

Модуль1_Организация и управление БД
.pdf9. < выражение> <операция сравнения> (<подзапрос>)
Подзапрос должен возвращать единственное значение – таблицу, имеющую один столбец и одну строку. Результат подзапроса, содержащий несколько строк, будет генерировать ошибку времени выполнения. Условие истинно, если сравнение истинно для значения, созданного подзапросом.
Следующий параметр оператора SELECT − параметр GROUP BY – требует группировки строк в результате запроса. Группировка – объединение нескольких строк результата запроса, составляющих группу, в одну строку. Условием образования группы является совпадение значений в заданных столбцах (группирующих выражениях) оператора SELECT. Схема объединения строк посредством группировки показана на рис. 9.1.
Исходное множество строк |
Результат группировки |
для группировки |
Группы
строк
группирующие выражения в столбцах:
групп. выр. 1,
. . . . . . . . . . ,
групп. выр. n
агрегатные выражения в столбцах, рассчитываемые на множестве строк, входящих в группу:
агр. выр.1,
. . . . . . . . . . .,
агр. выр.m
Рис.9.1. Схема создания групп в операторе SELECT
Общая структура оператора SELECT с группировкой строк такова: SELECT <групп.выр.1>,….,< групп.выр. n> , <агр.выр.1> , … ,<агр.выр. m>
FROM . . . . WHERE . . .
62
GROUP BY [All] < групп. выр.1> ,…. < групп. выр.n>
Список элементов в параметре GROUP BY должен быть согласован со списком столбцов самого оператора SELECT. Параметр GROUP BY должен содержать элементы из списка столбцов, по которым образуются группы строк. Кроме группирующих элементов (<групп.выр.1>, . .) в списке вывода могут содержаться элементы, задающие групповую обработку – агрегатные выражения (агр. выр. 1, . . . ), приводящие к вычислениям на множестве строк, попадающих в одну группу.
Агрегатные выражения строятся с помощью агрегирующих функций, которые вычисляют общий результат на множестве значений для группы.
Основные агрегирующие функции:
COUNT (*) – подсчитывает количество строк в группе;
|
ALL < выражение > |
|
COUNT |
– подсчитывает количество всех (ALL) или |
|
|
DISTINCT < выражение > |
|
только разных (DISTINCT) значений выражения на строках группы. По |
||
умолчанию действует опция ALL; |
||
|
ALL < выражение > |
|
SUM |
|
– вычисляет суммарное значение заданного |
DISTINCT < выражение > |
|
|
выражения на строках каждой группы; |
||
|
ALL < выражение > |
– вычисляет среднее значение выражения на |
|
|
|
AVG DISTINCT < выражение > |
||
всех строках группы (ALL) или только на различающихся значениях выражения (DISTINCT). DISTINCT предварительно удаляет дубликаты значений.;
|
ALL < выражение > |
|
|
MAX |
|
> |
– вычисляет максимальное значение |
DISTINCT < выражение |
|
||
выражения для каждой группы; |
|
|
|
|
ALL < выражение > |
|
|
MIN |
|
– вычисляет минимальное значение в группе. |
|
DISTINCT < выражение > |
|
||
Примером использования группировки может служить запрос, вычисляющий по таблице authors количество авторов, проживающих в каждом
63
штате SELECT STATE As [Штат], count(*) As [Число авторов] FROM authors GROUP BY STATE . Результатом запроса будет таблица вида:
Таблица 9.1
Штат |
Число авторов |
|
|
CA |
14 |
|
|
IN |
1 |
|
|
. . . . . |
. . . . . |
|
|
Если в параметре GROUP BY используется опция ALL совместно с агрегирующими выражениями, то будут выводиться все возможные группы, даже не удовлетворяющие критерию, заданному параметром WHERE, со значением NULL агрегирующих выражений, соответствующих группам, не удовлетворяющим критерию.
Агрегатные функции могут применяться и без использования группировки. В этом случае они вычисляют значения на всем множестве строк таблицы. Например, оператор Select Count(*) From authors возвратит число строк в таблице authors.
Следующий параметр HAVING в операторе SELECT предназначен для селекции групп перед выдачей результата запроса. Поэтому параметр HAVING без GROUP BY не используется. Он содержит критерий для фильтрации групповых строк. Критерий представляет собой логическое выражение, аналогичное WHERE, но применяемое к образованным в запросе группам.
