

Сортировка14.pdf Программирование
.pdf1 Сортировка линейным выбором
Линейный выбор заключается в выборе из сортируемого списка элемента с наименьшим ключом и размещение его в формируемом списке вывода. Просмотры выполняются до тех пор, пока список вывода не будет сформирован полностью. В готовом виде список вывода представляет собой упорядоченный исходный список. В начале каждого просмотра первый элемент списка считается элементом с наименьшим ключом. Ключ и адрес этого элемента передаются в рабочую память, где ключ сравнивается с ключом второго элемента. Если первый ключ меньше, то он сравнивается с ключом третьего элемента и т. д. Он сравнивается со всеми линейными преемниками до тех пор, пока в списке не найдется меньший элемент. Затем ключ найденного наименьшего элемента вместе с его адресом заменяет в рабочей памяти находившиеся там ключ и адрес и участвует в последующих проверках.
Ключ наименьшего на данный момент времени элемента всегда расположен в рабочей памяти и используется при сравнениях с оставшимися в списке ключами. По достижении конца списка наименьший элемент известен, так как это именно тот элемент, чей ключ и адрес находятся в рабочей памяти. Затем этот элемент передастся из исходного списка в текущую позицию области вывода. В исходном списке ключ каждого перемещенного элемента заменяется фиктивной величиной (например, полем из одних девяток), превосходящей любой ключ в списке, для того чтобы предотвратить повторный выбор этого элемента.
То, что адрес выбранного элемента находится в рабочей памяти, позволяет определять не только его место при пересылке, но и место, куда следует поместить фиктивный ключ. При каждом просмотре в список вывода добавляется текущий наименьший член сортируемого списка. Первый просмотр добавляет наименьший элемент, второй просмотр — следующий наименьший и т. д. Таким образом, в области вывода формируется упорядоченный список. Сортировка заканчивается, когда все члены исходного списка окажутся в списке вывода.
Этапы алгоритма:
1.Значение первого элемента принимается за минимальное значение всего массива, который сравнивается с другими элементами всего массива;
2.Если находится элемент меньше заданного минимального значение, то в качестве наименьшего принимается меньший из них;
3.В конце просмотра данный наименьший элемент массива добавляется в список вывода;
4.Так как каждый просмотр добавляет по одному элементу в список вывода, то просмотров должно быть столько, сколько элементов в массиве.
1 Сортировка линейным выбором
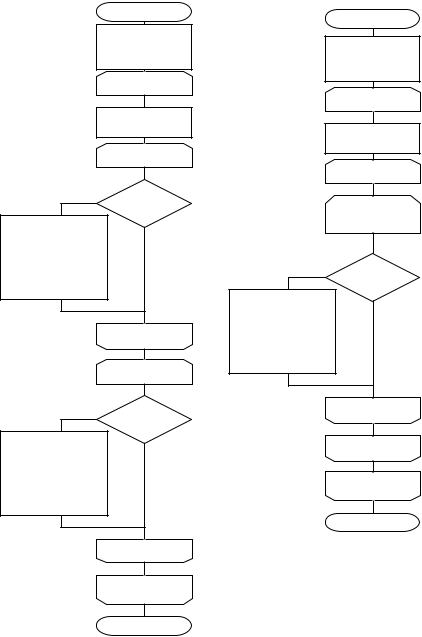
начало
minel, jj
i=0;i<n;i++ |
minel=x0; |
jj=0 |
j=0;j<n;j++
Да
xj < minel
minel=xj; jj=j
j
xjj = 32767 сi = minel
i |
конец |

2 Линейный выбор с обменом
Линейный выбор с обменом. В начале первого просмотра предполагается, что первый элемент списка имеет наименьший ключ. Этот ключ вместе с адресом пересылается в рабочую память, где сравнивается со всеми линейными преемниками до тех пор, пока не встретится меньший ключ. Меньший ключ и его адрес становятся содержимым рабочей области памяти. Сравнения продолжаются при новом содержимом рабочей памяти. Пересылка выполняется всегда, когда в списке встречается ключ, который меньше ключа в рабочей памяти. Таким образом, в рабочей памяти
всегда расположен |
наименьший из |
уже |
просмотренных ключей. |
|
Просмотр |
заканчивается по достижении конца списка. До этого момента |
|||
процесс идентичен простому линейному |
выбору. Сортировка обменом |
|||
отличается |
следующим шагом. |
|
|
|
По окончании первого просмотра запись, |
ключ которой расположен в |
|||
рабочей памяти, переставляется с записью из вершины списка. Теперь наименьшая величина в списке занимает первую позицию. Второй просмотр идентичен первому с той лишь разницей, что вторым по величине считается второй ключ, так как первым стоит наименьший элемент. Первая позиция исключается из процесса. По окончании второго просмотра вторая запись с наименьшим ключом помещается во вторую позицию списка. Третий просмотр начинается сравнением ключа из третьей позиции и т. д. Эта процедура заканчивается, когда свое место занимает (N—1)-я запись.
