

1. Михаил Виноградов, Вадим Метлицкий. — http://h323.Com.Ru/page2.Htm
Стандарт T.120
Группа стандартовT.120Международного телекоммуникационного союза (ITU) описывает механизм организациимноготочечных видеоконференцийсо многими участниками, соединенными различными линиями связи, включая стандартные телефонные линии, каналыISDNиЛВС.
Стандарты регламентируют основные форматы данных, протоколы и сопутствующие параметры.
T.120 — это совокупность протоколови служб. В его центре находится инфраструктура организации конференции. Внизу расположены специфичные для различных сетей протоколы, включаяTCP/IP, NetWare IPX,сети X.25с коммутацией пакетов, ISDN и коммутируемые соединения. Сверху находится набор стандартов для информационных конференций или совместно используемых приложений типа "электронной доски".
С помощью своих ПK, портативных компьютеров или просто телефонов пользователи подключаются к многоточечному узлу управления (MCU — Multipoint Control Unit) — многоточечному маршрутизатору, пересылающему трафик конференции всем ее участникам.
Для взаимодействия с участниками MCU использует общие функции управления конференцией, определенные стандартом T.120. Пользователи могут также подключаться к уже начатой конференции.
Стандарт T.126 описывает функции для передачи больших оцифрованных изображений и аннотирования. Стандарт T.127 определяет функции многоточечной передачи файлов в двоичном режиме, что позволяет сжимать файлы и передавать их всем участникам конференции или группе участников.
Список литературы
1. Jet Info on-line // # 4, 1999/ - http://www.jetinfo.ru/1999/4/2/article2.4.1999219.html
Всемирная паутина
WWW (World Wide Web— всемирная паутина) — гипертекстовая информационная система сетиInternet. Ее краткое название — Web. Появление и развитие WWW стало одним из основных факторов научно-технической революции, порожденной информационными технологиями. Человечество получило новые уникальные средства связи и доступа к распределенным источникам информации.
История Web началась в 1990 г., когда британецТим Бернерс Ли, работавший в Швейцарии, представил базовые компонентыWeb-технологии, как технологии "клиент-сервер". Этими компонентами были протокол HTTP передачи данных междуклиентамиисервером, язык разметкиHTMLдля представления передаваемых данных и клиентская программа-браузер для просмотра документов на языке HTML. Дальнейшее развитие Web-технологий привело к созданию глобальной системы накопления, поиска, обработки и интеграции информации с использованием специально разработанных для Web языков, протоколов, программного обеспечения.
Информация, доступная с помощью Web-технологий, оформляется в видеWeb-страници хранится на серверах сети Internet. Совокупность Web-страниц в определенном узле сети Internet называетсясайтом. С помощью гипертекстовых ссылок можно переходить от одного Web-сервера к другому, "путешествуя" по Web-пространству, включающему миллионы сайтов сети Internet и охватывающему весь земной шар. Именно последнее оправдывает название "всемирная паутина".
На Web-страницах обычно размещаются необходимый текстовый материал и ссылки на графические иллюстрации. Пользователь может просматривать содержимое страницы или непосредственно с экрана дисплея, или в виде твердой копии после вывода страницы на печатающее устройство. Изображение можно анимировать, включать в него ссылки на мультимедийные фрагменты. Страницы с такими изображениями называют динамическими, в отличие от статических страниц с неподвижными текстом и рисунками. Можно сделать Web-страницы интерактивными с помощью специальных средств программирования, Web-страницы могут заполняться данными, являющимися результатом выполнения тех или иных вычислительных процедур.
Клиентские программы WWW называютбраузерами(brousers). Для просмотра Web-страницы браузер обращается кWeb-серверус запросом. Web-сервер имеет программу, постоянно отслеживающую приход на определенный порт (обычно это порт 80) запросов от клиентов. Сервер, получив запрос от браузера, находит соответствующую запросу Web-страницу и передает содержимое запрошенных Web-страниц или результатов выполнения запрошенных процедур в браузер клиента для просмотра. Протокола HTTP, реализующий взаимодействие сервера и клиента в Web, функционирует на базе одного изтранспортных протоколов, обычно этопротокол TCP. Популярными серверными программами являются Apache Digital для ОС Unix, Netscape Enterprise Server и Microsoft Internet Information Server (IIS), которые могут работать как в Unix, так и в Windows NT, и Netware Web Server, предназначенный для работы в ОС Netware.
