

База данных / examen / theme_04_is
.pdfКлассификация моделей данных.
Одним из основополагающих в концепции баз данных являются обобщенные категории «данные» и «модель данных».
Понятие «данные» в концепции баз данных это набор конкретных значений, параметров, характеризующих объект, условие, ситуацию или любые другие факторы. Данные не обладают определенной структурой, данные становятся информацией тогда, когда пользователь задает им смысловое содержание. Поэтому центральным понятием в области БД является понятие модели. Не существует однозначного определения этого термина, у разных авторов эта абстракция определяется с некоторыми различиями, но тем не менее можно выделить нечто общее в этих определениях.
Модель данных – это некоторая абстракция, которая будучи приложима к конкретным данным, позволяет пользователям и разработчикам трактовать их уже как информацию, то есть сведения содержащие не только данные, но и взаимосвязь между ними. На рис. 1 представлена классификация моделей данных.
Рассмотрим понятие модели по отношению к каждому уровню.
Физическая модель данных оперирует категориями, касающимися организации внешней памяти и структуры хранения, используемых в данной операционной среде. В настоящий момент в качестве физических моделей используются различные методы размещения данных, основанные на файловых структурах: это организация файлов прямого и последовательного доступа, индексных файлов и инвертированных файлов и т.д. Кроме того, современные СУБД широко используют страничную организацию данных. Физические модели данных основанные на страничной организации являются наиболее перспективными.
Инфологические модели выражают информацию о предметной области в виде, независимой от используемой СУБД и отражают в естественной и удобной для разработчиков и других пользователей форме информационно-логический уровень
1
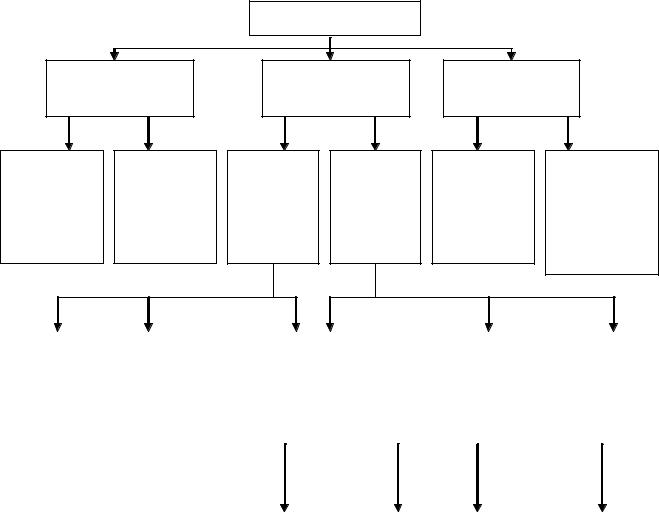
абстрагирования, связанный с фиксацией и описанием объектов предметной области, их свойств и их взаимосвязей.
|
|
модели данных |
|
|
|
инфологические |
даталогические |
физические |
|
||
модели |
|
модели |
|
модели |
|
диаграммы |
модель |
Докумен- |
фактогра- |
основанные |
основанные |
Бахмана |
сущность |
тальные |
фические |
на файловых |
на странично- |
|
Связь (ER) |
модели |
модели |
структурах |
сегментной |
|
|
|
|
|
организации |
Ориентиро- |
|
дескрип- |
|
тезаурусные |
|
теоретико- |
|
теоретико- |
|
объектно- |
||||||
ванные |
|
торные |
|
модели |
|
графовые |
|
множественные |
|
ориентиро- |
||||||
на формат |
|
модели |
|
|
|
|
|
|
|
|
|
|
|
|
ванные |
|
документиа |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
иерархическая |
|
сетевая |
|
реляцион- |
|
бинарных |
|
|
|
|
ная |
|
ассоциаций |
|
|
|
|
|
|
|
Рис.1. Классификация моделей данных.
Инфологические модели данных используются на ранних стадиях проектирования для описания структур данных в процессе разработки приложения, а даталогические модели уже поддерживаются конкретной СУБД.
Документальные модели данных соответствуют представлению о слабоструктурированной информации, ориентированной в основном на свободные форматы документов, текстов на естественном языке.
