БД_1-20
.docx|
*. Назначение и области применения систем БД (СБД). Типы СБД. Информационные системы с БД (СБД) и технологии БД создавались для решения некоторого круга проблем, возникающих при работе с большими массивами записей. Во-первых, это проблема поддержания целостности данных. Необходимо наличие входного контроля данных. Хранимые данные должны обновляться. В противном случае они быстро становятся неактуальными. При обновлении может нарушаться целостность данных. Т. о., при ведении записей необходим входной контроль данных на целостность. Во-вторых, это проблема рациональной организации данных. Данные д/б структурированы и упорядочены так, чтобы была возможна быстрая выборка подмножества записей по значениям произвольной совокупности признаков. Кроме того, есть «пересекающиеся данные», поэтому они в целом должны расм-ться как единый информационный ресурс. Д/б обеспечено централизованное управление этим ресурсом. Необходима единая система, которая решает:
Именно эти проблемы призваны решать технологии БД и системы с БД . Современные СБД обеспечивают:
Система базы данных – это система специальным образом организованных данных, программных, технических, языковых, организационно-методических ср-в, предназначенная для поддержания динамической информационной модели ПО и коллективного многоцелевого использования данных. БД и СУБД образуют ядро так называемой системы базы данных (СБД). Помимо БД и СУБД в систему включаются аппаратура, приложения, документация и пользователи. Архитектуры многопользовательских СБД весьма разнообразны. Выделяют два больших класса архитектур: системы с локальным доступом и системы с удаленным (сетевым) доступом.
Системы с локальным доступом разворачиваются на мощных универсальных ЭВМ. ЦП ЭВМ обеспечивает функционирование приложений пользователей, СУБД и ОС. Пользователи системы запускают свои приложения с рабочих станций (РС). РС обычно представляет собой простой терминал –используемый лишь для ввода и отображения данных. Наиболее распространѐны две архитектуры систем централизованных БД с сетевым доступом: с файловым сервером и с сервером базы данных. Обе архитектуры предполагают выделение одного из узлов сети в качестве центрального (серверного). На этом узле хранится совместно используемая централизованная БД. Все другие узлы сети выполняют функции РС (клиентов). Они поддерживают доступ пользователей системы к централизованной БД. В архитектуре с файловым сервером на каждом клиентском узле разворачиваются пользовательское приложение и копия СУБД. СУБД обрабатывает запросы приложения и генерирует соответствующие последовательности команд чтения/записи файлов внешней памяти. ОС сервера считывает запрошенные файлы БД и передаѐт их через сеть на клиентский узел. Клиентская копия СУБД производит выборку и обработку данных, затребованную приложением. Если приложение выполняло обновление данных, то обновлѐнные файлы возвращаются с ОС сервера. В архитектуре с сервером БД на клиентских узлах разворачиваются только приложения пользователей. На серверном узле не только хранится централизованная БД, но и функционирует единственная в системе копия СУБД. Сервер БД обеспечивает выполнение основного объѐма обработки данных. Запрос, выдаваемый клиентом, порождает выборку данных на сервере. Результаты выборки (но не файлы!) передаются по сети от сервера к клиенту. |
17. Понятие базы данных. Структурные единицы БД. Метаданные и индексы. БД (БД) – это самодокументированная интегрированная совокупность записей. Самодокументированность означает, что вместе с данными пользователей в БД содержится описание еѐ собственной структуры. Это описание назыв. метаданными. Метаданные сохраняются в специальном разделе БД. Он назыв. каталогом данных или, что то же самое, словарѐм данных. Все сведения о ресурсах данных можно получить из словаря данных. Кроме того, если понадобится как-либо изменить существующие структуры данных ( добавить новые поля), то нужно будет внести изменения только в словарь данных и, возможно, в те программы, кот. непоср-венно обрабатывают изменѐнные элементы. Тем самым обеспечивается независимость прикладных программ от данных. Интегрированность означает, что БД наряду с записями пользователей содержит сведения о связях записей. Обычно связи записей представляют индексами. Индекс – это служебная запись. В простейшем случае она состоит из двух полей, значения к-ых указывают на связанные рабочие записи пользователя. Эта информация используется для повышения производительности приложений. Структурными единицами БД являются поле, запись и таблица. Поле – элементарная именованная единица логической организации данных, которая соответствует неделимой единице информации – атрибуту (реквизиту). Для описания поля используются следующие обязательные характеристики: имя; тип; длина, определяемая максимально возможным количеством символов; точность для числовых данных. Каждое поле принимает значения из своего домeна – множества допустимых значений. Запись – это именованная совокупность логически связанных полей. Запись понимается как структурный тип данных. Описание записи составляется из еѐ имени и описаний полей. Таблица – это совокупность экземпляров записей одной структуры. Метаданные, как и данные пользователей, сохраняются в таблицах. Их называют иногда системными таблицами. Они составляют часть системного каталога. В них содержатся, в частности, описания полей и типов записей БД пользователя. В подобных таблицах хранятся сведения об отношениях таблиц, индексах, хранимых процедурах, триггерах и других объектах БД пользователя. Индекс – это служебная структура, сопоставленная базовой таблице. Он поддерживает прямой доступ к записям по ключу (первичному, вторичному) и последовательный просмотр записей в порядке возрастания или убывания значений ключа. Основной идеей индекса является хранение упорядоченного списка значений ключа с привязкой к каждому значению списка указателей – физических идентификаторов записей, содержащих это значение. Это избыточные данные, кот. используются для улучшения производительности системы и доступности БД. Индексы бывают уникальными и неуникальными. Уникальные создаются для полей, значения к-ых не могут дублироваться в существующих записях таблицы. Неуникальные могут создаваться для любых других полей, если по их значениям нужно часто сортировать или отфильтровывать записи. |
*. Понятие системы баз данных. Компоненты СБД. Система БД – это человеко-машинная система, предназначенная для поддержания динамической модели ПО и коллективного многоцелевого использования данных. БД и СУБД образуют ядро системы БД (СБД). Помимо БД и СУБД в систему включаются аппаратура, приложения, документация и пользователи. СБД является центральным хранилищем информации предприятия и, в то же время, инструментальным ср-вом поиска и анализа информации для различных пользователей, решающих свои задачи. Она предоставляет доступ к данным одновременно и независимо многим пользователям, создавая для каждого из них иллюзию индивидуальной работы.
