

Организация ЭВМ и систем 2 курс 2 семестр / УМК_Орг_ЭВМ / Лек2_ОЭВМ
.docТема 2. Основные стадии выполнения команды
1. Лекция 2.
1. Общие сведения об архитектуре и принципах организации вычислительного процесса в современных ВМ.
2. Архитектура системы команд.
2. Лекция 3. Программирование на языке ассемблера.
1. Синтаксис ассемблера
2. Операнды
3. Виды адресации ассемблера
3. Лекция 4. Программирование на языке ассемблера.
1. Команды пересылки данных.
2. Ввод из порта и вывод в порт.
3. Команды работы с адресами памяти.
4. Команды работы со стеком.
1. Общие сведения об архитектуре принцип организации вычислительного
процесса в современных ВМ
Хабовая архитектура (рис.1).
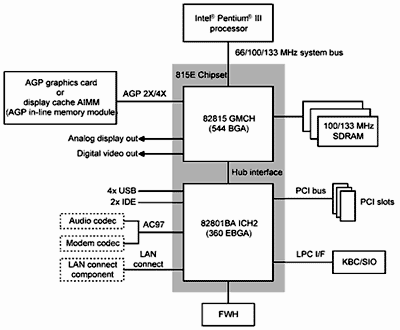
Рис. 1.
GMCH-микросхема Intel 82815 – это головной хаб чипсета. В ней интегрированы:
контроллер системной шины;
контроллер SDRAM-памяти, поддерживающий несколько спецификаций памяти;
контроллер AGP-шины – поддерживает универсальный AGP-слот (AGP Universal Connector), обеспечивая при этом обмен данными с установленной в него картой в соответствии с предусмотренной спецификацией;
графический контроллер (графический 3D-ускоритель с аппаратной поддержкой билинейной/трилинейной/анизотропной фильтрации при работе с 3D-графикой и алгоритмов motion compensation при MPEG/DVD-декодировании; имеет встроенный 230-мегагерцевый ЦАП; оснащен интерфейсом Digital Video Out;
контроллер локальной видеопамяти (в документации может называться двояко — как Local Graphics Memory Controller или как Display Cache);
контроллер хабовой шины (Hub Interface) — используется для передачи данных между MCH и ICH2. Изготавливается GMCH в виде 544-контактной BGA-микросхемы.
ICH2 — это хаб подсистемы ввода/вывода. В него встроены:
контроллер PCI-шины (соответствует спецификации PCI 2.2, поддерживает, помимо самого ICH2, до 6 PCI Bus Master-устройств);
IDE-контроллер (два Ultra ATA/100 канала — поддержка до четырех IDE-устройств);
LAN-контроллер (соответствует спецификации WfM 2.0);
два USB-контроллера (UHCI-реализация; каждый контроллер имеет два USB-порта, в сумме — четыре USB-порта);
контроллер AC'97 (имеет интерфейс AC’97 Digital Link, через который может подключаться аудио кодек AC’97, или модемный кодек AC’97, или аудио/модемный кодек AC’97, или одновременно два кодека — аудио AC’97 и модемный AC’97);
контроллер прерываний;
LPC-контроллер;
Enhanced DMA-контроллер;
RTC-контроллер (Real-Time Clock);
контроллер SMBus.
«Бриджевая» (мостовая) архитектура (рис. 2).
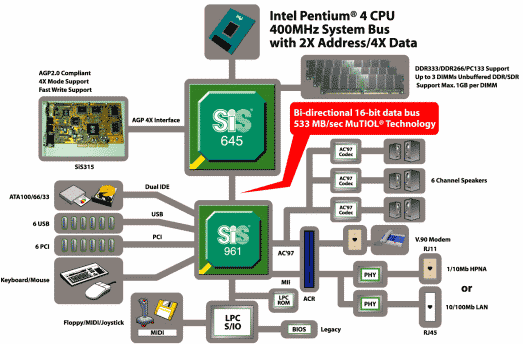
Рис. 2.
Данный набор микросхем построен в соответствии с классической двухмостовой архитектурой.
Северный мост SiS 645 имеет контроллер системной шины, обеспечивающий работу с шиной процессора Intel Pentium 4, контроллер памяти, поддерживающий работу с SDRAM-памятью и AGP-контроллер, обеспечивающий работу графической подсистемы. Для реализации высокоскоростного обмена в чипсете реализован координатор транзакций, который реализует механизм предвыборки при чтении из основной памяти.