В браузерах имеются команды листания, перехода к предыдущему или последующему документу, печати полученного текста, перехода по гипертекстовой ссылке и т.п. Из браузеров также доступны различные сервисы — передача файлов, электронная почта,телеконференции. Наиболее широкое распространение получили браузеры Netscape Navigator фирмы Netscape Communications, Internet Explorer фирмы Microsoft, HotJava фирмы Sun Microsystems.
Подготовка материалов к включению в Web-страницы заключается в его структурировании и форматировании с помощью языков разметки HTML (Hypertext Markup Language) и/или XML(Extensible Markup Language). Для этого разработан ряд специальных HTML- и XML-редакторов.
Технология CORBA
Технология распределенных вычислений CORBA (Common Object Request Broker Architecture) предложена ассоциацией OMG (Object Management Group). Это инвариантная к приложениям и языку программирования компонентно-ориентированная (объектная) сетевая технология. Архитектура CORBA представлена на рис. 1.
Схематично взаимодействие компонентов в технологии CORBA можно представить следующим образом. Клиент обращается с запросом на выполнение некоторой процедуры или получение некоторых данных. Запрос направляется к посреднику, называемомуORB(Object Request Broker), который способен выполнить действия, необходимые для нахождения нужного объекта в сети и его подготовки к обработке запроса. В посреднике имеется предварительно сформированный каталог (реестр или репозитарий) интерфейсов процедур с указанием компонентов-исполнителей. Посредник перенаправляет запрос соответствующему исполнителю. Исполнитель может запросить параметры процедуры. После выполнения процедуры полученные результаты возвращаются клиенту.
|
|

Рис. 1. Архитектура CORBA
При этом пользователь оперирует удобными для его восприятия идентификаторами компонентов и интерфейсов, а с помощью каталога эти идентификаторы переводятся в указатели (ссылки), используемые аппаратно-программными средствами и которые однозначно определяют интерфейс в распределенной сети из многих компьютеров.
Для описания интерфейсов и для организации связи клиента с серверными компонентами используетсяязык IDL(предложенный OMG и не совпадающий с языком IDL вRPC). Язык IDL в CORBA позволяет описывать интерфейсы создаваемых компонентов. Описание, называемоеметаданными, представляется в виде модуля метаданных, модуль включает заголовок, описания типов данных, интерфейсов и операций. В заголовке указывается идентификатор модуля. В части типов данных перечисляются атрибуты, возвращаемые значения, исключительные ситуации. Примерами типов данных могут служить типы базовые (например, float, double, char, boolean, struct), конструируемые пользователем (например, записи и массивы) и объектные ссылки, указывающие на интерфейсы компонентов. Описание интерфейсов начинается с ключевого слова interface, за которым следуют идентификаторы данного интерфейса и возможно наследуемых интерфейсов. Далее описываются операции (методы) в виде идентификаторов операций с возможными перечислениями параметров операций и указанием их принадлежности к входным или выходным данным.
Классы объектов (программные модули) должны быть реализованы в CORBA-среде. Для этого компилятор IDL выполняет следующие действия. Во-первых, метаданные для каждого класса объектов помещаются в специальную базу данных, имеющуюся в ORB, —репозитарий интерфейсов. Во-вторых, компилятор создает для каждого определенного на IDL метода клиентский и серверныйстабы– программные модули, обеспечивающие доступ к компонентам.
С помощью репозитария интерфейсов приложения во время выполнения могут получать информацию о структуре и форматах IDL-интерфейсов, необходимую для генерации динамических запросов.
Определения интерфейсов хранятся в репозитарии в виде множества объектов, содержащих описания операций, возможных исключительных ситуаций, типов параметров. Репозитарий обеспечивает также механизм доступа к этим объектам. Являясь одной из главных компонент стандарта CORBA, IR поддерживает взаимодействие брокеров различных производителей.
Физически репозитарий интерфейсов является программным компонентом, имеющим собственный IDL-интерфейс. Через этот интерфейс различные приложения и получают данные о других CORBA-объектах.
Спецификация репозитария интерфейсов удобна для построения приложений, в которых данные, параметры и функции могут изменяться во время работы приложений. К этой категории относятся CASE-средства, навигаторы и т.д.
Стабы используются для обеспечения взаимодействия клиента и сервера, функционирующих в разных адресных пространствах или на разных компьютерах (в том числе и в разных операционных системах). В терминологии CORBA они называются stub и skeleton. Stub (стаб) - это представитель сервера в адресном пространстве клиента (иногда для его обозначения используют и термин proxy). Skeleton (скелетон)- это представитель клиента в адресном пространстве сервера.