Конечные пользователи (КП) – работники предприятия, использующие данные для выполнения служебных обязанностей. Как правило, КП не имеет специальных знаний и навыков в области компьютерных технологий обработки данных. Прикладные программисты – пользователи системы, создающие и сопровождающие программы для конечных пользователей. Они не работают с данными непоср-венно. Их задачи – реализация алгоритмов обработки данных и созд. удобного интерфейса конечного пользователя. Администратор базы данных — группа специалистов, проектирующих, реализующих и сопровождающих систему. АБД несѐт всю ответственность за функционирование и развитие системы. Документация содержит различные инструкции и правила, кот. должны учитываться при проектировании и эксплуатации базы данных. Она обязательно должна включать описания – правил регистрации пользователей в системе; – правил использования отдельных инструментов СУБД или приложений; – процедуры запуска и останова системы; – процедуры создания резервных копий БД; – процедур обработки сбоев аппаратного и программного обеспечения; – процедур реструктурирования и реорганизации БД; – способов улучшения производительности системы; – методов архивирования данных на вторичных устройствах хранения. Документация создаѐтся вместе с системой и поддерживается в актуальном состоянии администратором базы данных. Приложения создаются прикладными программистами для решения конкретных задач конечных пользователей. Приложение состоит из запросов, форм, отчѐтов, меню и прикладных программ. Подсистема проектирования предназначена для создания БД, обеспечения интерфейсов всех категорий пользователей и проектирования приложений. Языки определения данных (ЯОД) предоставляют ср-ва описания элементов и структур данных, экранных форм и других параметров приложений. Языки манипулирования данными (ЯМД) обеспечивают навигацию в БД или формулирование запросов к данным. Языки программирования предназначены для написания прикладных программ, обрабатывающих данные. Обычно коммерческие СУБД имеют ср-ва для работы с несколькими системами программирования. Подсистема обработки занимается обработкой компонентов приложения. Так, при открытии формы процессор форм запрашивает еѐ определение из раздела БД «Метаданные приложений», воспроизводит элементы формы на экране, связывает поля с элементами хранимых данных и отображает в них текущие значения данных. Аналогичные функции выполняют процессор запросов и генератор отчѐтов. Процедурные ср-ва предназначены для обработки запросов прикладных программ на чтение и запись данных. Ядро СУБД – это постоянно загруженная часть системы. Оно обеспечивает интерфейс между БД и двумя другими компонентами СУБД. Например, подсистема обработки принимает запрос приложения на считывание данных. Запрос сформулирован в терминах приложения. Подсистема обработки формулирует его в терминах логических единиц организации данных (например, таблиц) и передаѐт ядру. Ядро преобразует запрос в последовательность команд операционной системы, считывающих данные с физического носителя. Аппаратное обеспечение – это совокупность технических ср-в, обеспечивающих функционирование программ системы. Набор этих ср-в зависит от масштабов СБД и финансовых возможностей еѐ владельца. |
|
14. Функции С УБ Д (8 сервисов Кодда). Требования к функциям и службам, кот. должна поддерживать полномасштабная СУБД сформулированы в 1982 году Э. Коддом и известны как «восемь сервисов Кодда». 1. СУБД должна предоставлять пользователям возможность сохранять, извлекать и обновлять данные в базе данных. Это самая главная функция СУБД. Способ реализации этой функции должен обеспечивать сокрытие от пользователя деталей физической реализации системы. 2. СУБД должна поддерживать доступный пользователям каталог, в котором хранятся описания элементов и структур данных. Системный каталог обеспечивает следующие возможности: Централизованное накопление и сохранение информации о ресурсах данных. Благодаря этому оказывается возможным управление данными как ресурсом организации; Сохранение точных определений смысла элементов и структур данных. Благодаря этому пользователи могут понять их предназначение; Обнаружение избыточности и противоречивости описания отдельных элементов данных; Протоколирование изменений организации базы данных, в частности, схем всех уровней; Определение последствий любых изменений в организации БД ещѐдо их внесения; Организацию поддержки целостности данных; Сохранение сведений о владельцах и пользователях данных и об их привилегиях. Благодаря этому система может обнаруживать и пресекать попытки несанкционированного использования данных. 3. СУБД должна иметь механизм, гарантирующий выполнение либо всех операций транзакции, либо ни одной из них. Эта служба обеспечивает атомарность и (совместно со службами 5 и 8) согласованность транзакции. 4. СУБД должна иметь механизм, гарантирующий корректное обновление базы данных при параллельном выполнении операций обновления многими пользователями. Эта служба обеспечивает изолированность транзакций. 5. СУБД должна предоставлять ср-ва восст-ния БД в случае к-л её повреждения или разрушения. Эта служба обеспечивает долговечность транзакций. 6. СУБД должна иметь механизм, гарантирующий доступ к данным только санкционированных пользователей. Этот механизм обеспечивает безопасность данных, уменьшает возможности их некомпетентного или злонамеренного использования. 7. СУБД должна иметь механизмы взаимодействия с различными коммуникационными программными ср-вами. Современные системы БД реализуются в технологии «клиент-сервер». Приложение, размещѐнное на клиентском узле сети, обращается к серверу БД и получает сообщения от него через сеть, управляемую менеджером обмена данными (МОД). МОД не является частью СУБД, но жизнеспособная СУБД должна быть способна к интеграции с различными МОД. 8. СУБД должна иметь ср-ва контроля данных на соответствие заданным правилам целостности. Эта служба обеспечивает предотвращение ошибок пользователей при обновлении данных, а также поддержание делового регламента организации в рамках известных системе правил. Кроме этих основных служб полномасштабная СУБД должна предоставлять некоторый набор вспомогательных служб (утилит), поддерживающих функции Администратора баз данных. |
||
|
16. Организация процессов обработки данных в системах оперативной обработки транзакций. Обработка транзакций в реальном времени (Online Transaction Processing, сокращенно OLTP), – это способ организации такой БД, которая может максимально быстро отвечать на запросы клиента, при этом обрабатывает большой поток не больших по размеру транзакций. OLTP используют, например, для осуществления банковских и биржевых операций, для регистрации прохождения детали на конвейере, для фиксации в статистике посещений очередного посетителя веб-сайта и т.д. Приложения OLTP, как правило, автоматизируют структурированные, повторяющиеся задачи обработки данных и поэтому они проектируются, настраиваются и оптимизируются для выполнения максимального количества транзакций за короткие промежутки времени. В большинстве случаев, здесь не нужны многофункциональные системы. Чаще всего используется фиксированный набор надѐжных и безопасных методов для ввода, модификации, удаления данных и выпуска оперативной отчѐтности. Показателем эффективности является количество транзакций, выполняемых за секунду. Обычно аналитические возможности OLTP-систем сильно ограничены (либо вообще отсутствуют). В процессе исполнения этих запросов приложений СУБД выполняет четыре разновидности высокоуровневых операций обработки данных. Следует иметь в виду, что каждая из них на уровне реализации представляется последовательностью низкоуровневых операций чтения/записи.
