

Engineering and Manufacturing for Biotechnology - Marcel Hofman & Philippe Thonart
.pdfRalph Berkholz and Reinhard Guthke
1.3. RESTRICTED VALIDITY OF BIOPROCESS MODELS
Bioprocess models used for experimental design procedures apply the concept of rate limiting reaction steps. A rate limiting step is determined by the actual and passed physiological states (i.e. biological memory). In general bioprocess models are not valid for all physiological states. Their validity is a restricted or local one. The bioprocess has to be studied and modelled for the relevant physiological state (or for a certain sequence of physiological states). Especially, the model to be applied for experimental design for the optimisation of fermentations has to be valid for the most productive process mode (i.e. the sequence of physiological states).
1.4. IDENTIFIABILITY
Usually unknown kinetic parameters are determined by nonlinear regression methods. It is often impossible to achieve an unambiguous parameter estimation due to the measurement noise, the small number of measurement data and a large number of model parameters. In that case different parameter values lead to nearly the same values of the identification criterion. Then the question arises which parameter values have to be used for the optimisation calculations. Different parameter values may result in different optimal process strategies. Therefore, models used for experimental design must be identifiable.
1.5. KNOWLEDGE AND DATA BASED HYBRID BIOPROCESS MODELLING
Various approaches of bioprocess modelling are established:
•general knowledge from textbooks, e.g. relational knowledge from metabolic
pathways of glycolysis or catabolite repression;
•general uncertain knowledge, e.g. the yield coefficient is known to be about 0.5 g/g or smaller for glucose as the sole carbon source in mass balances of microbial biomass growth and glucose consumption;
•process specific knowledge from skilled experts (if available), e.g. dependence of the reaction rates on the process phases;
•process specific knowledge hidden in the measured archived or actual data (if available), i.e. the dependence of reaction rates on environmental conditions (e.g.
glucose concentration or pH).
These different kinds of knowledge have to be acquired from literature or experts or have to be discovered from data. They may managed in so called expert systems (e.g. Gensym’s G2) or merged into one complex process model. For this merge of different kinds of knowledge those hybrid models are favoured which combine deterministic, fuzzy and data based (e.g. artificial neural network based) modules.
Fuzzy logic (Zadeh, 1965) is a convenient tool to handle uncertainties. Therefore it can be useful to build a hybrid bioprocess model consisting of a system of differential equations for the known mass balances including a fuzzy submodel describing the uncertain kinetic phenomena qualitatively or linguistically in the form of fuzzy rules.
The transformation of this qualitative knowledge into quantitative knowledge is carried out by tuning the membership functions of the fuzzy submodel.
132

Model based sequential experimental design for bioprocess Optimisation - an overview
This consideration leads us to the question, how to built such kinetic fuzzy submodels.
Generally there are two basic approaches to solve that problem, namely manually by an interview of a skilled expert (knowledge acquisition) or automatically by data exploration (data mining as a part of knowledge discovery from data). The success of an expert interview depends on the ability and willingness of the expert to reveal his knowledge. These conditions are not always fulfilled. Therefore great efforts were taken in the last years to develop methods for the extraction of knowledge from stored process data (Guthke and  1991; Guthke, 1992; Guthke and Ludwig, 1994; Guthke et al, 1998). This approach - often called data mining - includes two steps, the feature selection combined with fuzzy clustering methods and the fuzzy rule generation. The extracted fuzzy rules may be considered as hypotheses to be evaluated in advance of incorporating them in hybrid bioprocess models.
1991; Guthke, 1992; Guthke and Ludwig, 1994; Guthke et al, 1998). This approach - often called data mining - includes two steps, the feature selection combined with fuzzy clustering methods and the fuzzy rule generation. The extracted fuzzy rules may be considered as hypotheses to be evaluated in advance of incorporating them in hybrid bioprocess models.
An example for the fuzzy hybrid bioprocess modelling is given by Babuška et al. (1999). It describes the enzymatic penicillin-G conversion by a hybrid model including a fuzzy submodel. The authors showed the application of these approach to the experimental design for the optimisation of the fermentation of the enzyme hyaluronidase in recent own contributions (Berkholz et al., 1999; Berkholz et al., 2000a). In these papers the specific growth rate is described by a fuzzy submodel automatically data-derived using fuzzy-C-means clustering (Bezdek, 1981) and combinatory rule extraction (Guthke, 1992, Guthke and Ludwig, 1994).
Fuzzy hybrid models fulfil the demands on models used for experimental design procedures discussed in the sections above. They are transparent, explainable and evaluable with regard to their validity and relevance for the interesting productive process regions. The incorporated fuzzy submodels can be analysed with respect to their identifiability using sensitivity approaches. Unidentifiable fuzzy submodels have to be reduced stepwise until their output sensitivities become sufficient (Berkholz et al.,
2000a).
2. Direct experimental design method
Once an appropriate mathematical description of the considered bioprocess is found it can be applied to model based experimental design. This section refers to the so called direct experimental design method of bioprocess optimisation. This method is named direct method since the objective function is the same for both the optimisation of the experiment conditions and the process optimisation. That means the direct method leads to optimal experimental set-ups with respect to the productivity. Thus, this experimental design method is focussed directly on the primary aim of the experiments. A general expression for the objective function  for the direct experimental design is given as follows:
for the direct experimental design is given as follows:
According to equation (3) the value |
of |
is calculated using the predicted model output |
|
y at the free or fixed end |
of the |
process and is influenced by the model input u and |
|
133

