

Базы Данных - Сибилев, 2007
.pdf21
Во втором варианте состав и форматы записей файлов согласовыва-
лись внутри рабочей группы. Создавалось общее для всех программ отдела поле данных. Каждая программа обрабатывала определённую часть общих данных. При такой организации удаётся избежать неуправляемого дубли-
рования данных, но возникают другие проблемы. В частности, проблемы управления параллельным доступом программ к данным и разграничения полномочий доступа.
Заметим, что в обоих вариантах
— каждая программа содержит в своём теле определения всех необ-
ходимых ей файлов;
—каждая программа самостоятельно сканирует файлы, для того чтобы извлечь нужные записи;
—каждая программа использует методы доступа конкретной опера-
ционной системы.
2.2 Недостатки ФСОД
Уже первые опыты эксплуатации ФСОД показали неэффективность такой организации обработки данных предприятия. То, что получалось,
было плохо как с точки зрения программистов, так и (что важнее!) с точки зрения пользователей. Перечислим основные недостатки ФСОД.
2.2.1 Неконтролируемая избыточность данных.
Главный недостаток ФСОД с точки зрения пользователя — возмож-
ная противоречивость результатов работы различных программ. Она обу-
словлена тем, что каждая программа (подразделение) использует свой соб-
ственный набор файлов. Информационные интересы пользователей раз-
личных программ пересекаются. Поэтому различные, независимо обраба-
тываемые файлы должны содержать дубликаты общих данных.
ФСОД не имеет средств контроля идентичности дубликатов, а люди,
вводящие в файлы значения данных, не могут работать безошибочно. И с этим ничего не поделаешь. Поэтому "дубликаты" нередко оказывались не-
22
идентичными. Это могло привести (и приводило!) к дезинформации поль-
зователей и к неверным управленческим решениям.
Принципиальное решение этой проблемы — "обобществление" дан-
ных предприятия, создание единого хранилища данных для всех подразде-
лений. Тогда можно использовать схему "программы вокруг данных" (см.
рис. 2.3) в масштабах предприятия. Она избавляет от необходимости хра-
нения дубликатов данных.
2.2.2 Зависимость программ от данных.
Каждая прикладная программа ФСОД содержит описания всех ис-
пользуемых файлов. Если потребуется изменить структуру записи какого-
то файла, то придётся перекомпилировать и заново отладить все обраба-
тывающие его программы. Изменять структуры файлов приходилось до-
вольно часто. Например, для увеличения скорости обработки данных или в связи с изменениями требований пользователей.
По той же причине придётся заново отлаживать все программы ФСОД и при обновлении программно-технической платформы системы.
В шестидесятые-семидесятые годы компьютерная техника и обслу-
живающие программы совершенствовались особенно стремительно. Руко-
водство предприятия, имеющего компьютерную СОД, требовало от руко-
водства ООД совершенствования системы. Поэтому большая часть при-
кладных программ ФСОД постоянно находилась в состоянии отладки.
2.2.3 Разделение и изоляция данных.
Обычно каждый файл ФСОД содержит записи о каких-то объектах или фактах одного типа: ТОВАРах, ПРОДАЖАх, ПОСТАВЩИКах,
ПОСТАВКАх и т.п. В реальной жизни предприятия объекты деятельности связаны какими-то отношениями. Эти отношения представлены в системе обработки данных какими-то связями записей. Так, конкретная запись о
ПРОДАЖАх регистрирует факт продажи конкретного ТОВАРа (когда,
сколько, по какой цене и т.п.). Значит, каждая запись файла ПРОДАЖА
должна быть связана с какой-то одной конкретной записью файла ТОВАР,
23
содержащей сведения о проданном товаре. Аналогично, каждая запись файла ПОСТАВКА должна быть связана с какой-то записью файла ТОВАР
и какой-то записью файла ПОСТАВЩИК.
