

Mat_Metody_Otvety
.pdfполучают значения параметров интерполяционного уравнения (например, методом наименьших квадратов).

16. Погрешность измерения - оценка отклонения измеренного значения величины от еѐ истинного значения. Погрешность измерения является характеристикой (мерой) точности измерения.
В большинстве экспериментов используют косвенные измерения. Исследуемую величину f определяют по результатам прямых измерений других физических величин, например,x,y,z,..., с которыми она связана заранее установленным функциональным математическим соотношением
f = f(x, y, z, …)
Эта связь должна быть известна экспериментатору. Помимо данных прямых измерений, параметрами (5.1) могут оказаться другие величины, точно заданные или полученные в других измерениях, – они составляют набор исходных данных. Выражение (5.1), записанное в явном виде, называют рабочей формулой и
используют как для оценивания результата косвенного измерения 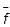 , так и для оценивания погрешности измерения delta f. Естественно, обе оценки связаны с окончательными результатами прямых измерений
, так и для оценивания погрешности измерения delta f. Естественно, обе оценки связаны с окончательными результатами прямых измерений 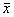 ± delta x,
± delta x,  ± delta y,
± delta y, 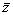 ± delta z.
± delta z.
Как и в предыдущем разделе, рассмотрим случай, когда погрешности измерения величин x, y, z, … носят только случайный характер и соответствуют нормальному закону распределения. Кроме этого, погрешность каждого отдельно взятого прямого измерения независима, т.е. не подвержена воздействию случайных факторов, вызывающих погрешности других прямых измерений, выполненных в эксперименте. Такие измерения и сами измеряемые величины носят название статистически независимых, или просто независимых. При выполнении указанных условий среднее значение величины f определяют на основе (5.1), исходя из средних значений величин x, y, z, … :
 = f(
= f(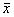 ,
,  ,
,  , …..) . (5.2)
, …..) . (5.2)
Если точность прямых измерений достаточно высока, т.е. x<< , y<< , z<< 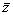 , ... , то погрешности результатов прямых измерений переносятся на результат косвенного измерения как независимые нормальные распределения f
, ... , то погрешности результатов прямых измерений переносятся на результат косвенного измерения как независимые нормальные распределения f
вокруг 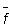 по каждому из аргументов функции (5.1). Строгое обоснование этого утверждения можно найти в математической статистике. Погрешность измерения f вследствие малых случайных вариаций
по каждому из аргументов функции (5.1). Строгое обоснование этого утверждения можно найти в математической статистике. Погрешность измерения f вследствие малых случайных вариаций
только величины x: f =f 'x ,
x x
только величины y: f =f 'y, (5.3)
y y
только величины z: f=f 'z, и т.д.
z z
Здесь fx', fy', fz'….. – производные функции f(x,y,z,…) по соответствующим переменным, являющиеся частными производными и обозначаемые в виде
fx'=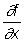 , fy'=
, fy'= , fz'=
, fz'= , …… .
, …… .
Аргументами в вычисленных производных (5.3) служат оценки средних значений  ,
,  ,
, 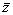

17) Вычисление числовых характеристик двух дискретных случайных величин (X, Y)
Законом |
распределения двух дискретных |
||
случайных |
величин |
называют |
перечень |
возможных |
|
значений |
и |
соответствующих им вероятностей совместного появления. В табличной форме этот закон имеет следующий вид:
При подаче таблице использованы следующие обозначения
Условие нормировки для двух дискретных случайных величин имеет следующий вид:
Основные числовые характеристики для случайных величин 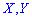 , образующих
, образующих
систему 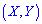 Математическое ожидание определяется по формуле
Математическое ожидание определяется по формуле
Дисперсия и среднее квадратическое отклонение для каждой дискретной величины определяют по правилам
При изучении системы двух и более случайных величин приходится выяснять наличие связи между этими величинами и его характер. С соответствующей целью применяют корреляционный момент
В случае нулевого значения корреляционного момента 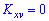 связь между величинами
связь между величинами 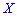 и
и
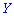 , и, принадлежащих системе
, и, принадлежащих системе 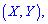 отсутствует.
