

metoda_2013
.pdfТЕОРИЯ ЯЗЫКОВ ПРОГРАММИРОВАНИЯ И МЕТОДЫ ТРАНСЛЯЦИИ
полностью в одном месте. А с другой стороны, это плохо, так как транслятор становится машинозависимым, и это делает его не мобильным.
Условия использования метода рекурсивного спуска
Метод рекурсивного спуска без возвратов можно использовать только для грамматик, правила которых удовлетворяют следующему условию: первого символа каждого правила должно быть достаточно для того, чтобы определить, какое правило применимо в данном случае. Более точно это условие можно формализовать путем определения множества FIRST.
Основные положения
Правила факторизации (левой факторизации) заключаются в том, что общие части грамматических правил выносятся за скобку. Эти правила называют также и “вынесением левого множителя”.
Принцип левой факторизации можно выразить в символической форме следующим образом: если грамматика содержит n правил
<A>=>a1b . . . <A>=>abn
где <A>- нетерминал, а a и bi для 1£ i £ n - цепочки нетерминалов и терминалов, то эти правила можно заменить на следующие n+1 правила:
<A>=>a<В>
<В>=>1b ... <B>=>bn
где <В>- нетерминальный символ, не входящий в исходную грамматику.
Грамматика, полученная такой заменой, порождает тот же язык, что и исходная грамматика, и о ней говорят, что она получена левой факторизацией.
Нисходящий разбор — класс алгоритмов грамматического анализа, где правила формальной грамматики раскрываются, начиная со стартового символа, до получения требуемой последовательности токенов.
Проблемы:
1. Сам по себе метод не исключает возвратов, т.е. для нетерминала, имеющего несколько правых частей, приходится решать, какую альтернативу необходимо выбрать. Пример,
<idlist> = id | id, <idlist>.
Для того, чтобы избавиться от возвратов, в компиляторах в качестве контекста обычно используется следующий "незакрытый" символ исходной программы. Тогда на грамматику налагается следующее требование: если есть альтернативы
240
ТЕОРИЯ ЯЗЫКОВ ПРОГРАММИРОВАНИЯ И МЕТОДЫ ТРАНСЛЯЦИИ
x|y|...|z, то множества символов, которыми могут начинаться выводимые из x,y,..,z слова, должны быть попарно различны. То есть если x => *Au и y => *Bv то A =/= B. если это требование выполнено, можно довольно просто определить, какая из альтернатив x,y или z - наша цель. Заметим, что факторизация оказывает здесь большую помощь. Если есть правило U ::= xy|xz, то преобразование этого правила к виду U ::= x(y|z) помогает сделать множесва первых символов для разных альтернатив непересекающимися.
2. Второй проблемой является левая рекурсия. Рассмотрим предложение <idlist> = id | <idlist>, id. Если
процедура выберет вторую альтернативу <idlist>, id, то она немедленно вызовет рекурсивно саму себя для поиска нетерминала <idlist>. В результате будет зацикливание.
В связи с этим недостатком рекурсивного спуска, в процессе грамматического разбора часто используется замена левой рекурсии на правую.
Правила факторизации (левой факторизации) заключаются в том, что общие части грамматических правил выносятся за скобку. Принцип левой факторизации можно выразить в символической форме следующим образом:
если грамматика содержит n правил <A> . . .<A>
n,
где <A> - нетерминал, а и i для 1 i n - цепочки нетерминалов и терминалов, то эти правила можно заменить на следующие n+1 правила:
<A> <В>
<В> ... <B> n
где <В>- нетерминальный символ, не входящий в исходную
грамматику. |
|
Пример, A BC |
A BCM |
A BCD |
A axN |
A axy |
M |
A аxz |
M D |
|
N y |
|
N z |
Нетерминал называется леворекурсивным, если, применяя к нему одно или более правил, можно вывести цепочку, начинающуюся этим нетерминалом. Правило называется леворекурсивным, если оно используется на первом шаге такого вывода. Пример, <A> a<B>; <A> <B>b; <B> <A>c; <B> d
Правило называется самолеворекурсивным, если его первый символ правой части и левая часть – это один и тот же символ.
241
ТЕОРИЯ ЯЗЫКОВ ПРОГРАММИРОВАНИЯ И МЕТОДЫ ТРАНСЛЯЦИИ
Пример, <S> <S> a; <S> b
Грамматику с левой рекурсивностью всегда можно переделать в грамматику с правой рекурсией. Основная идея при этом состоит в том, чтобы смотреть на рекурсивный нетерминал как на порождающий некоторую цепочку, за которой следует список из одного или более элементов.