2
Тезаурусные модели основаны на принципе организации словарей, содержат определенные языковые конструкции и принципы их взаимодействия в заданной грамматике. Эти модели эффективно используется в системах – переводчиках, особенно многоязыковых переводчиках. Принцип хранения информации в этих системах и подчиняется тезаурусные модели.
Дескрипторные модели – самые простые из документальных моделей, они широко использовались на ранних стадиях использования документальных баз данных. В этих моделях каждому документу соответствовал дескриптор – описатель. Этот дескриптор имел жесткую структуру и описывал документ в соответствии с теми характеристиками, которые требуются для работы с документами в разрабатываемой документальной базы данных.
Теоретико-графовые модели данных отражают совокупность объектов реального мира в виде графа взаимосвязанных информационных объекта. В зависимости от типа графа выделяют иерархическую и сетевую модель данных.
Появление теоретико-множественных моделей в системах баз данных было предопределено настоятельной потребностью пользователей в переходе от работы с элементами данных, как это делается в графовых моделях, к работе с некоторыми макрообъектами. Основной моделью в этом классе является модель данных. Реляционная модель баз данных представляет собой набор связанных между собой таблиц. Каждая из таблиц содержит информацию о каких-либо объектов одной группы. Все записи одной таблицы имеют идентичные, заданные пользователем, структуру и размеры.[3]
3
Глава 3. Реляционная модель данных
Реляционная модель данных была предложена Е. Коддом, известным американским специалистом в области баз данных. Основные концепции этой модели были впервые опубликованы в 1970 г. в статье «A Relational Model of Data for Large Shared Data Banks» (CACM, 1970, Vol. 13, № 6). Реляционная модель позволила решить одну из важнейших задач в управлении базами данных — обеспечить независимость представления и описания данных от прикладных программ, следствием чего было бы существенное упрощение проектирования и программирования баз данных.
К основным достоинствам реляционного подхода к управлению базой данных следует отнести:
-наличие небольшого набора абстракций, которые позволяют сравнительно просто моделировать большую часть распространенных предметных областей и допускают точные формальные определения, оставаясь интуитивно понятными;
-наличие простого и в то же время мощного математического аппарата, опирающегося главным образом на теорию множеств и математическую логику и обеспечивающего теоретический базис реляционного подхода к организации баз данных;
-возможность манипулирования данными без необходимости знания конкретной физической организации баз данных во внешней памяти.
Несмотря на все свои достоинства, реляционные системы далеко не сразу получили широкое признание. Хотя уже во второй половине 70-х годов появились первые прототипы реляционных СУБД, долгое время считалось невозможным добиться эффективной реализации таких систем. Однако постепенное накопление методов и алгоритмов организации реляционных баз данных и управления ими привели к тому, что уже в середине 80-х годов реляционные системы практически вытеснили с мирового рынка ранние СУБД.
В настоящее время реляционные СУБД остаются одними из наиболее распространенных, несмотря на некоторые присущие им недостатки. Сейчас основным предметом критики реляционных СУБД является не их недостаточная эффективность, а некоторая ограниченность таких систем при использовании в так называемых нетрадиционных областях (наиболее распространенными примерами являются системы автоматизации проектирования), в которых требуются предельно сложные структуры данных. Причем эта ограниченность реляционных СУБД является прямым следствием их простоты и проявляется лишь в отдельных предметных областях. Вторым часто отмечаемым недостатком реляционных баз данных является невозможность адекватного отражения семантики предметной области — возможности
4
представления знаний о семантической специфике предметной области в реляционных системах очень ограничены.
На устранение именно этих недостатков в основном и направлены исследования по созданию объектно-ориентированных баз данных.
§ 1. Базовые понятия реляционной модели данных
Термин «реляционный» (от английского relation — отношение) указывает прежде всего на то, что такая модель хранения данных построена на взаимоотношении составляющих ее частей, которые удобно представлять в виде двумерной таблицы. Кодд показал, что набор отношений (таблиц) может быть использован для хранения данных об объектах реального мира и моделирования связей между ними. Таким образом, реляционная модель данных представляет информацию в виде совокупности взаимосвязанных таблиц, которые принято называть отношениями или реляциями.
