

Глава 3
Комбинирование помехоустойчивого кодирования с приемами, усиливающими эффект их применения
Для
современных АСОИиУ характерным является
рост объемов информации, передаваемой
по каналам передачи и (или) хранимой в
запоминающих устройствах, что достигается,
в частности, увеличением разрядности
передаваемых или хранимых слов. Последнее
в силу изложенного в главе 1 ведет, при
прочих равных условиях, к увеличению
вероятности появления в словах
многократных ошибок, т.е. ошибок кратности
![]() .
Применение для их обнаружения и
исправления кодов с требуемыми
корректирующими возможностями ограничено
рядом причин. В этих условиях одним из
возможных и рациональных подходов к
решению проблемы коррекции многократных
ошибок в словах, передаваемых по каналу
связи или хранящихся в запоминающих
устройствах, является комбинирование
помехоустойчивого кодирования с
некоторыми приемами и средствами,
дополняющими и усиливающими эффект
применения корректирующих кодов.
Комбинирование кода с заданными
корректирующими возможностями с теми
или иными приемами преследует целью
исправление многократных ошибок сверх
того, на что способен код при его
применении в чистом виде и, следовательно,
должно позволить исправление многократных
ошибок доступными и сравнительно легко
реализуемыми средствами.
.
Применение для их обнаружения и
исправления кодов с требуемыми
корректирующими возможностями ограничено
рядом причин. В этих условиях одним из
возможных и рациональных подходов к
решению проблемы коррекции многократных
ошибок в словах, передаваемых по каналу
связи или хранящихся в запоминающих
устройствах, является комбинирование
помехоустойчивого кодирования с
некоторыми приемами и средствами,
дополняющими и усиливающими эффект
применения корректирующих кодов.
Комбинирование кода с заданными
корректирующими возможностями с теми
или иными приемами преследует целью
исправление многократных ошибок сверх
того, на что способен код при его
применении в чистом виде и, следовательно,
должно позволить исправление многократных
ошибок доступными и сравнительно легко
реализуемыми средствами.
3.1. Комбинирование помехоустойчивых кодов с методом двойного инвертирования
Известным удачным примером подобного подхода к исправлению многократных жестких (постоянных) ошибок в словах памяти ОЗУ является комбинирование помехоустойчивого кодирования и приема двойного инвертирования слов. Процедура исправления ошибок при этом выполняется в следующей последовательности (табл. 3.1).
Предположим,
что в ячейках памяти ОЗУ должны храниться
8-разрядные информационные слова ![]() ,
для защиты которых применен код с
контролем нечетности, т.е. единственный
проверочный разряд
,
для защиты которых применен код с
контролем нечетности, т.е. единственный
проверочный разряд ![]() ,
значение которого выбирается так, чтобы
общее число единиц в 9-разрядном кодовом
слове было нечетным, т.е.:
,
значение которого выбирается так, чтобы
общее число единиц в 9-разрядном кодовом
слове было нечетным, т.е.:![]() .В
данном примере число единиц в
информационном слове равно пяти,
следовательно, контрольный разряд
.В
данном примере число единиц в
информационном слове равно пяти,
следовательно, контрольный разряд ![]() выбирается равным нулю. В процессе
дальнейшей работы процессор обратится
к этой ячейке памяти с целью извлечения
хранимого слова.
выбирается равным нулю. В процессе
дальнейшей работы процессор обратится
к этой ячейке памяти с целью извлечения
хранимого слова.
Таблица 3.1
Процедура исправления ошибок методом двойного инвертирование
|
Последова-тельность коррекции |
|
|
Комментарии |
|
1-я запись |
1 1 0 1 0 0 1 1 |
0 |
Исходное слово данных |
|
1-е чтение |
1 1 0 1 0 1 1 1 |
0 |
Ошибка при проверке на нечетность |
|
1-е
|
0 0 1 0 1 0 0 0 |
1 |
Данные инвертируются |
|
2-я запись |
0 0 1 0 1 0 0 0 |
1 |
Запись инверсных данных |
|
2-е чтение |
0 0 1 0 1 1 0 0 |
1 |
Ошибка при проверке на нечетность |
|
2-е
|
1 1 0 1 0 0 1 1 |
0 |
Данные инвертируются, ошибка исправлена |
При первом чтении (см. строку 2) обнаружится, что общее число единиц в 9-разрядном считанном слове оказалось четным. Сравнивая строки 1 и 2, можем заключить, что имеется ошибка в разряде 5 (вместо нуля считана единица), но система контроля и коррекции об этом «не знает» – пока она лишь зарегистрировала наличие ошибки. Далее включается механизм коррекции, который работает следующим образом.