Этапы алгоритма:
1.Значение первого элемента принимается за минимальное значение всего массива;
2.Данный минимальный элемент сравнивается с другими элементами всего массива;
3.Если находится элемент меньше заданного минимального элемента, то в качестве наименьшего принимается меньший из них;
4.Просмотр заканчивается по достижении конца списка;
5.Минимальный элемент массива переставляется с элементов вершины списка, т.е. наименьшая величина в списке занимает первую позицию;
6.Второй и последующие просмотры идентичны первому с той лишь разницей, что вторым по величине считается второй элемент, третий – третьим и т.д.;
7.Процедура заканчивается когда свое место занимает (N – 1)-й элемент массива.
2 Линейный выбор с обменом
начало
minel, jj
i=0;i<n;i++ |
minel=xi; |
jj=i |
j=i;j<n;j++
Да
xj < minel
minel=xj; jj=j
j
xjj =xi |
xi=minel |
i |
конец |

3 Линейный выбор с подсчетом
Память, используемая линейным выбором с подсчетом, будет включать область вывода (так же как и при линейном выборе) для хранения окончательно упорядоченного списка. Размер области вывода отвечает тем же соображениям, что и при линейном выборе. Дополнительно должна быть обеспечена память под счетчик для каждого элемента списка. В результате действий над значениями этих счетчиков образуется множество индексов позиций для элементов в упорядоченном списке. При каждом просмотре ключ сравнивается со своими линейными преемниками. Каждый раз, когда находится больший ключ, его счетчик увеличивается на единицу. Если найденный ключ меньше или равен, то увеличивается счетчик, соответствующий большему из сравниваемых ключей. Следовательно, в любой момент времени счетчик элемента указывает количество ключей, о которых известно, что они меньше ключа рассматриваемого элемента.
При первом просмотре первый ключ в списке сравнивается со всеми остальными ключами. В его счетчике подсчитывается количество меньших ключей. В счетчиках больших ключей будут 1. При втором просмотре первый ключ не рассматривается. Второй ключ сравнивается с ключами всех преемников. Подсчеты фиксируются. Этот процесс продолжается N — 1 раз. На этом этапе известна относительная позиция каждого элемента. Помещая ключи в выходной список в соответствии со значениями их счетчиков, получаем упорядоченный список.
Этапы алгоритма:
1.Вводим массив счетчиков для каждого элемента исходного массива, все элементы которого равны нулю;
2.При первом просмотре первый элемент в списке сравнивается со всеми остальными элементами массива;
3.Если исходный элемент меньше текущего, тогда увеличивается счетчик исходного элемента на единицу, иначе на единицу увеличивается счетчик текущего элемента;
4.Второй и последующие просмотры идентичны первому с той лишь разницей, что вторым исходным элементом является второй элемент, третий
– третьим и т.д.;
5.Процесс продолжается (N — 1) раз, упорядоченный список получаем в соответствии со значениями счетчиков исходного массива.
