

Рихтер Дж., Назар К. - Windows via C C++. Программирование на языке Visual C++ - 2009
.pdf258 Часть II. Приступаем к работе
процессорной машине поток, владеющий ресурсом, может выполняться на другом процессоре и очень быстро освободить ресурс. Тогда появляется вероятность, что ресурс будет освобожден еще до того, как вызывающий поток завершит переход в режим ядра. В итоге уйма процессорного времени будет потрачена впустую.
Microsoft повысила быстродействие критических секций, включив в них спинблокировку. Теперь, когда вы вызываете EnterCriticalSection, она выполняет заданное число циклов спин-блокировки, пытаясь получить доступ к ресурсу. И лишь в том случае, когда все попытки заканчиваются неудачно, функция переводит поток в режим ядра, где он будет находиться в состоянии ожидания.
Для использования спин-блокировки в критической секции нужно инициализировать счетчик циклов, вызвав:
BOOL InitializeCriticalSectionAndSpinCount(
PCRITICAL_SECnON pcs,
DWORD dwSpinCount);
Как и в InitializeCriticalSection, первый параметр этой функции — адрес структуры критической секции. Но во втором параметре, dwSpinCount, передается число циклов спин-блокировки при попытках получить доступ к ресурсу до перевода потока в состояние ожидания. Этот параметр может принимать значения от 0 до 0x00FFFFFF. Учтите, что на однопроцессорной машине значение параметра dwSpinCount игнорируется и считается равным 0. Дело в том, что применение спин-блокировки в такой системе бессмысленно: поток, владеющий ресурсом, не сможет освободить его, пока другой поток «крутится» в циклах спин-блокировки.
Вы можете изменить счетчик циклов спин-блокировки вызовом:
DWORD SetCriticalSectionSpinCount(
PCRITICAL_SECTION pcs,
DWORD dwSpinCount);
И в этой функции значение dwSpinCount на однопроцессорной машине игнорируется.
На мой взгляд, используя критические секции, вы должны всегда применять спин-блокировку — терять вам просто нечего. Могут возникнуть трудности в подборе значения dwSpinCount, но здесь нужно просто поэкспериментировать. Имейте в виду, что для критической секции, стоящей на страже динамической кучи вашего процесса, этот счетчик равен 4000.
Критические секции и обработка ошибок
Вероятность того, что InitializeCriticalSection потерпит неудачу, крайне мала, но все же существует. В свое время Microsoft не учла этого при разработке функции и определила ее возвращаемое значение как VOID, т. е. она ничего не возвращает. Однако функция может потерпеть неудачу, так как выделяет
Глава 8. Синхронизация потоков в пользовательском режиме.docx 259
блок памяти для внутрисистемной отладочной информации. Если выделить память не удается, генерируется исключение STATUS_NO_MEMORY. Вы можете перехватить его, используя структурную обработку исключений (см. главы 23,24
и 25).
Есть и другой, более простой способ решить эту проблему — перейти на но-
вую функцию InitializeCriticalSectionAndSpinCount. Она, тоже выделяя блок памя-
ти для отладочной информации, возвращает FALSE, если выделить память не удается.
В работе с критическими секциями может возникнуть еще одна проблема. Когда за доступ к критической секции конкурирует два и более потока, она использует объект ядра «событие». Поскольку такая конкуренция маловероятна, система не создает объект ядра «событие» до тех пор, пока он действительно не потребуется. Это экономит массу системных ресурсов — в большинстве критических секций конкуренция потоков никогда не возникает. Кстати, этот объект ядра освобождается только при вызове DeleteCriticalSection. Так что не забывайте вызывать эту функцию, закончив операции в критической секции.
Раньше (до Windows XP) в случаях, когда в условиях нехватки памяти конкуренция потоков за критическую секцию все же возникала, системе не удавалось создать нужный объект ядра. И тогда EnterCriticalSection генерировала исключение EXCEPTION_INVALID_HANDLE. Большинство разработчиков просто игнорирует вероятность такой ошибки, и не предусматривает для нее никакой обработки, поскольку она случается действительно очень редко. Но если вы хотите заранее подготовиться к такой ситуации, у вас есть две возможности.
