

Взгляд назад
Никакую задачу нельзя исчерпать до конца: если её решение действительно нельзя усовершенствовать, то, во всяком случае, всегда можно глубже осмыслить её решение.
Проверка каждого шага (хода) решения ещё не гарантирует отсутствие ошибок; важна проверка и результата решения. Особенно важно не проглядеть какой-либо быстрый интуитивный способ (если он имеется) проверки результата или хода решения. Полезен вопрос: нельзя ли получить тот же результат иначе? Конечно, короткое интуитивное рассуждение устроит в большей мере, чем длинное и тяжеловесное: нельзя ли усмотреть его с первого взгляда? Когда оглядываемся назад на решение задачи, представляется естественная возможность исследовать связь данной задачи с другими задачами.
Применительно к построению алгоритма С. Гудман и С. Хидетниеми [2] сформулировали аналогичные подход и вопросы, которые воспроизведены ниже.
Основные этапы полного построения алгоритма
постановка задачи;
построение модели;
разработка алгоритма;
проверка правильности алгоритма;
реализация алгоритма;
анализ алгоритма и его сложности;
написание программы на подходящем языке;
отладка программы;
составление документации.
Постановка задачи
Прежде чем понять задачу, следует её точно сформулировать. Это условие само по себе не является достаточным для понимания задачи, но оно абсолютно необходимо. Для плохо сформулированных задач полезны следующие вопросы:
Понятна ли терминология, используемая в предварительной формулировке?
Что дано? Что нужно найти? В чём состоит условие?
Каких данных не хватает? Все ли они нужны?
Являются ли какие-то имеющиеся данные бесполезными?
Какие сделаны допущения?
Возможны и другие вопросы в зависимости от конкретной задачи. Часто после получения полных или частичных ответов на некоторые из вопросов их приходится ставить повторно.
Построение модели
Задача чётко поставлена, теперь нужно сформулировать для неё математическую модель. Это очень важный шаг в процессе решения, и его надо хорошо обдумать. Выбор модели существенно влияет на остальные этапы процесса решения.
Ясно, что невозможно предложить набор правил, автоматизирующих стадию моделирования. Большинство задач должно рассматриваться индивидуально. Тем не менее существует несколько полезных руководящих принципов. Выбор модели – в большей степени дело искусства, чем науки, и, вероятно, эта тенденция сохранится. Изучение удачных моделей – это наилучший способ приобрести опыт в моделировании.
Приступая к разработке модели, следует задать, по крайней мере, два основных вопроса:
Какие математические структуры больше всего подходят для задачи?
Существует ли решение аналогичной задачи?
Второй вопрос, возможно, самый полезный во всей математике. В контексте моделирования он часто даёт ответ на первый вопрос. Действительно, большинство решаемых в математике задач, как правило, являются модификациями уже решённых. Поскольку большинство из нас не обладает талантами великих математиков, то для продвижения вперёд приходится руководствоваться накопленным опытом.
Сначала нужно рассмотреть первый вопрос. Необходимо описать математически, что знаем, и что хотим найти. На выбор соответствующей структуры оказывают влияние следующие факторы: 1) ограниченность наших знаний относительно небольшим количеством структур; 2) удобство представления; 3) простота вычислений; 4) полезность различных операций, связанных с рассматриваемой структурой или структурами.
Сделав пробный выбор математической структуры, задачу следует переформулировать в терминах соответствующих математических объектов. Это будет одна из возможных моделей, если можно утвердительно ответить на такие вопросы:
Вся ли важная информация задачи хорошо описана математическими объектами?
Существует ли математическая величина, ассоциируемая с искомым результатом?
Выявлены ли какие-нибудь полезные отношения между объектами модели?
Можно ли работать с моделью? Удобно ли с ней работать?
Разработка алгоритма
Как только задача чётко поставлена и для неё построена модель, следует приступить к разработке алгоритма её решения. Выбор метода разработки, зачастую сильно зависящий от выбора моделей, может в значительной степени повлиять на эффективность алгоритма решения. Два разных алгоритма могут быть правильными, но очень сильно отличаться по эффективности.