Основными понятиями реляционной модели данных являются:
-тип данных;
-домен;
-атрибут;
-кортеж;
-ключ.
Рассмотрим смысл этих понятий на примере отношения (таблицы) СТУДЕНТЫ, содержащего информацию о студентах некоторого вуза (табл. 4.1).
Таблица 4.1. Пример отношения СТУДЕНТЫ реляционной базы данных
№_студенческого |
Имя |
Дата_ |
Курс |
Специальность |
_ билета |
|
рождения |
|
|
23980282 |
Алексеев Д. А. |
12.03.1982 |
2 |
Биология |
22991380 |
Яковлев Н. В. |
25.12.1979 |
4 |
Физика |
22657879 |
Михайлов В. В. |
29.02.1979 |
5 |
Математика |
24356783 |
Афанасьев А. В. |
19.08.1983 |
1 |
Иностранный язык |
24350283 |
Кузнецов В. И. |
03.10.1982 |
1 |
Физика |
23125681 |
Смирнов А. Д. |
26.03.1981 |
3 |
История |
Тип данных
Понятие тип данных в реляционной модели данных полностью эквивалентно соответствующему понятию в алгоритмических языках. Набор поддерживаемых типов данных определяется СУБД и может сильно различаться в разных системах. Однако практически все СУБД поддерживают следующие типы данных:
-целочисленные;
-вещественные;
5
-строковые;
-специализированные типы данных для денежных величин;
-специальные типы данных для временных величин (дата и/или время);
-типы двоичных объектов (данный тип не имеет аналога в языках программирования; обычно для его обозначения используется аббревиатура BLOB — Binary Large Object).
В настоящее время достаточно активно развивается подход к расширению возможностей реляционных систем абстрактными типами данных (соответствующими возможностями обладают, например, системы семейства Ingres/Postgres).
В рассматриваемом примере используются три типа данных — строковый (столбцы «Имя» и «Специальность»), временной тип (столбец «Дата_рождения») и целочисленный тип («Курс» и «№_студенческого_билета»).
Домен
Наименьшая единица данных реляционной модели — это отдельное атомарное (неразложимое) для данной модели значение данных. Доменом называется множество атомарных значений одного и того же типа. Иными словами, домен представляет собой допустимое потенциальное множество значений данного типа.
В нашем примере можно для каждого столбца таблицы определить домен:
-домены «Имена» и «Специальности» для столбцов «Имя» и «Специальность» соответственно будут базироваться на строковом типе данных — в число их значений могут входить только те строки, которые могут изображать имя и название специальности (в частности, такие строки не должны начинаться с мягкого знака);
-домен «Даты_рождения» для столбца «Дата_рождения» определяется на базовом временном типе данных — данный домен содержит только допустимый диапазон дат рождения студентов;
-домены «Номера_курсов» и «Номера_студенческих_билетов» базируются на целочисленном типе — в число его значений могут входить только те целые числа, которые могут обозначать номер курса университета (обычно от 1 до 6) и номер студенческого билета (обязательно положительное число).
Понятие домена более специфично для баз данных, хотя и имеет некоторые аналогии с диапазонными типами и множествами, имеющимися в ряде языков программирования. В самом общем виде домен определяется заданием некоторого базового типа данных, к которому относятся элементы домена, и произвольного логического выражения, применяемого к элементу типа данных. Если вычисление этого логического выражения дает результат «истина», то элемент данных является элементом домена.
6
Следует отметить также семантическую нагрузку понятия домена: данные считаются сравнимыми только в том случае, когда они относятся к одному домену. Если же значения двух атрибутов берутся из различных доменов, то их сравнение, вероятно, лишено смысла. В нашем примере значения доменов «Номера_курсов» и «Номера_студенческих_билетов» основаны на одном типе данных — целочисленном, но не являются сравнимыми.
Понятие домена используется далеко не во всех СУБД. В качестве примера реляционных баз данных, использующих домены, можно привести Oracle и InterBase.
Атрибуты, схема отношения, схема базы данных
Столбцы отношения называют атрибутами, им присваиваются имена, по которым к ним затем производится обращение.
