

Максимов Информационные ресурсы и поисковые системы 2008
.pdfкорения процесса поиска в системе используют два набора индек-
сов: индекс экземпляров (значений ключей) и индекс данных (ин-
вертированный список). С помощью индекса экземпляров в файле можно найти элементы данных, имеющих заданное значение. С помощью индекса данных можно найти записи, связанные с заданными значениями элементов. Такая организация характерна для организации данных документальных информационных систем.
На рис. 2.1 приведена примерная схема организации данных для представления и поиска информации диалоговой системы поиска до-
кументов STAIRS (Storage and Information Retrieval System), разра-
ботанной фирмой IBM в 1970-х годах. Отметим, что такая структура не только хорошо иллюстрирует принципы организации данных в документальных системах, но и составляет основу большинства современных АИПС.
Рис.2.1.Организацияданных вдокументальной АИПС STAIRS
Физическая структура БД рассматриваемой системы включает в себя следующие четыре файла:
- файл частотного словаря, устанавливающий соответствие между словом, встречающимся в БД, его кодом и частотой, используется при текстовом поиске;
51
-инверсный (инвертированный, обратный) список, содержащий для каждого слова БД список документов, его содержащих, используется при текстовом поиске;
-текстовый файл, содержащий собственно документы, используется при выдаче (просмотре) документов;
-прямой, последовательный файл, содержащий «собранные»
водну строку фиксированной длины форматные поля и список кодов слов, находящихся в тексте данного документа. При необходимости в соответствующих местах находятся разделители сегментов и/или предложений. Файл используется при наличии в запросах конструкций SENT, SEGM, CTX, определяющих необходимость проверки взаимного расположения поисковых терминов.
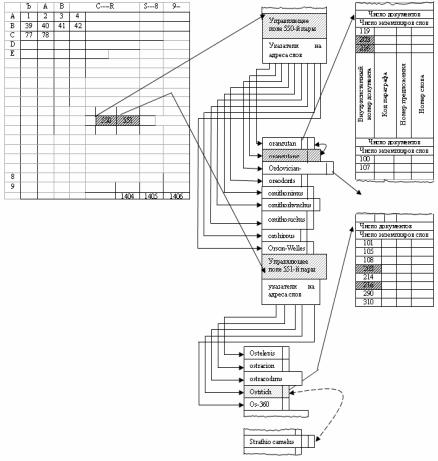
На рис. 2.2 представлена структура индексных файлов словарь слов, в котором содержится перечень терминов, встречающихся в документах. Словарь содержит само слово, его характеристики и указатель на списки ссылок на документы, в которых встречается это слово.
Ввиду значительных размеров словаря, его организация предусматривает наличие специального индекса, представленного матрицей пар знаков. Каждой паре знаков поставлен в соответствие указатель на блок словаря, содержащий группу слов, начинающихся с этих знаков. Знаками могут быть буквы, цифры, а также специальные символы. Группы слов в словаре имеют переменную длину.
Некоторые слова в словаре могут иметь одинаковый смысл; такие слова связаны с помощью специального указателя «синоним» (на рисунке связи данного типа показаны штриховыми стрелками).
При использовании инвертированных форм представления информации на первом шаге проводится поиск в инвертированном справочнике и, если предмет запроса отождествлен с соответствующим классом, то на втором шаге для детального соотнесения содержания документа и запроса обращение будет производиться только к сравнительно небольшому числу документов – только к тем, которые отнесены к этому классу. Таким образом, за счет введения информационно-избыточной структуры и дополнительного шага поиска достигается существенный выигрыш во времени: суммарное время на поиск в инвертированном справочнике существенно меньше поиска в целом массиве документов, поскольку длина индекса, идентифицирующего содержание документа, обычно
52
на порядки меньше длины самого документа, и, кроме того, индексы строго упорядочены (например, по лексикографическому признаку).
Рис.2.2.ОрганизацияиндексныхфайловдокументовАИПСSTAIRS
53
Идентификация содержания с помощью индексов строится по принципам искусственных информационно-поисковых языков, где каждый индекс представляет то или иное множество характеристических признаков. Это позволяет сократить число просматриваемых документов: в соответствии с формулой композиции признаков (что хорошо реализуется выражением алгебры логики) производится слияние относящихся к разным индексам списков ссылок на документы, т. е. выбираются только те документы, которые описываются именно этим сочетанием.
Использование технологии индексирования, тем не менее, имеет принципиальные недостатки:
1)индексационная информация, относящаяся к документу, статична: индексы, приписанные к документу, будут всегда иметь смысл, заложенный при создании языка индексирования (например, классификации конкретного поколения);
2)нельзя без дополнительных затрат реализовать управление глубиной поиска, а также выполнить поиск с использованием критерия «частичного» соответствия.
И все же, автоматизация поиска информации основывается именно на технологии индексирования (как способа идентификации содержания и, соответственно, инвертированных форм представления информации) документов, поскольку документальные АИПС имеют следующие принципиально важные особенности построения и использования [27].