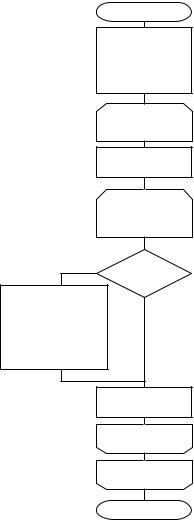
3 Линейный выбор с подсчетом
|
начало |
|
kn |
|
i=0;i<n;i++ |
|
j=i;j<n;j++ |
Да |
Нет |
|
xi < xj |
kj+=1 |
|
ki+=1 |
|
|
|
j; i |
i=0;i<n;i++ |
x[ki-1]=yi |
i |
конец |
4 Парный обмен
Метод парного обмена (также называемый «нечетно-четная перестановка») состоит из различного числа «нечетных» и «четных» просмотров. При нечетных просмотрах каждым элемент из нечетной позиции сравнивается со своим соседом из четной позиции и больший из них занимает четную позицию. Нисходящий просмотр списка продолжается до тех пор, пока последний нечетный элемент (N—1) в списке не сравнивается с последним четным элементом (N). Если в списке нечетное число элементов, то последний элемент не будет участвовать и сравнении. В течение каждого просмотра ведется подсчет обменов.
При четных просмотрах четные позиции сравниваются с соседними нечетными. Обмены выполняются тогда, когда надо, чтобы больший из пары занял нечетную позицию. Таким образом, ключи с большими значениями перемещаются на дно списка. При этом должно быть столько просмотров, сколько необходимо для того, чтобы переместить в позицию число, наиболее удаленные от своей конечной позиции. Затем выполняется заключительный просмотр, необходимый для того, чтобы опознать упорядоченность. В течение этого просмотра счетчик обменов равен 0. Данный метод требует по крайней мере двух просмотров — одного нечетного и одного четного.
Этапы алгоритма:
1.Сравниваем элементы из нечетных позиций с соседними элементами из четных позиций и больший из них занимает четную позицию;
2.Просмотр продолжается до тех пор, пока последний нечетный элемент (N-1) в списке не сравнивается с последним четным элементом (N);
3.В течение каждого просмотра ведется подсчет обменов;
4.Затем аналогично сравниваем элементы из четных позиций с элементами из нечетных позиций и больший из них занимает нечетную позицию, также ведется подсчет обменов;
5.Общий просмотр продолжается до тех пор, пока счетчик обменов не станет равным нулю.
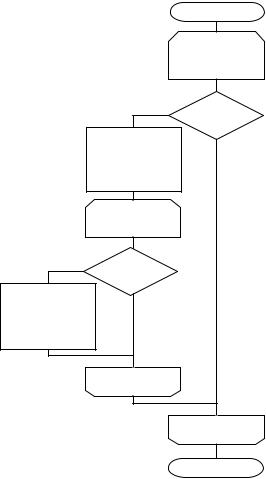
4 Парный обмен
начало
excount; |
avar; |
excount |
excount=0 |
i=0;i<n-1;i+=2 |
Да |
xi > xi+1 |
excount+=1; |
avar=xi; |
xi=xi+1; |
xi+1=avar; |
i |
i=1;i<n; i+=2 |
Да |
xi > xi+1 |
excount+=1; |
avar=xi; |
xi=xi+1; |
xi+1=avar; |
i |
excount!=0 |
конец |
начало |
excount; |
avar; |
excount |
excount=0 |
j=0;j<2;j++ |
i=0+j; i<n-1+j; |
i+=2 |
Да |
xi > xi+1 |
excount+=1; |
avar=xi; |
xi=xi+1; |
xi+1=avar; |
i |
j |
excount!=0 |
конец |
5 Стандартный обмен
Метод стандартного обмена (называемый также «методом пузырька») перемещает один элемент списка в соответствующую позицию при каждом просмотре. Таким образом, при первом просмотре запись с наибольшим ключом помещается в последнюю позицию, при втором просмотре запись со следующим по величине ключом перемещается в предпоследнюю позицию и т. д. Метод может быть преобразован так, что будет размещать элементы по убыванию.
При первом просмотре первый элемент списка сравнивается со своим непосредственным преемником, и, если этот преемник меньше, они меняются местами. Теперь больший элемент, расположенный во второй позиции, сравнивается с элементом из третьей позиции. Обмен происходит, если необходимо больший из них разместить в третьей позиции. Затем позиция 3 сравнивается с позицией 4, позиция 4 с позицией 5 и т. д. Когда позиция N—1 сравнивается с позицией N, просмотр заканчивается.