Ralph Berkholz and Reinhard Guthke
the actual parameter estimation p. The optimal experimental set-up can be found by searching the optimal model input  that leads to the maximisation of
that leads to the maximisation of 
A detailed literature overview analysing different realisations of equation (3) is given by Schneider(1999).
Examples for the application of this experimental design procedure are discussed by
Glassey et al. (1994) and Galvanauskas et al. (1998). Both contributions describe the experimental design for the optimisation of fermentation of recombinant E. coli. The biomass at the end of fermentation is the objective function for both the experimental design and the process performance. Glassey et al. use an Artificial Neural Network model whereas Galvanauskas et al. describe the bioprocess with a deterministic model.
The main advantage of the direct experimental design method is the ability to propose experiments carried out in the productive region of the considered process. So the model can be validated for the one physiological state or those necessary to reach high product yields.
Disadvantageously the parameter estimation accuracy is not considered by this design method. It is known, that important kinetic parameters are not identifiable using batch experiments (Nihtilä and Virkkunen, 1977; Holmberg, 1982; Holmberg, 1983).
Versyck et al. (1997) have shown that a fedbatch experiment optimal in productivity may lead to unidentifiable model parameters. So the model itself or the realised experimental conditions might not allow a unique parameter estimation. In this case it is hardly to decide, which parameter set should be used for the optimisation calculations. Different parameter sets will generally lead to different optimisation results.
3. Indirect experimental design method
The indirect experimental design method for bioprocess optimisation focuses on experiments optimal in parameter estimation accuracy. This approach is called indirect method since the model parameters are determined as precise as necessary at first. After estimating the parameters the well adapted model will be used for the optimisation of productivity via simulation without performing further experiments.
The parameter estimation accuracy can be evaluated by calculating functionals of the Fisher information matrix F:
where |
denotes the model output sensitivity matrix, |
the measurement error |
covariance matrix and N the number of measurement points. In the case of a linear regression problem the Fisher information matrix F is the inverse of the parameter estimation error covariance matrix  which is defined as
which is defined as
134

Model based sequential experimental design for bioprocess Optimisation - an overview
where m denotes the dimension of the parameter vector p (Ljung, 1987). Therefore in a nonlinear case the Fisher information matrix F gives an upper bound for the precision of the parameter estimation:
The model output sensitivity matrix  is defined as:
is defined as:
where n denotes the dimension of the model output vector y.  may be obtained from equation (2) by differentiation:
may be obtained from equation (2) by differentiation:
where  regards to the state sensitivity matrix, that may be calculated by differentiation of equation (1):
regards to the state sensitivity matrix, that may be calculated by differentiation of equation (1):
According to equation (6) the parameter estimation accuracy is high if the elements of
have small |
absolute values. |
Small variances var |
mean that the estimated |
parameter values |
are probably near to their true values. Small absolute values for the |
||
parameter covariances cov |
indicate a low level of linear correlations between the |
||
different elements of the parameter set. Due to equation (7) the parameter estimation accuracy is high if the elements of F have great absolute values.
135