Эти операции изменяют только состояние рабочего буфера СУБД. В физической базе данных новое состояние может быть зафиксировано, только если оно удовлетворяет ограничениям целостности данных. |
20. Организация доступа приложений к данным в СБД. К примеру, есть компания, которая занимается реализацией компьютерной техники. Для систематизации работы в компании, помимо прочего, были созданы отделы: закупок, продаж и склад. Для полноценного функционирования всех отделов необходимо создать приложение, с помощью которого каждый из конечных пользователей сможет вести учет, в соответствии с нормативами и требованиями своего отдела. При этом информация, обрабатываемая работниками, посредством СУБД попадает в общую базу данных предприятия, что очень хорошо можно отследить на рисунке, представленном ниже.
Архитектурная концепция ANSI/SPARC предполагает, что приложения должны получать доступ к сохраненным данным в ФБД только через СУБД. Этот процесс можно показать так:
1. СУБД получает запрос прикладной программы (ПП) в терминах внешней модели. 2. СУБД, используя внешнюю и концептуальную схемы и описание отображения внешний↔концептуальный, определяет, какие записи концептуального уровня необходимы для формирования требуемых внешних записей. 3. СУБД, используя концептуальную и внутреннюю схемы и описание отображения концептуальный↔внутренний, определяет, какие внутренние записи необходимы для формирования затребованных концептуальных записей и совокупность физических записей, которые должны быть для этого считаны с физического носителя. 4. СУБД выдает ОС запрос на считывание в свои буферы необходимых записей физической базы данных (ФБД). 5. ОС считывает затребованные записи и помещает их в системные буферы СУБД. 6. На основании схем и описаний отображений СУБД формирует в своем буфере затребованные внешние записи. 7. СУБД пересылает сформированные внешние записи в рабочую область (РО) ПП. 8. СУБД передает в ПП сообщение о результатах выполнения запроса.
|
|
|
6. Понятие транзакции. Свойства АСИД. Транзакция – это логическая единица работы в базе данных, которая воспринимается системой, как неделимая единица. Транзакция – это последовательность действий над базой данных, выполняемая по запросам одного пользователя или приложения и переводящая БД из согласованного начального состояния в согласованное конечное состояние. Транзакция может завершиться или фиксацией (commit) или откатом (rollback). Если к моменту завершения транзакции удовлетворены все ограничения целостности, то новое состояние БД фиксируется. В противном случае, все обновления данных, произведенные транзакцией, должны быть отменены (откат), и БД должна быть возвращена в исходное состояние. Процедура отмены обновлений называется откатом транзакции. Все операции обновления данных применяются к содержимому рабочего буфера СУБД. Поэтому при фиксации транзакции система должна в дальнейшем воспринимать новое состояние буфера как часть согласованного состояния БД. Откат транзакции – система должна восстановить то состояние буфера, которое существовало на момент начала транзакции. СУБД обязательно должна обеспечивать поддержку свойств ACID. В противном случае она не является системой управления базами данных. Требования ACID: - Атомарность (atomicity) - никакая транзакция не будет зафиксирована в системе частично. Либо выполнены все подоперации, либо не выполнено ни одной. Поскольку на практике невозможно одновременно и атомарно выполнить всю последовательность операций внутри транзакции, вводится понятие «отката» (rollback): если транзакцию не удается полностью завершить, результаты всех произведенных ей действий будут отменены, а система вернется в исходное состояние. - Согласованность (consistency) - система находится в согласованном состоянии до начала транзакции и должна остаться в согласованном состоянии после завершения транзакции. Но свойство согласованности следует понимать шире, чем требование целостности. Например, в банковской системе может существовать требование равенства суммы, списываемой с одного счета, сумме, зачисляемой на другой. Это бизнес-правило и оно не может быть гарантировано только проверками целостности, его должны соблюсти программисты при написании кода транзакций. Если какая-либо транзакция произведет списание, но не произведет зачисление, то система останется в некорректном состоянии и свойство согласованности будет нарушено. Наконец, еще одно замечание касается того, что в ходе выполнения транзакции согласованность не требуется. В нашем примере, списание и зачисление будут, скорее всего, двумя разными подоперациями и между их выполнением внутри транзакции будет видно несогласованное состояние системы. Однако не нужно забывать, что при выполнении требования изоляции, никаким другим транзакциям эта несогласованность не будет видна. А атомарность гарантирует, что транзакция либо будет полностью завершена, либо будет полностью откачена, тем самым эта промежуточная несогласованность является скрытой. - Изоляция (isolation) - во время выполнения транзакции другие процессы не должны видеть данные в промежуточном состоянии. - Долговечность (durability) – в независимости от возникших проблем (например, обесточивание системы или сбои в оборудовании) изменения, после успешно завершенной транзакциии, должны остаться сохраненными после возвращения системы в работу. То есть, если пользователь получил подтверждение, что транзакция выполнена – он может быть уверен, что сделанные им изменения не будут отменены из-за какого-либо сбоя. |
||
|