отсутствует.
Когда момент отличен от нуля |
, то между дискретными величинами |
и |
||
существует корреляционная |
связь. |
Тесноту |
корреляционной |
связи |
характеризует коэффициент корреляции |
|
|
|
|
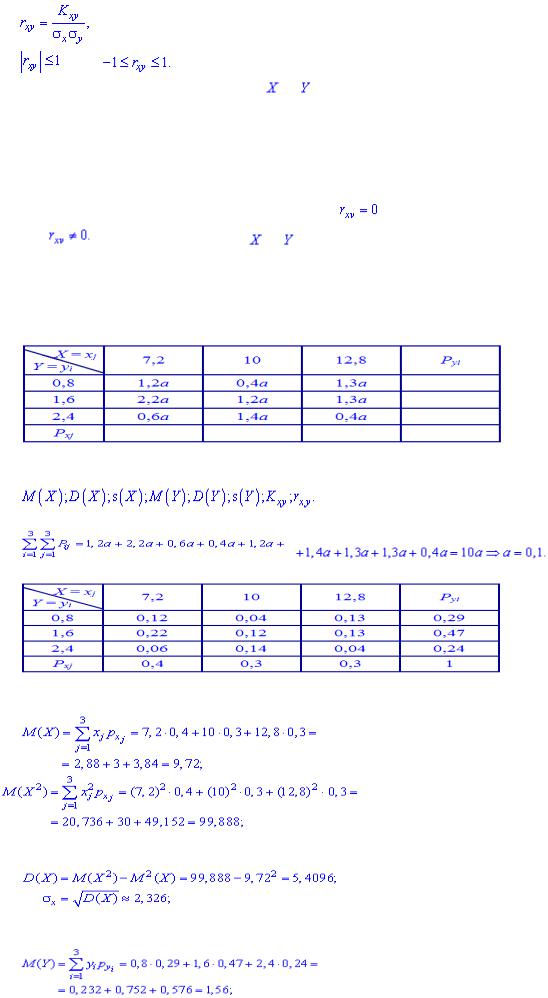
, или |
|
|
Итак, если |
случайные величины |
и независимы, то корреляционный момент равен |
нулю  и
и  . Равенство нулю
. Равенство нулю 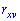 является необходимым, но не достаточным условием независимости случайных величин. Может существовать система зависимых случайных величин, в которой коэффициент корреляции равен нулю. Примером такой системы является система двух случайных величин, которая равномерно распределена внутри круга радиусом
является необходимым, но не достаточным условием независимости случайных величин. Может существовать система зависимых случайных величин, в которой коэффициент корреляции равен нулю. Примером такой системы является система двух случайных величин, которая равномерно распределена внутри круга радиусом  с центром в начале координат. Две случайные величины
с центром в начале координат. Две случайные величины  и
и  называют некоррелированными,
называют некоррелированными,
если |
коэффициент корреляции |
равен |
нулю |
, |
и |
коррелированными |
в противном |
|
случае |
Следовательно, |
если |
и |
независимы, |
то они будут и некоррелированными. |
|||
Но с |
некоррелированности |
случайных величин |
|
в |
общем случае не |
следует их |
||
независимость.
-----------------------------------------
Приведем решение распространенного на практике примера.
Пример 1. Задан закон распределения системы двух дискретных случайных величин (X,Y):
Найти неизвестную константу  . Вычислить математическое ожидание, дисперсию и среднее математические отклонения, корреляционный момент и коэффициент корреляции
. Вычислить математическое ожидание, дисперсию и среднее математические отклонения, корреляционный момент и коэффициент корреляции
Решение. Применяя условие нормирования, находим константу
По найденным 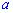 закон системы набирает такой вид:
закон системы набирает такой вид:
Основные числовые характеристики вычисляем по приведенным выше формулам. Математическое ожидание величины X получит значение
Дисперсия и среднее квадратичное отклонение набудут вида
Аналогичные вычисления выполняем для нахождения числовых характеристик случайной величины Y

Находим математическое ожидание появления обоих событий
Значение корреляционного момента вычисляем по формуле |
|
Поскольку корреляционный момент отличен от нуля |
, то между соответствующими |
величинами X и Y существует корреляционная связь. |
|
Для измерения тесноты корреляционной связи вычислим коэффициент корреляции

18. Определение регрессии. Регрессия — функция, позволяющая по средней величине одного признака определить среднюю величину другого признака, корреляционно связанного с первым.