Пример, грамматика: <idlist> id | <idlist> , id заменяется на
<idlist> id <A> <A> | , id <A>
7. LL(K)-грамматики. Направляющие символы. Идея разбора.
LL(k) – грамматики, основанные на принципе выборе одной альтернативы из множества возможных на основе нескольких очередных символов в цепочке. Грамматика обладает свойством LL(k), k > 0, если на каждом шаге вывода для однозначного выбора очередной альтернативы МП-автомату достаточно знать символ на верхушке стека и рассмотреть первые k символов от текущего положения считывающей головки во входной цепочке символов. Грамматика называется LL(k)-грамматикой, если она обладает св-вом LL(k) для нек. k > 0.
Название «LL(k)» несет определенный смысл. Первая литера «L» происходит от слова «left» и означает, что входная цепочка символов читается в направлении слева направо. Вторая литера «L» также происходит от слова «left» и означает, что при работе распознавателя используется левосторонний вывод. Вместо «k» в названии класса грамматики стоит некоторое число, которое показывает, сколько символов надо рассмотреть, чтобы однозначно выбрать одну из множества альтернатив. Так, существуют LL(1)-грамматики, LL(2)-грамматики и другие классы.
Для LL(k)-грамматик известны следующие полезные свойства:
всякая LL(k)-грамматика для любого k>0 является однозначной;
существует алгоритм, позволяющий проверить, является ли заданная грамматика LL(k)-грамматикой для строго
определенного числа k.
Кроме того, известно, что все грамматики, допускающие разбор по методу рекурсивного спуска, являются подклассом LL(1)- грамматик. То есть любая грамматика, допускающая разбор по методу рекурсивного спуска, является LL(1)-грамматикой (но не наоборот!).
Есть, однако, неразрешимые проблемы для произвольных КСграмматик:
242
ТЕОРИЯ ЯЗЫКОВ ПРОГРАММИРОВАНИЯ И МЕТОДЫ ТРАНСЛЯЦИИ
не существует алгоритма, который бы мог проверить, является ли заданная КС-грамматика LL(k)-грамм. для нек. произвольного числа k;
не существует алгоритма, который бы мог преобразовать произвольную КС-грамматику к виду LL(k)-грамматики для некоторого k (или доказать, что преобразование
невозможно).
Множество символов, позволяющих сделать правильный выбор правила, называется множеством выбора или множеством направляющих символов. Направляющие символы являются единственно допустимыми символами на каждом шаге анализа.
Идея разбора
Для каждого нетерминального символа, находящегося в левой части строится строка таблицы, в которую вносится имя нетерминала, множество направляющих символов для этого нетерминала и указатель на группу строк соответствующей правой части правила.
Если нетерминал имеет несколько альтернатив, то для него строятся соответствующие альтернативам строки, в каждую вносится имя нетерминала, множество направляющих символов для этого нетерминала и альтернативы, указатель на группу строк соответствующей альтернативы.
Каждому элементу из правой части отводится строка таблиц:
Если символ терминальный, то в строку вносится символ,
иуказатель на следующую строку таблицы, если символ не последний в альтернативе, иначе указателю присваивается нулевое значение.
Для нетерминала правой части строится строка таблицы, в которую вносится имя нетерминала, множество направляющих символов для этого нетерминала и указатель на строку, помеченную этим нетерминалом для левой части правила.
Для пустого символа тоже создается строка, в которую вносится пустой символ, множество направляющих символов
иуказателю присваивается нулевое значение.
243
ТЕОРИЯ ЯЗЫКОВ ПРОГРАММИРОВАНИЯ И МЕТОДЫ ТРАНСЛЯЦИИ
8. Построение LL(1)таблицы разбора.Разбор по LL(1)таблице.Проблемы LL(1)-разбора. Достоинство и недостатки метода.
LL(k) – грамматики, основанные на принципе выборе одной альтернативы из множества возможных на основе нескольких очередных символов в цепочке.
Название «LL(k)» несет определенный смысл. Первая литера «L» происходит от слова «left» и означает, что входная цепочка символов читается в направлении слева направо. Вторая литера «L» также происходит от слова «left» и означает, что при работе распознавателя используется левосторонний вывод. Число 1 показывает, сколько символов надо рассмотреть, чтобы однозначно выбрать одну из множества альтернатив.
Основные положения:
Для каждого нетерминального символа, находящегося в левой части строится строка таблицы, в которую вносится имя нетерминала, множество направляющих символов для этого нетерминала и указатель на группу строк соответствующей правой части правила.