Многие программисты затрачивают относительно небольшое время на стадию разработки алгоритма при создании программ – проявляется желание как можно быстрее начать писать саму программу. Однако этому побуждению не стоит поддаваться! На стадии разработки требуется тщательное обдумывание; нужно также уделить внимание двум предшествующим и первым трём следующим за стадией разработки этапам. Как и следует ожидать, все восемь перечисленных этапов являются взаимосвязанными. В особенности первые три сильно влияют на последующие, а шестой и седьмой этапы обеспечивают ценную обратную связь, которая может заставить нас пересмотреть некоторые из предшествующих этапов.
Правильность алгоритма
Доказательство правильности алгоритма – это один из наиболее трудных, а иногда и особенно утомительных этапов создания алгоритма.
Вероятно, наиболее распространенная процедура доказательства правильности программы – это прогон её на разных тестах. Если выданные программой ответы могут быть подтверждены известными или вычисленными вручную данными, возникает искушение сделать вывод, что программа «работает». Однако этот метод редко исключает все сомнения; может существовать случай, когда программа не сработает.
Можно предложить следующую методику доказательства правильности алгоритма [2]. Предположим, что алгоритм описан в виде последовательности шагов, например, от шага 0 до шага m. Постараемся предложить некое обоснование правомерности для каждого шага. В частности, может потребоваться лемма об условиях, действующих до и после пройденного шага.Затем постараемся предложить доказательство конечности алгоритма, при этом будут проверены все подходящие входные данные и получены все подходящие выходные данные. Подобный метод доказательства известен как «доказательство исчерпыванием»; это самый грубый из всех методов доказательства.
Подчеркнём тот факт, что правильность алгоритма ещё ничего не говорит о его эффективности. Исчерпывающие алгоритмы редко бывают хорошими во всех отношениях.
Реализация алгоритма
Как только алгоритм выражен, допустим, в виде последовательности шагов и есть уверенность, что он правильный, настаёт черёд реализации алгоритма, т. е. написание программы для ЭВМ.
Этот существенный шаг может быть довольно трудным. Во-первых, трудность заключается в том, что очень часто отдельно взятый шаг алгоритма может быть выражен в форме, которую трудно перевести непосредственно в конструкции языка программирования (например, для реализации данного шага потребуется целая подпрограмма). Во-вторых, реализация может оказаться трудным процессом потому, что перед тем, как начать писать программу, нужно построить целую систему структур данных для представления важных аспектов используемой модели. Чтобы сделать это, необходимо ответить, например, на такие вопросы:
Каковы основные переменные? Каких они типов?
Сколько нужно массивов и какой размерности?
Имеет ли смысл пользоваться связанными списками?
Какие нужны подпрограммы (возможно, уже записанные в памяти)?
Каким языком программирования пользоваться?
Конкретная реализация может существенно влиять на требования к памяти и на скорость алгоритма.
Другой аспект построения программной реализации – это программирование “сверху–вниз”, которое состоит в преобразовании алгоритма в такую последовательность всё более конкретизированных алгоритмов, что окончательный вариант представляет собой программу для ЭВМ.
Сделаем одно важное замечание. Одно дело – доказать правильность конкретного алгоритма, описанного в словесной форме, другое – доказать, что данная программа, предположительно являющаяся реализацией этого алгоритма, также правильна. Таким образом, необходимо очень тщательно следить, чтобы процесс преобразования правильного алгоритма (в словесной форме) в машинную программу «заслуживал доверия».
Пример построения алгоритма
Рассмотрим следующую задачу: построить алгоритм, формирующий всевозможные сочетания без повторений из символов (объектов), заданных множеством M={a1, a2, …, aN}, за исключением тривиальных случаев отсутствия символов либо наличия всех символов.
Данный
алгоритм может быть представлен как
процедура построения собственного
подмножества В
множества А={Q0,
Q1, …, QN},
где QJ
– множества элементов (наборов)
всевозможных сочетаний без повторений
из N
по J
символов из M,
![]() .
Напоминаем, что в собственное подмножество
не входят как пустое, так и полное
подмножества, т. е.ВА
, BQ0=,
ВQN.
.
Напоминаем, что в собственное подмножество
не входят как пустое, так и полное
подмножества, т. е.ВА
, BQ0=,
ВQN.