Считанное 9-разрядное слово данных, содержащее ошибку, инвертируется, например, процессором и вновь записывается в эту же ячейку памяти (см. строки 3 и 4). Сразу после этого выполняется второе чтение из этой же ячейки памяти. Поскольку в данном примере рассматривается постоянная ошибка, а именно ошибка типа «постоянная единица» в разряде 5 данной ячейки памяти, повторное чтение даст результат, показанный в строке 5 табл. 3.1. При этом число единиц в считанном 9-разрядном коде вновь оказалось четным, но на этот раз достаточно проинвертировать считанный код, чтобы получить правильный результат, совпадающий с исходным (см. строки 1 и 6).
Для
защиты информационных слов, хранящихся
в ОЗУ, могут быть применены и более
мощные коды, например, корректирующий
код, исправляющий до
![]() ошибок. В этом случае возможности
комбинирования, естественно, увеличатся
– появится возможность исправления
до
ошибок. В этом случае возможности
комбинирования, естественно, увеличатся
– появится возможность исправления
до
![]() ошибок, если выполняются условия:
ошибок, если выполняются условия:
1.
используемый код позволяет обнаружить
факт искажения слов, т.е. его обнаруживающие
возможности
![]() ;
;
2.
среди
![]() ошибок число мягких, т.е. обусловленных
сбоями ошибок не более
ошибок число мягких, т.е. обусловленных
сбоями ошибок не более
![]() .
.
В то же время для рассмотренного метода коррекции многократных ошибок характерны следующие ограничения, препятствующие его широкомасштабному применению:
а) метод комбинирования позволяет исправлять многократные ошибки только в ОЗУ и не применим для других типов ЗУ и каналов связи;
б) двойное инвертирование не исправляет мягкие ошибки, в то же время в каналах связи и хранения доля ошибок, обусловленных сбоями существенно преобладает над жесткими (постоянными) ошибками.
3.2. Комбинирование помехоустойчивых кодов и приема, основанного на делении слов на слоги
Допустим, что в m – разрядном слове, передаваемом по каналу или хранящемся в запоминающие устройстве, возможны многократные ошибки т.е. ошибки кратности r ≥ 2. Для их обнаружения и исправления необходим код, исправляющий dи ≥ r ошибок. Но такой код будет достаточно длинным – число проверочных разрядов k становится соизмеримым, а то и превышающим число информационных m. Последнее, в силу отмеченных выше обстоятельств, является одной из основных причин, сдерживающих широкомасштабное применение кодов, исправляющих многократные ошибки.
Разделим исходное m–разрядное информационное слово на g слогов, каждый из которых содержит m1,m2,…,mg символов соответственно, причем m=m1+m2+…+mg (рис. 3.1).

Рис. 3.1. Иллюстрация метода обнаружения и коррекции многократных ошибок, основанного на делении слова на слоги и их автономном кодировании
Тогда в силу сделанного ранее (глава 1) предположения о взаимной независимости и равновероятности ошибок можно заключить, что на отдельно взятые слоги придутся ошибки, кратности меньшей, чем r. Следовательно, для их исправления можно применить коды с меньшими корректирующими возможностями, т.е. более простые, в том числе с позиций их практической реализации, корректирующие коды.
Положим,
что для кодирования слогов применен
простейший из известных корректирующих
кодов, допускающий параллельное
кодирование-декодирование – код
Хэмминга или его модификация – удлиненный
код Хэмминга, позволяющие, как известно,
исправлять только одну ошибку. В
результате кодирования к каждому i-ому
слогу с mi
информационными символами добавляется
ki
проверочных
символов и получаем кодовые слоги,
содержащие
![]() символов, где
символов, где![]() .