Если нетерминал имеет несколько альтернатив, то для него строятся соответствующие альтернативам строки, в каждую вносится имя нетерминала, множество направляющих символов для этого нетерминала и альтернативы, указатель на группу строк соответствующей альтернативы.
Каждому элементу из правой части отводится строка таблиц:
Если символ терминальный, то в строку вносится символ, и указатель на следующую строку таблицы, если символ не последний в альтернативе, иначе указателю присваивается нулевое значение.
Для нетерминала правой части строится строка таблицы, в которую вносится имя нетерминала, множество направляющих символов для этого нетерминала и указатель на строку, помеченную этим нетерминалом для левой части правила.
Для пустого символа тоже создается строка, в которую вносится пустой символ, множество направляющих символов
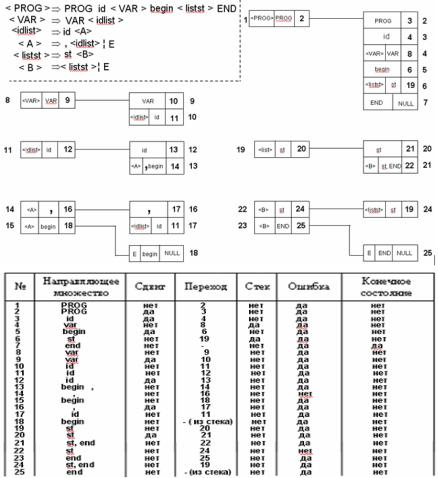
и указателю присваивается нулевое значение. Пример построения LL(1) :
244
ТЕОРИЯ ЯЗЫКОВ ПРОГРАММИРОВАНИЯ И МЕТОДЫ ТРАНСЛЯЦИИ
LL(k) – грамматики, основанные на принципе выборе одной альтернативы из множества возможных на основе нескольких очередных символов в цепочке.
Название «LL(k)» несет определенный смысл. Первая литера «L» происходит от слова «left» и означает, что входная цепочка символов читается в направлении слева направо. Вторая литера «L» также происходит от слова «left» и означает, что при работе распознавателя используется левосторонний вывод. Число 1 показывает, сколько символов надо рассмотреть, чтобы однозначно выбрать одну из множества альтернатив.
245
ТЕОРИЯ ЯЗЫКОВ ПРОГРАММИРОВАНИЯ И МЕТОДЫ ТРАНСЛЯЦИИ
Разбор по таблице:
Для левой части правила:
проверка входного символа на попадание в направляющее множество данного нетерминала и переход по указателям в случае, если входной символ совпадает с одним из направляющих символов. В противном случае – ошибка
(error).
Для терминала:
Проверка на совпадение входного символа с терминальным, если нет, то – ошибка (error);
Сдвиг по входной цепочке;
Переход по указателю, если указатель имеет нулевое значение, то переход по адресу, находящемуся в верхушке
стека.
Для нетерминала:
Проверка входного символа на совпадение с одним из символов направляющего множества;
В стек заносится адрес следующей строки, соответствующей следующему за нетерминалом символу правой части правила. Если такого символа нет, т.е. символ последний во входной цепочке, то в стек ничего не заносится.
Переход по указателю.
Для пустого символа:
проверка входного символа на совпадение с одним из
символов направляющего множества;
переход по указателю, находящемуся в верхушке стека.
Для левой части правила, имеющей несколько альтернатив:
входной символ проверяется на вхождение в направляющее
множество сначала первой альтернативы;
если входной символ не входит в это направляющее множество, то переход на следующую строчку, соответствующей следующей альтернативе и т.д.;
если входной символ не входит в направляющее множество
последней альтернативы, тогда ошибка (error);
если входной символ совпал с одним из символов направляющего множества одной из альтернатив, то переход по указателю соответствующей строки.
Модификация LL(1)-таблицы:
Модификация LL(1)-таблицы производится в ходе ее обработки.
246

ТЕОРИЯ ЯЗЫКОВ ПРОГРАММИРОВАНИЯ И МЕТОДЫ ТРАНСЛЯЦИИ
Основные поля новой таблицы: номер строки, направляющее множество (для каждого символа), сдвиг по входной цепочке (есть он или нет), переход (номер строки, на который происходит переход), стек (вносится адрес строки символа), ошибка (необходима для определения перехода по альтернативе), конечное состояние (конец разбираемой цепочки).
Алгоритм заканчивается успешно, если входная цепочка разобрана и признана принадлежащей разбираемому языку, если стек пустой, входной символ соответствует концу цепочки и разбор заканчивается на строке, соответствующей конечному состоянию. В противном случае разбор заканчивается с сообщением об ошибке.