С этой целью применяется коэффициент регрессии и целый ряд других параметров. Например, можно рассчитать число простудных заболеваний в среднем при определенных значениях среднемесячной температуры воздуха в осенне-зимний период.
Определение коэффициента регрессии. Коэффициент регрессии — абсолютная величина, на которую в среднем изменяется величина одного признака при изменении другого связанного с ним признака на установленную единицу измерения.
Формула коэффициента регрессии. Rу/х = rху x (σу / σx)
где Rу/х — коэффициент регрессии;
F - критерий Фишера используют для сравнения дисперсий двух вариационных рядов. Он вычисляется по формуле:
,
где 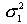 - большая дисперсия,
- большая дисперсия, 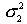 - меньшая дисперсия.
- меньшая дисперсия.
Если вычисленное значение критерия F больше критического для определенного уровня значимости и соответствующих чисел степеней свободы для числителя и знаменателя, то дисперсии считаются различными.
Число степеней свободы числителя определяется по формуле:
 ,
,
где  - число вариант для большей дисперсии.
- число вариант для большей дисперсии.
Число степеней свободы знаменателя определяется по формуле:
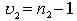 ,
,
где 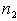 - число вариант для меньшей дисперсии.
- число вариант для меньшей дисперсии.
19. Из двумерной генеральной совокупности (X, Y) извлечена выборка объѐма n и по ней найден выборочный коэффициент корреляции rв, который оказался отличным от нуля. Поскольку выборка отобрана случайно, то нельзя заключить, что коэффициент корреляции генеральной совокупности r также отличен от нуля. Возникает необходимость при данном уровне значимости α проверить нулевую гипотезу H0={r=0} о равенстве нулю генерального
коэффициента корреляции при конкурирующей гипотезе H1={rs≠0}.
В качестве критерия проверки нулевой гипотезы применяют случайную величину
Величина T при справедливости нулевой гипотезы имеет распределение Стьюдента
сk=n-2 степенями свободы. Поэтому вычисляется эмпирическое значение критерия:
ипо таблице критических точек распределения Стьюдента по выбранному уровню
значимости α и числу степеней свободы k=n-2 находят критическую точку tкр(α;k).
Если |Tэмп|>tкр, то нулевую гипотезу отвергают, и выборочный коэффициент корреляции значимо отличается от нуля, а X и Y коррелированны, т.е. связаны линейной зависимостью.
20. a) Пусть имеются две независимые выборки объемами 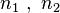 нормально распределенных случайных величин
нормально распределенных случайных величин  . Необходимо проверить по выборочным данным нулевую гипотезу
. Необходимо проверить по выборочным данным нулевую гипотезу

равенства математических ожиданий этих случайных величин 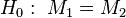 .
.
Рассмотрим разность выборочных средних 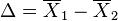 . Очевидно, если нулевая гипотеза выполнена
. Очевидно, если нулевая гипотеза выполнена 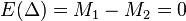 . Дисперсия этой разности равна исходя из
. Дисперсия этой разности равна исходя из
независимости выборок: |
. Тогда используя несмещенную оценку |
||
дисперсии |
получаем несмещенную оценку |
дисперсии |
разности |
выборочных средних: |
. Следовательно, t-статистика |
для проверки |
нулевой |
гипотезы равна |
|
|
|
Эта статистика при справедливости нулевой гипотезы имеет распределение 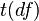 ,
,
где
Случай одинаковой дисперсии. В случае, если дисперсии выборок предполагаются одинаковыми, то
Тогда t-статистика равна:
Эта статистика имеет распределение Б) Критерий Фишера (Гипотеза о равенстве дисперсий)
Формируются две гипотезы: о равенстве и неравенстве эмпирических дисперсий двух выборок. Вычисляем критерий Фиш ера:
Если F < Fт а б л и ч н . (q,v1,v2), где v1=n1 -1, v2=n2 -1, где n1 - объем первой выборки, n2объем второй выборки , то мы принимаем гипотез у о равенстве дисперсий двух выборок. В числитель всегда ставится большая дисперсия.
