

2.Понятие информации (определение, её свойства и методы измерения её количества).
2.1. Неоднозначность и сложность понятия «информация»
Для большинства из нас слово «информация» - нечто само собой разумеющееся. Тем не менее, это понятие относится к базовым понятиям не только в области информатики (наряду с такими, как структура, модель, алгоритм), но и естествознании в целом.
Действительно, попробуйте сформулировать, что такое информация. Проведите опрос окружающих вас людей на работе, учёбе и дома. Сразу окажется, что однозначного определения вы не услышите. Почему это так? Просто потому, что это понятие вбирает в себя всё, что окружает нас. Это одно из первичных неопределённых понятий науки, что подтверждается множеством определений понятия информации: от философского (информация есть отражение реального мира) до крайне практического (информация есть сведения, являющиеся объектом хранения, передачи и преобразования).
Думаем, ситуация для неискушённого в теории человека станет ещё более запутанной, если мы «вбросим» ему для размышления ещё несколько вопросов и тезисов:
Существует ли информация в неживой природе?
Верно ли, что информация существует только в биологических системах?
Получили ли вы информацию, дотронувшись до горячего чайника?
Информацию можно получить только при общении, так как она возникает только при этом процессе.
Информацию всегда можно выразить в словах.
Одинакова ли информация в крике вороны для вас и для других ворон стаи?
Информация создаётся, хранится и обрабатывается.
Какую информацию получает охотник из следа зверя, и кто её создал?
Для кого предназначена информация в молекуле ДНК?
Получаете ли вы информацию от прочтения в первый раз сообщения из свежей газеты? А при прочтении его во второй или в третий раз?
Попробуем вместе разобраться, что понимать и как трактовать понятие информации, каким свойствами она обладает, что является «основой» для понимания сущности этого понятия.
Проведите такой эксперимент: введите в поисковике Google строку «информация». Что получилось? У нас при поиске страниц на русском языке в январе 2009 года было выдано более 155 миллионов страниц. Попробуйте ввести для поиска в режиме поиска «со всеми словами» сочетание «определение информации». Поисковик выдал более 6 700 ссылок! Думается, что с течением времени эти цифры ещё подрастут. Следовательно, идёт постоянная работа человечества над использованием и толкованием этого понятия, обусловленное его применением к всё более широким сферам человеческой деятельности. Например, появились определения «экологической информации», правовой информации, документированной информации и т. д.
Легально (в правовом смысле) в России определение "информации" впервые появляется в Федеральном законе РФ "Об информации, информатизации и защите информации" от 20 февраля 1995 года. В нём под "информацией" понимаются "сведения о лицах, предметах, фактах, событиях, явлениях и процессах независимо от формы их представления". Отметим, что наряду с определением собственно "информации" Закон также содержит определение "документированной информации", т.е. различает информацию как таковую, как нематериальный объект, и информацию, связанную с материальным носителем.
Обобщая, можно сказать, что в зависимости от области знания существуют различные подходы к определению понятия информации. В частности:
В неживой природе понятие информации связывают с понятием отражения, отображения.
В быту под информацией понимают сведения, которые нас интересуют.
В теории связи под информацией принято понимать любую последовательность символов, не учитывая их смысл.
В кибернетике под информацией понимается только та часть сообщения, которая участвует в управлении.
2.2. Методы измерения информации
В информатике используются различные подходы к измерению информации:
Содержательный подход к измерению информации. Сообщение – информативный поток, который в процессе передачи информации поступает к приемнику. Сообщение несет информацию для человека, если содержащиеся в нем сведения являются для него новыми и понятными Информация - знания человека ? сообщение должно быть информативно. Если сообщение не информативно, то количество информации с точки зрения человека = 0. (Пример: вузовский учебник по высшей математике содержит знания, но они не доступны 1-класснику)
Алфавитный подход к измерению информации не связывает кол-во информации с содержанием сообщения. Алфавитный подход - объективный подход к измерению информации. Он удобен при использовании технических средств работы с информацией, т.к. не зависит от содержания сообщения. Кол-во информации зависит от объема текста и мощности алфавита. Ограничений на max мощность алфавита нет, но есть достаточный алфавит мощностью 256 символов. Этот алфавит используется для представления текстов в компьютере. Поскольку 256=28, то 1символ несет в тексте 8 бит информации.
Вероятностный подход к измерения информации. Все события происходят с различной вероятностью, но зависимость между вероятностью событий и количеством информации, полученной при совершении того или иного события можно выразить формулой которую в 1948 году предложил Шеннон.
Количество информации - это мера уменьшения неопределенности.
1 БИТ – такое кол-во информации, которое содержит сообщение, уменьшающее неопределенность знаний в два раза. БИТ- это аименьшая единица измерения информации
Единицы измерения информации: 1байт = 8 бит
1Кб (килобайт) = 210 байт = 1024 байт
1Мб
(мегабайт) = 210 Кб
= 1024 Кб
1Гб (гигабайт) = 210 Мб = 1024 Мб
Формула Шеннона
I - количество информации
N – количество возможных событий
pi – вероятности отдельных событий
Задача1: Какое количество информации будет содержать зрительное сообщение о цвете вынутого шарика, если в непрозрачном мешочке находится 50 белых, 25красных, 25 синих шариков
1) всего шаров 50+25+25=100
2) вероятности шаров 50/100=1/2, 25/100=1/4, 25/100=1/4
3)I= -(1/2 log21/2 + 1/4 log21/4 + 1/4 log21/4) = -(1/2(0-1) +1/4(0-2) +1/4(0-2)) = 1,5 бит
Количество
информации достигает max значения, если
события равновероятны, поэтому
количество информации можно расcчитать по
формуле ![]()
Задача2 : В корзине лежит 16 шаров разного цвета. Сколько информации несет сообщение, что достали белый шар?
т.к. N = 16 шаров, то I = log2 N = log2 16 = 4 бит.
3.Формы представления информации, понятие и характеристика информационного канала, классификация информационных процессов.
3.6. Формы представления информации
Информация может существовать в самых разнообразных формах, например, в виде:
текстов, рисунков, чертежей, фотографий;
световых или звуковых сигналов;
радиоволн;
электрических и нервных импульсов;
магнитных записей;
жестов и мимики;
запахов и вкусовых ощущений;
хромосом, передающих по наследству признаки и свойства организмов и т. д.
Предметы, процессы, явления материального или нематериального свойства, рассматриваемые с точки зрения их информационных свойств, называются информационными объектами.
Процессы, связанные с определенными операциями над информационными объектами, называются информационными процессами.
Обработка информации — получение одних информационных объектов из других путем выполнения некоторых алгоритмов.
3.5. Передача информации. Информационные каналы
Характеристики информационного канала
Информация передается в виде сообщений от некоторого источника информации к ее приемнику посредством канала связи между ними (рис. 1.2). Источник посылает передаваемое сообщение. Любое событие или явление может быть выражено разными способами. Для более точной и экономной передачи по каналам связи информацию надо закодировать. Закодированное сообщение приобретает вид сигналов — носителей информации, которые идут по каналу. В приемнике принимаемый сигнал декодируется и становится принимаемым сообщением. Передача сигнала по каналам связи часто сопровождается воздействием помех, вызывающих искажение и потерю информации.
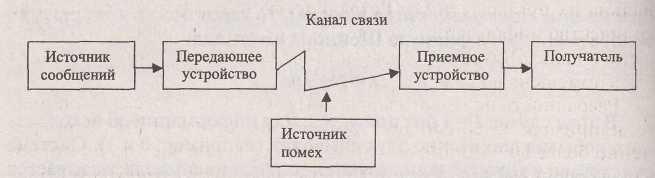
Рис.3. 2. Общая схема передачи информации
Совокупность устройств, предметов или объектов, предназначенных для передачи информации от одного из них, именуемого источником, к другому, именуемому приемником, называется каналом информации, или информационным каналом.
Примером канала может служить почта. Информация, закодированная в виде текста, помещается в конверт, поступает в почтовый ящик, извлекается оттуда и перевозится в почтовое отделение, где сортируется (вручную или машиной). Далее информация перемещается с помощью поезда (самолета, теплохода и т. П.) в почтовое отделение пункта назначения, сортируется и доставляется адресату. Таким образом, почтовый канал включает в себя: конверт (предмет), транспорт и сортировочные машины (устройства), почтовых работников (объекты).
Информация, помещенная в этот канал, остается неизменной, в отличие от информационного канала «телефон», который включает в себя: телефонные аппараты (устройства), провода (предметы) и аппаратуру АТС (устройства). Его особенностью является то обстоятельство, что при поступлении в него информация, представленная в виде звуковых волн, преобразуется в электрические колебания и затем передается. Такой канал называется каналом с преобразованием информации.
Компьютер является информационным каналом второго типа: информация поступает с внешних устройств (клавиатура, диск, микрофон), преобразуется во внутреннюю форму, обрабатывается, снова преобразуется в вид, пригодный для внешних устройств (монитор, принтер, динамик и др.) и передается на них.
Информационные каналы различаются по пропускной способности - количеству информации, передаваемой каналом в единицу времени. Измеряется пропускная способность в бит/с. В честь изобретателя телеграфа этой единице было дано имя бод: 1 бод = 1 бит/с.