При
разработке алгоритма воспользуемся
методом "сверху-вниз" [2]. Очевидно,
алгоритм должен включать в себя ввод
исходного множества M
символов, инициализацию, т.е. подготовительную
фазу процесса решения задачи: вычисление
констант, параметров, например, циклов,
предварительное преобразование данных
и представление их в удобной форме и т.
п., процедуру PAQ формирования всех
подмножеств QJ,
![]() наборов, а также вывода сформированных
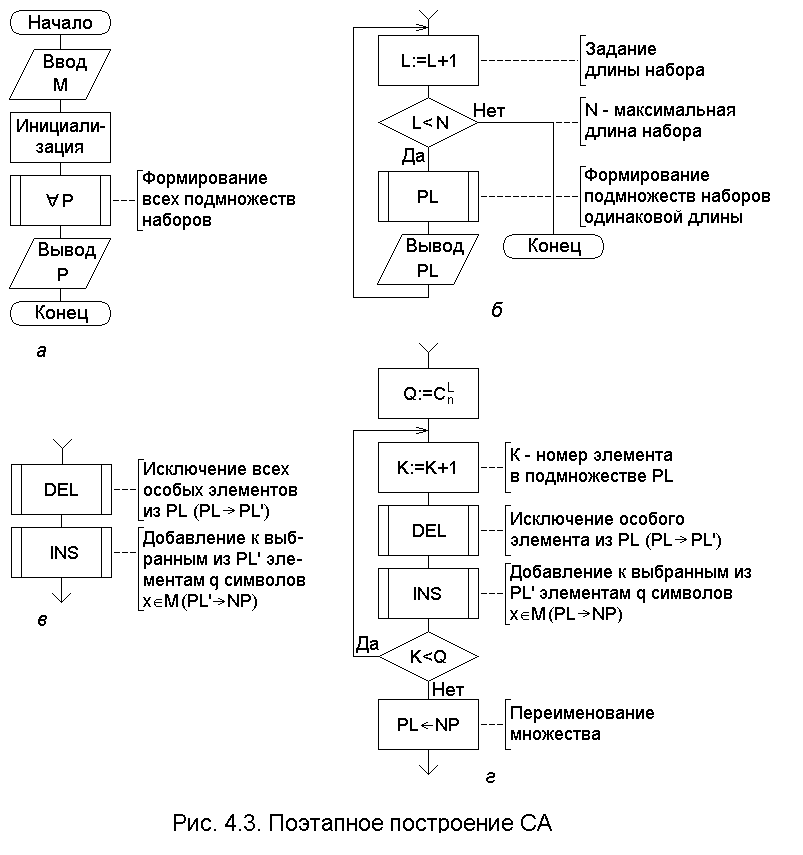
подмножеств (рис. 5.2,а).
наборов, а также вывода сформированных
подмножеств (рис. 5.2,а).
Далее заметим, что если подмножества сгруппировать по признаку одинаковой длины L наборов, то вывод сформированного подмножества QL с наборами длины L может быть произведен в цикле по L (рис. 5.2,б). Это даёт экономию памяти по сравнению с первым вариантом алгоритма. Процедуру формирования подмножества наборов длины L назовём PQL.
Рассмотрим один из возможных способов формирования подмножества QL. Очевидно, что новое подмножество (назовём его NQ) может быть получено из предыдущего дописыванием к его элементам символов из множества M. При этом нужно учесть, что если элемент qQL содержит последний символ ls (last symbol), ls=M[N], то к нему уже больше нечего дописывать. Поэтому имеет смысл из подмножества QL образовать подмножество Q'L, не содержащее элементов, последний символ p которых совпадает с ls; элементы, у которых p=ls, будем называть особыми, а процедуру удаления особых элементов будем называть DEL. Процедуру дописывания к выбранным из подмножества Q'L элементам q символов xM назовём INS. Тогда процедура формирования нового подмножества NQ из подмножества QL может быть реализована последовательным применением процедур DEL и INS (рис. 5. 2,в).