О связях записей различных файлов знают только прикладные про-
граммы ФСОД, выполняющие их совместную обработку. Так, о связях за-
писей файлов ТОВАР и ПРОДАЖА знает программа, которая готовит отчёт о продажах. Чтобы подготовить такой отчёт, она должна выполнить син-
хронную обработку записей этих файлов.
О связях записей файлов ТОВАР, ПОСТАВКА и ПОСТАВЩИК зна-
ет программа подготовки отчётов о поставках, поскольку она должна вы-
полнять синхронную обработку этих файлов.
В общем случае любая программа ФСОД, извлекающая информацию из нескольких разнотипных записей, должна выполнять синхронную обра-
ботку соответствующих файлов. Программист — автор программы, дол-
жен написать и отладить код синхронной обработки. Синхронная обработ-
ка файлов — типовое действие. Конкретные особенности реализации скрываются в параметрах синхронизации, т.е., в связях записей. В принци-
пе можно реализовать алгоритм синхронной обработки как некую стан-
дартную функцию. Однако эта функция должна получать откуда-то сведе-
ния о структурах записей обрабатываемых файлов. ФСОД не имеет служ-
бы, которая могла бы предоставить эти сведения.
2.2.4 Большое количество автономных программ в системе.
Каждая программа ФСОД создаётся для поддержки какой-то одной функции или нескольких связанных функций. Например, для создания и печати платёжной ведомости (функция бухгалтера расчётной группы), или для регистрации продажи товаров и печати чеков и кассового отчёта
(группа функций продавца). Многие программы ФСОД создаются для по-
лучения справочной информации определённого типа. Обобщая, можно сказать, что все эти программы обрабатывают предопределённые запросы к
данным. Если у пользователей системы появляются новые запросы, для их
24
обработки приходится писать новые программы или (что ничуть не проще)
модифицировать существующие. В конце концов (и довольно быстро) вся эта куча автономных программ становится совершенно неуправляемой.
2.3 Чем обусловлены недостатки ФСОД
Перечисленные недостатки ФСОД обусловлены следующими факто-
рами.
1. Данные, с которыми работает подразделение, рассматриваются как его внутренний ресурс. Считается, что каждое подразделение самостоя-
тельно накапливает, хранит и обрабатывает всё необходимое. Такой под-
ход к организации накопления и обработки данных приводит к избыточно-
сти данных. Опасным следствием избыточности является возможность по-
явления противоречий в полной совокупности хранимых данных. ФСОД не имели никаких средств контроля согласованности данных различных подразделений. Опыт эксплуатации ФСОД показал, что в системе должна быть какая-то постоянно загруженная программа, которая будет перехва-
тывать любую попытку обновления любого файла, и проверять допусти-
мость обновления. Очевидно, эта программа должна "знать" определения всех файлов и иметь к ним доступ. Реализовать такую программу в рамках используемого подхода невозможно.
2. Программы ФСОД реализуются и исполняются как автономные функциональные единицы. Они получают доступ к данным, используя ме-
тоды доступа конкретной ОС. Определения файлов хранятся в телах про-
грамм и неизбежно дублируются в различных программах. Кроме того,
программы содержат ссылки на конкретные устройства ввода/вывода. По-
этому любое изменение структур файлов, обновление ОС или внешних устройств приводит к необходимости изменения и перекомпиляции про-
грамм.
К середине 60-х годов прошлого века сообщество программистов,
работающих в области автоматизации обработки данных, уже ясно пони-
мало проблемы ФСОД и их причины. Уже возникла и даже была реализо-
25
вана идея управления данными. Она была окончательно сформулирована и описана детально во второй половине 60-х годов в докладе рабочей группы по базам данных, созданной Американским национальным институтом стандартизации (ANSI). Она и лежит в основе современной технологии баз данных.