Пропускная способность информационного канала определяется двумя параметрами: разрядностью и частотой — и пропорциональна их произведению. Разрядностью называют максимальное количество информации, которое может быть одновременно помещено в канал. Частота показывает, сколько раз информация может быть помещена в канал в единицу времени.
Разрядность почтового канала огромна. Так, пересылая по почте, например, лазерный диск, можно поместить в канал одновременно более 600 Мб информации. В то же время частота почтового канала очень низкая — выемка почты из ящиков происходит не чаще пяти раз в сутки.
Телефонный канал информации однобитный: одновременно по телефонному проводу можно послать или единицу (ток, импульс), или ноль. Однако частота этого канала может достигать десятков и сотен тысяч циклов в секунду. Это свойство телефонной сети позволяет использовать ее для связи между компьютерами.
3.7. Классификация информационных процессов
Получение информации тесно связано с информационными процессами, поэтому имеет смысл рассмотреть отдельно их виды.
Сбор данных – это деятельность субъекта по накоплению данных с целью обеспечения достаточной полноты. Соединяясь с адекватными методами, данные рождают информацию, способную помочь в принятии решения. Например, интересуясь ценой товара, его потребительскими свойствами, мы собираем информацию для того, чтобы принять решение: покупать или не покупать его.
Передача данных — это процесс обмена данными. Предполагается, что существует источник информации, канал связи, приемник информации, и между ними приняты соглашения о порядке обмена данными, эти соглашения называются протоколами обмена. Например, в обычной беседе между двумя людьми негласно принимается соглашение, не перебивать друг друга во время разговора.
Хранение данных — это поддержание данных в форме, постоянно готовой к выдаче их потребителю. Одни и те же данные могут быть востребованы не однажды, поэтому разрабатывается способ их хранения (обычно на материальных носителях) и методы доступа к ним по запросу потребителя.
Обработка данных — это процесс преобразования информации от исходной ее формы до определенного результата. Сбор, накопление, хранение информации часто не являются конечной целью информационного процесса. Чаще всего первичные данные привлекаются для решения какой-либо проблемы, затем они преобразуются шаг за шагом в соответствии с алгоритмом решения задачи до получения выходных данных, которые после анализа пользователем предоставляют необходимую информацию.
1
4.Представление (кодирование) данных в электронных вычислительных машинах: представление чисел, символов, звуковых и графических данных.
4.1. Понятие кодирования данных
Чтобы работать с данными различных видов, необходимо унифицировать форму их представления, а это можно сделать с помощью кодирования. Кодированием мы занимаемся довольно часто, например, человек мыслит весьма расплывчатыми понятиями, и, чтобы донести мысль от одного человека к другому, применяется язык. Язык — это система кодирования понятий. Чтобы записать слова языка, применяется опять же кодирование — азбука. Проблемами универсального кодирования занимаются различные области науки, техники, культуры. Вспомним, что чертежи, ноты, математические выкладки являются тоже некоторым кодированием различных информационных объектов. Аналогично, универсальная система кодирования требуется для того, чтобы большое количество различных видов информации можно было бы обработать на компьютере.
Взгляды создателей вычислительной техники были обращены на двоичное кодирование как универсальную форму представления данных для дальнейшей обработки их средствами вычислительной техники. Предполагается, что данные располагаются в некоторых ячейках, представляющих упорядоченную совокупность из двоичных разрядов, а каждый разряд может временно содержать одно из состояний – 0 или 1. Тогда группой из двух двоичных разрядов (двух бит) можно закодировать 22 = 4 различные комбинации кодов (00,.01, 10, 11); аналогично, три бита дадут 23 = 8 комбинаций, восемь бит или 1 байт — 28 = 256 и т.д.
Итак, внутренняя азбука компьютера очень бедна, содержит всего два символа: 0, 1, поэтому и возникает проблема представления всего многообразия типов данных – чисел, текстов, звуков, графических изображений, видео и др. — только этими двумя символами, с целью дальнейшей обработки средствами вычислительной техники.
4.2. Представление чисел в двоичном коде
Существуют различные способы записи чисел, например: можно записать число в виде текста — сто двадцать три; римской системе счисления – СХХШ; арабской — 123.
Совокупность приемов записи и наименования чисел называется системой счисления.
Числа записываются с помощью символов, и по количеству символов, используемых для записи числа, системы счисления подразделяются на позиционные и непозиционные. Если для записи числа используется бесконечное множество символов, то система счисления называется непозиционной. Примером непозиционной системы счисления может служить римская. Например, для записи числа один используется буква I, два и три выглядят как совокупности символов II, III, но для записи числа пять выбирается новый символ V, шесть – VI, десять – вводится символ X, сто – С, тысяча –М и т.д. Бесконечный ряд чисел потребует бесконечного числа символов для записи чисел. Кроме того, такой способ записи чисел приводит к очень сложным правилам арифметики.
Позиционные системы счисления для записи чисел используют ограниченный набор символов, называемых цифрами, и величина числа зависит не только от набора цифр, но и от того, в какой последовательности записаны цифры, т.е. от позиции, занимаемой цифрой, например, 125 и 215. Количество цифр, используемых для записи числа, называется основанием системы счисления, в дальнейшем его обозначим q.
В повседневной жизни мы пользуемся десятичной позиционной системой счисления, q = 10, т.е. используется 10 цифр: 0 12 3 4 5 6 7 8 9.
Рассмотрим правила записи чисел в позиционной десятичной системе счисления. Числа от 0 до 9 записываются цифрами, для записи следующего числа цифры не существует, поэтому вместо 9 пишут 0, но левее нуля образуется еще один разряд, называемый старшим, где записывается (прибавляется) 1, в результате получается 10. Затем пойдут числа 11, 12, но на 19 опять младший разряд заполнится и мы его снова заменим на 0, а старший разряд увеличим на 1, получим 20. Далее по аналогии 30, 40 … 90, 91, 92 … до 99. Здесь заполненными оказываются два разряда сразу; чтобы получить следующее число, мы заменяем оба на 0, а в старшем разряде, теперь уже третьем, поставим 1 (т.е. получим число 100) и т.д. Очевидно, что, используя конечное число цифр, можно записать любое сколь угодно большое число. Заметим также, что производство арифметических действий в десятичной системе счисления весьма просто.
Число в позиционной системе счисления с основанием q может быть представлено в виде полинома по степеням q. Например, в десятичной системе мы имеем число
123,45 = 1 • 102 + 2 • 101 + 3 • 10° + 4 •10-1 + 5 • 10-2
а в общем виде это правило запишется так:
Х(q) = xn-1 qn-1+ xn-2 qn-2+…+ x1 q1+ x0 q0+ x-1 q-1+ x-2 q-2+…+ x-m q-m
Здесь X(q) – запись числа в системе счисления с основанием q;
xi – натуральные числа меньше q, т.е. цифры;
n — число разрядов целой части;
m — число разрядов дробной части.
Записывая слева направо цифры числа, мы получим закодированную запись числа в двоичной системе счисления:
Х(q) = xn-1 xn-2 x1 x0 x-1 x-2 x-m
В информатике, вследствие применения электронных средств вычислительной техники, большое значение имеет двоичная система счисления, q = 2. На ранних этапах развития вычислительной техники арифметические операции с действительными числами производились в двоичной системе ввиду простоты их реализации в электронных схемах вычислительных машин. Например, таблица сложения и таблица умножения будут иметь по четыре правила:
|
0+0=0 |
0x0=0 |
|
0+1=1 |
0x1=0 |
|
1+0=1 |
1x0=0 |
|
1+1=10 |
1x1=1 |
А значит, для реализации поразрядной арифметики в компьютере потребуются вместо двух таблиц по сто правил в десятичной системе счисления две таблицы по четыре правила в двоичной. Соответственно на аппаратном уровне вместо двухсот электронных схем — восемь.
Представление чисел в памяти компьютера имеет специфическую особенность, связанную с тем, что в памяти компьютера они должны располагаться в байтах — минимальных по размеру адресуемых (т.е. к ним возможно обращение) ячейках памяти. Очевидно, адресом числа следует считать адрес первого байта. В байте может содержаться произвольный код из восьми двоичных разрядов, и задача представления состоит в том, чтобы указать правила, как в одном или нескольких байтах записать число.
Действительное число многообразно в своих «потребительских свойствах». Числа могут быть целые точные, дробные точные, рациональные, иррациональные, дробные приближенные, числа могут быть положительными и отрицательными. Числа могут быть «карликами», например, масса атома, «гигантами», например, масса Земли, реальными, например, количество студентов в группе, возраст, рост. И каждое из перечисленных чисел потребует для оптимального представления в памяти свое, количество байтов.
Очевидно, единого оптимального представления для всех действительных чисел создать невозможно, поэтому создатели вычислительных систем пошли по пути разделения единого по сути множества чисел на типы (например, целые в диапазоне от … до …, приближенные с плавающей точкой с количеством значащих цифр … и т.д.). Для каждого в отдельности типа создается собственный способ представления.