4. Подходы к ограничению доступа к данным в СБД. В современных условиях оперирование большими объемами информации производится широким кругом лиц. Защита данных от несанкционированного доступа является одной из приоритетных задач при проектировании любой информационной системы. Следствием возросшего в последнее время значения информации стали высокие требования к конфиденциальности данных. Системы управления базами данных, в особенности реляционные СУБД, стали доминирующим инструментом в этой области. Обеспечение информационной безопасности СУБД приобретает решающее значение при выборе конкретного средства обеспечения необходимого уровня безопасности организации в целом. Политика безопасности определяется администратором данных. Однако решения защиты данных не должны быть ограничены только рамками СУБД. Полная защита данных практически не реализуема, поэтому приходится довольствоваться относительной. Разграничение доступа к данным описывается в базе данных посредством ограничений, и информация об этом хранится в ее системном каталоге. Любая система санкционирования доступа к данным базируется на двух основных принципах. 1. Служащий имеет право доступа только к тем сведениям, которые необходимы для исполнения его служебных обязанностей. 2. Служащий имеет право выполнять только те манипуляции доступными данными, которые обусловлены его служебными обязанностями. Авторизация пользователей. В компьютерной системе эти принципы реализуются механизмом авторизации (подсистемой доступа). Подсистема доступа обеспечивает предоставление прав (привилегий) законного доступа к системе и её объектам. Пользователем считается зарегистрированный в системном каталоге идентификатор авторизации (userID), который может быть присвоен лицу, группе лиц или прикладной программе. Привилегия – это право пользователя выполнять определённое действие над определённым объектом БД: запуск приложения, чтение/вставка строки в таблицу и т.п. Ответственность за авторизацию пользователей возлагается на администратора системы. В его обязанности входит создание учётных записей пользователей. В учётной записи указывается: − идентификатор авторизации – имя (логин); − тип пользователя – лицо, группа или прикладная программа; − описание – ФИО, должность лица, наименование группы, имя программы, её назначение и т.п. Учётные записи сохраняются в системном каталоге. В современных СУБД достаточно развиты средства дискреционной защиты. Дискреционное управление доступам (DAC) – разграничение доступа между поименованными субъектами и поименованными объектами. Субъект с определенным правом доступа может передать это право любому другому субъекту. Дискреционная защита является многоуровневой логической защитой. Логическая защита в СУБД представляет собой набор привилегий или ролей по отношению к защищаемому объекту. К логической защите можно отнести и владение таблицей (представлением). Владелец таблицы может изменять (расширять, отнимать, ограничивать доступ) набор привилегий (логическую защиту). Данные о логической защите находятся в системных таблицах базы данных и отделены от защищаемых объектов (от таблиц или представлений). Информация о зарегистрированных пользователях базы данных хранится в ее системном каталоге. Пользователи работают в режиме сеанса. Сеанс – это время между моментом подключения пользователя к системе и моментом его отключения. Подключив пользователя, система готова предоставить ему все свои ресурсы в рамках его привилегий. Кроме того, система записывает в журнале действия пользователя в течение сеанса, а также моменты его подключения и отключения. Представление (внешняя схема, или view) это набор виртуальных записей, реально не существующих в БД. Эти записи создаются в системном буфере, когда пользователь запускает своё приложение. Представления являются гибким средством ограничения доступа к данным. Они отображают для пользователя только ту часть БД, которая необходима ему для работы. Если пользователь имеет единственную привилегию – запуск своего приложения, то его доступ к данным ограничен рамками внешней схемы. Ни о каких данных, кроме тех, которые отображает внешняя схема, он может и не подозревать. Для него это и есть вся БД. |
||
|
13. Назначение модели данных IDEF1X. Компоненты модели. Нотации графического языка IDEF1X. Уровни модели. Этапы моделирования. Стандарт IDEF1X дает следующее определение модели данных: Модель данных – графическое и текстуальное представление, идентифицирующее потребности организации в данных для достижения ее целей, выполнения функций и определения стратегий управления. Модель данных идентифицирует сущности, домены, атрибуты и связи между данными и поддерживает единый концептуальный взгляд на данные и их взаимосвязи. В соответствии с этим определением IDEF1Х как язык описания данных содержит два важнейших компонента: графический – средства создания диаграмм, показывающих структуру и взаимосвязи данных; текстовый – правила создания и ведения текстовых документов, уточняющих и поясняющих графическую модель, – глоссариев, спецификаций, отчетов, заметок и т.п. В IDEF1Х различают три уровня графического представления информации, или три уровня диаграмм. Уровень «сущность-связь» (ER level). Используется на начальной стадии моделирования, когда еще не выяснены или не поняты до конца свойства сущностей и связей. На диаграммах ER-уровня сущности и связи представлены только их именами. Уровень ключей (Key-Based Level, KB). На этом уровне в диаграммах отражаются имена первичных и внешних ключей сущностей и спецификации связей. Диаграмма KB-уровня объявляет уникальные идентификаторы экземпляров сущностей и ограничения ссылочной целостности. Уровень атрибутов (Fully Attributed Level, FA). Диаграмма FA-уровня показывает имена всех атрибутов сущностей и связей и полностью определяет структуру и взаимосвязи данных. Цель моделирования – создание FA-диаграммы. Она является графическим представлением структуры реляционной базы данных с полностью определенными схемами отношений. |
||
|
19. Трехуровневая архитектура СУБД. БД и программные ср-ва их создания и ведения (СУБД) имеют многоуровневое строение. Различают концептуальный, внутренний и внешний уровни представления данных БД, кот. соответствуют одноимѐнные схемы (описания).
