

Аверянов Современная информатика 2011
.pdfРис. 2.10. Классификация компьютерных систем (классификация Флина)
1)без использования параллельных вычислений, когда один поток команд обрабатывает поступающий на вход один поток данных
(ОКОД или SISD, single instruction, single data stream);
2)несколько процессоров по одному алгоритму (одной команде) обрабатывают одновременно несколько потоков данных (ОКМД или SIMD, single instruction, multiple data streams, параллельная об-
работка);
81
3)когда один поток данных обрабатывается большим количеством процессоров различного функционального назначения (МКОД или MISD, multiple instructions, single data stream, конвейерная ар-
хитектура);
4)самая высокая степень распараллеливания, когда множественный поток данных обрабатывает множественный поток команд
(МКMД или МIМD, multiple instructions, single data stream, матрич-
ная архитектура).
Если выделить из процессора функциональные блоки, ответственные за доставку и подготовку команд, назвав эту часть процессором команд, а часть процессора, непосредственно осуществляющую обработку, назвать арифметическим процессором, то четыре разновидности распараллеливания можно представить в виде схем
(рис. 2.10).
Развитие различных уровней запоминающих устройств, таких, как рассмотренные выше кэш-память, канал массовой памяти, электронные диски и т.п., также оказало заметное влияние на эволюцию архитектуры компьютеров.
Теперь рассмотрим, как же эти четыре принципа используются
вконкретных типах СОД.
2.5. Классификация компьютеров, краткие характеристики суперкомпьютеров, мейнфреймов и мини-компьютеров
Хотя современные персональные компьютеры (ПК) обладают впечатляющими возможностями, которые существенно расширились в связи с появлением 64-разрядных микропроцессоров, не следует полагать, что они справятся с любой задачей. Неявным подтверждением этого является несколько уровней технических средств, традиционно развивающихся на протяжении многих лет в мире (суперкомпьютеры, мейнфреймы) и появившихся сравнительно недавно (мини-компьютеры, микрокомпьютеры, ПК, рабочие станции, серверы и суперсерверы).
Хотя сложившаяся классификация ЭВМ в последнее время подвергаетсязначительным изменениям, тем не менее, до последнего времени эксплуатируютсявсеперечисленныевышетипыкомпьютеров.
82
Компьютерные технологии усложняются прямо на глазах, и пропорционально растет риск принятия ошибочных решений при внедрении новых аппаратных и программных продуктов. Если при покупке персонального компьютера цена ошибки не превышает сотни-другой долларов, то некомпетентное решение при компьютеризации научных, учебных или производственных подразделений может стоить потери десятков тысяч и более долларов.
При выборе вычислительных средств рекомендуется пользоваться следующим правилом: «из всех возможных вариантов построения системы наилучшим является тот, который обеспечивается наиболее простой архитектурой». Только когда ее возможностей не хватает, следует рассматривать более сложную организацию. Практикой доказано, что:
лучше использовать один быстрый компьютер, чем много медленных;
проблему создания необходимого количества рабочих мест (активных экранов) лучше решать с помощью многопользовательских систем, чем с помощью локальных систем ПК;
массовый параллелизм можно использовать только при полной уверенности в реально существующем параллелизме приложений.
Суперкомпьютеры – один из наиболее динамично развивающихся классов компьютеров, имеющих обширные и очень важные области применения.
По данным ведущих специалистов фирмы Intel рынок высокопроизводительных вычислений растет. К 2007 г. его объем уже достиг 10 млрд дол., а в некоторых секторах ежегодный прирост продаж превышает 30 %.
На начальном этапе потребность в компьютерах сверхвысокой вычислительной мощности была связана задачами в области аэродинамики, сейсмологии, метеорологии, атомной и ядерной физики, а также для физики плазмы, которые можно отнести к области моделирования сплошных сред.