Первая — использовать структурную обработку исключений и перехватывать ошибку. При этом вы либо отказываетесь от обращения к ресурсу, защищенному критической секцией, либо дожидаетесь появления свободной памяти, а затем по-
вторяете вызов EnterCriticalSection.
Вторая возможность заключается в том, что вы создаете критическую секцию вызовом InitializeCriticalSectionAndSpinCount, передавая параметр dwSpinCount с
установленным старшим битом. Тогда функция создает объект «событие» и сопоставляет его с критической секцией. Если создать объект не удается, она возвращает FALSE, и это позволяет корректнее обрабатывать такие ситуации. Но успешно созданный объект ядра «событие» гарантирует вам, что EnterCriticalSection выполнит свою задачу при любых обстоятельствах и никогда не вызовет исключение. (Всегда выделяя память под объекты ядра «событие», вы неэкономно расходуете системные ресурсы. Поэтому делать так следует лишь в нескольких случаях, а именно: если программа может рухнуть из-за неудачного завершения функции EnterCriticalSection, если вы уверены в конкуренции потоков при обращении к критической секции или если программа будет работать в условиях нехватки памяти.)
В Windows XP появился новый тип объекта ядра «событие» — т. н. событие с ключом (keyed event). Оно предназначено как раз для решения
260 Часть II. Приступаем к работе
проблемы создания объектов в условиях нехватки памяти. Вместе с процессом операционная система всегда создает один такой объект, его легко найти с помо-
щью утилиты Process Explorer от Sysinternals (см. http://www.micwsoft.com/technet/sysinternals/utilities/ProcessExplorer.mspx; ищите объект \KernelObjects\CritSecOutOfMemoryEvent). Этот недокументированный объект ядра во всем похож на обычный объект «событие» за исключением одного. Он способен синхронизировать различные группы потоков, которые определяются и блокируются с помощью ключа (по сути, указателя). Если из-за нехватки памяти потоку, вошедшему в критическую секцию, не удается создать объект «событие», в качестве ключа используется адрес критической секции. Так что потоки, пытающиеся войти в данную конкретную критическую секцию, будут синхронизированы и, при необходимости, блокированы на этом объекте «событие с ключом».
«Тонкая» блокировка
У «тонкой» блокировки чтения и записи (slim reader-writer lock), называемой так-
же SRWLock, то же назначение, что и у обычной критической секции: защита ресурса от одновременного доступа разных потоков. Однако, в отличие от критической секции, SRWLock различает потоки, обращающиеся к ресурсу для чтения и для записи (т.е. читающие и записывающие потоки). SRWLock разрешает нескольким читающим потокам одновременно обращаться к ресурсу, поскольку чтение не грозит повреждением ресурса. Потребность в синхронизации возникает только при попытке потока модифицировать ресурс. В этом случае нужен монопольный доступ, то есть запрет обращения к ресурсу всем другим потокам, как записывающим, так и читающим. Именно это позволяет сделать SRWLock, причем без особого труда.
Сначала следует объявить структуру SRWLOCK и инициализировать ее вызо-
вом InitializeSRWLock:
VOID InitializeSRWLock(PSRWLOCK SRWLock);
Структура SRWLOCK определена как RTL_SRWLOCK в файле WinBase.h. В WinNT.h объявление этой структуры содержит лишь указатель, ссылающийся на что-то другое, незадокументированное и потому (в отличие от полей CRITICAL_SECTION) недоступное для использования в коде.
typedef struct _RTL_SRWLOCK { PVOID Ptr;
} RTL_SRWLOCK, *PRTL_SRWLOCK;
После инициализации SRWLock записывающий поток может попытаться получить монопольный доступ к ресурсу, защищенному SRWLock, вызвав функцию AcquireSRWLockExclusive и передав ей в качестве параметра адрес объекта
SRWLOCK:
VOID AcquireSRWLockExclusive(PSRWLOCK SRWLock);
Глава 8. Синхронизация потоков в пользовательском режиме.docx 261
После модификации ресурса блокировку освобождают вызовом ReleaseSRWLockExclusive с передачей в качестве параметра адреса объекта SRWLOCK:
VOID ReleaseSRWLockExclusive(PSRWLOCK SRWLock);
В случае читающего потока все аналогично, только используются другие функции:
VOID AcquireSRWLockShared(PSRWLOCK SRWLock);
VOID ReleaseSRWLockShared(PSRWLOCK SRWLock);
Вот и все. Функций для удаления и разрушения объектов SRWLOCK нет, поскольку система выполняет эти операции автоматически.