Общее число символов кодового слова
составит
.
Общее число символов кодового слова
составит![]() ,в том числе
проверочных
символов
,в том числе
проверочных
символов
![]() .
.
Если предположить, что кодовое слово искажено r ошибками, то общее число вариантов их распределения между n символами кодового слова будет равно:
![]() ,
(3.1)
,
(3.1)
где
![]() -
число сочетаний изn
по r.
-
число сочетаний изn
по r.
Поскольку код Хэмминга, которым защищен каждый из g слогов, позволяет исправлять в кодовом слоге только одну ошибку, можно заключить, что все r ошибок будут исправлены только в том случае, когда на отдельно взятые слоги придется не более, чем по одной ошибке. При этом из g слогов будет искажено равно r.
Число таких вариантов распределения r ошибок равно:
![]() ,
(3.2)
,
(3.2)
где
![]() –
знак операции умножения,
–
знак операции умножения,
![]() –число
символов i-го
кодового слога, искаженного одной
ошибкой.
–число
символов i-го
кодового слога, искаженного одной
ошибкой.
Для
остальных
![]() возможных вариантов распределенияr
ошибок между
g
кодовыми слогами все r
ошибок
исправлены быть не могут. При этом можно
выделить следующие возможные ситуации:
возможных вариантов распределенияr
ошибок между
g
кодовыми слогами все r
ошибок
исправлены быть не могут. При этом можно
выделить следующие возможные ситуации:
а)
![]() ошибок,
приходятся
по одной на
ошибок,
приходятся
по одной на
![]() кодовых
слогов, остальные
кодовых
слогов, остальные
![]() распределены
произвольно (но не по одной) между
распределены
произвольно (но не по одной) между
![]() кодовыми
слогами и, следовательно с учетом
корректирующих возможностей кода
Хэмминга,
кодовыми
слогами и, следовательно с учетом
корректирующих возможностей кода
Хэмминга,
![]() ошибок не
могут быть исправлены (ошибки не
обнаруживаются или будет осуществлено
их ложное декодирование);
ошибок не
могут быть исправлены (ошибки не
обнаруживаются или будет осуществлено
их ложное декодирование);
б) кодовые слоги искажены ошибками кратности две или более и, следовательно, все r ошибок будут не исправимыми (они не обнаруживаются или будет осуществлено их ложное декодирование).
Таким
образом, метод деления слов на слоги и
последующего их автономного
кодирования-декодирования
не обеспечивает исправления многократных
ошибок для всех возможных вариантов
их распределения между g
слогами или n
символами кодового слова, определяемых
выражением (3.1). Исправлены все
![]() ошибок могут быть только для части
возможных вариантов их распределения
между g
слогами, устанавливаемую (3.2).
ошибок могут быть только для части
возможных вариантов их распределения
между g
слогами, устанавливаемую (3.2).
Естественно,
что для возможности исправления d=r
ошибок
![]() ,
например, для возможности исправленияd=2
ошибок, слово должно быть разделено не
менее чем
на 2 слога; при
d=3
– слово делится на 3 или более слогов
и т.д.
,
например, для возможности исправленияd=2
ошибок, слово должно быть разделено не
менее чем
на 2 слога; при
d=3
– слово делится на 3 или более слогов
и т.д.
В результате получаем выражение для вероятности исправления в кодовом слове r ошибок:
 .
(3.3)
.
(3.3)
Проиллюстрируем изложенное следующим примером.
Пример
3.1.
Положим, что разрядность информационного
слова, подлежащего передаче по каналу
или хранению в ЗУ, равна 8, т.е. m=8.
Допустим, что в канале передачи (или
хранения) возможны искажения одного
или двух разрядов, т.е. кратность
возможных ошибок
![]() .
.
Р азделим
8-и разрядное информационное слово на
два слога, например, равной разрядности
– по 4 разряда в каждом, т.е.m1=m2=4
(рис. 3.2).