Более тщательное рассмотрение этих процедур показывает, что изолированная реализация каждой из них является избыточной по временной сложности, так как и в первой, и во второй процедурах используется перебор в цикле элементов подмножеств QL и Q'L, но поочередно. Поэтому целесообразно организовать общий для них цикл по К, где К - номер элемента qQL (рис.5.2,г). Тогда эти процедуры необходимо несколько изменить и увязать их в общем цикле (рис. 5.2,д); число повторений цикла определяется количеством элементов в подмножестве QL: S=СLn. При выходе из цикла подмножествo NQ следует переименовать в QL, т. е. переписать содержимое файла с именем NQ в файл с именем QL (NQ обнуляется).
В процедуре DEL теперь будет решаться вопрос: "Удалить элемент q=QL[K]?"; в случае положительного ответа процедура INS для элемента q не выполняется. Удаление элемента q осуществляется по признаку cовпа-дения символов: p=ls (предварительно для q определяется его последний символ - Last Symbol of the Element - p = LSE(q)). Этот фрагмент СА представлен на рис. 5.2,д. В случае отрицательного ответа элемент q обрабатывается процедурой INS, где на его основе формируются новые элементы множества NQ. Отметим здесь же, что имеет смысл вынести из цикла по К и по L определение ls, как не зависящее от параметров этих циклов.
Рассмотрим процедуру INS. Должно быть ясно, что к элементу q надо дописывать не все символы хM, а только те, которые в множестве M идут после символа, совпадающего с последним символом р элемента q. Так, если M={a,b,c,d,e} и q= ab, то LSE(q)=b, и x{c,d,e}. Обозначим NM множество следующих за р символов из множества M; для данного примера NM={c,d,e}. Тогда процедура PNM - это формирование множества NM, которое получается исключением из М всех символов слева до р включительно. Далее можно непосредственно реализовать в цикле по I (I - номер символа в множестве NМ) процедуру дописывания по одному символу хNМ к элементу q, пока выбранный из NМ символ не окажется последним; полученные новые элементы заносятся в множество NQ слева направо. Затем производится переименование множества (QL:=NQ). Этот фрагмент СА представлен на рис. 5.2,е.
Отметим, что процедуры LSE, РNМ, а также операции занесения элемента в множество пока не определены. Конкретная их реализация зависит от выбора структуры данных; доработать данный алгоритм с учётом выбранных структур данных можно самостоятельно. "За бортом" остались также вопросы формирования имени подмножества, переменной длины подмножества, ввода и вывода данных; решение этих вопросов в большей мере определяется языком программирования.
"Соберём" схему алгоритма из отдельных, уже продуманных фрагментов. При этом с целью стыковки фрагментов СА в неё включены дополнительные блоки: блоки инициализации всех циклов (L:=1; K:=0; I:=0), блоки общей инициализации (ls:=A[N]- это константа; NQ:=М - для единообразия обработки подмножества Q1); блок вывода QL переставлен в начало цикла по L с целью единообразия обработки всех подмножеств QL, включая Q1.
Схему алгоритма построения собственного подмножества, составленного из фрагментов СА с учётом их стыковки и замечаний о неполноте проработки, можно получить самостоятельно.

Рассмотрим контрольный пример. Пусть задано множество символов М = {a, b, c, d, e}; последний элемент этого множества ls=e. Имеем (выделены особые элементы)
Q0 = - исключаем из рассмотрения; Число элементов
L = 1: Q1 = {a, b, c, d, e} = M; S = C15 = 5
Q’1 = {a, b, c, d}; S1 = C14 = 4
L = 2: Q2 = {ab, ac, ad, ae, bc, bd, be, cd, ce, de}; S = C25 = 10
Q’2 = {ab, ac, ad, bc, bd, cd}; S1 = C24 = 6
L = 3: Q3 = {abc, abd, abe, acd, ace, ade, bcd, bce, bde, cde}; S = C34 = 10
Q’3 = {abc, abd, acd, bcd}; S1 = C34 = 4
L = 4: Q4 = {abcd, abce, abde, acde, bcde}; S = C44 = 5
Q’4 = {abcd}; S1 = C44 = 1
L = 5: Q5 = {abcde} - исключаем из рассмотрения.
Проведём краткий анализ построенного алгоритма и определим оценки его временной и ёмкостной сложности.