Сплошную среду можно представить набором физических параметров, описывающих каждую точку некоторой трехмерной области. Численные значения параметров изменяются от точки к точке, и, как правило, под внешним воздействием они претерпевают изменения во времени. Параметрами могут быть, например, плот-
83
ность, скорость и температура движущегося газа, напряжение в твердом теле или составляющая электромагнитной силы. Основные физические законы, действующие в сплошных средах, описываются системами дифференциальных уравнений в частных производных, которые на языке исчисления бесконечно малых связывают между собой значения и скорости изменения переменных в соседних точках среды. Строго математически можно доказать существование единственного решения такой системы уравнений при заданных начальных или граничных условиях – значениях переменных в начальный момент времени или на границе области. Точное решение полностью определяет поведение изучаемой материальной системы. Однако во всех реальных ситуациях, за исключением простейших, практически невозможно получить точное решение в явном виде. Поэтому приходится обращаться к численным методам, которые абсолютно точного результата не дают, но могут обеспечить нужную нам точность, правда, ценой увеличения объема арифметических вычислений, за счет замены непрерывного пространства его дискретным аналогом и аппроксимации исходного дифференциального уравнения в точках разбиения, приближенным линейным.
Реализация методов дискретизации на исследуемом пространстве приводит к необходимости решения больших систем линейных (нелинейных) уравнений для довольно большого количества параметров исследуемого пространства. По данным из различных зарубежных источников, требуемая производительность для решения
сказания |
|
10 |
|
|
|
10 |
FLOPS, пред- |
||
задач NASA – |
|
|
FLOPS, физики плазмы 3* |
||||||
|
10 |
FLOPS, |
|
10 |
10 |
FLOPS, молекулярной динамики |
|||
|
погоды |
|
|
||||||
20* |
|
|
вычислительной космологии |
10 |
FLOPS (десять |
||||
|
|
|
|
||||||
квинтиллионов).
Всвязи с этим разработчикам пришлось перейти на новый уровень размерностей для оценки производительности компьютеров и емкости оперативной и внешней памяти (табл. 2.1).
Внастоящее время в связи с глобальными изменениями в технологии элементной базы суперкомпьютеров и естественным уменьшением стоимости сфера их применения значительно расширилась. Это и распределенные СУБД, криптография, нефтедобывающая промышленность и прочие применения.
84
Таблица 2.1
Giga |
109 |
Tera |
1012 |
Peta |
1015 |
Exa |
1018 |
Zetta |
1021 |
Yotta |
1023 |
Кроме всего прочего, рядовому пользователю полезно иметь представление о суперкомпьютерах и потому, что все новейшие технологические достижения, обычно появляются в суперкомпьютерах, но рано или поздно далее становятся достоянием масс, работающих на ПК. Так было уже не раз: виртуальная память, кэшпамять, конвейерное выполнение команд, предсказание ветвлений, суперскалярная архитектура и симметричное мультиплексирование, впервые нашли применение в мейнфреймах и суперкомпьютерах, уже стали привычным атрибутом настольных систем. Как показывают исследования, в среднем вычислительная мощь настольных ПК отстает от уровня производительности суперкомпьютеров на 13 лет. Иными словами, по уровню производительности сегодняшние профессиональные ПК практически полностью соответствуют суперкомпьютерам 13-летней давности.
Термин «суперкомпьютер» был использован в начале 60-х годов прошлого столетия, когда группа специалистов Иллинойского университета предложила идею реализации параллельного компьютера – проект, получивший название SOLOMON, базировался на принципе векторной обработки, которая была сформулирована Джоном фон Нейманом (J. von Neuman), и концепции матричнопараллельной архитектуры, предложенной С. Унгером (S.H. Unger)
вначале 50-х годов.
В60-х годах количество суперкомпьютеров исчислялось единицами, в 1988 г. (по данным США) их количество достигло 40 шт., в 1991 г. – 760 шт. (Cray Corp, Fujitsu, Hitachi, Nippon Electric (NEC)).
После 2000 г. началось массовое производство машин этого класса.
В80-е годы под суперкомпьютерами было принято считать вычислительные системы с производительностью не меньше 100 млн
85

операций с «плавающей точкой» в секунду (мегафлоп/с*), при работе с 64-разрядными словами в поле оперативной памяти не меньше одного мегабайта. «Плавающая точка» относится к двоичной версии хорошо известного в научной практике метода представления чисел, когда число записывается в виде произведения, в котором один множитель (мантисса) имеет величину между 0,1 и 1, а другой (порядок) является степенью 10, так 6600 можно записать как 0,66 104, а 66 – как 0,66 102. Такое представление удобно в научных расчетах, поскольку часто диапазон величин, входящих в задачу бывает очень большим. В компьютерах принято двоичное представление чисел с «плавающей точкой». Для суперкомпьютеров, имеющих длину слова 64 разряда, 49 разрядов отводится под мантиссу и 15 разрядов под показатель степени, что позволяет работать в диапазоне 10-2466 – 102466 с точностью 15 десятичных разрядов мантиссы. К операциям с «плавающей точкой» относятся сложение, вычитание, умножение и деление двух операндов.