Последний параметр оператора SELECT – ORDER BY задает порядок сортировки строк результата. Элементами ORDER BY могут быть выражения, имена или номера столбцов в списке результата запроса. Сортировка выполняется ступенчато, последовательно по элементам, перечисленным в ORDER BY. Сначала строки упорядочиваются по значениям первого элемента, заданного в ORDER BY. Затем строки с одинаковым значением первого элемента упорядочиваются по второму и т.д. Для задания порядка в каждом элементе сортировки используются опции: ASC – сортировка по возрастанию
64
значения элемента, DESC – по убыванию. Например, для расчета числа авторов в штатах и сортировки штатов по убыванию числа авторов можно применить оператор
SELECT STATE As [Штат], count(*) As [Число авторов] FROM authors GROUP BY STATE ORDER BY count(*) DESC
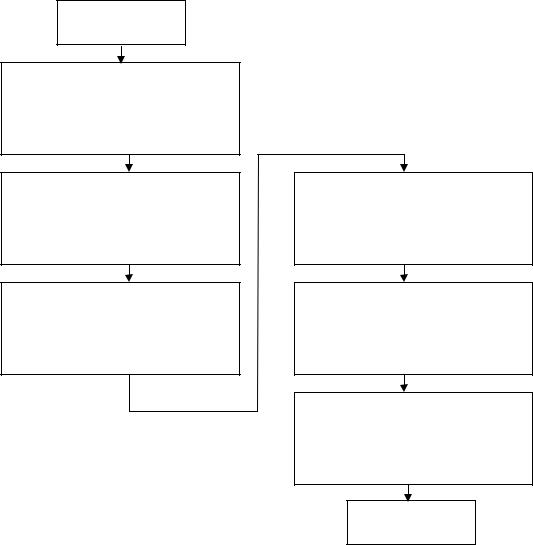
Последовательность действий при вычислении результата запроса представлена блок-схемой, представленной на рис. 9.2.
Начало
FROM
Создание полного источника данных
WHERE
Выборка строк для результата
GROUP BY
Группировка строк
HAVING
Отбор групп по выполнению условия
ORDER BY
Сортировка строк выражением значениям
SELECT
Формирование столбцов результата
Конец
Рис.9.2. Блок-схема выполнения оператора Select
Оператор UNION
Объединяет в общий результат множества строк, созданных отдельными операторами SELECT, и поэтому используется только за предшествующим
65
оператором SELECT или UNION. Оператор UNION содержит запрос SELECT, результирующие строки которого присоединяются к результату предыдущих операторов. Схема использования оператора UNION имеет вид:
SELECT …
UNION [ALL] SELECT …
[ UNION [ALL] SELECT …
. . . . . . . . . . . . . . . . . . . . . . . . . . . ]
Опция ALL сохраняет в объединенном результате запроса повторяющиеся строки. По умолчанию дубликаты строк удаляются.
Поскольку UNION добавляет строки к предыдущему набору, все операторы SELECT должны создавать строки одинаковой структуры с одинаковыми или автоматически конвертируемыми форматами данных. При этом имена столбцов результата берутся из первого оператора SELECT, а параметры ORDER BY и GROUP BY, задающие общий порядок и группировку результата, разрешено использовать только в последнем операторе UNION SELECT . . . . .
Оператор INSERT
Оператор INSERT добавляет новую строку (строки) в таблицу БД. Включение новых строк можно выполнить непосредственно в таблицу,
представление БД или функцию набора строк, но данные, тем не менее, помещаются в физически хранящуюся таблицу базы. Одним оператором можно добавить строку только в одну таблицу.