Южный мост SiS 645 предоставляет стандартный набор функциональных возможностей: двухканальный IDE-контроллер, шестиканальный аудиоконтроллер AC97, двухканальный USB-контроллер, сетевой контроллер.
Взаимодействие между мостами осуществляется по высокоскоростной двунаправленной шине, обеспечивающей пропускную способность 266 Мбайт/с в каждом из направлений.
Блок-схема процессора Intel Pentium 4 (рис.3)

Рис. 3.
Execution Trace Cache. Execution Trace Cache — это название и одновременно способ реализации L1-кэша инструкций в архитектуре NetBurst. Смысловое содержание этого термина можно перевести как «кэш трассировки выполняемых микроопераций».
В Execution Trace Cache хранятся микрооперации (µops), которые были получены в результате декодирования входного потока инструкций исполняемого кода и готовы для передачи на выполнение конвейеру.
Execution Trace Cache устроен таким образом, что вместе с кодом каждой микрооперации в нем хранятся результаты выполнения ветвей кода для этой микрооперации — в той же строке кэша (cache line), что и сама микрооперация. Это позволяет легко и своевременно выявлять микрооперации, которые никогда не будут выполнены, и быстро удалять их из L1-кэша инструкций, а также оперативно «вычищать» Execution Trace Cache от «лишних» микроопераций в случае обнаружения ошибочно предсказанного перехода. Последнее обстоятельство особенно важно, так как позволяет сократить общее время реинициализации конвейера после его остановки в результате выполнения перехода, который был «угадан» неправильно.
Rapid Execution Engine. Так, в архитектуре NetBurst назван блок выполнения арифметико-логических операций. Конструктив Rapid Execution Engine довольно оригинален: во-первых, он состоит из двух ALU-модулей, работающих параллельно; во-вторых, рабочая тактовая частота этих ALU-модулей в два раза выше тактовой частоты процессора — это достигается за счет регистрации как переднего, так и заднего фронта задающего тактового сигнала. Таким образом, каждый ALU-модуль способен выполнить до двух целочисленных операций за один рабочий такт процессора, а весь Rapid Execution Engine в целом — до четырех таких операций.
400 MHz System Bus. Физически системная шина у Intel Pentium 4 тактируется частотой в 100 МГц, однако благодаря использованию технологии Quad Pumping по этой шине передается четыре блока данных за один такт (аналогично тому, как это делается при передаче данных в режиме AGP 4X по AGP-шине). Так что эффективная рабочая частота системной шины у Intel Pentium 4 (которую также называют Quad Pumped Bus) составляет 400 МГц, а пропускная способность — 3,2 Гбайт/с.
Advanced Dynamic Execution. Advanced Dynamic Execution — это обобщенное название механизма динамического выполнения команд (dynamic execution), используемого в NetBurst, построенного на трех базовых концепциях: предсказание переходов (branch prediction), динамический анализ потока данных (dynamic data flow analysis) и спекулятивное выполнение инструкций (out-of-order execution). Аналогичный механизм, названный Dynamic Execution, используется в процессорах семейства P6, однако в Intel Pentium 4 он улучшен.
Так, например, емкость пула, в котором хранятся готовые для обработки инструкции (out-of-order instruction window), у Intel Pentium 4 увеличена до 126 инструкций — против 42 у процессоров семейства P6.
Кроме того, в Intel Pentium 4 интегрирован более совершенный механизм предсказания переходов и количество ошибочно предсказанных переходов у него в среднем на 33% меньше, чем у процессоров с архитектурой P6.
Advanced Transfer Cache. Под этим именем в архитектуре NetBurst «скрывается» L2-кэш процессора емкостью в 256 Кбайт. Ширина шины, по которой идет обмен данными между Advanced Transfer Cache и процессором, составляет 256 бит (32 байта), а ее тактовая частота совпадает с тактовой частотой ядра процессора.
Streaming SIMD Extensions 2 (SSE2). В Intel Pentium 4 также интегрирован набор из 144 новых SIMD-инструкций, получивший название Streaming SIMD Extensions 2 (сокращенно — SSE2), который добавлен к базовому набору SSE-инструкций, реализованному ранее в процессоре Intel Pentium III.