Центром архитектуры является концептуальный уровень. Он соответствует логическому представлению данных ПО в обобщѐнном виде без к-л ссылок на реализацию. Концептуальная схема состоит из определений типов концептуальных записей, их связей, ограничений целостности данных, а так же определений других типов объектов БД. В состав концептуальной записи входят только семантически значимые поля. Никаких служебных полей, видимых пользователю, в еѐ структуре нет. На концептуальном уровне представлена также семантическая информация о данных и сведения о мерах по обеспечению безопасности и поддержки целостности данных. Определения концептуального уровня выполняются на ЯОД СУБД и сохраняются в таблицах системного каталога (раздел метаданных БД). Пользователи всех категорий на любом этапе проектирования и эксплуатации системы могут получать сведения о семантике и логической организации данных из этих таблиц. СУБД использует определения при обработке запросов пользователей. Таблицы системного каталога автоматически обновляются СУБД при внесении к-л изменений в концептуальную схему. Т. о., и СУБД, и пользователи всегда располагают актуальной и целостной информацией о семантике и логической структуре хранимых данных. Концептуальный уровень представления данных можно понимать как множество экземпляров концептуальных записей. Эти экземпляры физически не существуют. СУБД воспроизводит их из экземпляров внутренних записей при обработке запросов пользователей. Внутренний уровень описывает организацию данных в среде хранения и соответствует физическому представлению данных. Внутренняя схема состоит из определений типов внутренних (хранимых) записей, файлов внешней памяти, индексов и других компонентов уровня реализации. Эти определения выполняются на входном ЯВУ СУБД. Все семантически значимые поля концептуальных записей представлены на внутреннем уровне. Однако в общем случае между внутренними и концептуальными записями не существует соответствия «один к одному». Различные поля одной и той же внутренней записи могут соответствовать полям нескольких концептуальных записей. И наоборот, различные поля одной и той же концептуальной записи могут соответствовать полям различных внутренних. Могут различаться типы и длины соответственных полей. Внутренние записи кроме семантически значимых и системных полей содержат служебные поля, созданные разработчиками БД для своих целей. Решения о составе и структуре внутренних записей принимают исходя из соображений эффективности обработки запросов. Они могут пересматриваться в процессе эксплуатации системы. Т. о., множество экземпляров внутренних записей и есть БД с «точки зрения» СУБД. Именно их она запрашивает у операционной системы. Внешний уровень поддерживает частные представления данных, необходимые конкретному пользователю. Каждая внешняя схема (подсхема) является частью (подмножеством) концептуальной схемы или выводится из неѐпоср-вом однозначных преобразований. Внешние записи формируются из полей концептуальных записей, но они представляют только те сущности, атрибуты и связи ПО, кот. представляют интерес для конкретного КП. Этот КП может даже не подозревать о том, что в БД есть и другие сведения. Различные внешние схемы могут по-разному отображать одни и те же данные. Внешние записи могут включать вычислимые и производные поля, не хранящиеся в БД как таковые. Поля различных концептуальных записей могут отображаться в одной внешней. Структуру и состав внешних записей проектируют исходя из требований конечного пользователя. Кроме внешних схем на этом уровне представлены определения форм, отчѐтов, запросов и другие компоненты приложений. С помощью внешних схем поддерживается интерфейс конечного пользователя и санкционированный доступ к данным и приложениям.
Уровни
представления данных связаны
однозначными отображениями. Отображения определяют соответствия между представлениями верхнего и нижнего уровней. Отображение концептуальный ↔внутренний ставит в соответствие концептуальным полям и записям хранимые. Это соответствие является взаимно однозначным. При изменении структур хранения отображение концептуальный ↔внутренний изменяется так, чтобы концептуальная схема осталась неизменной. Аналогично отображение внешний ↔концептуальный ставит в соответствие концептуальным полям и записям внешние. |
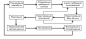
18. Жизненный цикл системы с базами данных. Фазы проектирования БД. Жизненный цикл СБД является непрерывным процессом от решения о создании СБД до полного изъятия ее из эксплуатации. ЖЦ состоит из этапов, представленных на рисунке ниже.
На этом рисунке представлен перечень работ, которые выполняются в процессе ЖЦ СБД. При этом в идеальных условиях результаты очередного этапа являются исходными данными для следующего. Однако на каждом из этапов могут возникнуть проблемы, которые потребуют пересмотра решений, принятых на любом из предшествующих.