Ralph Berkholz and Reinhard Guthke
Experimental set-ups leading to precise parameter estimates are said to be informative.
Their information content is high. Thus, the indirect experimental design is focused on the optimisation of the information content. According to equation (5) there are several possibilities to increase the information content of an experimental set-up (Munack, 1995):
•increase in number of measurements N,
•choice of convenient measurement points 
•choice of convenient measurement signals 
•choice of convenient input signals u.
Due to its relevance for process optimisation the choice of convenient input signals u will be considered only. Then a general expression for the objective function for the indirect experimental design  may be formulated as follows:
may be formulated as follows:
The optimal experimental set-up may be found by searching the optimal model input  that leads to the maximisation of
that leads to the maximisation of 
Several expressions for the evaluation of the information content were developed. Some of them are shown in Table 1.
In the last decades a lot of results were published concerning the application of this approach. Some of them will be discussed in the following. Munack (1985) presents the maximisation of information content of experiments carried out in a tower loop reactor by optimising the positions of several 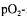 sensors. Posten and Munack (1990) apply the indirect experimental design to the improved modelling of plant cell suspension cultures. Baltes et al. (1994) take into account that bioprocess models are often not valid under transient conditions. Therefore they developed an objective function for the indirect experimental design combining the information content and the degree of stationarity of the process. Takors et al. (1997) optimise the parameter estimation accuracy of experiments carried out in a nutristat reactor using D-optimal experimental design. Syddall et al. (1998) give an application to improve the parameter estimation of a Penicillin fermentation model.
sensors. Posten and Munack (1990) apply the indirect experimental design to the improved modelling of plant cell suspension cultures. Baltes et al. (1994) take into account that bioprocess models are often not valid under transient conditions. Therefore they developed an objective function for the indirect experimental design combining the information content and the degree of stationarity of the process. Takors et al. (1997) optimise the parameter estimation accuracy of experiments carried out in a nutristat reactor using D-optimal experimental design. Syddall et al. (1998) give an application to improve the parameter estimation of a Penicillin fermentation model.
The main advantage of the indirect experimental design for bioprocess optimisation is that the proposed experimental set-ups lead to unique parameter estimates. Therefore there is no doubt which parameter values should be used during simulation calculations. On the other hand these experiments may be insufficient with respect to productivity. In those cases the experiments will be carried out in process regions out of interest. Thus the resulting experimental data may be worthless with regard to the validation of the state dependent bioprocess model (s. section 2.3).
136

Model based sequential experimental design for bioprocess Optimisation - an overview
4.  optimal experimental design method
optimal experimental design method
Due to the disadvantages of the both established experimental design methods for bioprocess optimisation discussed above we have proposed a novel experimental design approach called  optimal experimental design (Berkholz et al., 1999). The choice of the Greek letter
optimal experimental design (Berkholz et al., 1999). The choice of the Greek letter  standing on two feet symbolises the intention to take two objectives into account, namely the process productivity on the one and the parameter estimation accuracy on the other hand. So the
standing on two feet symbolises the intention to take two objectives into account, namely the process productivity on the one and the parameter estimation accuracy on the other hand. So the  optimal experimental design combines the concepts of direct and indirect experimental design. Therefore a general expression for the objective function for the
optimal experimental design combines the concepts of direct and indirect experimental design. Therefore a general expression for the objective function for the  optimal experimental design
optimal experimental design 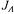 may be formulated:
may be formulated:
where  and
and  are the objective functions of the direct and the indirect experimental design method respectively. The optimal experimental set-up can be found by searching the optimal model input
are the objective functions of the direct and the indirect experimental design method respectively. The optimal experimental set-up can be found by searching the optimal model input  that leads to the maximisation of
that leads to the maximisation of 
There are several possibilities to solve this multi-objective optimisation problem. Here a weighted sum of  and
and  is applied:
is applied:
137