азделим
8-и разрядное информационное слово на
два слога, например, равной разрядности
– по 4 разряда в каждом, т.е.m1=m2=4
(рис. 3.2).
Рис. 3.2. Пример деления 8-и разрядного слова на два слога равной разрядности и их защиты кодом Хэмминга
Для кодирования слогов применим код Хэмминга с минимальным кодовым расстояниям d=3. Число проверочных разрядов k1=k2, которые необходимо добавить к информационным разрядам каждого слога mi, находится из неравенства Хэмминга:
![]()
Для рассматриваемого примера k1=k2=3 и, следовательно, n1=n2=7. В результате получаем кодовое слово, состоящее из n=n1+n2=14 символов, из которых k=k1+k2=6 приходятся на проверочные.
Любая однократная ошибка (d=1), вне зависимости от того, на какой слог кодового слова она придется, может быть исправлена.
Если же кодовое слово будет искажено двумя ошибками (d=2), то общее число вариантов их распределения составит:
![]()
Из общего числа двойных ошибок N(d=2) будут исправлены только те Nи(d=2), которые придутся по одной на слог –одна ошибка в первом слоге (в пределах разрядов n1), а вторая –во втором (в пределах разрядов n2). Число таких двойных ошибок равно:
![]()
Тогда получаем, что Nни(d=2)=N(d=2)–Nи(d=2)=91-49=42 ошибок из общего числа 91-й двойных ошибок оказываются не исправимыми. Следовательно, вероятность исправления двойных ошибок будет равна:
![]()
3.3. Многовариантность возможных реализаций комбинирования помехоустойчивых кодов и деления слов на слоги
Эффективная защита данных, передаваемых по каналам связи или хранящихся в ЗУ, при использовании предлагаемого метода, основанного на делении информационных слов на слоги и их последующего автономного кодирования-декодирования, изначально предполагает решение следующих вопросов.
1. На сколько слогов следует разделить исходное информационное слово? То есть подлежит обоснованию выбор значения g.
2. Какой разрядности (формата) должны быть образованные слоги? При некотором фиксированном g существуют различные варианты деления m-разрядного информационного слова на слоги, отличающиеся разрядностями.
3. Какой корректирующий код использовать для кодирования слогов?
Решение перечисленных вопросов должно быть найдено из анализа следующих, в общем случае, противоречивых условий:
обеспечение требуемых обнаруживающих и корректирующих возможностей;
обеспечение приемлемой достоверности декодирования – исключение или снижение до приемлемых значений вероятностей ложного декодирования и пропуска (не обнаружения) ошибок;
простота реализации процедур кодирования и в особенности декодирования, которая при их технической реализации сводится к снижению сложности и глубины кодирующих и декодирующих устройств.
Р ассмотренный
в разделе 3.2 иллюстративной пример
деления 8-и разрядного информационного
слова на два непересекающихся слога
(слоги, не имеющие общих символов) равной
разрядности – по 4 в каждом, естественно,
является не единственно возможным.
Деление 8-и разрядного информационного
слова на два непересекающихся слога
возможно различными вариантами (рис.
3.3).
ассмотренный
в разделе 3.2 иллюстративной пример
деления 8-и разрядного информационного
слова на два непересекающихся слога
(слоги, не имеющие общих символов) равной
разрядности – по 4 в каждом, естественно,
является не единственно возможным.
Деление 8-и разрядного информационного
слова на два непересекающихся слога
возможно различными вариантами (рис.
3.3).
Рис. 3.3. Варианты деления 8-и разрядного слова на два непересекающихся слога
При кодировании слогов, соответствующих этим вариантам с помощью кода Хэмминга, получаем различные значения k=k1+k2 и n=n1+n2, а также различные значения вероятностей исправления ошибок кратности d=2.
Пример 3.2. Так, если исходное 8-и разрядное информационное слово разбить на два слога с числом символов m1=1 и m2=7, каждый из которых представлен в коде Хэмминга (рис. 3.4), получаем:
k1=2, k2 =4, k=k1+k2=6; n1=3, n2=11, n=14.