Фазы проектирования БД Процесс создания внешней и концептуальной схем называют моделированием данных организации. Цель моделирования – понять, ЧТО нужно сделать. Концептуальное моделирование не связано ни с какими соображениями реализации. Процесс создания внутренней схемы называют физическим проектированием БД. Его цель – решить, КАК сделать то, что нужно. Концептуальное моделирование – это процесс анализа информационных потребностей конечных пользователей системы. На этой фазе цель аналитика – сформировать в своей голове представления об информационных потребностях бизнеса, адекватные представлениям предполагаемых конечных пользователей системы. Эти представления формируются в процессе изучения деятельности организации. Концептуальная модель служит источником информации для фазы логического моделирования. Логическое моделирование. В процессе логического моделирования концептуальная модель уточняется и преобразуется в логическую с учетом базовой модели данных целевой СУБД. Например, если целевая СУБД базируется на РМД, то структуры и связи объектов, представленные в концептуальной модели, преобразуются в систему взаимосвязанных отношений, удовлетворяющих определенным формальным требованиям. К началу логического моделирования должен быть определен тип целевой СУБД (реляционная, сетевая, объектно-ориентированная). Однако все прочие аспекты целевой СУБД (физическая организация структур хранения, способы построения индексов и т.п.) полностью игнорируются. Логическая модель содержит описания структур данных в терминах выбранной модели данных, а также описания ограничений целостности. Она должна – быть корректной, – соответствовать требованиям пользователей, зафиксированным в концептуальной модели, – обеспечивать поддержку всех необходимых пользователям транзакций. Логическая модель является источником информации для фазы физического проектирования БД и для проектирования приложений. Физическое проектирование. На этой фазе принимаются решения о способах реализации БД. Она может начаться только после выбора конкретной целевой СУБД. Целью физического проектирования является описание способа физической реализации логической модели. Например, если используется реляционная СУБД, то в ее среде должен быть создан набор таблиц и ограничений, представленный в логической модели. Должны быть определены конкретные структуры хранения данных (файлы) и методы доступа к данным, обеспечивающие требуемую производительность системы. Кроме того, должны быть разработаны средства защиты системы. В идеале фазы логического моделирования и физического проектирования следует разделять, однако реально это невозможно, поскольку решения, принимаемые на фазе физического проектирования с целью повышения производительности системы, могут повлиять на структуру логической модели. |
2. Понятие функциональной зависимости атрибутов. Нормальные формы отношений. Процедура нормализации.---Цель нормализации – преобразовать универсальное отношение в систему отношений, удовлетворяющих определенным формальным требованиям. При обновлении данных, хранящихся в такой системе отношений, не возникают аномальные ситуации, и РСУБД в состоянии поддерживать целостность данных. Нормализация основана на понятии функциональной зависимости атрибутов отношения.---Определение 1. Пусть R некоторое отношение, А, В – подмножества его атрибутов. Говорят, что А функционально определяет В (или В функционально зависит от А), если и только если для любого допустимого значения R каждому значению А соответствует точно одно значение В. Функциональную зависимость (ФЗ) принято обозначать А В. (Пример: ТабФамилия) Т.е, если А В, то для любого допустимого значения R два кортежа, совпадающие по значению А, совпадают также и по значению В. Обратное неверно. Подмножество А называют детерминантом зависимости, подмножество В – зависимой частью.---Определение 3. Пусть A и B – подмножества атрибутов и A – детерминант B. Говорят, что ФЗ A B неприводима, если не существует такого подмножества C A, что C B. (Пример: № поставки, № деталикол-во)---Говорят, что отношение находится в 1НФ, если и только если все домены его атрибутов содержат скалярные значения (простые типы данных – логический, строковый, численный)(универсальные отношения - возможно избыточное дублирование данных и аномалии вставки, обновления и удаления). Любое отношение автоматически уже находится в 1НФ.---Говорят, что отношение находится в 2НФ, если и только если каждый его неключевой атрибут неприводимо зависит от первичного ключа (те же проблемы).---Опр2. Атрибуты называются взаимно независимыми, если ни один из них не является функционально зависимым от другого. (Пример: вес и кол-во деталей)---Отношение R находится в 3НФ тогда и только тогда, когда отношение находится в 2НФ и все неключевые атрибуты взаимно независимы.---или Опр 3. Пусть R – некоторое отношение, А, В, С – подмножества его атрибутов. Если А В, В С, то А С. В таком случае говорят, что существует транзитивная функциональная зависимость.---Говорят, что отношение находится в 3НФ, если и только если оно находится в 2НФ и нет транзитивных зависимостей.---Для того, чтобы устранить зависимость неключевых атрибутов, нужно произвести декомпозицию отношения на несколько отношений. При этом те неключевые атрибуты, которые являются зависимыми, выносятся в отдельное отношение.---Алгоритм нормализации:---Шаг 1 (Приведение к 1НФ). На первом шаге задается одно или несколько отношений, отображающих понятия предметной области. По модели предметной области (не по внешнему виду полученных отношений!) выписываются обнаруженные функциональные зависимости. Все отношения автоматически находятся в 1НФ.---Шаг 2 (Приведение к 2НФ). Если в некоторых отношениях обнаружена зависимость атрибутов от части сложного ключа, то проводим декомпозицию этих отношений на несколько отношений следующим образом: те атрибуты, которые зависят от части сложного ключа выносятся в отдельное отношение вместе с этой частью ключа. В исходном отношении остаются все ключевые атрибуты.---Шаг 3 (Приведение к 3НФ). Если в некоторых отношениях обнаружена зависимость некоторых неключевых атрибутов от других неключевых атрибутов, то проводим декомпозицию этих отношений следующим образом: те неключевые атрибуты, которые зависят от других неключевых атрибутов выносятся в отдельное отношение. В новом отношении ключом становится детерминант функциональной зависимости. |
|
15. Назначение и составные части реляционной модели данных (РМД). Внутренние ограничения целостности РМД. Механизмы поддержания целостности реляционной базы данных.---Основы РМД были впервые изложены в статье Е.Кодда в 1970 г. Наиболее распространенная трактовка РМД принадлежит К.Дейту: РМД состоит из трех частей: структурной, целостной, манипуляционной. Структурная часть описывает, какие объекты рассматриваются РМД. Постулируется, что единственной структурой данных, используемой в реляционной модели, являются нормализованные n-арные отношения.---Целостная часть описывает ограничения специального вида, которые должны выполняться для любых отношений в любых РБД.---Манипуляционная часть описывает два эквивалентных способа манипулирования реляционными данными - реляционную алгебру и реляционное исчисление.---Текущее состояние БД является целостным, если возможна осмысленная интерпретация его в терминах ПО. Три разновидности внутренних ОЦ: 1) целостность домена - всякий атрибут может принимать значения только из своего домена (предотвращает грубые ошибки пользователя). Это означает, что в любой РБД для каждого атрибута должно существовать правило, определяющее допустимость значений. Правило целостности домена – это метаправило, правило о правилах.---2) целостность сущности - атрибуты, входящие в состав некоторого потенциального ключа не могут принимать null-значений (идентификация информации). Потенциальный ключ отношения - это набор атрибутов отношения, обладающий свойствами уникальности и неизбыточности.---3) ссылочная целостность - ни в какой момент времени в БД не может быть определенных (не Null-) значений ссылающегося ключа, которых нет среди существующих значений родительского ключа.---Таблица. Возможные нарушения ограничений целостности при операциях обновления.--- Операции
удаления или обновления значений
родительских ключей затрагивают, как
минимум, два отношения. СУБД сможет
поддерживать ссылочную целостность
при выполнении этих операций, если
для каждого ссылающегося отношения
определены правила изменения значений
внешних ключей при изменении значений
соответствующих родительских ключей.