Если в списке элемент k — 1 расположен раньше k, то при каждом сравнении (k—1) :k больший элемент попадает в позицию k. Элемент, перемещаемый вниз, считается в данный момент наибольшим в списке. Когда при сравнении обнаруживается, что k-й элемент больше, обмена не происходит. Следовательно, каждый раз сравниваются элемент, считающийся наибольшим (k— 1), и его непосредственный преемник k.
Второй просмотр идентичен первому с той лишь разницей, что уже установленная позиция исключается из последовательности. Каждый последующий просмотр исключает очередную установленную позицию, укорачивая список.
Подсчет обменов ведется для каждого просмотра. Просмотр, в результате которого число обменов не увеличилось, заканчивает сортировку.
Этапы алгоритма:
1.Сравниваем текущий элемент с соседним и больший элемент помещаем в большую позицию, затем данный со следующим элементом и т.д.;
2.При каждом обмене счетчик увеличивается на единицу;
3.В конце первого просмотра наибольший элемент находится в последней позиции, в конце второго просмотра второй по величине - в предпоследней позиции и т.д., поэтому каждый последующий просмотр исключает установленную позицию;
4.Общий просмотр продолжается до тех пор, пока счетчик обменов не станет равным нулю.
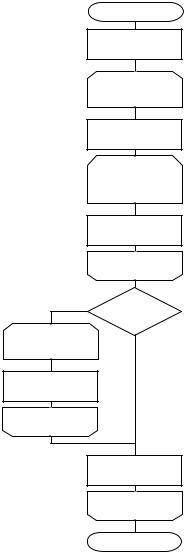
5 Стандартный обмен
начало
excount;
avar;
ready=0;
excount |
excount=0 |
i=1;i < n- |
ready; i++ |
Да |
xi-1 > xi |
excount+=1; |
avar=xi-1; |
xi-1=xi; |
xi=avar; |
ready+=1 |
i |
excount!=0 |
конец |
6 Просеивание
Метод просеивания (также называемый «линейной вставкой с обменом» или «челночной сортировкой») является самым лучшим из этих методов. Он отличается от других методов обмена тем, что не сохраняет фиксированной последовательности сравнений. Кроме этого, исчезает разделение на отдельные просмотры как следствие схемы последовательностей сравнений.
Метод просеивания работает точно так же, как стандартный обмен до тех пор, пока не надо выполнять перестановку. Сравниваемая величина с меньшим ключом поднимается насколько это возможно вверх по списку. Она сравнивается «в обратном порядке» со всеми ее линейными предшественниками по направлению к вершине списка. Если ее ключ меньше, чем у предшественника, то выполняется обмен и начинается очередное сравнение. Когда элемент, передвигаемый вверх, встречает элемент с меньшим ключом, этот процесс прекращается и нисходящее сравнение возобновляется с той позиции, с которой выполнялся первый обмен.
Назовем нисходящее сравнение первичным, а восходящее вторичным. Любое первичное сравнение может увеличить число вторичных сравнений.
Если первичное сравнение охватывает позиции 6 и 7, то цепочка вторичных сравнений может иметь самое большее пять сравнений. Этот максимум достигается, если исходный ключ из позиции 7 меньше всех ключей в списке, расположенных выше этой позиции. Фактическая длина последовательности вторичных сравнений зависит от величины двигающегося вверх элемента относительно величины каждого элемента из предшествующей упорядоченной части списка.
Сортировка заканчивается, когда первичное сравнение охватит (N + l) – й элемент.
Этапы алгоритма:
1.Сравниваем текущий элемент с соседним и больший элемент помещаем в большую позицию, это первичный просмотр;
2.Если элементы подверглись обмену, то необходим вторичный просмотр, смысл которого заключается в просмотре от текущего элемента до начала списка;
3.После завершения вторичного просмотра, продолжается первичный просмотр с позиции, с которой выполнялся первый обмен;
4.Просмотр продолжается до тех пор, пока первичный просмотр не достигнет конца списка.
6 Просеивание |
начало |
i=1;i<n-1; |
i++ |
Да |
xi > xi+1 |
avar=xi; |
xi=xi+1; |
xi+1=avar; |
j=i;j>0;j-- |
Да |
xj < xj-1 |
avar=xj; |
xj=xj-1; |
xj-1=avar; |
j |
i |
конец |
7 Линейная вставка
Под сортировку выделяется количество памяти, равное предполагаемой длине окончательного списка из всех элементов. Счетчик длины списка в самом начале устанавливается равным нулю. При помощи этого счетчика контролируется длина области поиска нужной позиции для элемента, вставляемого в список. Сортировка привлекается для каждого элемента. Один «вызов» сортирующей подпрограммы размещает один элемент в списке и увеличивает счетчик списка на единицу.