Из этих 144 инструкций 68 — расширяют возможности старых SIMD-инструкций по работе с целыми числами, а 76 — являются совершенно новыми. Среди последних — инструкции, позволяющие оперировать со 128-разрядными числами (как целыми, так и вещественными с двойной точностью).
Новые SSE2-инструкции были добавлены с той же целью, что и появившийся ранее набор SSE-инструкций — для увеличения производительности системы при обработке аудио- и видеоданных.
Этапы работы процессора
1.1
Нажатие клавиши с цифрой "2" приводит микропроцессор в состояние готовности и подает блоку предварительной выборки сигнал на запрос в системной памяти компьютера инструкции в отношении вновь поступивших данных, поскольку командная кэш-память такой инструкции не содержит.
1.2
Новая инструкция по работе с данными поступает из системной памяти компьютера через блок шины в микропроцессор и записывается в командную кэш-память, где ей присваивается код "2=X".
1.3.
Вслед за этим блок предварительной выборки запрашивает из кэш-памяти копию кода "2=X", которую направляет для дальнейшей обработки в блок декодировки.
1.4.
Блок декодировки раскодирует инструкцию "2=X", преобразуя ее в цепочку двоичных символов, которая пересылается в управляющий блок и в кэш данных, давая им указание о том, как с полученной инструкцией поступать дальше.
1.5.
Поскольку блоком декодировки принято решение о сохранении цифры 2 в кэш данных, управляющий блок выполняет соответствующую инструкцию для кода "2=X": цифре 2 в кэш-памяти данных присваивается адрес "Х", здесь она и будет находиться в ожидании дальнейших указаний.
2.1.
Нажав клавишу с цифрой "3", Вы дадите блоку предварительной выборки команду на запрос в системной памяти компьютера и в командной кэш-памяти инструкций о действиях в отношении вновь поступивших данных. Поскольку командная кэш-память таких инструкций не содержит, они поступят из системной памяти.
2.2.
Аналогично команде "2=X," новые инструкции по данным поступают из системной памяти компьютера в микропроцессор и записываются в командную кэш-память, где получают код адресации "3=Y".
2.3.
После этого копия кода "3=Y" поступает из командной кэш-памяти в блок предварительной выборки, откуда переправляется в декодирующий блок для дальнейшей обработки.
2.4.
Декодирующий блок раскодирует инструкцию "3=Y", преобразуя ее в цепочку двоичных символов, которую направляет в управляющий блок и в кэш-память данных, давая им указание о том, как с данной инструкцией поступать дальше.
2.5.
Поскольку декодирующий блок принимает решение о сохранении цифры 3 в кэш-памяти данных, то он выполняет соответствующую инструкцию для кода "3=Y": цифре 3 присваивается в кэш-памяти данных адрес "Y", где она, аналогично цифре 2, и будет находиться в ожидании дальнейших указаний.
3.1.
Нажатие клавиши со значком "+" заставляет блок предварительной выборки запросить из главной памяти компьютера и командной кэш-памяти инструкции в отношении вновь поступивших данных. Как и в предыдущих случаях, эти инструкции должны быть получены из системной памяти.
3.2.
Поскольку речь идет о не использовавшейся ранее инструкции, "плюс" поступает в микропроцессор из системной памяти компьютера и записывается в командную кэш-память с присвоением адресного кода "X+Y=Z", обозначающего операцию сложения.
3.3.
Вслед за этим блок предварительной выборки запрашивает из командной кэш-памяти копию кода "X+Y=Z" и пересылает ее блоку декодировки для дальнейшей обработки.
3.4.
Блок декодировки раскодирует инструкцию "X+Y=Z", преобразуя ее в цепочку двоичных символов, которую направляет в управляющий блок и в кэш-память данных, давая им указание о том, как с данной инструкцией поступать дальше. Одновременно арифметическое логическое устройство (ALU) получает указание на выполнение операции СЛОЖЕНИЯ.
3.5.
Управляющий блок расчленяет код, а арифметическое логическое устройство (ALU) выполняет по команде операцию СЛОЖЕНИЯ чисел, закодированных как "X" и "Y" и извлеченных из кэш-памяти данных. После этого ALU, "посовещавшись" со своими "партнерами" — регистрами, пересылает им полученное число 5 для записи по одному из адресов.
4.1.