Как уже говорилось, минимально адресуемой единицей памяти является байт, но представление числа требует большего объема. Очевидно, такие числа займут группу байт, а адресом числа будет адрес первого байта группы. Следовательно, произвольно взятый из памяти байт ничего нам не скажет о том, частью какого информационного объекта он является — целого числа, числа с плавающей запятой или команды. Резюмируя вышесказанное, можно сделать вывод, что кроме задачи представления данных в двоичном коде, параллельно решается обратная задача — задача интерпретации кодов, т.е. как из кодов восстановить первоначальные данные.
Для представления основных видов информации (числа целые, числа с плавающей запятой, символы, звук и т.д.) в системах программирования используют специального вида абстракции — типы данных. Каждый тип данных определяет логическую структуру представления и интерпретации для соответствующих данных.
4.3. Представление символьных и текстовых данных в двоичном коде
Для передачи информации между собой люди используют знаки и символы. Начав с простейших условных жестов, человек создал целый мир знаков, где главным средством общения стал язык (т.е. речь и письменность). Слово есть минимальная первичная единица языка, представляющая собой специальный набор символов и служащая для наименования понятий, предметов, действий и т.п. Следующим по сложности элементом языка является предложение — конструкция, выражающая законченную мысль. На основе предложений строится текст. Текст (от лат. Textus — ткань, соединение) — высказывание, выходящее за рамки предложения и представляющее собой единое и целое, наделенное внутренней структурой и организацией в соответствии с правилами языка.
С появлением вычислительных машин стала задача представления в цифровой форме нечисловых величин, и в первую очередь — символов, слов, предложений и текста.
Символы. Для представления символов в числовой форме был предложен метод кодирования, получивший в дальнейшем широкое распространение и для других видов представления нечисловых данных (звуков, изображений и др.). Кодом называется уникальное беззнаковое целое двоичное число, поставленное в соответствие некоторому символу. Под алфавитом компьютерной системы понимают совокупность вводимых и отображаемых символов. Алфавит компьютерной системы включает в себя арабские цифры, буквы латинского алфавита, знаки препинания, специальные символы и знаки, буквы национального алфавита, символы псевдографики — растры, прямоугольники, одинарные и двойные рамки, стрелки. Первоначально для хранения кода одного символа отвели 1 байт (8 битов), что позволяло закодировать алфавит из 256 различных символов. Система, в которой каждому символу алфавита поставлен в соответствие уникальный код, называется кодовой таблицей. Разные производители средств вычислительной техники создавали для одного и того же алфавита символов свои кодовые таблицы. Это приводило к тому, что символы, набранные с помощью одной таблицы кодов, отображались неверно при использовании другой таблицы. Для решения проблемы многообразия кодовых таблиц в 1981 г. Институт стандартизации США принял стандарт кодовой таблицы, получившей название ASCII (American Standard Code of Information Interchange – американский стандартный код информационного обмена). Эту таблицу использовали программные продукты, работающие под управлением операционной системы MS-DOS, разработанной компанией Microsoft по заказу крупной фирмы — производителя персональных компьютеров IBM (International Business Machine). Широкое распространение персональных компьютеров фирмы IBM привело к тому, что стандарт ASCII приобрел статус международного.
В таблице ASCII содержится 256 символов и их кодов. Таблица состоит из двух частей: основной и расширенной. Основная часть (символы с кодами от 0 до 127 включительно) является базовой, она в соответствии с принятым стандартом не может быть изменена. В нее вошли: управляющие символы (им соответствуют коды с 1 по 31), арабские цифры, буквы латинского алфавита, знаки препинания, специальные символы (табл. 1.1).
Расширенная часть (символы с кодами от 128 до 255) отдана национальным алфавитам, символам псевдографики и некоторым специальным символам. В соответствии с утвержденными стандартами эта часть таблицы изменяется в зависимости от национального алфавита той страны, где она используется, и способа кодирования. Именно поэтому, при наименовании программ, документов и других объектов желательно использовать латинские буквы, содержащиеся в основной, неизменяемой части таблицы, так как русскоязычные имена при' несоответствии таблиц кодирования будут неверно отображаться. Например, операционная система Windows поддерживает большое число расширенных таблиц для различных национальных алфавитов. В России наиболее распространенной кодовой таблицей алфавита русского языка является «латиница Windows 1251» (табл. 1.2).
Во многих странах Азии 256 кодов явно не хватило для кодирования их национальных алфавитов. В 1991 г. Производители программных продуктов и организации, утверждающие стандарты, пришли к соглашению о выработке единого стандарта. Этот стандарт построен по 16 битной схеме кодирования и получил название UNICODE. Он позволяет закодировать 216= 65536 символов, которых достаточно для кодирования всех национальных алфавитов в одной таблице. Так как каждый символ этой кодировки занимает два байта (вместо одного, как раньше), все текстовые документы, представленные в UNICODE, стали длиннее в два раза. Современный уровень технических средств нивелирует этот недостаток UNICODE.
Текстовые строки. Текстовая (символьная) строка — это конечная последовательность символов. Это может быть осмысленный текст или произвольный набор, короткое слово или целая книга. Длина символьной строки — это количество символов в ней. Записывается в память символьная строка двумя способами: либо число, обозначающее длину текста, затем текст, либо текст, затем — разделитель строк.
Текстовые документы. Текстовые документы используются для хранения и обмена данными, но сплошной, не разбитый на логические фрагменты текст воспринимается тяжело. Структурирование теста достигается форматированием — специфическим расположением текста при подготовке его к печати. Для анализа структуры текста были разработаны языки разметки, которые устанавливают текстовые метки (маркеры или теги), используемые для обозначения частей документа, записывают вместе с основным текстом в текстовом формате. Программы, анализирующие текст, структурируют его, считывая теги.
4.4. Представление звуковых данных в двоичном коде
Звук — это упругая продольная волна в воздушной среде. Чтобы ее представить в виде, читаемом компьютером, необходимо выполнить следующие преобразования. Звуковой сигнал преобразовать в электрический аналог звука с помощью микрофона. Электрический аналог получается в непрерывной форме и не пригоден для обработки на цифровом компьютере. Чтобы перевести сигнал в цифровой код, надо пропустить его через аналого-цифровой преобразователь (АЦП). При воспроизведении происходит обратное преобразование — цифро-аналоговое (через ЦАП). Позже будет показано, что конструктивно АЦП и ЦАП находятся в звуковой карте компьютера.
Во время оцифровки сигнал дискретизируется по времени и по уровню. Дискретизация по времени выполняется следующим образом: весь период времени Т разбивается на малые интервалы времени t, точками t1, t2, … tn. Предполагается, что в течение интервала t уровень сигнала изменяется незначительно и может с некоторым допущением считаться постоянным. Величина v = I/t называется- частотой дискретизации. Она измеряется в герцах (Гц) — количество измерений в течение секунды. Дискретизация по уровню называется квантованием и выполняется так: область изменения сигнала от самого малого значения Xmin до самого большого значения Хмах разбивается на N равных квантов, промежутков величиной
Х = (Хмах – Xmin)/N.
Точками Х1, Х2, … Хп. Xi = Xmin.+ Х • (i – 1).
Каждый квант связывается с его порядковым номером, т.е. целым числом, которое легко может быть представлено в двоичной системе счисления. Если сигнал после дискретизации по времени (напомним, его принимаем за постоянную ОСлирну) попадает в промежуток Xi-1 < X < Xi , то ему в соответствие ставится код i.
Возникают две задачи:
первая: как часто по времени надо измерять сигнал,
вторая: с какой точностью надо измерять сигнал, чтобы получить при воспроизведении звук удовлетворительного качества.
Ответ на первую задачу дает теорема Найквиста, которая утверждает, что, если сигнал оцифрован с частотой v, то высшая «слышимая» частота будет не более v/2.
Вторая задача решается подбором числа уровней так, чтобы звук не имел высокого уровня шума и «электронного» оттенка звучания (точнее, это характеризуется уровнем нелинейных искажений). Попутно заметим, что число уровней берется как 2n. Чтобы измерение занимало целое число байт; v выбирают n = 8 или n = 16, т.е. каждое измерение занимает один или два байта.
Высокое качество воспроизведения получается в формате лазерного аудиодиска при следующих параметрах оцифровки: частота дискретизации — 44,1 кгц, квантование — 16 бит, т.е. Х = (Хмах – Xmin)/ 216. Таким образом, 1 с стереозвука займет 2 байт 44100байт/с 2 кан 1 с = 176 400 байт дисковой памяти. Качество звука при этом получается очень высоким.
Для телефонных переговоров удовлетворительное качество получается при частоте дискретизации 8 кгц и частоте квантования 255 уровней, т.е. 1 байт, при этом 1 с звуковой записи займет на диске
1 байт 8000 байт/с 1 с = 8000 байт.
4.5. Представление графических данных в двоичном коде
Есть два основных способа представления изображений.
Первый — графические объекты создаются как совокупности линий, векторов, точек — называется векторной графикой.
Второй – графические объекты формируются в виде множества точек (пикселей) разных цветов и разных яркостей, распределенных строкам и столбцам, — называется растровой графикой.
Модель RGB. Чтобы оцифровать цвет, его необходимо измерить. Немецкий ученый Грасман сформулировал три закона смешения цветов:
закон трехмерности — любой цвет может быть представлен комбинацией трех основных цветов;
закон непрерывности — к любому цвету можно подобрать бесконечно близкий;
закон аддитивности — цвет смеси зависит только от цвета составляющих.