Первый элемент помещается в верхнюю позицию области вывода. Следующий элемент, присоединяемый к списку, сравнивается с первым. Если ключ нового элемента больше, он помещается в позицию, следующую за позицией первого элемента. Если ключ нового элемента меньше, то первый элемент перемещается в позицию 2, а новый элемент помещается в позицию 1. В дальнейшем все новые элементы последовательно сравниваются с каждым элементом списка, начиная с первого, до тех пор, пока не встретится больший. Этот больший элемент и все последующие элементы списка передвигаются на одну позицию вниз. Таким образом, освобождается место, на которое вставляется новый элемент.
Этапы алгоритма:
1.Работаем с двумя массивами: исходный и результирующий, элементы последнего равны нулю.
2.Первому элементу результирующего массива присваиваем значение первого элемента исходного массива и просмотр начинаем со второго элемента исходного массива.
3.Второй элемент исходного массива сравниваем с первым элементом результирующего массива. Если второй больше, то помещаем его на следующую позицию, если меньше, то первый элемент сдвигам на позицию вниз, а на его место ставим второй.
4.Следующие элементы исходного массива сравниваем сначала с первым, а затем со всеми последующими элементами результирующего массива, до тех пор, пока не встретим наибольший.
5.Все элементы, начиная с наибольшего, сдвигаем на позицию вниз. То есть, освобождаем место для нового элемента.
6.Просмотр продолжается до тех пор, пока не будет размещен последний элемент исходного массива в результирующем массиве.
7 Линейная вставка
начало |
x0 = y0 |
i=1;i<n-1; i++ |
j=0 |
xj < yi && |
j≤ (i-1) |
j++ |
Да |
j!=i |
p=i-1;p≥j; p++ |
xp+1 = xp |
p |
xj = yi |
i |
конец |

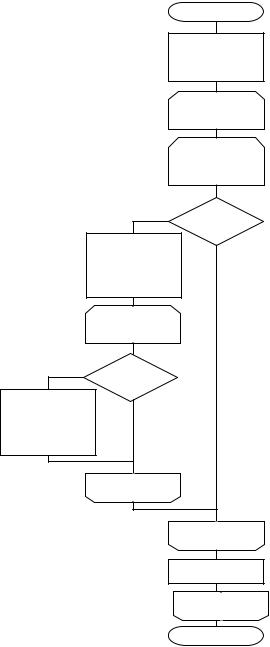
8 Метод Шелла
Сортировка Шелла является расширением сортировки просеивания, но сравниваются и обмениваются не непосредственные соседи, а элементы, отстоящие на заданное расстояние. Сравниваемая величина с меньшим ключом поднимается насколько это возможно вверх по списку. Она сравнивается «в обратном порядке» со всеми ее предшественниками с заданным шагом по направлению к вершине списка. Если ее ключ меньше, чем у предшественника, то выполняется обмен и начинается очередное сравнение. Когда элемент, передвигаемый вверх, встречает элемент с меньшим ключом, этот процесс прекращается и нисходящее сравнение возобновляется с той позиции, с которой выполнялся первый обмен.
Назовем нисходящее сравнение первичным, а восходящее вторичным. Любое первичное сравнение может увеличить число вторичных сравнений.
На каждом просмотре шаг между сравниваемыми элементами определяется путем сокращения вычисленного исходного шага. На последнем просмотре он сокращается до 1.
Этапы алгоритма:
1.Определим шаг просмотра, для этого разделим список пополам (N/2) и выделим из него целую часть (например, 11/2=5,5 → h=5).
2.Сравним элементы, отстоящие друг от друга на заданное расстояние h, между собой. Например, 1 сравнивается с 5, 2 с 6, …, 5 с 9, 6 с 10 и т.д. Если i-тый элемент больше (i+h) элемента, то меняем их местами. Это первичные сравнения.