Выполнение таких операций требует несколько большего времени, чем соответствующие действия над числами с фиксированной точкой и целыми.
При определении быстродействия суперкомпьютера время, затрачиваемое на извлечение операндов из оперативной памяти и запись в оперативную память, входит в продолжительность операции.
В начале 90-х годов производительность машин этого класса достигает нескольких миллиардов операций в секунду, а позже уже десятков и сотен миллиардов. Суперкомпьютеры стали обязательным атрибутом парка вычислительной техники всех информацион- но-развитых стран. С их помощью решаются не только научнотехнические, но и комплексные стратегические задачи.
* Различают пиковую и реальную производительность суперкомпьютеров. Пиковая производительность многопроцессорной системы – теоретическое значение, недостижимое на практике. Оно получается умножением пиковой производительности отдельного процессора на число процессоров в системе. Пиковая производительность отдельного процессора в общем случае получается путем умножения его тактовой частоты на максимальное число операций, выполняемое за один такт.
Реальной называют производительность, полученную при решении реальной задачи (академической или промышленной). Так, системы в рейтинге самых мощных суперкомпьютеров (ТОР-500) ранжируются по результатам теста LINPACK – реальной академической задачи на решение системы линейных уравнений.
86
Рассмотрим, каким же образом достигается сверхвысокое быстродействие в суперкомпьютерах. Повышение быстродействия компьютера обеспечивается, в основном, двумя факторами: увеличение быстродействия микро- (нано) электронных компонентов и аппаратного обеспечения для одновременного выполнения максимально возможного числа операций.
Каким образом можно распараллелить алгоритмы пользователя и как этот параллелизм обеспечивается архитектурой компьютера?
На первых порах принцип фон Неймана предполагал единственную, как тогда казалось, архитектуру компьютера: процессор по очереди выбирает команды программы и также по очереди обрабатывает данные. Всё строго последовательно, просто и понятно, однако очень скоро выяснилось, что компьютерные вычисления обладают естественным параллелизмом, т.е. большая или меньшая часть команд программы может выполняться одновременно и независимо друг от друга. Вся дальнейшая история вычислительной техники развивалась в соответствии с логикой расширения параллелизма программ и компьютеров, и каждый новый шаг на этом пути предварялся теоретическим анализом.
Упоминавшийся ранее известный специалист по архитектуре М. Флин обратил внимание на то, что существует две причины, порождающие вычислительный параллелизм, – независимость потоков команд, одновременно существующих в системе, и не связанность данных, обрабатываемых в одном потоке команд. Если первая особенность параллелизма вычислительного процесса достаточно известна (это обычное мультипроцессирование) и не требует особых комментарий, то на параллелизме данных следует остановиться более подробно, поскольку в большинстве случаев он существует скрыто от программиста и используется ограниченным кругом программистов.
Простейшим примером параллелизма данных является последовательность из двух команд:
а) А = В + С; в противоположность |
б) C = E * F; |
D = E * F; |
A = B + C. |
Если строго следовать принципу фон Неймана, то вторая операция может быть запущена на исполнение только после завершения
87
первой операции. Однако очевидно, порядок выполнения этих команд не имеет никакого значения – операнды А, В и С не связаны с операндами D, E и F второй команды. Иными словами, обе операции являются параллельными. Практически любая программа содержит группы операций над параллельными данными.
Другой вид параллелизма данных, как правило, возникает в циклических программных конструкциях типа DO, в которых одни
ите же операции выполняются десятки, сотни, а иногда и тысячи раз. И именно в этих операциях скрыт очень большой потенциал повышения производительности компьютеров. Известный специалист в области системного программирования Д. Кнутц (D. Knuth) показал, что циклы DO, занимая даже менее 4 % кода фортранпрограмм, требуют более половины времени выполнения задач. В связи с этим возникает естественное желание ускорить выполнение циклических вычислений, и для большинства прикладных задач решение этой проблемы найдено с помощью введения класса векторных вычислений. Для программиста вектор – лишь упорядоченный список данных или одномерная матрица A[1:N] и B[1:N], элементы которого должны быть занесены в память неким стандартным способом. Число элементов списка называется длиной вектора (в отличие от более известного определения вектора в математике
ифизике). Простейшим примером цикла DO может служить операция сложения двух одномерных матриц (векторов):
A[1:N] и B[1:N]
Begin: DO i = 1, N
C(i) = A(i) + B(i)
END DO.