Основное назначение стабов — выполнение маршалинга и организация передачи данных через сеть.Маршалингомназывают упаковку параметров в стандартный формат для пересылки. Маршалинг необходим по той причине, что представление данных в разных компьютерных средах может быть различным (например, различия в кодировке символов, в изображении чисел с плавающей запятой). Клиентский стаб будет использоваться для передачи вызовов и данных от клиента в сеть, а скелетон, называемый также серверным стабом, будет вызывать метод уже в среде сервера и возвращать результаты.
Клиентское приложение взаимодействует со stub-объектом, вызывая его методы (названия которых совпадают с названиями методов серверного объекта). В действительности stub-объект обращается к клиентской части Object Request Broker (ORB), обращающейся, в свою очередь, к специализированному сервису middleware- Smart Agent (он может функционировать на каком-либо из компьютеров сети), представляющему собой не что иное, как directory service - службу, обеспечивающую поиск доступного сервера, содержащего реализацию запрашиваемого клиентом объекта.
Когда сервер найден, в его адресном пространстве создается запрошенный серверный объект, содержащий, в свою очередь, skeleton-объект, которому ORB передает запрос клиента с помощью базового объектного адаптера Basic Object Adapter (BOA). BOA - это набор интерфейсов для создания ссылок на удаленные объекты, регистрации объектов, авторизации запросов и активизации приложений. Используя эту службу, skeleton регистрирует созданный серверный CORBA-объект с помощью Smart Agent, а также сообщает о доступности, факте создания и о готовности объекта принимать запросы клиента.
На серверной стороне данные о каждом новом классе объектов, поддерживаемом конкретным сервером, заносятся в репозитарий реализаций. Эту операцию выполняетобъектный адаптер. Обычно в ORB имеется несколько объектных адаптеров, обслуживающих разные группы компонентов (так, возможны объектные адаптеры, ориентированные на библиотеки, на базы данных, на группу отдельных программ и т.п.).
Объектные адаптеры выполняют также ряд других отмеченных выше функций, в частности, активацию и дезактивацию компонентов. Возможны разные способы активации и дезактивации компонентов. В первом из них для обслуживания каждого клиентского запроса создается своя копия компонента. В других способах копии не создаются, компонент обслуживает все запросы с разделением или без разделения во времени.
При реализации запроса брокер через объектный адаптер активирует соответствующий компонент. Далее клиент-серверное взаимодействие происходит через стабы.
Изложенную схему клиент-серверного взаимодействия называют статической. В CORBA предусмотрены также динамические вызовы. Для их осуществления не требуется предварительного формирования стабов с помощью компилятора языка IDL. Вместо стабов, специфических для каждого вызываемого метода, в CORBA используются специальные программы динамического взаимодействия, инвариантные к вызываемым методам. При этом необходимые данные для обращения к компоненту должны быть представлены в клиентской программе, в частности, они могут быть предварительно получены из репозитария интерфейсов. Динамические вызовы обеспечивают большую гибкость при программировании, но выполняются они значительно медленнее
В CORBA предусмотрен ряд унифицированных сервисов, работающих под управлением ORB. В частности, это сервисы:
именования — присваивает объектам уникальные имена, в результате пользователь может искать объекты в сети по имени;
жизненного цикла – обеспечивает создание, перемещение, копирование и удаление объектов (документов) в системе, в том числе составных объектов вместе со всеми ссылками и ассоциированными объектами;
обработки транзакций — осуществляет управление транзакциями (блокировка, фиксация и откат транзакций) из приложений или из ОС, что позволяет многим объектам в сети использовать одни и те же серверы;
событий — обеспечивает асинхронное распространение и обработку сообщений о событиях, происшедших при реализации процессов, что позволяет заинтересованным объектам координировать свои действия;
обеспечения безопасности — поддерживает целостность данных.
Языки разметки
Электронные документы в современныхавтоматизированных системахявляются структурированнымигипертекстовыми документами, оформляемыми с помощьюязыков разметки.
Одним из первых был разработан язык разметкиSGML(Standard Generalized Markup Language), представленный в стандарте ISO 8879. Этот язык принят в качестве основного языка оформления технической документации, в том числеинтерактивных электронных технических руководствна создаваемые изделия вCALS-технологиях.
В языке SGML определяется структура документов в виде последовательности объектов данных. Объекты данных, представляющие части документа, могут храниться в различных файлах. Стандарт SGML устанавливает такие множества символов и правил для представления информации, которые позволяют различным системам правильно распознавать и идентифицировать эту информацию. Названные множества описывают в отдельной части документа, называемой декларациейDTD(Document Type Decfinition), которую передают вместе с основным SGML-документом. В DTD указывают соответствие символов и их кодов, максимальные длины используемых идентификаторов, способ представления ограничителей для тегов, другие возможные соглашения, синтаксис DTD, а также тип и версию документа. Следовательно, SGML можно назвать метаязыком для семейства конкретных языков разметки. В частности, подмножествами SGML можно считать языки разметкиXMLиHTML.