Две
основные
стратегии
– ОТЛОЖИТЬ и КАСКАДИРОВАТЬ – обычно
поддерживаются стандартными процедурами
РСУБД. Все специфические правила
внешних ключей должны быть определены
проектировщиком и реализованы в виде
хранимых
процедур (контроль целостности домена,
сущности и ссылочной целостности).---*Отложить
-
удаление/обновление
ссылочного ключа до тех пор, пока в БД
не останется ни одного ссылающегося
на него значения внешнего
ключа.---*Каскадировать
-
разрешить выполнение требуемой
операции, но внести каскадные изменения
в другие отношения так, чтобы не
допустить нарушения ссылочной
целостности. |
||
|
7. Проблема синхронизации транзакций. Двухфазный протокол синхронизационных блокировок. СУБД одновременно контролирует сеансы и обрабатывает транзакции многих пользователей. Операции различных транзакций чередуются, за счёт чего достигается их параллельное исполнение. Это способствует повышению общей производительности. Однако при чередовании операций различных транзакций результаты параллельно выполняемых обновлений данных могут оказаться несогласованными, несмотря на то, что каждая транзакция выполнялась вполне корректно. Рассмотрим типичные ситуации, которые могу возникать при параллельном исполнении транзакций: - Потеря обновлений - если две транзакции пытаются параллельно обновлять один и тот же объект. - Чтение «грязных» данных - если транзакция имеет доступ к промежуточным результатам другой транзакции. - Несогласованная обработка - в двух предыдущих примерах речь шла о параллельном исполнении транзакций, изменяющих состояние БД. Однако проблемы возникают и в том случае, если одна из двух параллельно исполняемых транзакций обновляет состояние БД, а другая только извлекает данные, и выполняет какие-либо преобразования. Из сказанного следует, что транзакции являются не только единицами работы в БД, но и единицами управления. СУБД должна обеспечить такой режим обработки транзакций, при котором результат их параллельного исполнения совпадал бы с результатом последовательного исполнения в каком-либо порядке. В этом случае транзакции будут изолированы, т.е., никакая из них не будет влиять на результаты других. Двухфазный протокол блокировки Идея подхода – перед выполнением какой-либо операции над объектом А, транзакция Т должна запросить блокировку (захват) А. В зависимости от вида предполагаемой операции объект может быть заблокирован в одном из двух режимов: - S (Shared lock) – разделяемый захват, необходимый для выполнения операции чтения; - X (eXclusive lock) – монопольный захват, необходимый для выполнения операций добавления/удаления/модификации.
Если
объект захвачен некоторой транзакцией
в режиме S,
то его может захватить в этом же режиме
любая другая транзакция, однако захват
в режиме X
невозможен.
Объект, захваченный в режиме X,
не может быть захвачен другой транзакцией
ни в каком режиме. Транзакция, запросившая блокировку объекта, заблокированного другой транзакцией в несовместимом режиме, ожидает до тех пор, пока блокировка с этого объекта не будет снята. Транзакции, конфликтующие по доступу, запрашивают несовместимые блокировки. Поскольку конфликта по чтению не существует, S-захваты совместимы. Сформулируем теперь протокол доступа к данным: Перед операцией извлечения объекта транзакция должна заблокировать его в S-режиме. Перед операцией обновления объекта транзакция должна заблокировать его в X-режиме. Если она уже заблокировала его в S-режиме, то эта блокировка должна быть заменена X-блокировкой. Если запрашиваемая транзакцией Т1 блокировка отвергается из-за несовместимости с блокировкой, наложенной на объект транзакцией Т2, то Т1 переходит в состояние ожидания. Она находится в этом состоянии до тех пор, пока наложенная транзакцией Т2 блокировка не будет снята. Все наложенные транзакцией блокировки сохраняются вплоть до завершения транзакции оператором COMMIT или ROLLBACK. Нетрудно заметить, что протокол допускает возникновение тупиковых ситуаций (взаимных блокировок), когда две транзакции могут сколь угодно долго ждать завершения друг друга. Протокол предусматривает две фазы выполнения транзакции: фазу наложения блокировок и фазу снятия блокировок. В первой происходит накопление захватов, во второй – освобождение всех захваченных объектов. Транзакция не может запросить ни одной блокировки после того, как она сняла хотя бы одну наложенную ранее. Если все транзакции соблюдают двухфазный протокол блокировки, то коллизии потерянных изменений, «грязных» чтений и несогласованной обработки невозможны. |
11. Операции реляционной алгебры. Синтаксис выражений.---РА относится к манипуляционной части РМД. РА представляет собой набор операторов, использующих отношения в качестве аргументов, и возвращающие отношения в качестве результата.---Определяют восемь реляционных операторов, объединенных в две группы.---Теоретико-множественные операторы: объединение, пересечение, вычитание, декартово произведение.---Специальные реляционные операторы: выборка, проекция, соединение, деление.---Опр 1. Будем называть отношения совместимыми по типу, если они имеют одно и то же множество имен атрибутов и атрибуты с одинаковыми именами определены на одних и тех же доменах.---Правило: Никакие реляционные операторы не передают результатирующему отношению никаких данных о потенциальных ключах.---Оператор переименования атрибутов – Rename – можно получить совместимое множество.---Объединением двух совместимых по типу отношений A и B называется отношение с тем же заголовком, что и у отношений A и B, и телом, состоящим из кортежей, принадлежащих или A, или B, или обоим отношениям.---A UNION B---Пересечением двух совместимых по типу отношений A и B называется отношение с тем же заголовком, что и у отношений A и B, и телом, состоящим из кортежей, принадлежащих одновременно обоим отношениям A и B.---A INTERSECT B---Вычитанием двух совместимых по типу отношений A и B называется отношение с тем же заголовком, что и у отношений A и B, и телом, состоящим из кортежей, принадлежащих отношению A и не принадлежащих отношению B.