За основные три цвета приняты красный (Red), зеленый (Green), синий (Blue). В модели RGB любой цвет получается в результате сложения основных цветов. Каждый составляющий цвет при этом характеризуется своей яркостью, поэтому модель называется аддитивной. Эта схема применяется для создания графических образов в устройствах, излучающих свет, — мониторах, телевизорах.
Модель CMYK. В полиграфических системах напечатанный на бумаге графический объект сам не излучает световых волн. Изображение формируется на основе отраженной волны от окрашенных поверхностей. Окрашенные поверхности, на которые падает белый свет (т.е. сумма всех цветов), должны поглотить (т.е. вычесть) все составляющие цвета, кроме того, цвет которой мы видим. Цвет поверхности можно получить красителями, которые поглощают, а не излучают. Например, если мы видим зеленое дерево, то это означает, что из падающего белого цвета, т.е. суммы красного, зеленого, синего, поглощены красный и синий, а зеленый отражен. Цвета красителей должны быть дополняющими:
голубой (Cyan = В + G), дополняющий красного;
пурпурный (Magenta = R + В), дополняющий зеленого;
желтый (Yellow = R + G), дополняющий синего.
Но так как цветные красители по отражающим свойствам не одинаковы, то для повышения контрастности применяется еще черный (black). Модель CMYK названа по первым буквам слов Cyan, Magenta, Yellow и последней букве слова black. Так как цвета вычитаются, модель называется субстрактивной.
Оцифровка изображения. При оцифровке изображение с помощью объектива проецируется на светочувствительную матрицу т строк и п столбцов, называемую растром. Каждый элемент матрицы — мельчайшая точка, при цветном изображении состоящая из трех светочувствительных (т.е. регистрирующих яркость) датчиков красного, зеленого, желтого цвета. Далее оцифровывается яркость каждой точки по каждому цвету последовательно по всем строкам растра.
Если для кодирования яркости каждой точки использовать по одному байту (8 бит) на каждый из трех цветов (всего 3 8 = 24 бита), то система обеспечит представление 224 ~ 16,7 млн. распознаваемых цветов, что близко цветовосприятию человеческого зрения. Режим представления цветной графики двоичным кодом из 24 разрядов называется полноцветным или True Color. Очевидно, графические данные, также как и звуковые, занимают очень большие объемы на носителях. Например, скромный по современным меркам экран монитора имеет растр 800 х 600 точек, изображение, представленное в режиме True Color, займет 800 600 х 3 = 1 440 000 байт.
В случае, когда не требуется высокое качество отображения цвета, применяют режим High Color, который кодирует одну точку растра двумя байтами (16 разрядов дают 216 ~ 65,5 тысячи цветов).
Режим, который при кодировании одной точки растра использует один байт, называется индексным, в нем различаются 256 цветов. Этого недостаточно, чтобы передать весь диапазон цветов. Код каждой точки при этом выражает собственно не цвет, а некоторый номер цвета (индекс) из таблицы цветов, называемой палитрой. Палитра должна прикладываться к файлам с графическими данными и используется при воспроизведении изображения.
5.Характеристика основных структур данных в информатике.
Работа с большими наборами данных автоматизируется проще, когда данные упорядочены, то есть образуют заданную структуру. Существует три основных типа структур данных: линейная, иерархическая и табличная. Их можно рассмотреть на примере обычной книги.
Если разобрать книгу на отдельные листы и перемешать их, книга потеряет свое назначение. Она по-прежнему будет представлять набор данных, но подобрать адекватный метод для получения из нее информации весьма непросто. (Еще хуже дело 'будет обстоять, если из книги вырезать каждую букву отдельно, — в этом случае вряд ли вообще найдется адекватный метод для ее прочтения.)
Если же собрать все листы книги в правильной последовательности, мы получим простейшую структуру данных — линейную. Такую книгу уже можно читать, хотя для поиска нужных данных ее придется прочитать подряд, начиная с самого начала, что не всегда удобно.
Для быстрого поиска данных существует иерархическая структура. Так, например, книги разбивают на части, разделы, главы, параграфы и т. п. Элементы структуры более низкого уровня входят в элементы структуры более высокого уровня: разделы состоят из глав, главы из параграфов и т. д.
Для больших массивов поиск данных в иерархической структуре намного проще, чем в линейной, однако и здесь необходима навигация, связанная с потребностью просмотра. На практике задачу упрощают тем, что в большинстве книг есть вспомогательная перекрестная таблица, связывающая элементы иерархической структуры с элементами линейной структуры, то есть связывающая разделы, главы и параграфы с номерами страниц. В книгах с простой иерархической структурой, рассчитанных на последовательное чтение, эту таблицу принято называть оглавлением, а в книгах со сложной структурой, допускающей выборочное чтение, ее называют содержанием.
Линейные структуры (списки данных, векторы данных)
Линейные структуры — это хорошо знакомые нам списки. Список — это простейшая структура данных, отличающаяся тем, что адрес каждого элемента данных однозначно определяется его номером. Проставляя номера на отдельных страницах рассыпанной книги, мы создаем структуру списка. Обычный журнал посещаемости занятий, например, имеет структуру списка, поскольку все студенты группы зарегистрированы в нем под своими уникальными номерами. Мы называем номера уникальными потому, что в одной группе не могут быть зарегистрированы два студента с одним и тем же номером.
При создании любой структуры данных надо решить два вопроса: как разделять элементы данных между собой и как разыскивать нужные элементы. В журнале посещаемости, например, это решается так: каждый новый элемент списка заносится с новой строки, то есть разделителем является конец строки. Тогда нужный элемент можно разыскать по номеру строки.
N п/п Фамилия, Имя, Отчество
1 Аистов Александр Алексеевич
2 Бобров Борис Борисович
3 Воробьева Валентина Владиславовна
……………………………………
27 Сорокин Сергей Семенович
Разделителем может быть и какой-нибудь специальный символ. Нам хорошо известны разделители между словами — это пробелы. В русском и во многих европейских языках общепринятым разделителем предложений является точка. В рассмотренном нами классном журнале в качестве разделителя можно использовать любой символ, который не встречается в самих данных, например символ «*». Тогда наш список выглядел бы так:
Аистов Александр Алексеевич * Бобров Борис Борисович * Воробьева Валентина Владиславовна *... * Сорокин Сергей Семенович
В этом случае для розыска элемента с номером n надо просмотреть список начиная с самого начала и пересчитать встретившиеся разделители. Когда будет отсчитано n-1 разделителей, начнется нужный элемент. Он закончится, когда будет встречен следующий разделитель.
Еще проще можно действовать, если все элементы списка имеют равную длину. В этом случае разделители в списке вообще не нужны. Надо просмотреть список с самого начала и отсчитать n-1 элемент. Со следующего символа начнется нужный элемент. Поскольку его длина известна, то его конец определить нетрудно. Такие упрощенные списки, состоящие из элементов равной длины, называют векторами данных. Работать с ними особенно удобно.
Таким образом, линейные структуры данных (списки) — это упорядоченные структуры, в которых адрес элемента однозначно определяется его номером.
Табличные структуры (таблицы данных, матрицы данных)
С таблицами данных мы тоже хорошо знакомы, достаточно вспомнить всем известную таблицу умножения. Табличные структуры отличаются от списочных тем, что элементы данных определяются адресом ячейки, который состоит не из одного параметра, как в списках, а из нескольких. Для таблицы умножения, например, адрес ячейки определяется номерами строки и столбца. Нужная ячейка находится на их пересечении, а элемент выбирается из ячейки.
При хранении табличных данных количество разделителей должно быть больше, чем для данных, имеющих структуру списка. Например, когда таблицы печатают в книгах, строки и столбцы разделяют графическими элементами — линиями вертикальной и горизонтальной разметки (рис. 1.10).
|
Город |
Население 1850 |
Население 1900 |
Население 1950 |
Население 1980 |
|
Нью-Йорк |
696115 |
3 437 202 |
7 891 957 |
7 071 639 |
|
Лос-Анжелес |
1 610 |
102479 |
1 970 358 |
2 966 850 |
|
Чикаго |
29963 |
1 698 575 |
3 620 962 |
3 005 072 |
|
Хьюстон |
2396 |
44633 |
596 163 |
1 595 138 |
|
Филадельфия |
121 376 |
1 293 667 |
2 071 605 |
1 688210 |
Рис. 1.10. В двумерных таблицах, которые печатают в книгах,
применяются два типа разделителей — вертикальные
и горизонтальные
Если нужно сохранить таблицу в виде длинной символьной строки, используют один символ-разделитель между элементами, принадлежащими одной строке, и другой разделитель для отделения строк, например так:
Нью-Йорк*696115*3437202*7891957*7071639#Лос-Анжелес*1610*102479*1970 58*2966850
Для розыска элемента, имеющего адрес ячейки (m, n), надо просмотреть набор данных с самого начала и пересчитать внешние разделители. Когда будет отсчитан m-1 разделитель, надо пересчитывать внутренние разделители. После того как будет найден n-1 разделитель, начнется нужный элемент. Он закончится, когда будет встречен любой очередной разделитель.