Тогда общее число возможных ошибок кратности d=2, приходящихся на 14-и разрядное кодовое слово согласно (3.1) будет равно:
![]()
Из общего числа двойных ошибок могут быть исправлены только те, которые придутся по одной на каждый из кодовые слогов, т.е.:
![]()
Следовательно, для рассматриваемого варианта деления слова на слоги вероятность исправления двойных ошибок составит:
![]()

Рис. 2.4. Вариант деления 8-и разрядного информационного слова на два слога с числом символов m1= 1 и m2=7 и их защиты кодом Хэмминга
Результаты расчетов, выполненные для других возможных вариантов, отличающихся форматами (разрядностью) слогов сведены в табл. 3.2. В скобках указаны эквивалентные варианты деления информационного слова, например, варианту m1= 1 и m2=7 эквивалентен: m1= 7 и m2=1.
Таблица 3.2
Параметры кодовых слогов и вероятности исправления двух ошибок, соответствующие возможным вариантам деления 8-и разрядного информационного слова на два слога
|
m1 m2 |
1 (7) 7 (1) |
2 (6) 6 (2) |
3 (5) 5 (3) |
4 4 |
|
k1 k2 |
2 4 |
3 4 |
3 4 |
3 3 |
|
k=k1+k2 |
6 |
7 |
7 |
6 |
|
n=(m1+m2)+(k1+k2) |
14 |
15 |
15 |
14 |
|
|
0,363 |
0,478 |
0,51 |
0,538 |
Естественно, что информационные слова могут быть разделены не только на два, но и на три и более слогов.
Пример 3.3. Разделим 8-и разрядное информационное слово на три слога с числом символов m1=m2=3 и m3=2 и каждый из них представим в коде Хэмминга. В результате получаем k1= k2= k3=3, k=k1+ k2+ k3=9; n1=n2=6, n3=5, n=n1+ n2+ n3=17 (рис. 3.5).
Тогда
из общего числа возможных ошибок
кратности d=2:
![]() могут быть исправлены те, которые
придутся по одной на два слога из трех,
т.е.
могут быть исправлены те, которые
придутся по одной на два слога из трех,
т.е.
![]()

Рис. 3.5. Деление 8-разрядного слова на три слога, для кодирования которых применен код Хэмминга
При этом вероятность исправления двух ошибок составит:
![]()
Как и в рассмотренных выше примерах деления слова на два непересекающихся слога вероятность исправления двух ошибок зависит от выбранного варианта деления слова на три слога.
Пример 3.4.Если 8-и разрядное информационное слово разбить на три слога с числом символовm1=m2=2 и m3=4, каждый из которых представлен в коде Хэмминга (рис. 3.6), получаем:k1= k2= k3=3, k=k1+ k2+ k3=9; n1=n2=5, n3=7, n=n1+ n2+ n3=17.

Рис. 3.6. Вариант деления 8-и разрядного информационного слова на три слога, для кодирования которых применен код Хэмминга
Тогда общее число возможных ошибок кратности d=2, приходящихся на 17-и разрядное кодовое слово, будет равно:
![]()
Из общего числа двойных ошибок могут быть исправлены только те, которые придутся по одной на два слога из трех, т.е.:
![]()
Следовательно, для рассматриваемого варианта деления слова на три слога вероятность исправления двойных ошибок составит:
![]()
Возможные варианты деления 8-и разрядного информационного слова на три непересекающихся слога, соответствующие им параметры кодовых слогов и слова, а также значения вероятностей исправления двойных ошибок сведены в табл. 3.3.
Таблица 3.3
Варианты деления 8-и разрядного слова на три слога и соответствующие им значения параметров кодовых слогов, и вероятностей исправления двойных ошибок
-
№ варианта
1
2
3
4
5
m1
m2
m3
1
1
6
1
2
5
1
3
4
2
2
4
2
3
3
k1
k2
k3
2
2
4
2
3
4
2
3
3
3
3
3
3
3
3
k= ki
8
9
8
9
9
n1
n2
n3
3
3
10
3
5
9
3
6
7
5
5
7
5
6
6
n= ni
16
17
16
17
17

0,5
0,639
0,675
0,698
0,705
Параметры
кодового слова и, следовательно, значения
![]() ,
соответствующие тому или иному варианту
деления не зависят от изменения форматов
слогов внутри варианта. Например,
первому варианту, приведенному в табл.