УSRWLock отсутствует ряд функций критической секции:
■Вызовы типа TryEnter(Shared/Exclusive)SRWLock невозможны, поскольку вызовы функций вида AcquireSRWLock(Shared/Exclusive) блокируют вызывающий поток, если у него уже есть блокировка.
■Невозможно также рекурсивное получение SRWLOCK, то есть один поток не может получить сразу несколько блокировок для многократной записи, а затем освободить их, вызвав соответствующее число раз функцию ReleaseSRWLock*.
Впрочем, если вы смиритесь с этими ограничениями, то получите реальный
прирост производительности, заменив критические секции блокировками SRWLock. Чтобы убедиться в том, что эти механизмы сильно различаются по скорости работы, запустите на многопроцессорной машине проект 08UserSyncCompare, доступный на веб-сайте поддержки этой книги.
Эта простая программа порождает один, два или четыре потока, повторно исполняющих одну и ту же задачу с использованием различных механизмов синхронизации. Я прогнал все тесты на своем двухпроцессорном компьютере и записал затраченное время. Результаты показаны в табл. 8-2.
Табл. 8-2. Сравнение производительности различных механизмов синхронизации
|
|
|
Время (мс) |
|
|
|
||
Число |
Чтение без син- |
Запись без син- |
Приращение |
SRWLock |
SRWLock |
(общий |
|
|
потоков |
критическая |
(общий |
Мьютекс |
|||||
хронизации |
хронизации |
(Interlocked) |
доступ) |
|||||
|
секция |
доступ) |
|
|||||
|
|
|
|
|
|
|||
1 |
8 |
8 |
35 |
66 |
66 |
67 |
1060 |
|
2 |
8 |
76 |
153 |
268 |
134 |
148 |
11082 |
|
4 |
9 |
145 |
361 |
768 |
244 |
307 |
23785 |
|
В ячейках табл. 8-2 показано время (в мс; измерено с помощью класса StopWatch, показанного в главе 7), прошедшее от запуска потоков до завершения исполнения последним потоком 1000000 следующих операций:
262 Часть II. Приступаем к работе
■ Чтение (без синхронизации) значения типа long:
LONG lValue = gv_value;
Эта операция — самая быстрая, поскольку не требует синхронизации и кэшпамять у разных процессоров работает независимо. Обычно такой тест занимает примерно одинаковое время независимо от числа процессоров или потоков.
■ Запись (без синхронизации) значения типа long:
gv_value = 0;
Если используется один поток, операция занимает столько же времени — 8 мс. Можно думать, что в случае двух потоков время исполнения этой операции просто удвоится, но на деле двухпроцессорный компьютер тратит на нее намного больше времени (76 мс). Причина — в необходимости взаимодействия процессоров для поддержания когерентности кэша. При увеличении числа потоков до четырех время операции увеличивается почти вдвое (до 145 мс) просто за счет удвоения нагрузки. Однако затраты времени увеличиваются не так сильно, как могло бы, поскольку для обработки данных используется лишь два процессора. Чем больше процессоров в компьютере, тем сильнее снижается быстродействие, поскольку с числом процессоров увеличивается и объем взаимодействия, необходимый для поддержания когерентности кэша у каждого из процессоров.
■Безопасное приращение long-значения с помощью функции InterlockedIncrement.