После нажатия клавиши со значком "=" блок предварительной выборки в очередной раз проверяет командную кэш-память на предмет наличия инструкций, относящихся к вновь поступившим данным. Как и прежде, такие инструкции там отсутствуют.
4.2.
Инструкция для значка "=" поступает в микропроцессор из системной памяти компьютера через блок шины и записывается в командную кэш-память, получив код адресации "Print Z" ("отобразить на экране символ Z").
4.3.
Вслед за этим блок предварительной выборки запрашивает из командной кэш-памяти копию кода "Print Z", которую пересылает декодирующему блоку для дальнейшей обработки.
4.4.
Декодирующий блок раскодирует инструкцию "Print Z", преобразуя ее в цепочку двоичных символов, которая затем пересылается управляющему блоку с указанием на то, как с полученной инструкцией поступать дальше.
4.5.
Теперь, когда значение величины, представленной кодом Z, уже вычисленно и записано в позиции № 5 блока регистров, для завершения операции сложения 2+3 остается выполнить команду вывода содержания регистра 5 на экран дисплея. На этом работа микропроцессора заканчивается.
Блок шины: Блоком шины называется то место, куда поступают инструкции по пути от системной памяти к микропроцессору и обратно.
Командная кэш-память: Командная кэш-память — это своего рода встроенный "склад" команд, избавляющий микропроцессор от необходимости обращаться каждый раз к системной памяти за очередной инструкцией. Быстрый доступ к командной кэш-памяти существенно ускоряет процесс выполнения команд, "извлекаемых" оттуда блоком предварительной выборки, который их выстраивает в определенном порядке для последующей обработки.
Блок предварительной выборки: Исходя из содержания текущей команды или поставленной задачи, блок предварительной выборки определяет порядок запроса соответствующих данных и инструкций из командной кэш-памяти или системной памяти компьютера. По мере поступления инструкций, важнейшей задачей блока предварительной выборки становится их правильное "выстраивание" и пересылка в блок декодировки.
Блок декодировки: Функции блока декодировки полностью соответствуют его названию: он расшифровывает инструкции, преобразуя их со сложного языка ЭВМ в достаточно простой формат, понятный арифметическому логическому устройству (ALU) и регистрам. Таким образом повышается эффективность процесса обработки данных и команд.
Управляющий блок: Управляющий блок — один из наиболее важных компонентов микропроцессора, поскольку именно на нем лежит ответственность за весь ход процесса обработки данных. На основании инструкций, поступивших из блока декодировки, он генерирует управляющие сигналы, которые дают арифметическому логическому устройству (ALU) и регистрам указания о том, какие действия им надлежит выполнить, какие данные при этом задействовать и как поступить с полученным результатом. Управляющий блок обеспечивает правильное и своевременное выполнение всех операций.
Арифметическое логическое устройство (ALU): В ALU — "умном" компоненте микросхемы — проходит завершающий этап процесса обработки данных и команд: выполнение операций сложения, вычитания, умножения и деления. Кроме того, ALU знает, что означают логические команды — такие, как ИЛИ, И, НЕТ. Сообщения, поступающие из управляющего блока, указывают ALU, что ему надлежит делать, а для выполнения поставленной задачи устройство пользуется данными, которыми его снабжают ближайшие "сотрудники" — регистры. В нашем примере, именно здесь и осуществляется сама операция сложения чисел 2 и 3.
Регистры: Регистрами называется тот "мини-склад", где хранятся данные, используемые арифметическим логическим устройством (ALU) при выполнении задач согласно указаниям, полученным из управляющего блока. Данные, поступающие сюда из кэш-памяти данных, системной памяти или управляющего блока, хранятся в особых местах, выделяемых регистрами с тем, чтобы ALU могло их извлечь быстро и эффективно.
Кэш-память данных: Кэш-память данных работает в очень тесном сотрудничестве со своими "партнерами" — ALU, регистрами и блоком декодировки. Здесь ALU сохраняет для последующей обработки особо отмеченные данные, поступившие из блока декодировки, а кроме того, здесь готовится конечный результат для его дальнейшей передачи различным компонентам компьютера.
Системная память: А это уже большой "склад" данных, который входит в состав компьютерной системы, но располагается вне микропроцессора. Системная память периодически направляет блоку предварительной выборки данные или инструкции, которые нередко сохраняются по определенным адресам в командной кэш-памяти для последующего использования.