Еще проще можно действовать, если все элементы таблицы имеют равную длину. Такие таблицы называют матрицами. В данном случае разделители не нужны, поскольку все элементы имеют равную длину.
Таким образом, табличные структуры данных (матрицы) — это упорядоченные структуры, в которых адрес элемента определяется номером строки и номером столбца, на пересечении которых находится ячейка, содержащая искомый элемент.
Многомерные таблицы. Выше мы рассмотрели пример таблицы, имеющей два измерения (строка и столбец), но в жизни нередко приходится иметь дело с таблицами, у которых количество измерений больше. Вот пример таблицы, с помощью которой может быть организован учет учащихся.
Номер факультета: 3
Номер курса (на факультете): 2
Номер специальности (на курсе): 2
Номер группы в потоке одной специальности: 1
Номер учащегося в группе: 19
Размерность такой таблицы равна пяти, и для однозначного отыскания данных об учащемся в подобной структуре надо знать все пять параметров (координат).
Иерархические структуры данных
Нерегулярные данные, которые трудно представить в виде списка или таблицы, часто представляют в виде иерархических структур. С подобными структурами мы очень хорошо знакомы по обыденной жизни. Иерархическую структуру имеет система почтовых адресов. Подобные структуры также широко применяют в научных систематизациях и всевозможных классификациях (рис. 1.11).

Рис. 1.11. Пример иерархической структуры данных
В иерархической структуре адрес каждого элемента определяется путем доступа (маршрутом), ведущим от вершины структуры к данному элементу. Вот, например, как выглядит путь доступа к команде, запускающей программу Калькулятор (стандартная программа компьютеров, работающих в операционной системе Windows 98):
Пуск > Программы > Стандартные > Калькулятор.
Упорядочение структур данных
Списочные и табличные структуры являются простыми. Ими легко пользоваться, поскольку адрес каждого элемента задается числом (для списка), двумя числами (для двумерной таблицы) или несколькими числами для многомерной таблицы. Они также легко упорядочиваются. Основным методом упорядочения является сортировка. Данные можно сортировать по любому избранному критерию, например: по алфавиту, по возрастанию порядкового номера или по возрастанию какого-либо параметра.
Несмотря на многочисленные удобства, у простых структур данных есть и недостаток — их трудно обновлять. Если, например, перевести студента из одной группы в другую, изменения надо вносить сразу в два журнала посещаемости; при этом в обоих журналах будет нарушена списочная структура. Если переведенного студента вписать в конец списка группы, нарушится упорядочение по алфавиту, а если его вписать в соответствии с алфавитом, то изменятся порядковые номера всех студентов, которые следуют за ним.
Таким образом, при добавлении произвольного элемента в упорядоченную структуру списка может происходить изменение адресных данных у других элементов. В журналах успеваемости это пережить нетрудно, но в системах, выполняющих автоматическую обработку данных, нужны специальные методы для решения этой проблемы.
Иерархические структуры данных по форме сложнее, чем линейные и табличные, но они не создают проблем с обновлением данных. Их легко развивать путем создания новых уровней. Даже если в учебном заведении будет создан новый факультет, это никак не отразится на пути доступа к сведениям об учащихся прочих факультетов.
Недостатком иерархических структур является относительная трудоемкость записи адреса элемента данных и сложность упорядочения. Часто методы упорядочения в таких структурах основывают на предварительной индексации, которая заключается в том, что каждому элементу данных присваивается свой уникальный индекс, который можно использовать при поиске, сортировке и т. п. После такой индексации данные легко разыскиваются по двоичному коду связанного с ними индекса.
С примерами индексации вы, конечно, знакомы. Обычная книга (например такая, как эта) имеет иерархическую структуру. Алфавитный указатель в конце книги — это пример индекса. С его помощью можно найти страницу, соответствующую нужному термину, не прибегая к просмотру всего содержания.
Адресные данные
Если данные хранятся не как попало, а в организованной структуре (причем любой), то каждый элемент данных приобретает новое свойство (параметр), которое можно назвать адресом. Конечно, работать с упорядоченными данными удобнее, но за это приходится платить их размножением, поскольку адреса элементов данных — это тоже данные, и их тоже надо хранить и обрабатывать.
Самое обидное явление — это когда размер адресных данных становится больше, чем размер самих данных, на которые указывает адрес. В этом случае структура данных напоминает книгу, в которой оглавление занимает большую часть книги. Чтобы избежать такой ситуации, используются специальные методы организации хранения данных.
6.Информационные революции и основные этапы развития информатики.
Историю развития информатики принято рассматривать как последовательность 4-ёх информационных революций, а историю вычислительной техники принято делить на 4 основных этапа:
Домеханический,
Механический,
Электромеханический и
Электронный.
Эти четыре периода включают в себя весь прогресс от счета на пальцах до вычислений сверхмощных компьютеров. Как Вы сможете заметить при изучении дальнейшего материала, временные границы между этими периодами являются достаточно размытыми.
Заранее хочется отметить, как из приводимых ниже данных следует одна важная закономерность развития ВТ - это лавинообразное ускорение прогресса в этой области. Если ранее от одного достижения к другому человечество шло сотни и десятки лет, то на современном этапе эти периоды исчисляется уже месяцами!
Подчеркнём, что развитие техники шло параллельно с формированием научных приёмов, методологий, теорий в области информатики и разработки языков программирования
Многие изобретатели ВТ в разных странах работали параллельно и независимо друг от друга, получали практически одинаковые результаты. Естественно, что отметить всех в достаточно кратком изложении просто невозможно.
7.Информационные революции и основные этапы развития вычислительной техники.
1.2. Информационные революции и периодизация развития истории ВТ
Как мы уже выяснили, человечество со дня своего выделения из животного мира значительную часть своего времени и внимания уделяло информационным процессам.
На первых этапах носителем данных была память, и информация от одного человека к другому передавалась устно. Этот способ передачи информации был ненадежен и подвержен большим искажениям, ввиду естественного свойства памяти утрачивать редко используемые данные.
По мере развития цивилизации, объемы информации, которые необходимо было накапливать и передавать, росли, и человеческой памяти стало не хватать — появилась письменность. Это великое изобретение было сделано шумерами около шести тысяч лет назад. Оно позволило наряду с простыми записями счетов, векселей, рецептов записывать наблюдения за звездным небом, за погодой, за природой. Изменился смысл информационных сообщений. Появилась возможность обобщать, сопоставлять, переосмысливать ранее сохраненные сведения. Это же в свою очередь дало толчок развитию истории, литературы, точным наукам и в конечном итоге изменило общественную жизнь. Изобретение письменности характеризует первую информационную революцию.
Дальнейшее накопление человечеством информации привело к увеличению числа людей, пользовавшихся ею, но письменные труды одного человека могли быть достоянием небольшого окружения. Возникшее противоречие было разрешено с изобретением печатного станка. Эта веха в истории цивилизации характеризуется как вторая информационная революция (началась в XVI в.). Доступ к информации перестал быть делом отдельных лиц, появилась возможность многократно увеличить объем обмена информацией, что привело к большим изменениям в науке, культуре и общественной жизни
Третья информационная революция связывается с открытием электричества и появлением (в конце XIX в.) на его основе новых средств коммуникации — телефона, телеграфа, радио. Возможности накопления информации для тех времен стали поистине безграничными, а скорость обмена очень высокой.
К середине XX в. появились быстрые технологические процессы, управлять которыми человек не успевал. Проблема управления техническими объектами могла решаться только с помощью универсальных автоматов, собирающих, обрабатывающих данные и выдающих решение в форме управляющих команд. Ныне эти автоматы называются компьютерами. Бурно развивавшаяся наука и промышленность привели к росту информационных ресурсов в геометрической прогрессии, что породило проблемы доступа к большим объемам информации.
Наше время отмечается как четвертая информационная революция. Наиболее характерной её особенностью является подключение к активному использованию вычислительной техники в повседневной жизни сотен миллионов людей, также объединение компьютеров в сети всепланетного масштаба. Появилась всемирная компьютерная сеть Интернет, услугами которой пользуется значительная часть населения планеты, оперативно получая и обмениваясь данными, т.е. формируется единое мировое информационное пространство.
В свою очередь историю развития вычислительной техники принято разделять по следующим основным периодам:
Домеханический – с VI века до н. э. до XVII века н.э.;
Механический – с XVII века до начала XX ;
Электромеханический – с середины XIX века до середины XX века;
Электронный – с середины XX века до настоящего времени.
Электронный период можно разбить ещё на ряд периодов – так быстро развивалась техника в этот период. Но об этом будет сказано далее в соответствующем разделе.
9.Понятие алгебры логики. Элементарные логические операции и их техническая реализация. Определение вентиля и их обозначения. Понятие таблицы истинности.
Алгебра логики — раздел математики, изучающий высказывания, рассматриваемые с точки зрения их логических значений (истинности или ложности) и логических операций над ними.
Под логическим высказыванием понимается любое повествовательное предложение, в отношении которого можно однозначно сказать, истинно оно или ложно. Например, логическим высказыванием будет “Земля третья планета от Солнца”, но не является таковым “Морозная в этом году зима”.