InterlockedIncrement(&gv_value);
InterlockedIncrement работает медленнее, чем чтение-запись без синхронизации. Дело в том, что при этом процессор должен заблокировать доступ к соответствующей области памяти, чтобы предотвратить обращение к ней других процессоров. Использование двух потоков еще больше замедляет эту операцию, поскольку процессорам приходится обмениваться данными для поддержания когерентности кэша. В случае с четырьмя потоками быстродействие снижается пропорционально объему вычислений, которые, правда, выполняются двумя процессорами. Вероятно, на четырех-процессорной машине производительности снизится еще сильнее, поскольку в синхронизации кэша нуждаются уже четыре процессора.
■ Чтение long-значения с использованием критической секции:
EnterСriticalSection(&g_cs); gv_value = 0; LeaveCriticalSection(&g_cs);
Критические секции еще медленнее, поскольку поток должен входить и выходить из них, то есть выполнять две дополнительные операции. Кроме того, во время этих операций происходит модификация множес-
Глава 8. Синхронизация потоков в пользовательском режиме.docx 263
тва полей структуры CRITICAL_SECTION. При возникновении конкуренции работа критических секций замедляется еще сильнее, как видно из табл. 8-2. Так, обработка с четырьмя потоками занимает 768 мс, то есть затраченное время увеличивается более чем вдвое по сравнению с двумя потоками (268 мс) по причине переключения контекста, повышающего вероятность конкуренции.
■ Чтение long-значения с помощью SRWLock:
AcquireSRWLockShared/Exclusive(&g_srwLock); gv_value = 0; ReleaseSRWLockShared/Exclusive(&g_srwLock);
Скорость чтения и записи с использованием SRWLock практически не отличается, если эти операции выполняет единственный поток. Производительность чтения с участием двух потоков при использовании SRWLock несколько выше, чем записи, поскольку оба потока могут читать ресурс одновременно, а записывать — только по очереди. При использовании четырех потоков чтение с использованием SRWLock работает заметно быстрее записи. Причина та же: все потоки могут читать ресурс одновременно. Результаты теста могут показаться неожиданно низкими (см. табл. 8-2), но в нем используется простой код, который мало что делает после установки блокировки. При этом поля блокировки и данные, которые она изменяет, непрерывно модифицируютсянесколькими потоками, в результате процессорам приходится обмениваться данными для синхронизации кэша.
■Использование синхронизирующего объекта ядра «мьютекс» (см. главу 9) для чтения long-значения:
WaitForSingleObject(g_hMutex, INFINITE); gv_value = 0;
ReleaseMutex(g_hMutex);
Мьютексы намного медленнее остальных механизмов из-за необходимости ожидания этого объекта. Кроме того, для освобождения мьютексов поток должен каждый раз переключаться из режима пользователя в режим ядра и обратно, что отнимает уйму процессорного времени. Конкуренция, возникающая при наличии двух и более потоков, снижает производительность еще сильнее.
Производительность SRWLock вполне сравнима с производительностью критической секции. Более того, результаты теста показывают, что во многих случаях SRWLock работает быстрое критической секции, поэтому я рекомендую использовать именно ее. Кроме того, SRWLock поддерживает одновременное чтение ресурсов несколькими потоками, что повышает общую скорость работы и масштабируемость в отношении числа читающих потоков (как правило, их в приложениях большинство).
264Часть II. Приступаем к работе
Взаключение я кратко расскажу, как добиться максимальной производительности приложений. Для начала попытайтесь обойтись вовсе без разделяемых ресурсов. Если это невозможно, используйте (в порядке предпочтительности) чте- ние-запись без синхронизации, interlocked-функции, SRWLock-блокировки либо критические секции. И только если ни один из этих механизмов не подходит для ваших задач, прибегайте к синхронизирующим объектам ядра (о них — в следующей главе).
Условные переменные
Из сказанного выше ясно, что SRWLock применяют в случаях, когда возможен одновременный доступ к ресурсу читающих потоков (потоков-потребителей данных), а записывающему потоку (потоку-создателю данных) требуется только монопольный доступ. Возможны ситуации, когда данные для потока-потребителя еще не готовы, и тогда он должен освободить блокировку и ждать, пока потоксоздатель не запишет в ресурс какие-нибудь данные. Если записывающий поток «под завязку» заполнил своими данными структуру, играющую роль приемника данных, он также должен освободить блокировку и «заснуть», пока читающие потоки не опустошат структуру-приемник.