Список имен атрибутов отношения с указанием имен доменов (или типов, если домены не поддерживаются) называется схемой отношения.
Схема нашего отношения СТУДЕНТ запишется так:
СТУДЕНТ {№_студенческого_билета Номера_студенческих_билетов Имя Имена.
Дата_рождения Даты_рождения. Курс Номера_курсов. Специальность Специальности}
Степень отношения — это число его атрибутов. Отношение степени один называют унарным, степени два — бинарным, степени три — тернарным,..., а степени n — n-арным.
Степень отношения СТУДЕНТЫ равна пяти, то есть оно является 5-арным. Схемой базы данных называется множество именованных схем отношений.
Кортеж
Кортеж, соответствующий данной схеме отношения, представляет собой множество пар {имя атрибута, значение}, которое содержит одно вхождение каждого имени атрибута, принадлежащего схеме отношения. «Значение» является допустимым значением домена данного атрибута (или типа данных, если понятие домена не поддерживается). Тем самым степень кортежа, то есть число элементов в нем, совпадает со степенью соответствующей схемы отношения. Иными словами, кортеж — это набор именованных значений заданного типа.
Схему отношения иногда называют также заголовком отношения, а отношение как набор кортежей — телом отношения.
Понятие схемы отношения напоминает понятие структурного типа данных в языках программирования (структура в C/C++, запись в Pascal). Однако в реляционных базах данных имя
7
схемы отношения всегда совпадает с именем соответствующего отношения-экземпляра. В классических реляционных базах данных после определения схемы базы данных изменяются только отношения-экземпляры. В них могут появляться новые и удаляться или модифицироваться существующие кортежи. Однако во многих реализациях допускается и изменение схемы базы данных: определение новых и изменение существующих схем отношения. Это принято называть эволюцией схемы базы данных.
Таким образом, отношение по сути является множеством кортежей, соответствующим одной схеме отношения.
Кардинальным числом или мощностью отношения называется число его кортежей. Мощность отношения СТУДЕНТЫ равна 6. В отличие от степени отношения кардинальное число отношения изменяется во времени.
Пустые значения
Внекоторых случаях какой-либо атрибут отношения может быть неприменим. Например, в рассматриваемом в качестве примера отношении СТУДЕНТЫ может также храниться информация о потенциальных абитуриентах, посещающих подготовительные курсы вуза. В этом случае неприменимыми оказываются атрибуты «№_студенческого_билета» и «Курс» (так как абитуриенты еще не поступили в вуз и, следовательно, не имеют студенческого билета и не могут быть отнесены к какому-либо курсу). Кроме того, иногда при вводе информации в строку реляционной таблицы некоторые данные могут быть неизвестны и выясняться позже. (Для нашего примера — при поступлении на подготовительные курсы абитуриент еще не определился окончательно, на какую специальность он будет поступать.)
Вобоих указанных случаях в поля, соответствующие неприменимым или неизвестным атрибутам, ничего не заносится, и строка записывается в базу данных с пустыми значениями этих атрибутов.
Следует понимать, что пустое значение — это не ноль и не пустая строка, а неизвестное значение атрибута, которое не определено в данный момент времени и в принципе может быть определено позднее.
Для обозначения пустых значений полей используется слово NULL.
Ключи отношения
Поскольку отношение с математической точки зрения является множеством, а множества по определению не содержат совпадающих элементов, то никакие два кортежа отношения не могут быть дубликатами друг друга в любой произвольно заданный момент времени. Таким образом, в отношении всегда должен присутствовать некоторый атрибут (или набор атрибутов), однозначно
8
определяющий каждый кортеж отношения и обеспечивающий уникальность строк таблицы. Такой атрибут (или набор атрибутов) называется первичным ключом отношения.
Более строго определить понятие первичного ключа можно следующим образом:
если R — отношение с атрибутами A1, A2,…An то множество атрибутов К = (Аi, Аj,...,Ak) отношения R является первичным ключом этого отношения тогда и только тогда, когда удовлетворяются два независимых от времени условия:
-уникальность: в произвольный момент времени никакие два различных кортежа отношения R не имеют одного и того же значения для Аi, Аj,...,Ak;
-минимальность: ни один из атрибутов Аi, Аj,...,Ak не может быть исключен из К без нарушения уникальности.