Важность знакомства с двоичными алгебрами ( а именно таковой является алгебра логики) заключается в следующем. Во-первых, они являются математической основой строения всех логических схем компьютеров, обрабатывающих информацию в двоичной системе счисления. Во-вторых, они служат математической основой решения сложных логических задач.
Работу вентильных, логических схем следует рассматривать в двоичной системе и на математическом, логическом уровне, не затрагивая технические аспекты – то есть аспекты микроэлектроники, системотехники (хотя они и очень важны в технической информатике).
Логические функции отрицания, дизъюнкции и конъюнкции реализуют, соответственно, логические схемы, называемые инвертором, дизъюнктором и конъюнктором.
4.3. Элементарные логические операции и их техническая реализация
4.3.3. Инверсия (логическое отрицание)
Логическая функция "инверсия", или отрицание, реализуется логической схемой (вентилем), называемой инвертор.
Принцип его работы можно условно описать следующим образом: если, например, "0" или "ложь" отождествить с тем, что на вход этого устройства скачкообразно поступило напряжение в 0 вольт, то на выходе получается 1 или "истина", которую можно также отождествить с тем, что на выходе снимается напряжение в 1 вольт.
Аналогично, если предположить, что на входе инвертора будет напряжение в 1 вольт ("истина"), то на выходе инвертора будет сниматься 0 вольт, то есть "ложь»
Функцию отрицания можно условно отождествить с электрической схемой соединения в цепи с лампочкой (рис. 4.2), в которой замкнутая цепь соответствует 1 ("истина") или х = 1, а размыкание цепи соответствует 0 ("ложь") или х = 0.
Моделью ячейки, реализующей функцию НЕ, может служить размыкающий контакт реле. При срабатывании реле цепь, в которую входит такой контакт, будет размыкаться. Таким образом, инверсия единицы равна нулю, инверсия нуля - единице, а двойная инверсия не изменяет значения переменной.
4.3.2. Дизъюнкция (логическое сложение)
Дизъюнкция — это такая двоичная функция, которая равна нулю тогда и только тогда, когда все аргументы функции равны нулю, другое определение: дизъюнкция — это такая функция, которая равна единице, если хотя бы один аргумент равен единице.
Функции дизъюнкции соответствует операция логическое сложение. Знак операции: Пример записи формулы функции дизъюнкция: f (х1, х2 ) = =х1 х2. Читается формула так: «х1 или х2».
Запись на языках программирования: «х1 OR х2».
Функцию дизъюнкция реализует логический элемент дизъюнктор (элемент ИЛИ).
Логическое сложение (дизъюнкция) обозначается символом "+" или V (первая буква латинского слова vel-или). Таким образом, логическая сумма равна единице тогда, когда равно единице одно или несколько слагаемых.
В качестве примера реализации функции дизъюнкция рассмотрим схему голосования «хотя бы один». На рис. показана цепь с N кнопками, позволяющими включать индикаторную лампочку. Лампочка засветится в случае, если будет замкнут хотя бы один ключ, то есть схема реализует функцию дизъюнкция.
Дизъюнкцию реализует логическое устройство (вентиль) называемое дизьюнктор
В качестве примера цепи, реализующей: функцию ИЛИ, можно привести параллельное соединение замыкающих контактов нескольких реле. Цепь, в которую входят эти контакты, будет замкнута, если сработает хотя бы одно реле.
Работу дизъюнктора можно интерпретировать и схемой голосования «хотя бы один». На рис. 4.5 показана цепь с двумя (а в общем случае с N) кнопками, позволяющими включать индикаторную лампочку. Лампочка засветится в случае, если будет замкнут хотя бы один ключ, то есть схема реализует функцию дизъюнкция.
Таблица истинности операции логического сложения
|
Значение сигнала X |
Значение сигнала Y |
Значение сигнала на выходе (X ˅ Y) |
|
1 |
0 |
1 |
|
0 |
1 |
1 |
|
1 |
1 |
1 |
|
0 |
0 |
0 |
4.3.3. Конъюнкция (логическое умножение)
Конъюнкция — это такая булева функция, которая равна единице тогда и только тогда, когда все аргументы функции равны единице.
Другое определение — это такая функция, которая равна нулю, если хотя бы один аргумент функции равен нулю.
Логическое умножение (конъюнкция) обозначается точкой или символом ^ либо вообще в буквенных выражениях никак не обозначается.
Функцию конъюнкция получаем как результат операции логическое умножение. Знак операции: & или ^ (в теоретических работах по алгебре логики). В формулах, как и в обычной алгебре, знак чаще всего опускается.
Запись в языках программирования: х1 AND х2.
Функцию И реализуют, например, соединенные последовательно замыкающие контакты нескольких реле. Цепь в этом случае будет замкнута только тогда, когда сработают все реле (реализация схемы «вопрос решён положительно, только тогда, когда «за» проголосуют все. Конъюнкцию реализует логическая схема (вентиль), называемая конъюнктором, логика работы которой представлена на рис. 4.5(a,b,c):
Конъюнктор можно условно изобразить схематически электрической цепью вида (рис. 4.6)
4.4. Техническая реализация логических элементов
Схематически инвертор, дизьюнктор и конъюнктор на логических схемах различных устройств можно изображать условно следующим образом (рис. 4.7 а, б, в). Есть и другие общепринятые формы условных обозначений.
Из указанных простейших базовых логических элементов собирают, конструируют сложные логические схемы ЭВМ, например, сумматоры, шифраторы, дешифраторы и др. Большие (БИС) и сверхбольшие (СБИС) интегральные схемы содержат в своем составе (на кристалле кремния площадью в несколько квадратных сантиметров) десятки тысяч вентилей. Это возможно еще и потому, что базовый набор логических схем (инвертор, конъюнктор, дизъюнктор) является функционально полным (любую логическую функцию можно представить через эти базовые вентили), представление логических констант в них одинаково (одинаковы электрические сигналы, представляющие 1 и 0) и различные схемы можно "соединять" и "вкладывать" друг в друга (осуществлять композицию и суперпозицию схем).
10.Принципиальная схема и принцип работы ячейки хранения информации (триггера). доделать
Триггерами или, точнее, триггерными системами называют большой класс электронных устройств, обладающих способностью длительно находиться в одном из двух или более устойчивых состояний и чередовать их под воздействием внешних сигналов. Каждое состояние триггера легко распознаётся по значению выходного напряжения. По характеру действия триггеры относятся к импульсным устройствам — их активные элементы (транзисторы, лампы) работают в ключевом режиме, а смена состояний длится очень короткое время.
Отличительной особенностью триггера как функционального устройства является свойство запоминания двоичной информации. Под памятью триггера подразумевают способность оставаться в одном из двух состояний и после прекращения действия переключающего сигнала. Приняв одно из состояний за «1», а другое за «0», можно считать, что триггер хранит (помнит) один разряд числа, записанного в двоичном коде.
При изготовлении триггеров применяются преимущественно полупроводниковые приборы (обычно полевые транзисторы), в прошлом — электромагнитные реле, электронные лампы. В настоящее время логические схемы, в том числе с использованием триггеров, создают в интегрированных средах разработки под различные программируемые логические интегральные схемы (ПЛИС). Используются в основном в вычислительной технике для организации компонентов вычислительных систем: регистров, счётчиков, процессоров, ОЗУ.
11.Таблицы истинности основных логических схем.
Основные логические операции
Отрицание (инверсия), от латинского inversio -переворачиваю:
соответствует частице НЕ, словосочетанию НЕВЕРНО, ЧТО;
обозначение: не A, A, -A;
таблица истинности:
|
A |
A |
|
0 |
1 |
|
1 |
0 |
Инверсия логической переменной истинна, если сама переменная ложна, и, наоборот, инверсия ложна, если переменная истинна.
пример: A = {На улице идет снег}.
A={Не верно, что на улице идет снег}
A={На улице не идет снег};
логическая схема (инвертор):
Логическое сложение (дизъюнкция), от латинского disjunctio - различаю:
соответствует союзу ИЛИ;
обозначение: +, или, or, V;
таблица истинности:
|
A |
B |
F |
|
0 |
0 |
0 |
|
0 |
1 |
1 |
|
1 |
0 |
1 |
|
1 |
1 |
1 |
Дизъюнкция ложна тогда и только тогда, когда оба высказывания ложны.
пример: F={На улице светит солнце или дует сильный ветер};
логическая схема (дизъюнктор)
Логическое умножение (конъюкция), от латинского conjunctio -связываю:
соответствует союзу И
(в естественном языке: и А, и В
как А, так и В
А вместе с В
А, не смотря на В
А, в то время как В);
обозначение: Ч, •, &, и, ^, and;
таблица истинности:
|
A |
B |
F |
|
0 |
0 |
0 |
|
0 |
1 |
0 |
|
1 |
0 |
0 |
|
1 |
1 |
1 |
Конъюкция истинна тогда и только тогда, когда оба высказывания истинны.
пример: F={На улице светит солнце и дует сильный ветер};
логическая схема (конъюктор):
Любое сложное высказывание можно записать с помощью основных логических операций И, ИЛИ , НЕ.С помощью логических схем И, ИЛИ, НЕ можно реализовать логическую функцию, описывающую работу различных устройств компьютера.