Ralph Berkholz and Reinhard Guthke
The upper index (*) indicates the normalisation of both functionals  and
and  due to their different orders of magnitude. It is advisable to normalise
due to their different orders of magnitude. It is advisable to normalise and
and  on the interval
on the interval
[0,1]. Doing so the weight factor 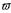 be selected with respect to the
be selected with respect to the
is also an element of the interval [0,1] and can easily experimental progress. At the beginning of the
bioprocess optimisation it is useful to choose a smaller weight. So the |
optimal |
experimental design procedure focuses mainly on the estimation accuracy of the unknown model parameters. Within further experiments the weight  can be increased to set the priority more on the process performance.
can be increased to set the priority more on the process performance.
The advantage of the 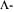 optimal experimental design is the consideration of both the productivity and parameter estimation accuracy. Using this approach it is possible to design experiments allowing a validation of the process model for the interesting productive process region and leading to unique parameter estimates for simulation calculations. The disadvantage of the
optimal experimental design is the consideration of both the productivity and parameter estimation accuracy. Using this approach it is possible to design experiments allowing a validation of the process model for the interesting productive process region and leading to unique parameter estimates for simulation calculations. The disadvantage of the  optimal experimental design method is the increased computational effort. A software tool using the MATLAB environment is available supporting the design of
optimal experimental design method is the increased computational effort. A software tool using the MATLAB environment is available supporting the design of  optimal experiments for the fermentation optimisation.
optimal experiments for the fermentation optimisation.
5. Experimental Example
In this section a short experimental example for the application of the  optimal experimental design is given considering the design of a single experiment for the optimisation of the hyaluronidase fermentation. Details about the process modelling, the cultivation conditions and the description of the whole sequence of three experiments carried out during the process optimisation can be found in Berkholz et al. (2000b).
optimal experimental design is given considering the design of a single experiment for the optimisation of the hyaluronidase fermentation. Details about the process modelling, the cultivation conditions and the description of the whole sequence of three experiments carried out during the process optimisation can be found in Berkholz et al. (2000b).
The objective function for the process performance  is expressed by the mass mp of the product
is expressed by the mass mp of the product
at the end  of the fermentation process. The objective function for the parameter estimation accuracy
of the fermentation process. The objective function for the parameter estimation accuracy  bases on the modified E-criterion:
bases on the modified E-criterion:
The only input influencing both |
is the substrate dosage rate |
In the current |
|
process optimisation state |
is realised quite simple by a pulse-like dosage at the |
||
dosage time Applying |
optimal design the optimal dosage time |
is given by |
|
where the objective function 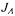 combining the normalised values of
combining the normalised values of 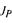 and
and  is:
is:
138

Model based sequential experimental design for bioprocess Optimisation - an overview
In figure 1 the criteria |
and |
are shown as functions of the dosage time It is |
|
recognisable that both |
and |
have their maximum at different dosage time points |
|
The objective function |
is calculated by setting the weight factor |
at 0.2. The |
|
corresponding optimal dosage time  is 9 h.
is 9 h.
In figure 2 the measured data of the designed optimal experiment and the kinetics of the process model are shown.
It can be seen, that the model fits the experimental data quite well. The process productivity reached during this experiment was about 60 % higher than before. The objectives of the  optimal experimental design namely the experimental validation of the process model in the productive process region and the improving of the parameter estimation have been achieved.
optimal experimental design namely the experimental validation of the process model in the productive process region and the improving of the parameter estimation have been achieved.
139