3.Необходимо предусмотреть вторичные просмотры, когда i-тый элемент сравнивается с (i-h) элементом. Т.е. вторичные сравнения охватывают те элементы, входившие в последовательность первичных сравнений. Например, если обмену местами подверглись элементы 9 и 11, то возможная вторичная последовательность состоит из сравнений 7 и 9, и далее 5 и 7 и т.д.
4.После достижения конца списка, изменяем шаг, уменьшая его в два раза (если h=5, тогда h=2 и т.д.), и выполняем пункты 2 и 3. Деление продолжаем до тех пор, пока шаг не станет равным 1, просмотр с шагом 1 будет последним.
8 Метод Шелла |
начало |
h = n / 2 |
h>0 |
i=0;i<n-h; |
i++ |
Да |
xi > xi+h |
avar=xi; |
xi=xi+h; |
xi+h=avar; |
j=i;j≥h;j-- |
Да |
xj < xj-h |
avar=xj; |
xj=xj-h; |
xj-h=avar; |
j |
i |
h = h / 2 |
h |
конец |
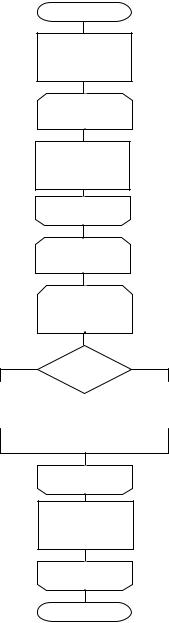
9 Метод Хиббарда
Сортировка Хиббарда является расширением сортировки просеивания, но сравниваются и обмениваются не непосредственные соседи, а элементы, отстоящие на заданное расстояние. Сравниваемая величина с меньшим ключом поднимается насколько это возможно вверх по списку. Она сравнивается «в обратном порядке» со всеми ее предшественниками с заданным шагом по направлению к вершине списка. Если ее ключ меньше, чем у предшественника, то выполняется обмен и начинается очередное сравнение. Когда элемент, передвигаемый вверх, встречает элемент с меньшим ключом, этот процесс прекращается и нисходящее сравнение возобновляется с той позиции, с которой выполнялся первый обмен.
Назовем нисходящее сравнение первичным, а восходящее вторичным. Любое первичное сравнение может увеличить число вторичных сравнений.
На каждом просмотре шаг между сравниваемыми элементами определяется путем сокращения вычисленного исходного шага. На последнем просмотре он сокращается до 1.
Этапы алгоритма:
1. Определим шаг просмотра (2 |
entier log2N |
- 1)(например, если количество |
|
|
|||
элементов равно 11, тогда entier log2N |
= 3, 23 = 8 → |
h=8-1=7) |
|
(plg=log(n)/log(2), h=pow(2,plg)-1). |
|
|
|
2.Сравним элементы, отстоящие друг от друга на заданное расстояние h, между собой. Например, 1 сравнивается с 5, 2 с 6, …, 5 с 9, 6 с 10 и т.д. Если i-тый элемент больше (i+h) элемента, то меняем их местами. Это первичные сравнения.
3.Необходимо предусмотреть вторичные просмотры, когда i-тый элемент сравнивается с (i-h) элементом. Т.е. вторичные сравнения охватывают те элементы, входившие в последовательность первичных сравнений. Например, если обмену местами подверглись элементы 9 и 11, то возможная вторичная последовательность состоит из сравнений 7 и 9, и далее 5 и 7 и т.д.
4.После достижения конца списка, изменяем шаг, уменьшая его в два раза (если h=5, тогда h=2 и т.д.), и выполняем пункты 2 и 3. Деление продолжаем до тех пор, пока шаг не станет равным 1, просмотр с шагом 1 будет последним.
9 Метод Хиббарда |
начало |
plg=log(n)/log(2) |
hh=pow(2,plg)-1 |
h>0 |
i=0;i<n-h; |
i++ |
Да |
xi > xi+h |
avar=xi; |
xi=xi+h; |
xi+h=avar; |
j=i;j≥h;j-- |
Да |
xj < xj-h |
avar=xj; |
xj=xj-h; |
xj-h=avar; |
j |
i |
h = h / 2 |
h |
конец |
10 Турнирная сортировка
В памяти необходимо место для представления 2N - 1 ключей и 2N - 1 адресов. Это место должно быть связным и организовано так, чтобы сортируемые элементы (или признаки) занимали последние N логических позиций рабочей области памяти. Первые N—1 логических позиций должны быть свободны. Адреса используются для того, чтобы найти победителя, когда его надо переместить из списка.