Во-первых, задачи в области документального поиска не сравнимы с другими задачами обработки текстов, такими, как, например, автоматический перевод. По существу документальные ИПС создаются только для того, чтобы указать потребителю те документы, которые, скорее всего, имеют отношение к данному интересующему его вопросу. Поэтому здесь можно ограничиваться довольно грубым раскрытием содержания документа, указывающим лишь основные моменты, вместо фразеологического анализа, необходимого, например, при переводе.
Во-вторых, поисковые системы создаются для обслуживания больших и часто разнородных групп потребителей. Поскольку последние могут иметь различные потребности и цели, поисковые запросы варьируются от вопросов обзорного или познавательного
54
характера до очень подробных аналитических запросов. При таких условиях слишком подробный анализ может оказаться излишне (или даже неприемлемо) специализированным для большинства пользователей.
В-третьих, в основе процесса оценки лежит некоторый критерий эффективности, обычно усредняемый по многим поисковым запросам. Это означает, что более предпочтительными оказываются такие методы, которые дают умеренно высокую общую эффективность, чем, может быть, более тонкие алгоритмы, которые могут превосходно обрабатывать одни запросы, но значительно хуже другие. Практически может оказаться, что для каждого вида запроса оптимальным будет некоторый специфический метод, но для среднего запроса наилучшими являются более простые методы индексирования.
Как очевидно следует из изложенного, высокое качество поиска, в первую очередь – полнота и точность, могут быть достигнуты только за счет метаинформационной и/или процедурной избыточности. Увеличение полноты достигается, например, следующими путями:
1)дополнительным индексированием документа (вплоть до индексирования несколькими методами каждого поля документа, включая полный текст);
2)расширением запроса за счет близкой по смыслу лексики, выбираемой пользователем или системой из дополнительных (метаинформационных) справочников, таких, как словари синонимов, тезаурусы;
3)использованием многостадийных итеративных процедур и/или нескольких механизмов поиска;
4)снижением точности запроса или порога выдачи, что позволяет, занижая требования к степени смыслового соответствия, увеличить вероятность попадания в выдачу истинно релевантных документов. Очевидно, что при этом в выдачу попадет во много раз больше нерелевантных документов и пользователь должен будет потратить больше времени на отбор истинно релевантных. Этот путь кажется малопривлекательным, однако, поскольку многие (если не большинство) промышленные ИР (см. примеры в разделе
4)достаточно ограниченно используют средства, перечисленные в первых трех пунктах, в некоторых случаях, это вариант является
55
единственно возможным для получения удовлетворительного результата.
Увеличение точности достигается, например, следующими путями:
1)использованием для индексирования словосочетаний, обычно дескрипторов ИПТ или словосочетаний, приведенных к нормализованной форме;
2)использованием при построении поискового образа документа и/или запроса статистики словоупотреблений и/или лингвистических процессоров, что позволяет «взвешивать» термины;
3)использованием сложных критериев отбора, дифференциально учитывающих роль и значимость терминов и терминологических конструкций;
4)использованием постобработки, упорядочивающей документы для просмотра, что позволяет сократить время пользователя.
Перечисленные средства не являются взаимоисключающими и широко исследуются и, в той или иной степени, применяются. Например, во многих поисковых машинах и системах (прежде всего в тех, поисковые интерфейсы которых в явной форме не ориентированы на алгебру логики) после отбора проводится постобработка, так или иначе упорядочивающая отобранные документы. В простейшем случае это может быть сортировка по какому-либо существенному для пользователя атрибуту (дате публикации, шифру классификации и т.д.) или степени соответствия (мере близости). В более сложных случаях система может рубрицировать выданные документы в соответствии с какой-то классификационной схемой, или кластеризовать их по степени взаимной близости. Существо постобработки с точки зрения сокращения объема документов, которые должен просматривать пользователь до момента фактического удовлетворения ИП, состоит в том, что достаточно большое множество всех найденных документов разделяется на сравнительно небольшие подклассы. И, поскольку классы обычно выделяются по тематическому признаку, пользователь, возможно, удовлетворится просмотром документов одного, двух классов, вполне обоснованно не обращаясь к остальным.
56
2.2.Функциональная обработка запросов и документов
вАИПС
На рис. 2.3 представлена обобщенная схема обработки запросов и документов в АИПС.
Сорганизационно-функциональной точки зрения в АИПС выделяются два контура: обработки запросов и обработки доку-
ментов. В свою очередь, в контуре обработки документов могут выделяться (как отдельные подсистемы) контуры первичной и вторичной информации. Контур первичной информации выделяется в отдельную подсистему в том случае, если массив первичных документов размещается на иных типах носителей или использует отдельную систему управления данными, например, на микрофишах или специализированные хранилища CD ROM-носителей, не имеющих программных интерфейсов с АИПС.
Сточки зрения функциональности в составе АИПС можно выделить три блока:
- блок предобработки – преобразование в машинную форму документов и запросов;
- блок формирования базы данных АИПС – загрузка ПОД и машинных форм документов (полных текстов) в базу данных
- блок поиска – отбор по поисковому образу запроса из множества ПОД, тех, которые удовлетворяют требованиям критерия смыслового соответствия;
- блок постобработки – упорядочение найденных докумен-
тов.
