообщение по принятому кодовому слову.
В простейшем случае, когда объем алфавита источника m равен основанию кода q, можно сопоставить каждый кодовый символ букве источника. На практике применяют более сложные коды, основное назначение которых заключается в согласовании источника сообщений с дискретным каналом по объему алфавита и по избыточности.
Согласование по объему необходимо во всех случаях, когда объем алфавита источникаm не совпадает с количеством различных символов n, для передачи которых пригоден используемый дискретный канал. Чаще всегоm>n, так что каждый знак источника кодируется несколькими последовательными кодовыми символами. Так, например, в простейшем телеграфном коде Бодо каждая буква русского алфавита кодируется кодовым словом из пяти двоичных символов (0 и 1); в телеграфном коде Морзе на каждую букву алфавита затрачивается от двух до шести символов, принимающих значения «точка», «тире» и «пробел».
Остановимся подробнее на согласовании источника с каналом по избыточности. Пусть случайное сообщение А заменяется кодовой последовательностью В. Поскольку считаем кодирование обратимым, то получаем
 ,
(1.32)
,
(1.32)
где I(А, В) — количество информации в кодовой последовательности относительно сообщения; H(А) — энтропия сообщения; Н(В) — энтропия кодовой последовательности. Следовательно, энтропия при кодировании не изменяется..
Иначе обстоит дело с избыточностью, определяющей соотношение между энтропией и ее максимальным значением (при данном алфавите). Избыточность может при кодировании как возрастать, так и уменьшаться.
Пусть,
например, избыточность источника велика,
т. е.
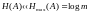 .
Тогда может
стоять задача о таком кодировании, при
котором избыточность уменьшается (в
предельном случае вовсе устраняется).
Такое кодирование называется эффективным
кодированием. Эффективное (или экономное)
кодирование позволяет увеличить скорость
передачи сообщений по каналу с ограниченной
пропускной способностью. В частности,
осмысленный русский текст можно
передавать, затрачивая всего лишь 1,5
двоичных символов на букву, вместо пяти
при равномерном коде.
.
Тогда может
стоять задача о таком кодировании, при
котором избыточность уменьшается (в
предельном случае вовсе устраняется).
Такое кодирование называется эффективным
кодированием. Эффективное (или экономное)
кодирование позволяет увеличить скорость
передачи сообщений по каналу с ограниченной
пропускной способностью. В частности,
осмысленный русский текст можно
передавать, затрачивая всего лишь 1,5
двоичных символов на букву, вместо пяти
при равномерном коде.
Отметим некоторые свойства кодовой последовательности, в которой полностью устранена избыточность. В любом месте такой последовательности все символы появляются равновероятно и независимо от значений других символов. В противном случае энтропия на символ последовательности не имела бы максимального значения logm т, т. е. существовала бы остаточная избыточность. Отсюда следует, что и все последовательности символов произвольно заданной длины правновероятны. Предположим, что при передаче такой кодовой последовательности под воздействием помех возникли ошибки. (Принятая ошибочная последовательность кодовых символов соответствует ошибочной последовательности сообщений, которая, однако, имеет .ту же вероятность, что и 'правильная. Никаких признаков ошибочности принятая последовательность не может иметь. При передаче безызбыточных сигналов по каналу с ошибками любая принятая последовательность соответствует возможному сообщению, но полной уверенности в том, что именно это сообщение передано в действительности, у получателя нет. Ошибочный прием всего лишь одного кодового символа может изменить до неузнаваемости переданное сообщение. Поэтому эффективное кодирование используют в чистом виде только тогда, когда кодовая последовательность не подвергается воздействию помех.
Избыточность в передаваемом сообщении позволяет в некоторых случаях обнаруживать и исправлять ошибки. Искаженная кодовая последовательность может иметь нулевую или очень близкую к нулю вероятность, что указывает на наличие ошибки. Если определить, какая из возможных переданных последовательностей наиболее правдоподобна, можно во многих случаях ошибки исправить.
Если при кодировании не устранять, а вводить избыточность, то должны увеличиться возможности обнаружения и исправления ошибок. Такое кодирование называют помехоустойчивым, или корректирующим..
При помехоустойчивом кодировании чаще всего считают, что избыточность источника на входе кодера R=0. Для этого имеются следующие основания: во-первых, очень многие дискретные источники (например, информация на выходе ЭВМ) обладают малой избыточностью; во-вторых, если избыточность первичных источников существенна, она обычно порождается сложными связями, которые в месте приема трудно использовать для повышения верности. Разумно поэтому в таких случаях по возможности уменьшить избыточность первичного источника путем эффективного кодирования, а затем методами помехоустойчивого кодирования внести такую избыточность в сигнал, которая позволит достаточно простыми средствами поднять верность. Из сказанного видно, что экономное кодирование вполне может сочетаться с помехоустойчивым.
Коды можно классифицировать по различным признакам. Одним из них является основание кода q, или число различных используемых в нем символов. Наиболее простыми являются двоичные (бинарные) коды, у которых q = 2.
Далее коды можно разделить наблочные и непрерывные. Блочными называют коды, в которых последовательность элементарных сообщений источника разбивается на отрезки и каждый из них преобразуется в определенную последовательность (блок) кодовых символов {bi}, называемую кодовой комбинацией или кодовым словом bi (i=1, 2, 3, ..., n-1). Непрерывные коды образуют последовательность символов {bi}, не разделяемую на последовательные кодовые комбинации: здесь в процессе кодирования символы определяются всей последовательностью элементов сообщения.
В настоящее время на практике чаще используют блочные коды, равномерные и неравномерные. В равномерных кодах, в отличие от неравномерных, все кодовые комбинации содержат одинаковое число символов (разрядов), передаваемых по каналу элементами сигнала неизменной длительности. Это обстоятельство существенно упрощает технику передачи и приема сообщений и повышает помехоустойчивость системы синхронизации. Число различных блоков М n-разрядного равномерного кода с основанием qудовлетворяет очевидному неравенству
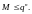 (1.33)
(1.33)
Если в (1.33) имеет место равенство, т. е. все возможные кодовые комбинации используются для передачи сообщений, то вэтом случае код называется простым, или примитивным, он не вносит избыточности и поэтому не является помехоустойчивым. Избыточностью равномерного кода Rκ называют величину
 (1.34)
(1.34)
а относительной скоростью кода
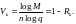 (1.35)
(1.35)
Если все блоки равномерного кода передавать равновероятно и независимо друг от друга, то logMпредставляет собственную информацию (энтропию), приходящуюся на каждый блок.
В дальнейшем будем рассматривать главным образом двоичные коды (q = 2).