Для каждого отношения свойством уникальности обладает по крайней мере полный набор его атрибутов. Однако требуется обеспечить и условие минимальности. Поэтому, как правило, в отношении всегда имеется один атрибут, обладающий свойством уникальности и являющийся первичным ключом.
В зависимости от количества атрибутов, входящих в ключ, различают простые и сложные (или составные) ключи.
Простой ключ — ключ, содержащий только один атрибут. В общем случае операции объединения выполняются быстрее в том случае, когда в качестве ключа используется самый короткий и самый простой из возможных типов данных. С этой точки зрения наилучшим образом подходит целочисленный тип, который имеет аппаратную поддержку для выполнения над ним логических операций.
Сложный или составной ключ — ключ, состоящий из нескольких атрибутов.
Набор атрибутов, обладающий свойством уникальности, но не обладающий минимальностью, называется суперключом. Суперключ — сложный (составной) ключ с большим числом столбцов, чем необходимо для того, чтобы быть уникальным идентификатором. Такие ключи нередко используются на практике, так как избыточность может оказаться полезной пользователю.
В зависимости от того, содержит ли атрибут, являющийся первичным ключом, какую-либо информацию, различают искусственные и естественные ключи.
Искусственный или суррогатный ключ — ключ, созданный самой СУБД или пользователем
спомощью некоторой процедуры, который сам по себе не содержит информации. Искусственный ключ используется для создания уникальных идентификаторов строк, когда сущность должна быть описана полностью, чтобы однозначно идентифицировать конкретный элемент. Искусственный ключ часто используют вместо значимого сложного ключа, который является
9
слишком громоздким, чтобы использоваться в реальной базе данных. Система поддерживает искусственный ключ, но он никогда не показывается пользователю.
Естественный ключ — ключ, в который включены значимые атрибуты и который, таким образом, содержит информацию.
Врассматриваемом нами примере в качестве первичного ключа отношения СТУДЕНТЫ можно рассматривать атрибут №_студенческого_билета. Причем данный ключ будет естественным, так как он несет вполне определенную информацию.
Каждый из типов первичных ключей имеет свои преимущества и недостатки; их обсуждению посвящено большое количество публикаций. Мы не будем проводить подробное их сравнение, а отметим лишь основные плюсы и минусы каждого из видов ключей.
Основными достоинствами естественных ключей является то, что они несут вполне определенную информацию и их использование не приводит к необходимости добавлять в таблицы атрибуты, значения которых не имеют никакого смысла и используются лишь для связи между отношениями. Иными словами, использование естественных ключей позволяет получить более компактную форму таблиц (в которых не будет избыточных, неинформативных данных) и более естественные связи между ними.
Основным же недостатком естественных ключей является то, что их использование весьма затруднительно в случае изменчивости предметной области. Следует понимать, что значения атрибутов первичного ключа не должны изменяться. То есть однажды заданное значение первичного ключа для кортежа не может быть позже изменено. Такое требование ставится в основном для поддержания целостности базы данных. Связь между отношениями обычно устанавливается именно по первичному ключу, и его изменение приведет к нарушению этих связей или к необходимости изменения записей в нескольких таблицах. Даже в сравнительно простых базах данных это может вызвать ряд трудноразрешимых проблем.
Внекоторых реляционных СУБД допускается изменение первичного ключа. Иногда это бывает действительно полезно. Однако прибегать к этому следует лишь в случае крайней необходимости.
Типичным примером изменчивой предметной области, в которой для сущности невозможно определить неизменный естественный ключ, является любая область, где в качестве сущности выступает человек. Действительно, невозможно определить для человека набор атрибутов, которые были бы уникальны и неизменны на протяжении всей его жизни.
Второй, довольно существенный недостаток естественных ключей состоит в том, что, как правило, уникальные естественные ключи являются составными и содержат строковые атрибуты. Как уже отмечалось выше, максимальная скорость выполнения операций над данными
10