2) Таблица истинности — это таблица, описывающая логическую функцию.
Под
«логической функцией» в данном случае
понимается функция, у которой значения
переменных (параметров функции) и
значение самой функции выражают
логическую истинность. Например, в
двузначной логике они могут принимать
значения «истина» либо «ложь»
(либо
,
либо
).
Табличное задание функций встречается не только в логике, но для логических функций таблицы оказались особенно удобными, и с начала XX века за ними закрепилось это специальное название. Особенно часто таблицы истинности применяются в булевой алгебре и в аналогичных системах многозначной логики.
Конъю́нкция- логическая операция, по своему применению максимально приближённая к союзу "и".логи́ческое умноже́ние, иногда просто "И".
Дизъю́нкция-логическая операция, по своему применению максимально приближённая к союзу «или» в смысле «или то, или это, или оба сразу». логи́ческое сложе́ние, иногда просто «ИЛИ».
Импликация —
бинарная логическая связка, по своему
применению приближенная к
союзам «если…то…».Импликация
записывается как посылка следствие;
применяются также стрелки другой формы
и направленные в другую сторону (остриё
всегда указывает на следствие).
Эквивале́нция (или эквивале́нтность) — двуместная логическая операция. Обычно обозначается символом ≡ или ↔.
13.Содержание понятия «Приложения и системы на основе Web».
1.2. Разработка Web приложений
Рассмотрим понятие «Разработка Web». Оно в противоположность «созданию страниц Web», выходит далеко за пределы использования кодов разметки и нескольких подключаемых модулей или метода сценариев для создания привлекательных или информативных страниц Web. Этот термин относится к использованию специальных стратегий, инструментов и методов для создания страниц Web и сайтов Web, характеризуемых как трехуровневые, клиент/серверные системы обработки информации. Рассмотрим эти термины более подробно, чтобы понять разнообразие задач, для которых разрабатываются страницы и сайты Web.
1.2.1. Системы обработки информации: интранет, интернет и экстранет.
Технологии Web используются не только для создания персональных или рекламных сайтов Web, содержащих информативный, интересный или развлекательный материал для публичного потребления. Прежде всего, они стали важным средством поддержки фундаментальных бизнес-процессов современных организаций, а именно операционных и управленческих функции.
Технические инфраструктуры поддержки этих задач упрощенно делятся на три типа систем на основе Web, называемых системами интранет, интернет и экстранет.
Системы интранет
Системы интранет являются внутренними системами, помогающими выполнять повседневную обработку информации, обеспечивая управленческо-информационную и производственную деятельность организаций. Системы интранет на основе Web обслуживают стандартные внутренние функции бизнеса, оказывая тем самым влияние на основные организационные системы, такие, как бухгалтерский учет и финансовая отчетность, маркетинг и отдел продаж, системы закупок и сбыта, производственные системы, системы трудовых ресурсов и другие.
Со временем системы интранет на основе Web станут основными техническими средствами, посредством которых будет осуществляться внутренняя деятельность организаций по выполнению бизнес-процессов.
Системы интернет
Системы интернет являются публичными информационными системами. Они включают в себя публичные сайты, которые предоставляют новости, информацию, и развлечения; сайты электронной коммерции для маркетинга и продажи продуктов и услуг; правительственные сайты для информирования или обслуживания широкой публики; и образовательные сайты для предоставления локального и удаленного доступа к образованию и знаниям. Всем частям общества публичные системы интернет предоставляют товары, услуги и информацию посредством Всемирной паутины WWW и связанных с ней сетей и услуг.
Системы экстранет
Системы экстранет являются системами бизнес-для-бизнеса (B2B), которые управляют электронным обменом данными (EDI) между деловыми предприятиями. Эти системы обеспечивают информационный поток между организациями – между компанией и ее поставщиками и между компанией и ее сбытовыми организациями – чтобы помочь в координации последовательности закупки, производства и распространения. Электронный обмен данными помогает исключить бумажный поток, сопровождающий бизнес-транзакции, используя технологии Web для пересылки электронных документов между компьютерами, а не между людьми.
Так как эти системы основаны на Web приложениях, то это автоматически устраняет трудности передачи информации между различными программными и аппаратными платформами с изначально различными информационными форматами и различными протоколами обмена информацией, так как для Web сетей такое взаимодействие планировалось изначально.
Web становится основным технологическим базисом, электронной магистралью для сбора информации, обработки и распространения во всех типах организаций – в коммерческих и финансовых предприятиях, образовательных учреждениях, правительственных агентствах, учреждениях здравоохранения, агентствах новостей и отрасли развлечений и в большинстве других формальных организаций, как больших, так и маленьких. Это всепроникающая технология для разработки систем работы с информацией во всех частях общества.
1.2.2. Что означает термин «системы на основе Web»
Термин «на основе Web» определяется тем фактом, что системы обработки информации базируются на технологии Интернет, в частности, на так называемой Всемирной паутине (WWW). Поэтому системы на основе Web действуют в технологических рамках со следующими характеристиками.
Системы действуют в публичных, а не в частных сетях данных. Они осуществляют коммуникацию через Интернет, т.е. через распространенные по всему миру, взаимосвязанные сети компьютеров, которые являются публично доступными.
Коммуникационные сети основываются на открытых и публичных технических стандартах, таких, как архитектуры Ethernet, протоколы передачи TCP/IP и протоколы приложений HTTP и FTP. Они не являются частными или патентованными стандартами, но являются принципиально открытыми и свободными для публичного использования.
Системы обработки на основе Web используют широко распространенное, часто бесплатное, программное обеспечение для разработки и работы. Деятельность по обработке происходит с помощью браузеров Web, а не специально написанного программного обеспечения для интерфейса пользователя и для внешнего сбора данных и обработки. Браузеры Microsoft Internet Explorer, Mozilla Firefox, Opera, Netscape Navigator и другие являются средством взаимодействия пользователей с системами обработки информации. Также широко распространенные компьютеры серверов Web выполняют основные функции бизнес-обработки, а серверы баз данных обеспечивают хранение информации, доступ к ней и извлечение.
Поэтому общедоступные, не являющиеся специализированными, не являющиеся патентованными оборудование и системы программного обеспечения предоставляют техническую среду для разработки систем обработки информации и для управления этой деятельностью.
14. Суть концепции «клиент-серверная архитектура» и обобщённая модель взаимодействия клиент/сервер.
1.2.3.Концепция клиент/серверной архитектуры
В предыдущем разделе были упомянуты термины серверы Web и серверы баз данных. Общее понятие сервера означает либо программу (комплекс программ), выполняющую определенную и достаточно сложную задачу управления каким-либо компьютерным процессом, представляющим интерес для пользователя, либо компьютер, на котором работает эта программа.
В этом случае можно дать такое определение: сервер - это компьютер, подключенный к локальной или глобальной сети, с установленным на нем соответствующим ПО, позволяющим отвечать на запросы и обслуживать другие серверы и клиентские компьютеры.
В принципе на одном компьютере может работать несколько «серверных» программ, но чаще крупные поставщики компьютерных услуг разделяют функции по разным аппаратам.
Под Web сервером понимают основную программу, которая обеспечивает работу Web сайта. Главная задача такого сервера - передача страниц сайта браузеру (программе на компьютере клиента) по протоколу HTTP. При необходимости сервер запускает скрипты для динамического создания страниц сайта. Действия сервера обычно протоколируются в логах (лог-файлах) и служат основанием для подсчета статистики сайта.
Под сервером баз данных понимают программу, позволяющую пользователю получать доступ к данным базы, манипулировать ими и структурой базы на специальном языке запросов к данным SQL.
Противоположным понятию сервера (и неразрывно с ним связанного) является понятие программы-клиента или компьютера-клиента.
Википедия даёт следующее определения этому понятию:
«Клиент — это аппаратный или программный компонент вычислительной системы, посылающий запросы серверу».
Программа, являющаяся клиентом, взаимодействует с сервером, используя определённый протокол (стандартизированные правила передачи и приёма). Она может:
Запрашивать с сервера какие-либо данные,
Манипулировать данными непосредственно на сервере,
Запускать на сервере новые процессы и т. п.
Полученные от сервера данные клиентская программа может предоставлять пользователю или использовать как-либо иначе, в зависимости от назначения программы.
Программа-клиент и программа-сервер могут работать как на одном и том же компьютере, так и на разных компьютерах. Во втором случае для обмена информацией между ними используется сетевое соединение.
Разновидностью клиентов являются терминалы - рабочие места на многопользовательских ЭВМ, оснащённые монитором с клавиатурой, и не способные работать без сервера.
Тем не менее, не всегда под клиентом подразумевается компьютер со слабыми вычислительными ресурсами. Чаще всего понятия «клиент» и «сервер» описывают распределение ролей при выполнении конкретной задачи, а не вычислительные мощности. На одном и том же компьютере могут одновременно работать программы, выполняющие как клиентские, так и серверные функции. Например, Web сервер может в качестве клиента получать данные для формирования страниц от SQL сервера.
Понятия сервер и клиент и закрепленные за ними роли образуют программную концепцию «клиент/сервер».