26
3 Организация систем с базами данных
3.1 Концепция системы с базами данных (СБД)
Обобщение опыта создания и эксплуатации ФСОД приводит к кон-
цепции организации обработки данных, которую сейчас можно назвать концепцией систем с базами данных (СБД). Рассмотрим основные положе-
ния этой концепции.
Положение 1. Вся совокупность данных предприятия должна рас-
сматриваться как единый информационный ресурс. Управление этим ре-
сурсом должно быть централизованным.
Ранние СОД буквально воспроизводили средствами вычислительной техники те способы и методики, которые использовались при ручной об-
работке данных. В "докомпьютерную" эпоху первичные источники дан-
ных: счета, договоры, заявления об увольнении, табели и другие докумен-
ты поступали в соответствующие отделы администрации предприятия.
Здесь из них извлекались и переносились в журналы, картотеки, хозяйст-
венные книги и т.п., важные для предприятия данные. Тем самым создава-
лись записи, необходимые для оперативной работы подразделений. Сами первичные источники могли сохраняться в шкафах и папках отдела или возвращаться туда, откуда поступили, в соответствии с принятыми прави-
лами документооборота. Таким образом, все данные предприятия сущест-
вовали, как минимум, в двух экземплярах: в исходных документах и в за-
писях отделов — картотеках, регистрационных книгах и т.п. Сотрудники отделов использовали эти записи для выполнения своих служебных функ-
ций. Каждый отдел работал со своим набором записей.
Такая организация обработки данных предполагает информационную изолированность подразделений. Однако все отделы — подразделения од-
ного предприятия. Ни один из них не может выполнять свои функции, не взаимодействуя с другими. Поэтому их информационные потребности пе-
ресекаются. Наборы записей различных отделов содержат, возможно, в
27
различных формах, одни и те же данные. Идентичность этих копий не га-
рантируется. Её можно обеспечить лишь при централизованном управле-
нии данными предприятия.
Централизованно управляемое хранилище данных предполагает их централизованное накопление и хранение, и контролируемый доступ к данным для работников отделов. Очевидно, это идеальный способ органи-
зации обработки данных предприятия, но, если данные накапливаются и хранятся на бумажных носителях, это немыслимо. Из такого хранилища невозможно своевременно получить информацию, необходимую для при-
нятия оперативных решений.
Концепция информационной изолированности подразделений для ор-
ганизации ручной обработки данных вполне оправданна. Она обеспечивает следующее.
— Оперативность доступа к данным и приемлемую скорость их об-
работки. Все необходимые данные всегда находятся в помещении отдела,
как правило, под рукой того сотрудника, которому они нужны чаще всего.
— Разграничение полномочий доступа к данным. Пользоваться запи-
сями отдела без ограничений могут только его сотрудники, а обновлять конкретную картотеку, журнал и т.п. — только определённый начальством сотрудник.
— Определение зон ответственности подразделений за достовер-
ность информации. Ответственность за ошибки в записях отдела несёт его руководитель, а уж он-то взыщет с виновного сотрудника.
Но, создавая компьютерную СОД, не следует копировать способы организации ручной обработки данных. Возможности компьютерной сис-
темы в части управления данными просто не сравнимы с возможностями человека.
Для эффективной компьютерной обработки данные организации могут и должны рассматриваться как единый централизованно управляе-
мый информационный ресурс. Только так можно избежать неконтроли-

28
руемой избыточности данных и гарантировать их непротиворечивость.
Каждое подразделение вносит в этот ресурс свой вклад и получает из это-
го ресурса то, что ему необходимо для выполнения его функций.
Технически это означает, в частности, что должны быть определены структуры данных, единые для всех прикладных программ. Эти структуры должны, во-первых, обеспечивать накопление всех необходимых данных,
и, во-вторых, исключать неконтролируемую избыточность. В большом и сложно организованном хранилище данных избыточность неизбежна. Хотя бы для того, чтобы сохранять информацию о связях различных записей и обеспечить возможность быстрого поиска данных (индексы, картотеки и т.п.). Компьютерное хранилище может скрыть эту избыточность от поль-
зователя и полностью управлять ею.