2. Архитектура системы команд
Системой команд вычислительной машины называют полный перечень команд, которые способна выполнять данная ВМ. В свою очередь, под архитектурой системы команд (АСК) принято определять те средства вычислительной машины, которые видны и доступны программисту. АСК можно рассматривать как линию согласования нужд разработчиков программного обеспечения с возможностями создателей аппаратуры вычислительной машины (рис. 4).

Рис. 4.
В истории развития вычислительной техники как в зеркале отражаются изменения, происходившие во взглядах разработчиков на перспективность той или иной архитектуры, системы команд. Сложившуюся на настоящий момент ситуацию в области АСК иллюстрирует рис. 5.
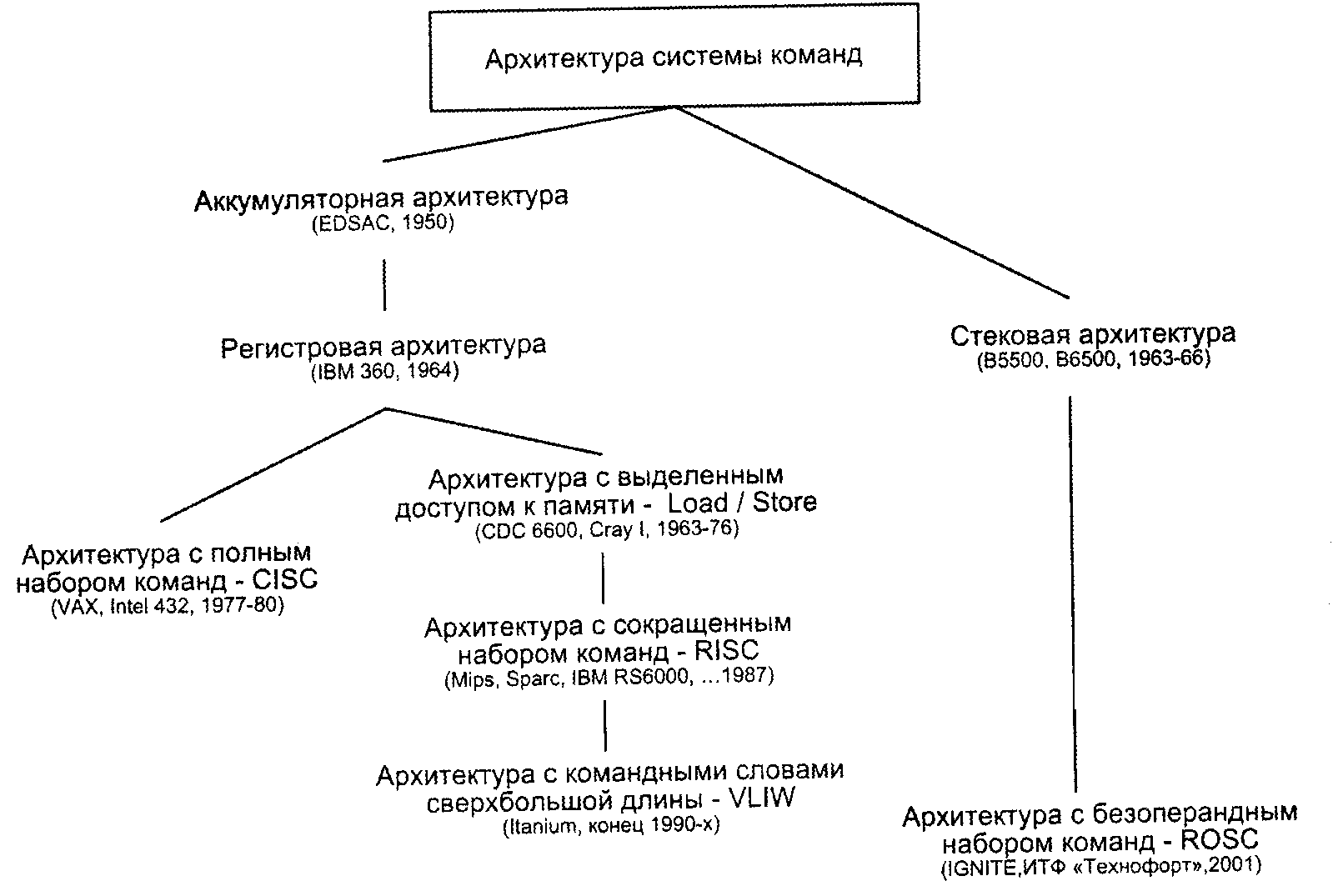
Среди мотивов, чаще всего предопределяющих переход к новому типу АСК, остановимся на двух наиболее существенных. Первый — это состав операций, выполняемых вычислительной машиной, и их сложность. Второй — место хранения операндов, что влияет на количество и длину адресов, указываемых в адресной части команд обработки данных. Именно эти моменты взяты в качестве критериев излагаемых ниже вариантов классификации архитектур системы команд.