Для взаимодействия с клиентом (или клиентами, если поддерживается одновременная работа с несколькими клиентами) сервер выделяет необходимые ресурсы межпроцессного взаимодействия (например, разделяемая память) и ожидает запросов на открытие соединения (или, собственно, запросов на предоставляемый сервис). В зависимости от типа такого ресурса, сервер может обслуживать процессы в пределах одной компьютерной системы или процессы на других машинах через каналы передачи данных (например, COMM-порт) или сетевые соединения.
Формат запросов клиента и ответов сервера определяется протоколом.
Более точное понимание концепции «клиент/сервер» может быть достигнуто через рассмотрение моделей «клиент/серверного» взаимодействия.
1.2.4. Обобщенная модель взаимодействия «клиент/сервер»
В настоящее время существуют двух- и трёхзвенные модели взаимодействия (иногда термин «звено» заменяют термином «слой»). Компанией Gartner Group, специализирующейся в области исследования информационных технологий, предложена следующая классификация двухзвенных моделей взаимодействия «клиент/сервер» (двухзвенными эти модели называются потому, что три компонента приложения различным образом распределяются между двумя компьютерными узлами) – Рис. 1-1:

Рис. 1‑1. Схематическое представление возможного распределения разных элементов обработки данных на компьютере пользователя (над диагональю) и компьютере-сервере (под диагональю)
Показанная схема модифицировалась параллельно с развитием вычислительной техники, в том числе и технологий межкомпьютерной связи.
Исторически первой появилась модель распределенного представления данных, которая реализовывалась на универсальной ЭВМ с подключенными к ней неинтеллектуальными терминалами. Управление данными и взаимодействие с пользователем при этом объединялись в одной программе, на терминал передавалась только «картинка», сформированная на центральном компьютере.
Затем, с появлением персональных компьютеров (ПК) и локальных сетей, были реализованы модели доступа к удаленной базе данных. Некоторое время базовой для сетей ПК была архитектура файлового сервера. При этом один из компьютеров является файловым сервером, на клиентах выполняются приложения, в которых совмещены компонент представления и прикладной компонент (СУБД и прикладная программа). Протокол обмена при этом представляет набор низкоуровневых вызовов операций файловой системы. Такая архитектура, реализуемая, как правило, с помощью персональных СУБД, имеет очевидные недостатки - высокий сетевой трафик и отсутствие унифицированного доступа к ресурсам.
С появлением первых специализированных серверов баз данных появилась возможность другой реализации модели доступа к удаленной базе данных. В этом случае ядро СУБД функционирует на сервере, протокол обмена обеспечивается с помощью языка SQL. Такой подход по сравнению с файловым сервером ведет к уменьшению загрузки сети и унификации интерфейса «клиент/сервер». Однако сетевой трафик остается достаточно высоким, кроме того, по-прежнему невозможно удовлетворительное администрирование приложений, поскольку в одной программе совмещаются различные функции.
Позже была разработана концепция активного сервера, который использовал механизм хранимых процедур. Это позволило часть прикладного компонента перенести на сервер (модель распределенного приложения). Процедуры хранятся в словаре базы данных, разделяются между несколькими клиентами и выполняются на том же компьютере, что и SQL сервер. Преимущества такого подхода: возможно централизованное администрирование прикладных функций, значительно снижается сетевой трафик (т.к. передаются не SQL запросы, а вызовы хранимых процедур). Недостаток - ограниченность средств разработки хранимых процедур по сравнению с языками общего назначения (C, C++, С#, PHP и т.д.).
На практике сейчас обычно используются смешанный подход:
простейшие прикладные функции выполняются хранимыми процедурами на сервере,
более сложные функции реализуются на клиенте непосредственно в прикладной программе,
В последние годы начала реализовываться концепция «тонкого клиента», функцией которого остается только отображение данных (модель удаленного представления данных).
В компьютерных технологиях терминал или тонкий клиент (англ. thin client) - это компьютер-клиент сети с архитектурой «клиент/сервер», который переносит большинство задач по обработке информации на сервер.
Таким образом, сервер необходим для нормальной работы терминала. Этим терминал (тонкий клиент) отличается от толстого клиента, который, напротив, производит обработку информации независимо от сервера, используя последний в основном лишь для хранения данных. Примером подобного терминала (тонкого клиента) может служить компьютер с браузером, использующийся для работы с Web приложениями.
Терминальный сервер - также сервер терминалов, предоставляющий клиентам вычислительные ресурсы (процессорное время, память, дисковое пространство) для решения задач. Технически, терминальный сервер представляет собой очень мощный компьютер (либо кластер), соединенный по сети с терминальными клиентами, которые, как правило, представляют собой маломощные или устаревшие рабочие станции. Построение сетевой инфраструктуры на базе терминалов (тонких клиентов) осуществляется с использованием терминального сервера, на котором и происходит обработка информации.
В последнее время также наблюдается тенденция к большему использованию модели распределенного приложения. Характерной чертой таких приложений является логическое разделение приложения на две или более части, каждая из которых может выполняться на отдельном компьютере. Выделенные части приложения взаимодействуют друг с другом, обмениваясь сообщениями в заранее согласованном формате. В этом случае двухзвенная архитектура клиент/сервер становится трехзвенной, а в некоторых случаях, она может включать и больше звеньев (смотри Рис. 1-1).

Рис. 1‑1. Схематическое изображение трёхзвенной архитектуры
15.Содержание понятий «аппаратные и программные слои» трёхслойной системы обработки информации и распределение функций по обработке информации между ними.
1.2.5. Трехслойная модель клиент/серверной архитектуры для Web приложений и задачи его разработки
Термин «клиент/сервер» относится к применению сетей на основе серверов (то есть программ) для управления общим доступом к ресурсам и для распределения задач между аппаратными и программными компонентами. В сетях «клиент/сервер» на основе Web распределение задач обработки происходит в трех слоях, которые соответствуют трем основным компонентам оборудования и программного обеспечения системы (Рис. 1-1).

Рис. 1‑1. Аппаратные и программные слои трехслойной системы обработки информации
В первом слое клиентский настольный ПК выполняет работу интерфейса пользователя системы; во втором слое сервер Web выполняет основные функции системы по обработке; и в третьем слое сервер базы данных, и в некоторых случаях медиа-сервер, осуществляет требуемые системе функции хранение и извлечения информации.
В свою очередь, каждый из трех аппаратных компонентов содержит соответствующее программное обеспечение. Клиентским программным обеспечением является браузер Web. Сервер Web выполняет сетевую операционную систему (NOS), такую, как Windows Server, Unix Server или Linux Server, и с помощью дополнительного программного обеспечения, например, Internet Information Server или Apache Web Server, реализует службы Интернет, — WWW, FTP, SMTP (Simple Mail Transfer Protocol) и другие. Сервер базы данных выполняет команды размещённой на нём системы управления базой данных, таких, как MySQL, Oracle, Microsoft SQL Server, Access и других популярных пакетов.
Таким образом, отдельные компоненты выполняют отдельные задачи обработки, которые интегрируются с помощью Web в законченную систему обработки информации.
Рассмотрим, например, посещение Web сайта электронной коммерции (е-коммерции). Браузер Web является интерфейсом работы с сайтом. В ответ на различные «входящие» запросы, которые вы отправляете при просмотре продаваемых товаров, создаются различные страницы «вывода». Запросы вводятся в систему через ссылки Web и посылаемые формы, ответы системы создают страницы HTML, передаваемые назад браузеру для вывода на экране. Браузер выполняет действия по вводу и выводу, необходимые для взаимодействия с сайтом.
При этом на Web сервере решаются специальные задачи по обработке информации. При запросе клиента по поиску товара, выполняются программы поиска в базах данных для извлечения подходящего для клиента товара и для форматирования вывода для доставки в браузер Web. При просмотре корзины покупателя другие процедуры извлекают выбранные товары и вычисляют общую стоимость заказа. При оплате заказа исполняются специальные программы для соединения с системой проверки кредитной карты и банковскими системами, так что соответствующие счета дебетуются и кредитуются.
Множество задач обработки, связанных с перемещением в сети и покупкой, происходят на серверах Web скрыто от пользователя, но они критически важны для осуществления покупки и для осуществления бизнес-транзакций, которые с этим связаны.
Большая часть информации, которая собирается и генерируется во время покупки, хранится в базах данных, которые находятся на отдельных серверах баз данных. Вся информация, которая выводится на экран, извлекается из таблиц базы данных. Выбранные товары хранятся в таблицах базы данных. Практически каждый фрагмент информации о просматриваемых продуктах и транзакциях при покупке сохраняется в больших базах данных в самой системе е-коммерции или в связанных базах данных, которые находятся в центре окружающих ее систем бухгалтерского учета, закупок и дистрибуции.
Даже в самых маленьких коммерческих системах на основе Web присутствуют такие же функции. Главное состоит в том, что в системах на основе Web любого размера существуют три основных слоя функциональности. Поэтому, с точки зрения разработчика Web, задача разработки полноценного приложения состоит в создании:
интерфейса пользователя,
процедур обработки бизнес-операций,
компонентов поддержки базы данных и, наконец,
последующей интеграции в полностью функциональную систему обработки информации.