

Завдання.
1. Відновити пропущені значення серед даних, наведених у таблиці, що містить пропуски серед значень результуючої характеристики, використовуючи методи resampling-1, resampling-2 та метод Бартлетта.
2.
Порівняти одержані результати. Для їх
контролю та верифікації вважати, що у
таблиці представлена залежність
![]() .
.
3. Відновити пропущені значення серед значень вхідних факторів, представлених у відповідній таблиці. Вихідні дані є статистичною інформацією про виробництво і споживання різних видів енергії. Використати емпіричні методи та еволюційне моделювання. Порівняти одержані результати.
Початкові дані для виконання роботи знаходяться в файлі lab_CCC_vars.xls в робочому каталозі дисципліни на сервері локальної комп’ютерної мережі кафедри (лист “відновлення пропусків”).
Методичні вказівки
Див. Конспект лекцій з дисципліни.
Приклад розв’язання задачі
Для
верифікації еволюційного методу
проведено експериментальне моделювання
з використанням середовища Matlab
7.0.
B
якості
початкових даних для моделювання
визначено дві вибірки. Дані першої
вибірки генерувались штучно, значення
вхідних факторів мають рівномірний
розподіл, а результуюча характеристика
отримана за формулою
![]() .
Друга
вибірка є офіційною статистикою
національного інформаційного центру
енергетики США і містить дані з 1949 по
2004 роки, що включають виробництво
твердого палива, ядерної та іншої
енергії, імпорт нафти і інших енергоносіїв,
експорт
вугілля,
газу, коксу і електроенергії, споживання
твердого палива, ядерної та іншої
енергії, а також загальне споживання.
.
Друга
вибірка є офіційною статистикою
національного інформаційного центру
енергетики США і містить дані з 1949 по
2004 роки, що включають виробництво
твердого палива, ядерної та іншої
енергії, імпорт нафти і інших енергоносіїв,
експорт
вугілля,
газу, коксу і електроенергії, споживання
твердого палива, ядерної та іншої
енергії, а також загальне споживання.
Перша вибірка налічувала 25 образів, з яких 20 віднесено до навчальної послідовності і 5 - до контрольної. Моделювання проводилося для різної кількості пропусків за незмінних інших умов. Так, кількість ітерацій навчання нейронної мережі обмежена 50, а значення цільової функції склало 10. При моделюванні встановлено, що така точність досягнута не була, і процес навчання припинявся через обмеження на кількість ітерацій. Результати наведені в табл. 7.1, де N - кількість пропусків, NP - відсоткове співвідношення кількості пропусків, F - значення цільової функції, Er - відносна похибка (у відсотках). Залежність значення відносної похибки від кількості пропусків зображена на рис. 7.1.