---A MINUS B---Декартовым произведением двух отношений A(A1,A2…An) и B(B1,B2…Bn) называется отношение, заголовок которого является сцеплением заголовков отношений A и B: (A1,A2…An, B1,B2…Bn), а тело состоит из кортежей, являющихся сцеплением кортежей отношений A и B: (a1,a2…an, b1,b2…bn) ---A TIMES B---Замечания. Мощность произведения равна произведению мощностей отношений, атрибуты с одинаковыми наименованиями перед выполнением необходимо переименовать, совместимость по типу не требуется.---Выборкой (ограничением, селекцией) на отношении А с условием r называется отношение с тем же заголовком, что и у отношения A, и телом, состоящем из кортежей, значения атрибутов которых при подстановке в условие r дают значение ИСТИНА. A WHERE r---Проекцией отношения A по атрибутам X, Y…Z, где каждый из атрибутов принадлежит отношению A, называется отношение с заголовком (X, Y…Z) и телом, содержащим множество кортежей вида (x, y…z). ---A[X,Y…Z]---Соединением отношений A и B по условию r называется отношение (A TIMES B) WHERE r, в котором r представляет собой логическое выражение, в которое могут входить атрибуты отношений A и B и (или) скалярные выражения. Пусть даны отношения A(A1…An,X1…Xp) и B(X1…Xp, B1…Bm), имеющие одинаковые атрибуты X1…Xp (т.е. атрибуты с одинаковыми именами и определенные на одинаковых доменах).---Тогда естественным соединением отношений A и B называется отношение с заголовком (A1…An,X1…Xp,B1…Bm) и телом, содержащим множество кортежей (a1…an,x1…xp,b1…bm).---A JOIN B---Пусть даны отношения A(X1…Xn,Y1…Ym) и B(Y1…Ym), причем атрибуты Y1…Ym - общие для двух отношений. Делением отношений A на B называется отношение с заголовком (X1…Xn) и телом, содержащим множество кортежей (x1…xn), таких, что для всех кортежей (y1…ym)B в отношении A найдется кортеж (x1…xn, y1…ym).---A DEVIDEBY B. Замечание. Типичные запросы, реализуемые с помощью операции деления, обычно в своей формулировке имеют слово "все" - "какие поставщики поставляют все детали?" |
|
|
12. Операторы обновления данных в SQL. Операторы обновления данных всегда используют в качестве приемника данных одну именованную таблицу – базовую или представление. Если приемником является представление, то оно должно быть обновляемым. Обновляются только базовые таблицы. Порядок исполнения операторов обновления следующий. Приняв оператор, система считывает из ФБД в свой рабочий буфер обновляемую базовую таблицу. Все изменения данных выполняются в этой копии. Обновленная таблица переносится из рабочего буфера в ФБД, только если транзакция, содержащая оператор обновления, завершилась успешно. В противном случае рабочий буфер очищается, и никаких изменений в ФБД не происходит. Действие операторов ограничено не только привилегиями пользователя, но и правилами целостности данных, объявленными в определениях объектов схемы. Исполняющая система автоматически проверяет все ограничения, которые могут быть нарушены вследствие предложенных изменений данных. Если хотя бы одно из них нарушается, операция обновления будет отвергнута. Если правилами целостности в связи с предложенными изменениями предусмотрены каскадные обновления других объектов, они выполняются автоматически. Порядок выполнения этих не заданных явно обновлений такой же. INSERT INTO имя_таблицы [(имя_столбца.,..)] запрос | конструктор_значений_таблицы | {DEFAULT VALUES}; Оператор INSERT в общем случае добавляет в указанную таблицу группу строк. Группа может быть либо результатом запроса, либо явно заданным списком строк – конструктором значений таблицы. Результат запроса или строки конструктора могут содержать значения части столбцов обновляемой таблицы. В этом случае имена этих столбцов должны быть указаны списком имен столбцов. Здесь имя_столбца – имя столбца обновляемой таблицы. Список имен можно не указывать, если добавляемые строки содержат значения для всех столбцов таблицы. Столбцам, не вошедшим в список, в новых строках будут присвоены значения по умолчанию, если они определены, либо NULL-значения. Если для какого-либо столбца это невозможно (например, столбец определен как NOT NULL, а значение по умолчанию не задано), операция будет прервана. Запрос – любой оператор SELECT, производящий таблицу с числом столбцов, равным числу имен в списке или (если он не задан) числу столбцов приемника данных. Столбцы производной таблицы запроса должны совпадать по типу с соответствующими по порядку следования столбцами из списка имен или из схемы обновляемой таблицы. конструктор_значений_таблицы ::= VALUES конструктор_значений_строки.,.. конструктор_значений_строки ::= элемент_конструктора | (элемент_конструктора.,..) | подзапрос_строки элемент_конструктора ::= выражение_для_вычисления_значения | NULL | DEFAULT Оператор UPDATE изменяет значения одного или нескольких столбцов в подмножестве строк базовой таблицы. Вот его синтаксическая диаграмма: UPDATE имя_таблицы SET {имя_столбца=выражение_для_вычисления_значения | NULL | DEFAULT }.,.. [WHERE предикат]; Здесь выражение может содержать литералы, имена переменных, ссылки на любые столбцы обновляемой таблицы, скалярные подзапросы. Тип выражения должен соответствовать типу обновляемого столбца. В качестве альтернативы выражению можно явно указывать значение NULL или «значение по умолчанию» DEFAULT, заданное при определении столбца. Если оператор не содержит предложения WHERE, то указанные в предложении SET значения присваиваются столбцам во всех строках таблицы. Предложение WHERE ограничивает действие оператора подмножеством строк, на которых предикат принимает значение TRUE. Оператор DELETE удаляет подмножество строк из базовой таблицы. DELETE FROM имя_таблицы [WHERE предикат]; Предложение WHERE определяет подмножество удаляемых строк. Если оно отсутствует, то удаляются все строки таблицы. Определение таблицы в схеме сохраняется, то есть в базе данных остается пустая таблица. |