Пример разбора для таблицы из прошлого вопроса:
program work var A,B,C begin st st end
1.Считывается program, проверяется и переход к 2.
2.program принимается, переход к 3.
3.Считывается work(id), принимается, переход к 4.
4.Считывается var, переход к 8.
8.Проверяется var, переход к 9.
9.Принимается var, переход к 10.
10.Считывается А(id), переход к 11.
11.Проверяется id, переход к 12
12.Принимается id, переход к 13
13.Считывается ",", переход к 14
14.Выбор по ",", переход к 15-16
16.Принимаем ",", переход к 18
18.Считываем В(id), переход к 11
11.Проверяется id, переход к 12
12.Принимается id, переход к 13
13.Считывается ",", переход к 14, по "," к 15-17
17.Принимаем ",", переход к 18
18.Считываем С(id), переход к 11
11.Проверяется id, переход к 12
12.Принимается id, переход к 13
13.Считывается begin, переход к 14, выбор 16
16.Переход по адресу из стека (5)
5.begin принимается, переход к 6
247

ТЕОРИЯ ЯЗЫКОВ ПРОГРАММИРОВАНИЯ И МЕТОДЫ ТРАНСЛЯЦИИ
6. Считывается st, переход к 19, в стек 7
19.Опр, переход к 20.
20.Принимается st, переход к 21
21.Считывается st, переход к 22
22.по st, переход к 25
25. переход к 19
19.переход к 20
20.Принимается st, переход к 21
21.Считывается end, переход к 22
22.по end, переход к 24
23.переход по адресу стека
25.Принимаем end, в стеке 0, в цепочке ~
Проблемы LL(1) разбора: см вопрос 9: “Проблемы нисходящего разбора”.
Достоинства распознавателей, основанных на LL(1) грамматике
в отличие от рекурсивного спуска в методе нет возвратов, это детерминированный метод;
время разбора пропорционально длине входной программы;
имеются хорошие диагностические характеристики, и существует возможность исправления ошибок, так как распознавание ведется по одному символу;
таблица разбора меньше, чем соответствующая таблица разбора в других методах.
Недостаток распознавателей, основанных на LL(1) грамматиках
не все классы языков описываются LL(1) грамматиками.
248
ТЕОРИЯ ЯЗЫКОВ ПРОГРАММИРОВАНИЯ И МЕТОДЫ ТРАНСЛЯЦИИ
9. Восходящий разбор. Проблемы. Общий метод разбора.LR(K)-грамматики. Идея разбора.
LR-грамматики основаны на восходящем методе разбора, то есть разборе снизу - вверх, при котором промежуточные выводы перемещаются по дереву по направлению к корню. Разбор идет справа налево.
При восходящем разборе дерево начинает строиться от терминальных листьев путем подстановки правил, применимых к входной цепочке, в общем случае, в произвольном порядке. На следующем шаге новые узлы полученных поддеревьев используются как листья во вновь применяемых правилах. Процесс построения дерева разбора завершается, когда все символы входной цепочки будут являться листьями дерева, корнем которого окажется начальный нетерминал. Если, в результате полного перебора всех возможных правил, мы не сможем построить требуемое дерево разбора, то рассматриваемая входная цепочка не принадлежит данному языку.
При использовании этого метода в текущей сентенциальной форме повторяется поиск основы (самой левой простой фразы), которая в соответствии с правилом U::= u приводится к нетерминалу U. При восходящем разборе возникает проблема – как найти основу и выяснить к какому нетерминалу нужно ее приводить и как найти основу, если задана сентенциальная форма (последовательность символов (терминалов и нетерминалов), выводимых из аксиомы) x. Хотелось бы, двигаясь слева направо и рассматривая только два соседних символа одновременно, суметь определить, нашли ли мы хвост основы. А затем, продвигаясь назад к левому концу сентенциальной формы, найти голову основы, принимая каждый раз решение только по двум соседним символам. То есть мы сталкиваемся с такой проблемой: если задана цепочка …RS…, то всегда ли R является хвостом основы, или RS вместе могут встретиться в основе, или возможны другие варианты? Хотелось бы, не приступая еще к разбору, исследовать грамматику и принять решение относительно каждой пары символов R и S.
Рассмотрим два символа R и S из словаря V грамматики G. Предположим, что существует (каноническая) сентенциальная форма …RS… На некотором этапе канонического разбора либо R, либо S (либо оба символа одновременно) должны войти в основу. При этом возникают следующие три возможности:
249