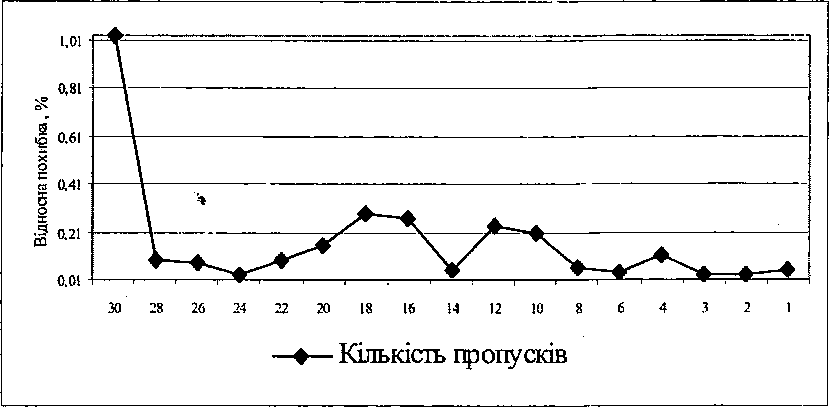
Рис. 7.1. Динаміка відносної похибки
|
Таблиця 7.1 Результати експериментів |
|
Таблиця 7.2 Результати експериментів |
||||||
|
N |
NP |
F |
Er |
|
N |
NP |
F |
Er |
|
5 |
1,14 |
0,93 |
0,0096 |
|
30 |
50,00 |
1474 |
1,028 |
|
10 |
2,27 |
0,88 |
0,0091 |
|
28 |
46,67 |
463 |
0,09 |
|
15 |
3,41 |
0,39 |
0,004 |
|
26 |
43,33 |
417 |
0,081 |
|
20 |
4,55 |
0,35 |
0,0036 |
|
24 |
40,00 |
164 |
0,033 |
|
25 |
5,68 |
0,174 |
0,0018 |
|
22 |
36,67 |
443 |
0,088 |
|
30 |
6,82 |
0,665 |
0,007 |
|
20 |
33,33 |
776 |
0,015 |
|
35 |
7,95 |
0,265 |
0,0027 |
|
18 |
30,00 |
1410 |
0,284 |
|
40 |
9,09 |
0,508 |
0,0053 |
|
16 |
26,67 |
1317 |
0,266 |
|
45 |
10,23 |
0,806 |
0,0083 |
|
14 |
23,33 |
257 |
0,049 |
|
50 |
11,36 |
0,611 |
0,0063 |
|
12 |
20,00 |
1157 |
0,236 |
|
55 |
12,50 |
0,523 |
0,0054 |
|
10 |
16,67 |
1056 |
0,209 |
|
60 |
13,64 |
0,965 |
0,01 |
|
8 |
13,33 |
335 |
0,065 |
|
65 |
14,77 |
0,611 |
0,0063 |
|
6 |
10,00 |
205 |
0,044 |
|
70 |
15,91 |
0,829 |
0,0086 |
|
4 |
6,67 |
554 |
0,109 |
|
75 |
17,05 |
0,902 |
0,0093 |
|
3 |
5,00 |
138 |
0,027 |
|
80 |
18,18 |
0,791 |
0,0195 |
|
2 |
3,33 |
121 |
0,026 |
|
|
|
|
|
|
1 |
1,67 |
248 |
0,053 |
Статистична інформація, що характеризує стан енергетики США, складалася з 11 вхідних факторів, однієї результуючої характеристики і налічувала 40 образів. 3 них 35 віднесено в навчальну послідовність і 5 - у контрольну. Кількість ітерацій встановлена рівною 150, значення цільової функції - 1. На другій вибірці ітерації припинялися через досягнення вказаного значення помилки. Максимальної кількості ітерацій, на відміну від першого випадку, досягнуто не було. Результати моделювання наведені в табл. 7.2 і на рис. 7.2.
При моделюванні для роботи ГА використовувалася вибіркова популяція з 20 елементів, кількість епох дорівнювала 100. Час моделювання на комп'ютері Intel Pentium M 2,0 Ггц склав у середньому 30 хвилин і від кількості пропусків не залежав. Отримані результати свідчать про достатньо високу точність методу, яку можна підвищити, якщо збільшити кількість ітерацій навчання нейронної мережі. Динаміка відносної похибки, що наведена на рис. 7.4 і рис. 7.5, характеризує пластичність методу, тобто здатність нейромережі до узагальнення, і свідчить про те, що вона зростає при збільшенні кількості пропусків (до деякої границі). Така тенденція є незвичайною, її пояснення вимагає додаткових досліджень.
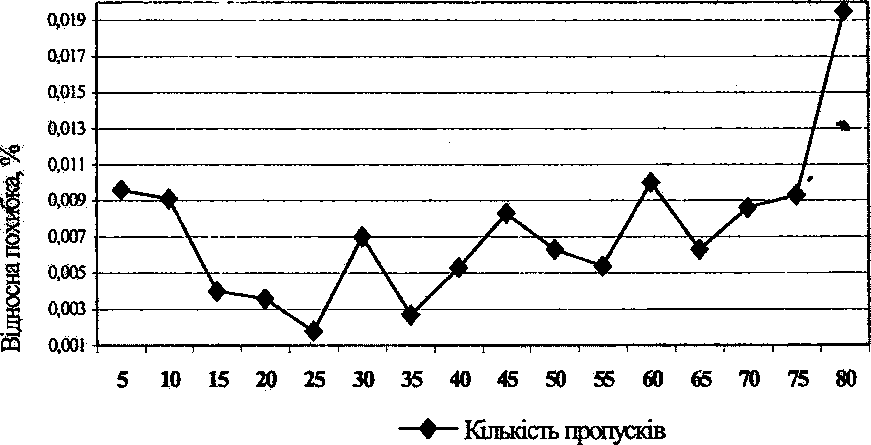
Рис. 7.2. Динаміка відносної похибки