Классификация по составу и сложности команд
Современная технология программирования ориентирована на языки высокого уровня (ЯВУ), главная цель которых — облегчить процесс программирования. Переход к ЯВУ, однако, породил серьезную проблему: сложные операторы, характерные для ЯВУ, существенно отличаются от простых машинных операций, реализуемых в большинстве вычислительных машин. Проблема получила название семантического разрыва, а ее следствием становится недостаточно эффективное выполнение программ на ВМ. Пытаясь преодолеть семантический разрыв, разработчики вычислительных машин в настоящее время выбирают один из трех подходов и, соответственно, один из трех типов АСК:
архитектуру с полным набором команд: CISC (Complex Instruction Set Computer);
архитектуру с сокращенным набором команд: RISC (Reduced Instruction Set Computer);
архитектуру с командными словами сверхбольшой длины: VLIW (Very Long Instruction Word).
В вычислительных машинах типа CISC проблема семантического разрыва решается за счет расширения системы команд, дополнения ее сложными командами, семантически аналогичными операторам ЯВУ. Основоположником CISC-архитектуры считается компания IBM, которая начала применять данный подход с семейства машин IBM 360 и продолжает его в своих мощных современных универсальных ВМ, таких как IBM ES/9000. Аналогичный подход характерен и для компании Intel в ее микропроцессорах серии 8086 и Pentium. Для CISC-архитектуры типичны:
наличие в процессоре сравнительно небольшого числа регистров общего назначения;
большое количество машинных команд, некоторые из них аппаратно реализуют сложные операторы ЯВУ;
разнообразие способов адресации операндов;
множество форматов команд различной разрядности;
наличие команд, где обработка совмещается с обращением к памяти.
К типу CISC можно отнести практически все ВМ, выпускавшиеся до середины 1980-х годов, и значительную часть производящихся в настоящее время.
Термин RISC впервые был использован Д. Паттерсоном и Д. Дитцелем в 1980 году. Идея заключается в ограничении списка команд ВМ наиболее часто используемыми простейшими командами, оперирующими данными, размещенными только в регистрах процессорах. Обращение к памяти допускается лишь с помощью специальных команд чтения и записи. Резко уменьшено количество форматов команд и способов указания адресов операндов. Сокращение числа форматов команд и их простота, использование ограниченного количества способов адресации, отделение операций обработки данных от операций обращения к памяти позволяет существенно упростить аппаратные средства ВМ и повысить их быстродействие. RISC-архитектура разрабатывалась таким образом, чтобы уменьшить Твыч за счет сокращения среднего количества тактов процессора, приходящихся на одну команду (CPI) и длительности тактового периода. Как следствие, реализация сложных команд за счет последовательности из простых, но быстрых RISC-команд оказывается не менее эффективной, чем аппаратный вариант сложных команд в CISC-архитектуре.
Элементы RISC-архитектуры впервые появились в вычислительных машинах CDC 6600 и суперЭВМ компании Cray Research. Достаточно успешно реализуется RISC-архитектура и в современных ВМ, например в процессорах Alpha фирмы DEC, серии РА фирмы Hewlett-Packard, семействе PowerPC и т. п.
Отметим, что в последних микропроцессорах фирмы Intel и AMD широко используются идеи, свойственные RISC-архитектуре, так что многие различия между CISC и RISC постепенно стираются.
Помимо CISC- и RISC-архитектур в общей классификации был упомянут еще один тип АСК — архитектура с командными словами сверхбольшой длины (VLIW). Концепция VLIW базируется на RISC-архитектуре, где несколько простых RISC-команд объединяются в одну сверхдлинную команду и выполняются параллельно. В плане АСК архитектура VLIW сравнительно мало отличается от RISC. Появился лишь дополнительный уровень параллелизма вычислений, в силу чего архитектуру VLIW логичнее адресовать не к вычислительным машинам, а к вычислительным системам.