Условные переменные (condition variables) облегчают жизнь разработчика при реализации сценариев, в которых необходимо заставить поток атомарно освободить блокировку ресурса, а после заблокировать его при помощи показанных ни-
же функций SleepConditionVariableCS или SleepConditionVariableSRW, пока не бу-
дет выполнено некоторое условие.
BOOL SleepConditionVariableCS(
PCONDITION_VARIABLE pConditionVariable,
PCRITICAL_SECTION pCriticalSection,
DWORD dwMilllseconds);
BOOL SleepConditionVariableSRW(
PCONDITION_VARIABLE pConditionVariable,
PSRWLOCK pSRWLock,
DWORD dwMilliseconds,
ULONG Flags);
Параметр pConditionVariable — это указатель на инициализированную условную переменную, на которой ожидает поток. Второй параметр — указатель на критическую секцию либо SRWLock, применяемую для синхронизации доступа к разделяемому ресурсу. Параметр dwMilliseconds указывает, как долго вызывающий поток должен ждать момента, когда условная переменная примет нужное значение (ожидание будет бесконечным, если передать значение INFINITE). Параметр Flags второй функции определяет, какую блокировку следует установить, когда условная переменная получит значение, заданное условием. Чтобы установить монопольную блокировку
Глава 8. Синхронизация потоков в пользовательском режиме.docx 265
(для записывающего потока), передайте 0; чтобы разрешить совместный доступ (читающим потокам), передайте значение CONDITION_VARIABLE_LOCKMODE_SHARED. Эти функции возвращают FALSE, если период ожидания истек, а условной переменной так и не присвоено заданное значение; в противном случае возвращается TRUE. Естественно, ни блокировка, ни критическая секция не создается, если функция вернула FALSE.
Поток, заблокированный в этих Sleep-функциях, пробуждается, если другой поток вызывает функцию WakeConditionVariable или WakeAllConditionVariable и
выполненная в результате вызова проверка подтвердит выполнение некоторого условия. Для потока-потребителя таким условием может быть наличие данных, записанных потоком-создателем, а для потока-создателя — наличие свободного места в структуре-приемнике данных. Разберем, чем отличаются эти функции:
VOID WakeConditionVariable(
PCONDITION_VARIABLE ConditionVariable);
VOID WakeAllConditionVariable(
PCONDITION_VARIABLE ConditionVariable);
При вызове WakeConditionVariable поток, ожидающий переменной, заданной при вызове SleepConditionVariable*, пробуждается с установкой соответствующей блокировки. Когда данный поток освободит эту блокировку, не проснется ни один из других потоков, спящих в ожидании той же самой условной переменной. Напротив, при вызове WakeAllConditionVariable просыпаются все потоки, ожидающие одной и той же условной переменной, заданной при вызове SleepConditionVariable*. Это допустимо, поскольку в каждый момент времени только один записывающий поток может владеть монопольной блокировкой (если вы запросили такую блокировку). Либо, если в параметре Flag передано значение
CONDITION_VARIABLE_LOCKMODE_SHARED, будет установлена блокиров-
ка, разрешающая всем потокам совместный доступ для чтения. Таким образом, в одних случаях просыпаются сразу все читающие потоки, либо сначала просыпается один читающий поток, затем один записывающий и т.д., пока каждый из заблокированных потоков не завладеет блокировкой. Те, кто работают с Microsoft
.NET Framework, могут заметить сходство между классом Monitor и условными переменными. Оба механизма обеспечивают синхронизацию доступа за счет ис-
пользования функций SleepConditionVariable / Wait и Wake*ConditionVariable /
Pulse (All). Подробнее о классе Monitor см. на сайте MSDN
(http://msdn2.microsoft.com/en-us/library/hf5de04k.aspx) либо в моей книге CLR via
C#. Программирование на платформе Microsoft .NET Framework 2.0 на языке C#, Русская редакция, Питер, 2006-2007.