Понятно, что для обработки цикла, взятого в качестве примера, компьютер фон Неймана должен выполнить, как минимум, N сложений элементов векторов А и В, не считая 2N команд приращения индекса и условного перехода. Идея векторной обработки циклов такого рода заключается в том, что в систему команд компьютера вводится векторная операция сложения <А + В>, которая задает сложение всех элементов – операндов. При этом реализуются сразу две возможности ускорения вычислений: во-первых, сокращается число выполняемых процессором команд объектного кода, по-
88
скольку отпадает необходимость в пересчете индексов и организации условного перехода; и, во-вторых, все операции сложения элементов векторов-операндов могут быть выполнены одновременно в силу параллелизма этих операций.
В более общем случае, когда цикл DO содержит группу команд, можно говорить о том, что один поток команд (последовательность операций, записанных в теле цикла) обрабатывает множество потоков параллельных данных. Существует широкий класс задач (аэродинамики, ядерной физики, геологии, метеорологии, обработки изображений и т.д.), в которых процесс операций выполняемых в циклах DO, достаточно велик и достигает 80 – 90 %.
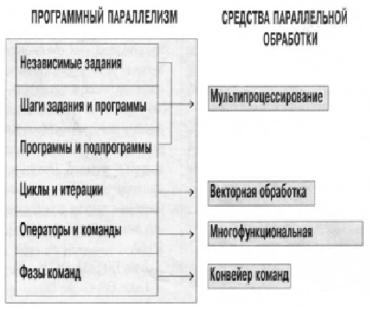
Теоретическое осмысление проблемы программного параллелизма привело к созданию достаточно близких по смыслу классификаций, из которых наиболее признанной считается классификация по шести уровням параллелизма, предположенная П. Треливеном (PC. Treleaven) из университета Ньюкастла (рис. 2.11).
Рис. 2.11. Классификация по шести уровням параллелизма
89
Три верхних уровня параллелизма занимают крупные программные объекты – независимые задания, программы и процедуры программы. Несвязанные операторы, циклы и операции образуют нижние уровни параллелизма. С учетом классификации Флина, которая была рассмотрена в разд. 2.4, становится почти очевидно, что параллелизм верхнего уровня, в основном, достигается за счет множества независимых командных потоков, а параллелизм нижнего уровня обязан своим существованием, главным образом, несвязанным потоком данных.
Каким же образом происходило развитие параллельных архитектур, и какими средствами располагают современные суперкомпьютеры для превращения программного параллелизма в характеристики производительности системы?
По мере развития вычислительной техники архитектура фон Неймана обогатилась сначала конвейером фаз операций, затем многофункциональной обработкой и получила обобщенное название SISD. Оба вида средств низкоуровнего параллелизма впервые были введены в компьютерах Control Data 6600 и 7600 в начале 70-х годов и с тех пор применяются во всех компьютерах повышенного быстродействия. Дело дошло до того, что конвейерная обработка используется даже в микропроцессорах, начиная с Intel 80486.
Из всех типов параллелизма операций архитектуры класса SISD не охватываем только один – параллелизм циклов и итераций, который тесно связан с понятием множественности потоков данных и реализуется векторной обработкой, что соответствует архитектуре
SIMD (по М. Флину).
Первоначальный этап развития суперкомпьютеров связан с созданием так называемых матричных структур, реализующих SIMDархитектуру. Это – группа процессоров, разделяющих общую память и выполняющих один поток инструкций, способных выполнять операции над матрицами, – примитивные инструкции. Количество процессоров, входящих в группу, может составлять 1000 и более.
Одним из важнейших вопросов для параллельных структур был вопрос обмена множества процессоров с модулями ОП (рис. 2.12). Разделение памяти позволяет всем процессорам параллельной системы иметь доступ к глобальным, или общим модулям памяти. В простой схеме разделения памяти (см. рис. 2.12, а) каждый процес-
90