Ralph Berkholz and Reinhard Guthke
References
Babuška, R., H.B. Verbruggen and H.J.L. Can, 1999, Fuzzy Modelling of Enzymatic Penicillin-G Conversion, Engineering Applications of Artificial Intelligence, 12, 59-78.
Baltes, M., R. Schneider, C. Sturm and M. Reuss, 1994, Optimal Experimental Design for Parameter Estimation in Unstructured Growth Models. Biotechnol. Prog. 10, 480-488.
Berkholz, R., R. Guthke and W. Schmidt-Heck, 1999, Sequentielle Versuchsplanung zur Optimierung von
Bioprozessen mit Produktbildung im Übergangszustand, DECHEMA/GVC-Tagung ,,Wechselwirkung zwischen Biologie und  Erfurt, 10.-11.5.1999.
Erfurt, 10.-11.5.1999.
Berkholz, R., R. Guthke, W. Schmidt-Heck and D. Röhlig, 2000a, Experimental Design for Bioprocess Optimisation: Numerical and Experimental Results, Int. Symp. Biotechnology, Berlin, 3.-8.9.2000.
Berkholz, R., R. Guthke and D. Röhlig, 2000b, Data and Knowledge Based Experimental Design for
Bioprocess Optimisation, Enzyme and Microbial Technology, in press.
Bezdek, J., 1981, Pattern Recognition with Fuzzy Objective Function Algorithms, Plenum, New York. Galvanauskas, R., R. Simutis, N. Volk and A. Lübbert, 1998, Model Based Design of a Biochemical
Cultivation Process, Bioprocess Eng., 18, 227-234.
Glassey, J., G.A. Montague, A.C. Ward and B.V. Kara, 1994, Artificial Neural Network Based Experimental Design for Enhancing Fermentation Development, Biotechnol. Bioeng., 44, 397-405.
Guthke, R. and R.  1991, Fermentation Analysis by Clustering. Bioprocess Eng., 6, 157-161. Guthke, R., 1992, Learning Rules from Fermentation Data, In: Karim, M.N. and G. Stephano-poulos (Eds.),
1991, Fermentation Analysis by Clustering. Bioprocess Eng., 6, 157-161. Guthke, R., 1992, Learning Rules from Fermentation Data, In: Karim, M.N. and G. Stephano-poulos (Eds.),
Modelling and Control of Biotechnical Processes, Colorado, USA, 403-405.
Guthke R. and B. Ludwig, 1994, Generation of Rules for Expert Systems by Statistical Methods of
Fermentation Data Analysis, Acta Biotechnol., 14, 13-26.
Guthke, R., W. Schmidt-Heck and M. Pfaff, 1998, Knowledge Acquisition and Knowledge Based Control in
Bioprocess Engineering, J. Biotechnol., 65, 37-46.
140
Model based sequential experimental design for bioprocess Optimisation - an overview
Holmberg, A., 1982, On the Practical Identifiability of Microbial Growth Models Incorporating MichaelisMenten Type Nonlinearities, Math. Biosci., 60, 23-43.
Holmberg, A., 1983, On Accuracy of Estimating the Parameters of Models Containing Michaelis-Menten
Type Nonlinearities, In: Vansteenkiste, G.C. and P.C. Young (Eds.), Modelling and Data Analysis in Biotechnology and Medical Engineering, North-Holland Publishing Company.
Ljung, L., 1987, System Identification: Theory for the User, Prentice-Hall, Englewood Cliffs.
Munack, A., 1985, On the Parameter Identification for Complex Biotechnical Systems, Proc. 1st IFAC Symp. Modelling and Control of Biotechnological Processes, Noordwijkerhout, 159-165.
Munack, A., 1995, Simulation bioverfahrenstechnischer Prozesse, In: Schuler, H. (Eds.), 
VCH, Weinheim, New York, Basel, Cambridge.
Nihtilä, M. and J. Virkkunen, 1977, Practical Identifiability of Growth and Substrate Consumption Models, Biotechnol. Bioeng., 19, 1831-1850.
Posten, C. and A. Munack, 1990, Improved Modelling of Plant Cell Suspension Cultures by Optimum Experiment Design, Preprints of the 11 t h IFAC World Congress ,,Automatic Control in the Service of Mankind“, Tallinn, Estonia.
Schneider, R., 1999, Untersuchung eines adaptiven prädiktiven Regelungsverfahrens zur Optimierung von bioverfahrenstechnischen Prozessen, Dissertation, VDI-Verlag, Düsseldorf.
Syddall, M.T., G.C. Paul and C.A. Kent, 1998, Improving the Estimation of Parameters of Penicillin
Fermentation Models, Preprints of the 7th International Conference on Computer Applications in Biotechnology, 23-28, Osaka, Japan.
Takors, R., W. Wiechert and D. Weuster-Botz, 1997, Experimental Design for the Identification of Macrokinetic Models and Model Discrimination, Biotechn. Bioeng., 56, 564-576.
Versyck, K.J., J.E. Claes and J.F. Van Impe, 1997, Practical Identification of Unstructured Growth Kinetics by Application of Optimal Experimental Design, Biotechnol. Prog., 13, 524-531.
Zadeh, L., A., 1965, Fuzzy Sets, Information and Control, 8, 338-353.
141