3.3, для которого m1=m2=1
и
m3=6
эквивалентны
варианты деления: m1=m3=1
и
m2=6
или
m1=6,
а m2=m3=1.
Поэтому табл. 3.3 содержит только по
одному варианту деления слова из группы
эквивалентных.
,
соответствующие тому или иному варианту
деления не зависят от изменения форматов
слогов внутри варианта. Например,
первому варианту, приведенному в табл.
3.3, для которого m1=m2=1
и
m3=6
эквивалентны
варианты деления: m1=m3=1
и
m2=6
или
m1=6,
а m2=m3=1.
Поэтому табл. 3.3 содержит только по
одному варианту деления слова из группы
эквивалентных.
Полученные
результаты расчетов, а также значения
чисел проверочных разрядов и вероятностей
исправления двойных ошибок, соответствующие
вариантам деления 8-и разрядного
информационного слова на 4,5,6,7 и 8
непересекающихся слогов представлены
на рис. 3.7,а в виде интервалов (диапазонов)
изменений ![]() и
и
![]() ,
соответствующих различным возможным
вариантам деления 8-и разрядного
информационного слова на g
слогов, для кодирования которых применен
код Хэмминга.
,
соответствующих различным возможным
вариантам деления 8-и разрядного
информационного слова на g
слогов, для кодирования которых применен
код Хэмминга.
Аналогичным
образом получены возможные интервалы
значений ![]() и
и
![]() при делении 16-и разрядного информационного
слова на g
слогов (g=2,3,…,16)
и их автономном кодировании с помощью
кода Хэмминга (рис. 3.7.б).
при делении 16-и разрядного информационного
слова на g
слогов (g=2,3,…,16)
и их автономном кодировании с помощью
кода Хэмминга (рис. 3.7.б).

Рис. 3.7. Интервалы изменения числа проверочных символов k и вероятности исправления двойных ошибок при делении информационных слов разрядности 8 (а) и 16 (б) на g непересекающихся слогов, для кодирования которых применен код Хэмминга
Следует
отметить, что при делении m-разрядного
информационного слова на g
слогов и их автономном кодировании
появляется возможность исправления
многократных ошибок кратностей от 2 до
g
включительно. Так, например, при делении
8-и разрядного информационного слова
на 3 слога появляется возможность
исправления не только двойных ошибок
(соответствующие значения
![]() приведены в табл. 3.3), но и тройных, а при
делении слова на 4 слога возможно
исправление ошибок кратностей 2, 3 и 4.
приведены в табл. 3.3), но и тройных, а при
делении слова на 4 слога возможно
исправление ошибок кратностей 2, 3 и 4.
Полученные
результаты расчетов значений вероятностей
исправления многократных ошибок
![]() ,
соответствующие вариантам деления 8-и
разрядного информационного слова на
g
слогов при их защите кодом Хэмминга
сведены в табл. 3.4.
,
соответствующие вариантам деления 8-и
разрядного информационного слова на
g
слогов при их защите кодом Хэмминга
сведены в табл. 3.4.