21.
ТОЧЕЧНАЯ ОЦЕНКА - оценка имеющая конкретное числовое значение. Например, среднее арифметическое:
X = (x1+x2+...+xn)/n, |
|
|
|
|
где: X - |
среднее |
арифметическое |
(точечная |
оценка МО); |
x1,x2,...xn - |
выборочные |
значения; n - |
объем |
выборки. |
ИНТЕРВАЛЬНАЯ ОЦЕНКА - оценка представляемая интервалом значений, внутри которого с задаваемой исследователем вероятностью находится истинное значение оцениваемого параметра. Интервал в интервальной оценке называется ДОВЕРИТЕЛЬНЫМ ИНТЕРВАЛОМ, задаваемая исследователем вероятность называется ДОВЕРИТЕЛЬНОЙ ВЕРОЯТНОСТЬЮ. В практике статистических вычислений применяются стандартные значения доверительной вероятности: 0,95, 0,98 и 0,99 (95%, 98% и 99% соответственно). Например, интервальная оценка МО (3,8) при доверительной вероятности 0,95. Это означает,

что МО лежит в пределах |
от 3 до 8 с вероятностью 0,95, следовательно вероятность |
того, |
||||||
что МО |
меньше |
3 |
или |
больше |
8 |
не |
превышает |
0,05. |
Очевидно, что чем выше доверительная вероятность, тем выше точность оценки, но шире доверительный интервал. Отсюда следует - ДЛЯ НЕПРЕРЫВНЫХ СЛУЧАЙНЫХ
ВЕЛИЧИН ВЕРОЯТНОСТЬ ТОГО, ЧТО ТОЧЕЧНАЯ ОЦЕНКА (ширина доверительного интервала равна 0) СОВПАДЕТ С ЛЮБЫМ ЗАДАННЫМ ЗНАЧЕНИЕМ ИЛИ ОЦЕНИВАЕМЫМ ПАРАМЕТРОМ РАВНА 0.
Таким образом, точечная оценка имеет смысл лишь тогда, когда приведена характеристика рассеяния этой оценки (дисперсия). В противном случае она может служить лишь в качестве
исходных данных для построения интервальной оценки. |
|
|
|
||||
|
Вычисление интервальной оценки рассмотрим на |
примере |
интервальной |
||||
оценки МО для |
случайной |
величины подчиняющейся нормальному закону распределения. |
|||||
Границы доверительного интервала определятся по формулам: |
|
|
|||||
|
Xmin = X - T(ν,P)*S/(n)1/2 |
|
|
|
|
||
|
Xmax = X + T(ν,P)*S/(n)1/2 |
|
|
|
|
||
|
где: Xmin, |
Xmax - |
нижняя |
и |
верхняя |
границы |
интервала; |
X - |
среднее |
арифметическое |
(точечная |
оценка |
МО); |
||
n - |
|
|
|
объем |
|
|
выборки; |
T(ν,P) - поправочный |
коэффициент, называемый T-статистика, |
величина |
которого |
определяется значением |
задаваемой доверительной вероятностиp и |
числом |
степеней |
свободы ν (ν=n-1); |
|
|
|
S = [(x1 - X)2 + (x2 - X)2 + ... + (xn - X)2]1/2 - корень квадратный из оценки дисперсии случайной величины X
ЧИСЛО СТЕПЕНЕЙ СВОБОДЫ СТАТИСТИКИ - число независимых случайных величин, по которым вычисляется данная статистика. Например, при вычислении среднего арифметического все случайные величины в выборке x1,x2,...,xn независят друг от друга. В оценке S из nотклонений вида (xi - X)2 независимы только n-1 (т.к. в формуле присутствует X, то по любому набору n-1 отклонений вычисляется n-ое).