Классификация по месту хранения операндов
Количество команд и их сложность, безусловно, являются важнейшими факторами, однако не меньшую роль при выборе АСК играет ответ на вопрос о том, где могут храниться операнды и каким образом к ним осуществляется доступ. С этих позиций различают следующие виды архитектур системы команд:
стековую;
аккумуляторную;
регистровую;
с выделенным доступом к памяти.
Выбор той или иной архитектуры влияет на принципиальные моменты: сколько адресов будет содержать адресная часть команд, какова будет длина этих адресов, насколько просто будет происходить доступ к операндам и какой, в конечном итоге, будет общая длина команд,
Стековая архитектура
Стеком называется память, по своей структурной организации отличная от основной памяти ВМ. Стек образует множество логически взаимосвязанных ячеек (рис. 6), взаимодействующих по принципу «последним вошел, первым вышел» (LIFO, Last In First Out).
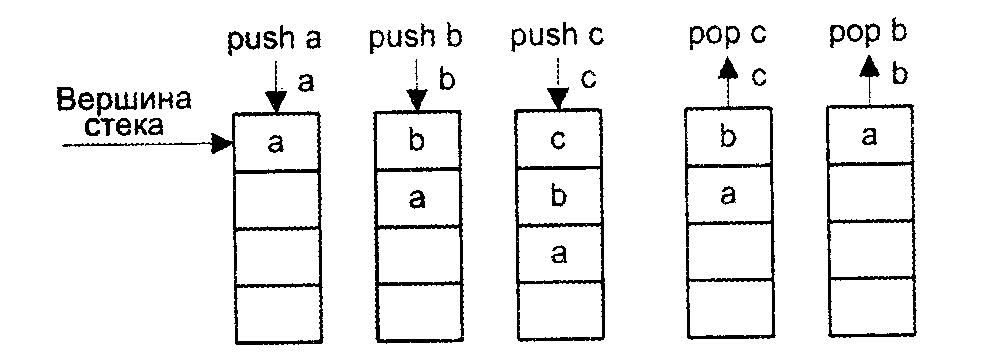
Рис.6.
Верхнюю ячейку называют вершиной стека. Для работы со стеком предусмотрены две операции: push (проталкивание данных в стек) и pop (выталкивание данных из стека). Запись возможна только в верхнюю ячейку стека, при этом вся хранящаяся в стеке информация предварительно проталкивается на одну позицию вниз. Чтение допустимо также только из вершины стека. Извлеченная информация удаляется из стека, а оставшееся его содержимое продвигается вверх. В вычислительных машинах, где реализована АСК на базе стека (их обычно называют стековыми), операнды перед обработкой помещаются в две верхних ячейки стековой памяти. Результат операции заносится в стек.
Основные узлы и информационные тракты одного из возможных вариантов ВМ на основе стековой АСК показаны на рис. 7.