- блок выдачи – форматирование и отображение материала найденных документов.
Как видно на рис. 2.3, изначальными являются процессы генерации информации и появление информационной потребности. Их возникновение происходит в сознании человека, однако выражение, так или иначе, связывается с конкретной предметной областью, её структурой и терминологией. При этом могут использоваться такие лингвистические средства, как тезаурусы предметных областей, язык представления онтологий (OWL) или язык представления знаний (KML). При этом для машинной формы материа-
57
лов, ориентированной на передачу, используются коммуникативные форматы, как например, ISO-2709 и ISO-8211, или XML, а для описания логической структуры ресурса, содержащего материалы, может использоваться язык описания ресурсов RDF.
Обработка поступающих в систему документов обычно включает:
-присвоение документу уникального идентификатора, необходимого для поиска, а также, возможно, для связывания ПОД с полным текстом документа, для чего может использоваться соответствующий кодификатор или, например, система идентификации цифровых объектов (Digital Object Identifier – DOI);
-преобразование во внутрисистемный формат, когда могут использоваться XML-схемы и язык определения документов DTD;
-индексирование и, возможно, реферирование – построение поискового образа (не обязательно автоматическое или автоматизированное) в рамках лингвистических средств АИПС, для чего используются словари, рубрикаторы, классификации, тезаурусы предметных областей;
-загрузку ПОД и, если в АИПС есть контур первичной информации, то и полного текста документа в базу данных. При этом используются языки определения и манипулирования данными соответствующей СУБД, а для оперативного взаимодействия с внешними ресурсами, например, XML-SQL.
При обработке запросов введенная пользователем формулировка преобразуется в соответствии с требованиями информацион- но-поискового языка (индексируется) и преобразуется во внутрисистемный формат в соответствии с правилами информационнопоискового языка конкретной АИПС. При этом используются словари системы, а для расширения (терминологического и тематического обогащения запроса) могут использоваться тезаурусы, онтологии, а также словари естественного языка.
На этапе отбора документов поисковый запрос, по тому или иному алгоритму, сопоставляется с поисковым образом документа и, если результат удовлетворяет критерию выдачи, который высту-
пает в качестве критерия смыслового соответствия, то документ
(точнее, его идентификатор в БД) включается в список результата поиска.
58
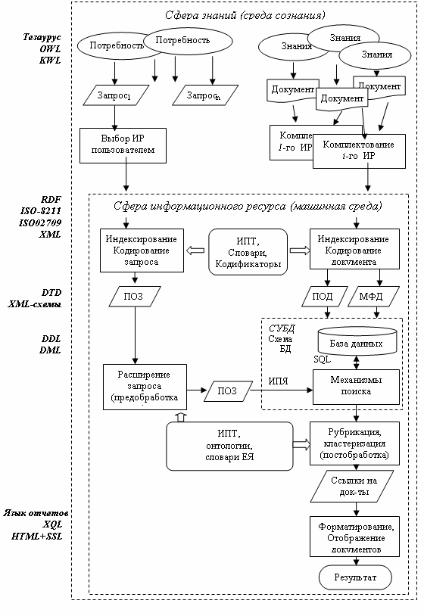
Рис. 2.3. Обобщенная схема обработки запросов и документов в АИПС
59
На этапе постобработки отобранные по ПОЗ документы могут группироваться (путем классификации или кластеризации) и ранжироваться, например, по степени соответствия запросу. При этом для обогащения ПОДа и уточнения возможных (осмысленных) сочетаний лексических единиц за счет устойчивых семантических связей используются словари, тезаурусы, онтологии предметной области, а также словари естественного языка.
На этапе выдачи документы из внутренней машинной формы преобразуются в форму удобную для восприятия человеком и, более или менее, адекватную его задачам. При этом используются языки отчетов, HTML+SSL и т.д.
Отметим, что в целом лингвистические средства, упомянутые выше, могут быть с той или иной точностью отнесены либо к группе, обеспечивающей форму представления информации, либо к группе, обеспечивающей представление содержания. К первой группе относятся коммуникативные форматы, схемы документов и баз данных, языки отчетов, HTML, XML, DTD, RDF. Ко второй – тезаурусы, классификации, рубрикаторы, кодификаторы, ИПЯ, языки онтологий. Более подробно основные из перечисленных компонентов ЛО будут рассмотрены далее.
2.3. Лингвистическое обеспечение и обработка информации в АИПС
Лингвистическое обеспечение – это совокупность языковых средств (в том числе и правила реферирования и индексирования!), позволяющих более или менее подготовленному пользователю взаимодействовать с машинной системой (по крайней мере, в части отыскания нужных пользователю документов).
Как уже отмечалось, принципиальное различие сред обработки информации (сознание человека – память ЭВМ) предопределяет, что общий для них язык общения будет далек от естественного, и его конкретные возможности будут определяться, прежде всего, спектром задач АИПС и требованиями к уровню эффективности. Он должен быть безусловно приемлем для машинной обработки, в то время как его приемлемость для человека может быть достаточно условной. Язык может обладать большими возможностя-
60