Приложение-пример Queue
Условные переменные всегда используют вместе с блокировками» реализованными с помощью критических секций либо SRWLock. В приложении
266 Часть II. Приступаем к работе
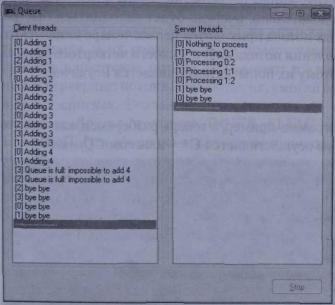
Queue (08-Queue.exe) для управления очередью запросов используется SRWLock и две условные переменные. Его исходный код и файлы ресурсов находятся в разделе 08-Queue на веб-сайте поддержки данной книги (см. выше). Если запустить это приложение и щелкнуть кнопку Stop, спустя некоторое время откроется следующее окно:
При инициализации Queue создается четыре клиентских потока (это записывающие потки) и два серверных (эти потоки являются читающими). Клиентские потоки помещают в очередь элементы-запросы, затем на некоторое время засыпают и, пробудившись, снова пытаются добавить запросы в очередь. После добавления элементов в очередь обновляется список Client Threads. Каждый элемент очереди содержит номер добавившего его клиентского потока. Например, первый элемент списка добавляет клиентский поток с номером 0, за ним добавляют свои элементы клиентские потоки 1,2 и 3, далее поток 0 помещает свой второй запрос и все повторяется.
Серверные потоки отвечают за обработку запросов. Серверный поток с номером 0 обрабатывает запросы с четными номерами, а поток номер 1 — запросы с нечетными номерами. Пока очередь пуста, потоки простаивают. Как только в очереди появляется хотя бы один элемент, пробуждается соответствующий серверный поток и обрабатывает его. При этом серверный поток помечает элемент очереди как прочитанный, уведомляет клиентские потоки о том, что они могут добавить в очередь новые элементы и засыпают до появления подходящих для него запросов.
Список Server Threads отображает состояние серверных потоков. Как видно из первой записи в списке, поток 0 пытался (безуспешно) найти запрос с четным номером. Вторая запись говорит, что серверный поток номер 1 обработал первый запрос, созданный клиентским потоком с номером 0.

Глава 8. Синхронизация потоков в пользовательском режиме.docx 267
Третья запись показывает, что серверный поток 0 обработал второй запрос клиентского потока 0 и т.д. После щелчка кнопки Stop потоки уведомляются о необходимости остановки и добавляют в свои списки записи «bye bye».
В этом примере серверные потоки недостаточно быстро обрабатывают клиентские запросы, поэтому через некоторое время очередь заполняется. Я инициализировал структуру данных очереди так, чтобы в ней умещалось не более 10 элементов, следовательно, очередь будет заполняться быстро. Кроме того, на два серверных потока приходится целых четыре клиентских. Видно, что к моменту добавления потоками 3 и 2 своего четвертого запроса очередь уже заполнена, поэтому их попытка заканчивается неудачей.
Реализация Queue
Вы увидели, что делает программа-пример, а теперь разберемся, как оно это делает. Управление очередью осуществляется С++-классом CQueue:
class CQueue
{
public:
struct ELEMENT {
int n_nTnreadNum; int m_nRequestNum;
// здесь должны быть другие элементы данных
};
typedef ELEMENT* PELEMENT;
private: |
|
|
struct INNER_ELEMENT { |
|
|
int |
m_nStamp; |
// 0 = пусто |
ELEMENT m_element; |
|
|
}; |
|
|
typedef INNER_ELEMENT* PINNER_ELEMENT; |
|
|
private: |
|
|
PINNER_ELEMENT m_pElements; |
// массив элементов, подлежащих |
|
|
|
// обработке |
int |
m_nMaxElements; |
// максимальное число элементов |
|
|
|
|
|
// в массиве |
int |
m_nCurrentStamp; |
// число добавленных элементов |
private:
int GetFreeSlot();
int GetNextSlot(int nThreadNum);
public:
CQueue(int nMaxElements);