Таблица 3.4
Значения
![]() ,
соответствующие различным вариантам
деления 8-и разрядного информационного
слова на g
слогов при кодировании их кодом Хэмминга
,
соответствующие различным вариантам
деления 8-и разрядного информационного
слова на g
слогов при кодировании их кодом Хэмминга
-
g
 (d=r)
(d=r)2
3
4
5
6
7
8
 (d=2)
(d=2)0.54
0.705
0.785
0.835
0.863
0.885
0.91
 (d=3)
(d=3)0
0.265
0.438
0.521
0.619
0.673
0.72
 (d=4)
(d=4)0
0
0.129
0.238
0.343
0.442
0.534
 (d=5)
(d=5)0
0
0
0.055
0.133
0.224
0.32
 (d=6)
(d=6)0
0
0
0
0.027
0.067
0.152
 (d=7)
(d=7)0
0
0
0
0
0.015
0.051
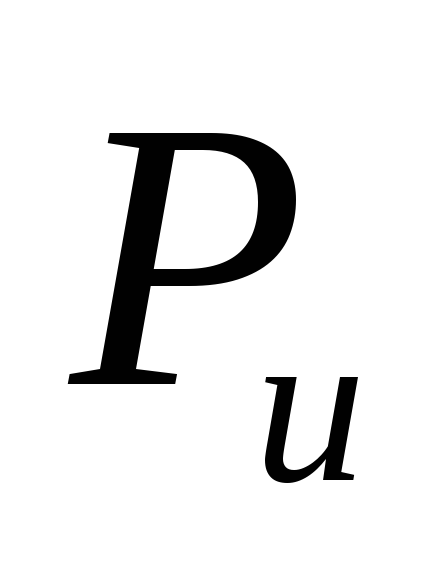 (d=8)
(d=8)0
0
0
0
0
0
0.009
В
таблице приведены максимальные значения
![]() из интервалов их возможных значений,
соответствующих тому или иному варианту
деления слова на слоги.
из интервалов их возможных значений,
соответствующих тому или иному варианту
деления слова на слоги.
Упражнения
№1. В передаваемом по каналу связи кодовом слове возможно искажение до двух разрядов (т.е. кодовое слово может прийти без искажений, либо содержать один или два искаженных разряда).
Для возможности их обнаружения (где Ф – число букв в вашей фамилии) информационных разрядах слова делятся на 3 слога (содержащих 2, 2 и Ф-4 разрядов), каждый из которых кодируется с помощью кода с контролем на четность.
Определите значение вероятности обнаружения в кодовом слове двух ошибок – P0(d=2).
№2. В предаваемом по каналу связи кодовом слове возможно искажение до трех разрядов (т.е. кодовое слово может прийти без искажений, либо содержать один, два или три искаженных разряда).
Для возможности их исправления 10 информационных разрядов слова делятся на 3 слога (содержащих 3, 3, и 4 разряда), каждый из которых кодируется с помощью кода Хэмминга.
Определите значение вероятности исправления в кодовом слове двух ошибок – Pu(d=2), трех ошибок – Pu(d=3).
Список литературы
Каган Б.М., Мкртумян Н.Б.Основы эксплуатации ЭВМ: Учеб. пособие ля вузов / Под ред. Б.М. Кагана. – 2-е изд., перераб. и доп. – М: Энергоатомиздат, 1988.
Иыуду К.А. Надежность, контроль и диагностика вычислительных машин и систем: Учеб. пособие для вузов по спец. «Вычислительные машины, комплексы, системы и сети» – М.: Высш. шк., 1989.
Блейхут Р. Теория и практика кодов, контролирующих ошибки / Пер. с англ. – М.: Мир, 1986.
Золотарев В.В., Овечкин Г.В. Помехоустойчивое кодирование. Методы и алгоритмы. Справочник. М.: Горячая линия – Телеком, 2004.
Кононелько В.К., Лосев В.В. Надежное хранение информации в полупроводниковых запоминающихся устройствах. – М.: Радио и связь, 1986.
Огнев И. В., Сарыгев К.Ф. Надежность запоминающих устройств. – М.: Радио и связь, 1988.
Питерсон У.У. Коды, исправляющие ошибки / Пер. с англ. – М.: Мир, 1976.
Сагалович Ю.Л. Кодовая защита оперативной памяти ЭВМ от ошибок // Автоматика и телемеханика, 1991, №5.
Тлостанов Ю.К., Тугуж У.Х. Метод коррекции многократных ошибок в каналах передачи и хранения, основанный на делении слов данных на слоги и их автономном кодировании // Нелинейный мир, 2007, №6.
Щербаков Н.С. Достоверность работы цифровых устройств. – М.: Машиностроение, 1989.