Заметим, что создание единых структур данных устранит неконтро-
лируемую избыточность, но не снимет других проблем, в частности, про-
блемы зависимости программ от данных. Ведь в тело каждой программы придётся включать определения всех требующихся файлов. Каждая про-
грамма будет по-прежнему использовать методы доступа конкретной ОС и содержать ссылки на конкретные физические устройства.
Положение 2. Детали организации данных во внешней памяти и методов доступа к данным должны быть скрыты от прикладных про-
грамм.
В ФСОД обработка данных организована по схеме, приведённой на рис. 3.1. Между хранимыми данными и программами размещена операци-
онная система. К ней обращаются программы с запросами на доступ к фай-
лам. От неё они получают физические записи и в своих рабочих буферах преобразуют их в некоторые логические единицы данных. Эти логические единицы соответствуют объектам реального мира и определяются исклю-
чительно информационными потребностями пользователя. Они не зависят
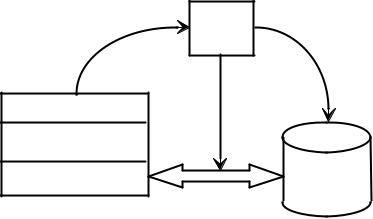
29
от того, в каких физических структурах и на каких устройствах хранятся
данные, и какая ОС обеспечивает к ним доступ.
ОС
Запросы файлов Команды
чтения/записи
Программа ФСОД
Определения
файлов
Рабочий буфер |
Файлы |
|
Физические
страницы
Рис. 3.1 Схема обработки данных в файловой системе
Проблема адаптации программ обработки данных к изменениям физических структур хранения данных и среды функционирования была бы снята, если бы программы получали доступ не к файлам, а к логиче-
ским структурам данных, которые нужно обработать. Это можно обес-
печить, если поставить между программами обработки данных и опера-
ционной системой некую программу (сервер), которая по запросам при-
кладной программы (клиента) выполняет типовые операции обработки данных и предоставляет ей не файлы, а именно обработанные логические записи. Сервер должен вести все физические файлы и выполнять по за-
просам клиентов типовые операции обработки данных. Разумеется, и
программы-клиенты, и сервер должны располагать описаниями логиче-
ских структур. Сервер, кроме того, должен знать, как отображаются логи-
ческие структуры данных на физические и обратно.
В этом случае программы обработки данных не будут содержать никаких ссылок физического уровня. Никакие изменения программно-
технической платформы системы не потребуют переработки программ-
клиентов. Правда, они могут потребовать каких-то изменений в сервере.
Идея сервера данных приводит к схеме обработки данных, изображён-
ной на рис 3.2.

30
Прикладным программам, работающим по этой схеме, не нужны
описания физических структур данных. Достаточно того, что они известны серверу. Но описания логических структур данных необходимы приклад-
ным программам.
Рис. 3.2 Организация обработки данных в СБД
Возникает вопрос: где должны храниться описания логических структур?
Если они будут включаться в тела прикладных программ и сервера,
то мы окажемся в той ситуации, от которой стремимся уйти. Правда, на более высоком уровне.
Положение 3. Описания структур данных должны сохраняться от-
дельно от программ обработки данных.
А почему бы не сохранять описания данных там же, где хранятся са-
ми данные, т.е. во внешней памяти? Структуры и элементы данных имеют имена и обладают вполне определёнными наборами свойств. Например,
предположим, что сведения о товарах, поставщиках, поставках и т.п. хра-
нятся в плоских таблицах, наподобие следующей:
ТОВАР(штрих-код, наименование, ед.измерения, цена,…).
Описание такой структуры состоит из её имени и сопоставленного ему перечня имён полей с указанием их типов, длин и т.п. свойств. Множе-
ство возможных свойств конечно.