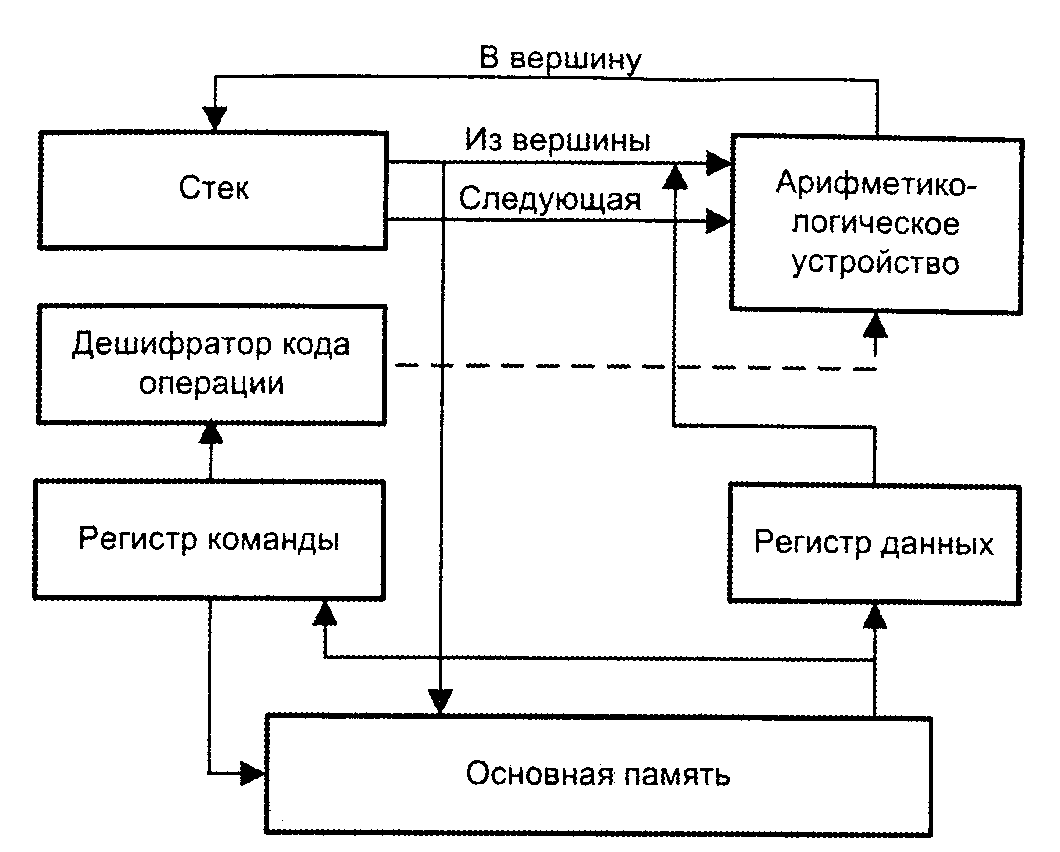
Рис. 7.
Информация может быть занесена в вершину стека из памяти или из АЛУ. Для записи в стек содержимого ячейки памяти с адресом х выполняется команда push x, по которой информация считывается из ячейки памяти, заносится в регистр данных, а затем проталкивается в стек. Результат операции из АЛУ заносится в вершину стека автоматически.
Сохранение содержимого вершины стека в ячейке памяти с адресом х производится командой pop х. По этой команде содержимое верхней ячейки стека подается на шину, с которой и производится запись в ячейку х, после чего вся находящаяся в стеке информация проталкивается на одну позицию вверх.
Для выполнения арифметической или логической операции на вход АЛУ подается информация, считанная из двух верхних ячеек стека (при этом содержимое стека продвигается на две позиции вверх, то есть операнды из стека удаляются). Результат операции заталкивается в вершину стека. Возможен вариант, когда результат сразу же переписывается в память с помощью автоматически выполняемой операции pop х.
Верхние ячейки стековой памяти, где хранятся операнды и куда заносится результат операции, как правило, делаются более быстродействующими и размещаются в процессоре, в то время как остальная часть стека может располагаться в основной памяти и частично даже на магнитном диске.
К достоинствам АСК на базе стека следует отнести возможность сокращения адресной части команд, поскольку все операции производятся через вершину стека, то есть адреса операндов и результата в командах арифметической и логической обработки информации указывать не нужно. Код программы получается компактным. Достаточно просто реализуется декодирование команд.
С другой стороны, стековая АСК по определению не предполагает произвольного доступа к памяти, из-за чего компилятору трудно создать эффективный программный код, хотя создание самих компиляторов упрощается. Кроме того, стек становится «узким местом» ВМ в плане повышения производительности. В силу помянутых причин, данный вид АСК долгое время считался неперспективным встречался, главным образом, в вычислительных машинах 1960-х годов.
Последние события в области вычислительной техники свидетельствуют о возрождении интереса к стековой архитектуре ВМ. Связано это с популярностью языком Java.
Аккумуляторная архитектура
Архитектура на базе аккумулятора исторически возникла одной из первых. В ней для хранения одного из операндов арифметической или логической операции в процессоре имеется выделенный регистр — аккумулятор. В этот же регистр заносится и результат операции. Поскольку адрес одного из операндов предопределен, в командах обработки достаточно явно указать местоположение только второго операнда. Изначально оба операнда хранятся в основной памяти, и до выполнения операции один из них нужно загрузить в аккумулятор. После выполнения команды обработки результат находится в аккумуляторе и, если он не является операндом для последующей команды, его требуется сохранить в ячейке памяти.