22.
Критерий Пирсона
Критерий согласия |
Пирсона позволяет осуществлять |
проверку эмпирического и |
|
теоретического (либо другого эмпирического) распределений |
одного |
признака. Данный |
|
критерий применяется, в основном, в двух случаях: |
|
|
|
- Для сопоставления |
эмпирического распределения |
признака |
с теоретическим |
распределением (нормальным, показательным, равномерным либо каким-то иным законом); - Для сопоставления двух эмпирических распределений одного и того же признака.
Идея метода – определение степени расхождения соответствующих частот ni и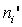 ;
;
чем больше это расхождение, тем больше значение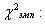
Объемы выборок должны быть не меньше 50 и необходимо равенство сумм частот
Нулевая гипотеза H0={два распределения практически не различаются между собой}; альтернативная гипотеза – H1={расхождение между распределениями существенно}.
Приведем схему применения  критерия для сопоставления двух эмпирических распределений:
критерия для сопоставления двух эмпирических распределений:
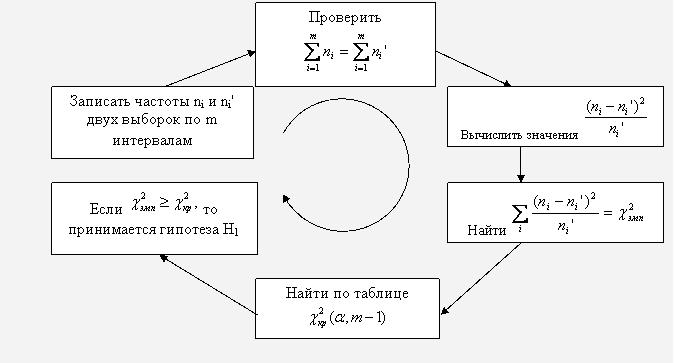
23.
Метод половинного деления (или метод вилки) хорошо знаком по доказательству теоремы о промежуточном значении в
курсе математического анализа. Его суть заключается в построении последовательности вложенных отрезков, содержащих корень. При этом на каждом шаге очередной отрезок делится пополам и в качестве следующего отрезка берется та половина, на которой значения функции в концах имеют разные знаки. Процесс продолжают до тех пор, пока длина очередного отрезка не станет меньше, чем величина 2 . Тогда его середина и будет приближенным значением корня с точностью .
Алгоритм данного метода можно записать так: 1.Ввести данные (a, b, ).
2.Если нужная точность достигнута (| b - a | < 2) то иди к п.6 3.Возьми середину очередного отрезка ( С = ( a + b )/ 2 ).
4.Если значения функции в точках а и С одного знака (f(a)*f(C)>0), то в качестве следующего отрезка возьми правую половину (а=С), иначе левую (b=C).
5.Иди к п.2.
6.Напечатать ответ (( a + b ) / 2 )
Упражнение 1.5 Перевести данный алгоритм на один из языков программирования. Метод хорд и касательных (или метод Ньютона, хотя принято называть методом Ньютона не комбинированный метод, а
метод хорд) применяется только в том случае, когда . f'(X) и f''(X) не изменяют знака на отрезке [a,b], т.е.функция f(X) на отрезке [a,b] монотонна и не имеет точек перегиба.
Суть метода та же самая - построение последовательности вложенных отрезков, содержащих корень, однако отрезки строятся по-другому. На каждом шаге через концы дуги графика функции f(X) на очередном отрезке проводят хорду и из одного конца проводят касательную. Точки пересечения этих прямых с осью ОХ и образуют следующий отрезок. Процесс построения прекращают при выполнении того же условия (| b - a | < 2 ).
Для того, чтобы отрезки получались вложенными, нужно проводить ту касательную из конца, которая пересекает ось ОХ на отрезке [a,b]. Перебрав четыре возможных случая, легко увидеть, что касательную следует проводить из того конца, где знак функции совпадает со знаком второй производной. Также несложно заметить, что касательная проводится либо все время из правого, либо все время из левого конца. Будем считать для определенности , что этот конец - b .