Техническое описание в виде SGML-документа включает:
основной файл с техническим руководством, размеченный SGML-тегами;
описание сущностей, если документ относится к группе, в которой используются одни и те же сущности и подразумевается их известность;
словарь для пояснения SGML-тегов;
DTD.
Однако язык SGML сложен для освоения и применения. Поэтому для широкого применения разметки в документах, представляемых в WWW-технологиях, в 1991 г. на базе SGML был разработан упрощенныйязык HTML(HyperText Markup Language), а в 1996 г.язык XML(eXtensible Markup Language), который становится в сочетании с HTML основным языком представления документов в различных приложениях.
Язык HTML разработан с целью широкого применения разметки в документах, представляемых в WWW-технологиях.
Описание на языке HTML представляет собой текст в формате ASCII и последовательность включенных в него команд (управляющих кодов), называемых также дескрипторами или тегами. Этот текст называют HTML-документом, или HTML-страницей, или после размещения на Web-сервере — Web-страницей. Теги расставляются в нужных местах исходного текста, они определяют шрифты, переносы, появление графических изображений, ссылки и т.п. При использовании WWW-редакторов вставка команд осуществляется простым нажатием соответствующих клавиш.
Язык XML, как и HTML, считается подмножеством языка SGML. В настоящее время язык XML претендует на роль основного языка представления документов в информационных технологиях, его можно рассматривать как метаязык, служащий основой для создания частных языков разметки в различных приложениях. При этом XML более удобен, чем SGML, что обеспечивается устранением в XML некоторых второстепенных особенностей SGML. Описания на XML легче воспринимаются, приспособлены для использования в современных браузерахпри сохранении основных возможностей SGML.
Для конкретных приложений создаются свои варианты XML, называемые XML-словарями или XML-приложениями. Так, для описания текстов со специфической математической символикой разработано XML-приложение OSD (Open Software Description). Для CALS интерес представляет вариант Product Definition eXchange (PDX), посвященный обмену данными. Известны словари для химии (CML — Chemical Markup Language), биологии (BSML — Bioinformatic Sequence Markup Language) и др.
Язык HTML
Язык разметкиHTML (HyperText Markup Language) разработан в 1991 г. с целью широкого применения разметки в документах, представляемых вWWWтехнологиях.
Описание наязыке HTMLпредставляет собой текст в формате ASCII и последовательность включенных в него команд (управляющих кодов), называемых также дескрипторами или тегами. Этот текст называют HTML-документом, или HTML-страницей, или после размещения наWeb-сервере—Web-страницей. Теги расставляются в нужных местах исходного текста, они определяют шрифты, переносы, появление графических изображений, ссылки и т.п. При использовании WWW-редакторов вставка команд осуществляется простым нажатием соответствующих клавиш.
Собственно команды имеют форму <команда>, где вместо слова "команда" записывается имя команды.
Структура текста в HTML-странице имеет вид:
<HTML><HEAD>
<TITLE>Заголовок текста</TITLE>
</HEAD>
<BODY>
Текст HTML-документа
</BODY>
</HTML>
В клиентской области окна при просмотре появляется только текст, помещенный между тегами <BODY>и</BODY>. Заголовок между тегами<TITLE>и</TITLE>выполняет лишь служебные функции.
Приведем примеры HTML-тегов. К тегам форматирования текста (тегам компоновки) относятся:
<P>— конец абзаца;
<BR>— перевод строки;
<HR>— перевод строки с печатью горизонтальной линии, разделяющей части текста;
<CENTER>— выравнивание изображения по центру страницы;
<LISTING>Текст</LISTING>— представление листингов программ;
<BLOCKQUOTE>Текст</BLOCKQUOTE>— выделение цитат;
<FONT>— задание типа, размера и цвета используемого шрифта, имена этих параметров (атрибутов)FACE,SIZEиCOLORсоответственно.
Теги форматирования символов имеют вид <B>,<I>,<U>; текст между открывающем и закрывающем тегами будет выделен соответственно полужирным шрифтом, курсивом, подчеркиванием.
Для форматирования заголовков используются теги <H1>...<H6>:
<H1>Текст</H1>— текст печатается наиболее крупным шрифтом, используется для заголовков верхнего уровня;
<H2>Текст</H2>— для заголовков следующего уровня и т.д. вплоть до<H6>;
<PRE>Текст</PRE>— указанный текст представлен заданным при его записи шрифтом.