66

INSERT < имя дополняемой таблицы>
имя |
имя |
< выражение 1 |
< выражение n > |
||
[(< столбца1>, [, < столбца n >])]VALUES |
|
NULL , . . . . . . . . . . .., NULL |
|
||
|
|
||||
|
|
DEFAULT |
DEFAULT |
|
|
Первым параметром в операторе INSERT указывается имя дополняемой таблицы. Далее в операторе INSERT в круглых скобках через запятую могут быть перечислены имена столбцов, значения которых определяются следующим параметром оператора. Если имена столбцов в операторе не заданы, то они выбираются из структуры таблицы. Следующий параметр VALUES определяет значения полей добавляемой строки. Через запятую задаются значения для каждого столбца в последовательности их перечисления в операторе. Отдельное значение поля добавляемой строки может быть представлено вычисляемым выражением, признаком NULL или ключевым словом DEFAULT. DEFAULT заносит в поле умалчиваемое значение, заданное для столбца в структуре таблицы. Последовательность и количество значений в VALUES должны соответствовать списку имен столбцов. С помощью параметра VALUES одним оператором можно добавить только одну строку.
В другой форме оператора INSERT добавляемые строки вместо параметра VALUES определяются подзапросом или хранимой процедурой базы
(для MS SQL Server).
INSERT < имя таблицы>
имя |
|
имя |
< подзапрос > |
[(< столбца1 |
>, |
[, < столбца n >]) ] < вызов хранимой процедуры> |
|
Например, чтобы добавить записи об авторах, живущих в Калифорнии (state = ‘CA’), из таблицы authors в существующую таблицу new_authors можно применить следующий оператор SQL:
INSERT new_authors SELECT * from authors WHERE state = ‘CA’
Структуры таблиц authors и new_authors должны совпадать.
67
Используя подзапрос или хранимую процедуру, одним оператором INSERT можно добавлять в таблицу сразу несколько строк. При этом структура строк, созданных подзапросом или процедурой, должна соответствовать заданному в операторе списку из имен столбцов дополняемой таблицы.
При любом способе добавления строк столбцы со свойством NOT NULL обязательно требуют наличия данных, а столбцы со свойством IDENTITY (инкрементное поле - счетчик), напротив, не должны иметь данных.
Оператор DELETE
Оператор DELETE используется для удаления строк из таблицы БД. Одним оператором можно удалить строки только из одной таблицы.
имя
DELETE [FROM] < таблицы> [ FROM< список используемых таблиц базы>]
[WHERE < критерий для отбора>] удаляемых строк
В первом (с необязательным ключом FROM) параметре указывается таблица, из которой удаляются строки, удовлетворяющие критерию, заданному в параметре WHERE. Если критерий не задан, то будут удалены все строки. Второй параметр FROM используется, если в критерии для отбора удаляемых строк необходимо использовать дополнительные таблицы БД. В этом параметре FROM указываются используемые таблицы совместно с заданием способа связывания их строк так, как это было определено в параметре FROM оператора SELECT.
Критерий для отбора удаляемых строк в параметре WHERE может быть задан логическим выражением, аналогичным выражению для оператора SELECT. Удаляются строки, для которых значением критерия является истина. В качестве примера удаления строк рассмотрим две связанных таблицы: Пусть Заказчики − главная таблица и их Заказы − связанная дочерняя таблица. Строки таблиц связаны полем [Код заказчика]. Оператор для удаления заказов для заказчика, заданного своим наименованием, например, ‘УГТУ-УПИ’, имеет вид:
68
DELETE [Заказы] FROM [Заказы] INNER JOIN [Заказчики]
ON [Заказы].[Код заказчика] = [Заказчики].[Код заказчика] WHERE [Заказчики].[Наименование = ‘УГТУ-УПИ’]
Здесь таблица [Заказчики] используется только для правильного отбора удаляемых строк из таблицы [Заказы].
Оператор UPDATE
Оператор UPDATE вносит изменения (обновляет данные) в таблице БД. Одним оператором UPDATE можно изменить значения в любых столбцах и строках, но только одной таблицы.
Полный синтаксис оператора UPDATE имеет вид:
UPDATE < |
имя изменяемой |
> [FROM <список используемых таблиц базы>] |
||
таблицы |
|
|||
|
< выражение |
> |
||
SET <имя столбца> = |
|
NULL |
[, . . . . ] |
|
|
|
DEFAULT |
|
|
[WHERE <критерий для отбора обновляемых строк>]
Первым параметром оператора указывается таблица, в которой изменяются данные (поля). Для указания обновляемых столбцов и их новых значений используется параметр SET (установить). Отдельный элемент в списке параметра SET определяет обновляемый столбец и его новое значение, задаваемое выражением, в котором могут использоваться имена столбцов обрабатываемой таблицы. В расчетах нового значения будут использованы значения полей из обрабатываемой строки. Параметры FROM и WHERE предназначены для определения строк, в которых изменяются заданные в параметре SET столбцы. Синтаксис этих параметров соответствует аналогичным параметрам оператора DELETE.