Вопрос 1. Почему при описанном выше построении очередной полученный отрезок также содержит корень исходного уравнения? Обоснуйте этот факт геометрически, а если сможете, то докажите его строго.
Формулы, употребляемые в методе Ньютона, хорошо известны из аналитической
геометрии: |
|
|
|
|
Уравнение хорды, проходящей через точки (a,f(a)) и (b,f(b)): |
y = f(a)+(x-a)*(f(b)-f(a))/(b- |
|||
a), |
|
|
|
|
откуда точка пересечения с осью ОХ: |
Х= a - f(a) *(b-a)/(f(b)-f(a)). |
|
||
Уравнение касательной, проходящей через точку |
(b,f(b)): |
-y=f(b)+f'(b)(x-b), |
||
откуда точка пересечения с осью ОХ: |
Х= b - f(b)/f'(b). |
|
||
При составлении алгоритма снова естественно использовать для концов отрезка только две |
||||
переменные a и b и писать: |
a= a - f(a) *(b-a)/(f(b)-f(a)) и |
(1.1) |
||
b= b - f(b)/f'(b) |
|
|
(1.2) |
|
Однако, в этом случае важен порядок формул (1.1) и (1.2).
Вопрос 2:В каком порядке следует писать формулы (1) и (2) при составлении алгоритма метода Ньютона и почему ?
Упражнение 1.6.Составить алгоритм и программу на одном из языков для решения уравнений методом Ньютона.
Метод итераций
применяется к уравнению вида Х= u(x) на отрезке [a,b], где:
а) модуль производной функции u(x) невелик: | u'(x) | <= q < 1 (x [a,b] )
б) значения u(x) лежат на [a,b] ,т.е. a <= u(x) <= b при x [a,b].
Если заранее известно, что на отрезке [a,b] расположен ровно один корень уравнения Х=u(x), то достаточно проверить выполнение условия а).
Упражнения: определить, применим ли метод итераций для уравнений:
1.7 Х=ln(3X+2) на отрезке [0,5]. А на отрезке [1,5]?
1.8Х=е х-9 на отрезке [10,12]. А на отрезке [0,1]?
Сведение исходного уравнения к виду, пригодному для применения метода итераций.
Сведение уравнения f(x)=0 к нужному виду обычно осуществляют одним из двух способов:
1)Выражают один из Х, входящих в уравнение, например уравнение ех - х-=0 приводят к виду:
Х=ех или Х = ln(х)
2) Подбирают множитель и производят преобразования: f(х)=0 => k*f(x)=0 => х=х + k*f(x), т.е. u(x)=х+ k*f(x). Например, если 0 < m < f'(x) <= M при Х[a,b], то можно в качестве k взять величину - 1/М, и тогда 0 <= u'(x) = 1 +к* f'(x)= 1- 1/M * f' (x) <= 1- m/M
Упражнения. Свести к виду, пригодному для применения метода итераций уравнения:
1.9 |
х3- 3 х2 + 1 =0 на отрезке [ 2,3 ] . |
1.10 |
x * tg(x/2)- sin(x/2) =0 на отрезке [-1,1 ] . |
1.119-x2-ex= 0 на отрезке [1,2].
24.
Сравнение различных методов.
Сравнение методов обычно производится по следующим критериям: 1.Универсальность.
2.Простота организации вычислений и контроля за точностью.
3.Скорость сходимости.
Если сравнить три приведенных выше метода, то следует отметить, что
1)Самым универсальным является метод половинного деления, поскольку он применим для любой непрерывной функции. Однако и в двух других методах ограничения не слишком жесткие и, обычно, на практике можно применять любой метод.
2)Все три метода примерно одинаковы и очень просты.
3)Скорость сходимости в методе половинного деления -геометрическая прогрессия со знаменателем 1/2 , в методе итерации -со знаменателем q, а метод Ньютона, как правило, дает сходимость со скоростью, превышающей скорость сходимости любой геометрической прогрессии. Во всех случаях скорость сходимости очень высока.