На первом просмотре путем сравнения ключей и выбора «победителя» (наименьшего из сравниваемых) строится древовидная структура. Победитель перемещается в предшествующую позицию, адрес которой равен целой части от половины адреса текущей позиции победителя. Например, меньший из ключей в позициях 8 и 9 переместится в позицию 4. Наличие пустых позиций в расширенной области памяти гарантирует непосредственный доступ к адресам, соответствующим предшествующим гнездам.
Первый просмотр начинается со сравнения последних позиций списка. Меньший ключ помещается в предшествующую позицию. Первоначальный адрес этого ключа перемещается в соответствующую позицию адресного пространства. Сравнения в списке выполняются снизу вверх (N: N-1; N - 2 : N - 3 и т. д.) до тех пор, пока какой-нибудь элемент не займет первую позицию, соответствующую корневому узлу в дереве. Если при сравнении используется элемент, ранее перемещенный в списке вверх, то создается новый уровень дерева. При сравнениях образуется первый уровень дерева. «Круг» турнира закончен, так как далее все сравнения будут проводиться на следующем уровне дерева.
Новый круг начинается, как только при сравнении используется элемент из предшествующей позиции. Запись, представляющая корневой узел, помещается в область вывода, а в позицию, которую занимал победитель в начале просмотра, помещается ключ (Z), наибольший среди всех ключей, какие могут встретиться в сортируемых данных. Остальные вершины остаются без изменения, даже несмотря на то, что некоторые ключи встречаются в разных местах.
Второй просмотр начинается со сравнения позиций, первоначально содержавших предыдущего победителя и его соперника. В этой предшествующей позиции он сравнивается с соперником, узел которого расположен на этом же уровне. Победитель продвигается дальше. В конце просмотра 2 содержимое корневого узла добавляется к списку вывода. Дополнительные просмотры достроят список вывода до правильной последовательности ключей.
Необходимо позаботиться о вычислении адресов для начального сравнения в просмотрах, отличных от первого. Если известна позиция победителя, то надо определить, находится ли его соперник в позиции на единицу большей или меньшей. При четном N, если позиция победителя четна, соперник всегда находится в позиции, на единицу меньшей, если же позиция победителя нечетна, то в позиции, на единицу большей. Когда N нечетно, все наоборот.
Этапы алгоритма:
1.Создаем два массива рабочих массива размером 2*N-1 и один - N, один хранит значения массива, а другой адреса (номера позиций) и третий результат сортировка.
2.Записываем значения элементов исходного массива в рабочий, где элементы рабочего, начиная с конца, равны элементам исходного, адреса аналогично.
3.Количество просмотров равно количеству элементов в исходном массиве.
4.Каждый просмотр начинается с конца с шагом -2, что текущий сравнивать с предыдущим.
5.Наименьший из двух сравниваемых записывается в рабочий массив (сам в себя) со значением индекса равному половине исходного (8/2=4), во второй рабочий массив записывается адрес данного элемента с таким же значением индекса.
6.Данный просмотр продолжаем до тех пор, пока не достигнем конца списка рабочего массива, где в первой позиции будет находиться минимальный элемент всего массива.
7.Данный элемент записываем в результирующий массив, а элементу по адресу, определяемому из второго рабочего массива, присваивается значение фиктивной величины.
10 Турнирная сортировка |
|
|
начало |
|
z[2n-1]; j=0; |
|
k[2n-1]; |
|
i=n-1;i>=0;i-- |
|
z2n-2-j = yi |
|
k2n-2-j = 2n-2-j++ |
|
i |
|
i=0;i<n;i++ |
|
j=2n-3; |
|
j>=0; j-=2 |
Да |
Нет |
|
zj < zj+1 |
zj/2 = zj |
|
zj/2 = zj+1 |
kj/2 = kj |
|
kj/2 = kj+1 |
|
|
|
j |
xi = z0 |
z[k[0]]=30000 |
i |
конец |