Схема обработки таблицы оператором UPDATE показана на рис.9.3.
69
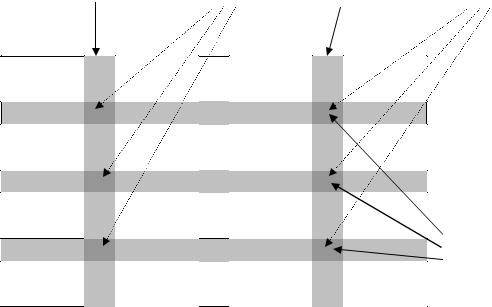
Изменяемые столбцы
SET <имя столбца 1> = < выражение>, <имя столбца 2> = < выражение>, . . .
Изменяемые строки определяются параметрами
FROM … и
WHERE …
Обновляемые |
поля таблицы |
Рис.9.3. Назначение параметров оператора UPDATE |
Например, для снижения в таблице titles цены книг (столбец price), изданных ранее 2003 года, на 15% можно применить оператор UPDATE следующего вида:
UPDATE titles SET price = price * 0.85 WHERE YEAR (pubdate) < 2003.
Здесь pubdate столбец типа DATETIME таблицы titles, который содержит дату издания. Используется встроенная функция YEAR, которая извлекает из поля даты (pubdate) год и возвращает его в виде целого числа.
Лекция 10. Архитектура и средства администрирования MS SQL Server
MS SQL Server работает под управлением операционной системы Windows и, в зависимости от редакции, может устанавливаться на сервере Windows или рабочей станции Windows Professional/XP для локального использования. Типичная установка MS SQL SERVER показана на рис. 10.1. Стандартная комплектация Microsoft SQL Server 2000 включает собственно сервер, реализованный набором служб ОС Windows, и набор готовых служебных программ (утилит) для управления сервером и его базами данных.
70
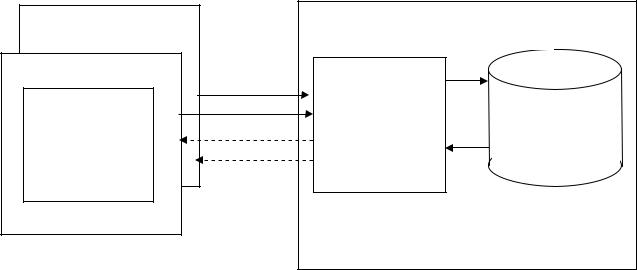
Рабочая станция n |
ОС Windows Server |
|
Рабочая станция 1 |
SQL |
|
запросы |
|
|
Утилиты |
MS SQL |
|
клиента и/или |
Server – |
Базы данных |
приложения |
набор |
|
для работы с |
сервисов ОС |
|
MS SQL Server |
Ответы |
|
сервера на |
|
|
|
|
|
|
запросы |
|
Рис. 10.1 Типичная установка MS SQL SERVER
Язык, на котором создаются запросы и программы обработки данных в
MS SQL Server, основан на стандарте SQL/92 и называется Transact SQL.
Архитектура MS SQL Server
Функции сервера обеспечивается пятью службами операционной системы
Windows:
1)MS SQL SERVER – собственно СУБД, обеспечивающая создание базы, хранение и управление данными. Для работы сервера эта служба должна быть обязательно запущена. Остальные службы решают частные задачи работы с базой данных.
2)MS SQL SERVER AGENT отвечает за:
−выполнение на сервере заданий по расписанию;
−обработку событий сервера и формирование сообщений оператору (администратору), обслуживающему базу данных.
3)MS DTC – Distributed Transaction Coordinator – координатор распределенных транзакций предназначен для работы с распределенной базой данных под управлением нескольких серверов. Выполнение распределенной транзакции на нескольких серверах реализуется по схеме двухфазной фиксации, гарантирующей выполнение транзакции всеми
71