В HTML имеются теги форматирования списка. Это теги <OL>и<UL>, используемые для выделения пунктов списков с нумерацией или с пометкой специальным символом (например, *) соответственно. Каждый пункт в списке должен начинаться с тега<LI>. В словарях и глоссариях удобно применять тег<DL>, отмечающий начало списка, теги<DT>и<DD>, отмечающие очередной новый термин словаря и определяющий его текст соответственно.
В командах вставки графики игипертекстовыхссылок используются адреса вставляемого или ссылочного материала, называемыеURL(Uniform Resourse Locator). Ссылаться можно как на определенные места в том же документе, в котором поставлена ссылка, так и на другие файлы, находящиеся в любом месте сети. Перед простановкой внутренней ссылки, т.е. ссылки на некоторую позицию в данном файле, нужно разместить метку в этой позиции. Тогда URL есть указание этой метки, например, URL=#a35 есть ссылка на метку a35. URL может представлять собой имя файла в данном узле сети илиIP-имядругогоузлас указанием местоположения файла в этом узле и, возможно, также метки внутри этого файла.
Строка гипертекстовой ссылки в HTML-документе имеет вид:
<A HREF="URL">Текст</A>
Текст, указанный в этой строке и отображаемый на экране дисплея, будет выделен цветом или подчеркиванием. Можно ссылаться на определенное место в документе. Тогда ссылка имеет вид:
<A HREF="URL#метка">Текст</A>
Сама метка в документе имеет вид:
<A NAME="метка">Текст</A>
Ссылки на фрагменты данного документа можно упростить:
<A HREF="#метка">Текст</A>
Тег вставки графического изображения:
<IMG SRC="URL" [ALIGN=TOP|MIDDLE|BOTTOM] [ALT="Текст"]>
Здесь URL указывает адрес графического изображения, ALIGN— параметр выравнивания, указывает место в окне для расположения рисунка;ALT— параметр, задающий текст, который выводится на экран вместо рисунка в текстовыхбраузерах. Например:
<IMG SRC="fgr.gif">
Кроме параметров ALIGNиALTможно использовать параметрыHEIGHTиWIDTH, задающие высоту и ширину изображения (в пикселах),HSPACEиVSPACE, определяющие размер промежутка между изображением и границами страницы в горизонтальном и вертикальном направлениях,BORDER, задающий рамку вокруг изображения. Сами изображения должны быть в определенном формате (обычно это форматыGIFилиJPEG).
Экран может быть разделен на несколько окон (областей, фреймов) с помощью парного тега <FRAMESET>. В каждом окне помещается содержимое файла (текст, изображение) указанием источника в теге<FRAME>, например:
<FRAME SRC="имя_файла">
Представление таблиц выполняется с помощью тегов формирования таблиц. Парные теги <TABLE>и</TABLE>служат для указания начала и конца таблицы;<TH>и</TH>— то же для шапки таблицы;<TR>и</TR>— для строки таблицы;<TD>и</TD>— для элемента таблицы. Для форматирования таблиц используются параметры, записываемые в открывающих тегах и задающие цвет фона, ширину таблицы, расположение текста в ячейках.
Имеются возможности создания на Web-странице формы, в которую пользователи могут заносить информацию, передаваемую браузером на сервер(тег<FORM>) или управляющую выбором из меню (тег<INPUT>).
Поскольку в языке HTML множество тегов ограниченное и фиксированное, действия, предусматриваемые ими, в частности, операции форматирования, реализованы в браузерах. При этом тегам, подобным<H1>, соответствует определенный стиль (тип, размер, цвет шрифта). Чтобы дать возможность пользователям устанавливать желаемый стиль изображения, разрабатывают таблицы стилей, представляющие информацию о параметрах стиля, и способы связывания таких таблиц с HTML-документом. Большинство браузеров поддерживаюткаскадные таблицы стилейCSS (Cascading Style Sheet).
Таблица CSS состоит из правил форматирования. В каждом правиле указываются тип элемента, к которому относится форматирование, и список объявлений. Список обрамляется фигурными скобками, объявления в списке разделяются точками с запятой. Каждое объявление задает значение одного из свойств отображения элемента в виде свойство:значение. К свойствам относятся тип (гарнитура), размер, цвет, способ выравнивания и стиль (обычный, полужирный, курсив) шрифта, цвет или рисунок фона, межстрочные интервалы, наличие рамок, взаимное расположение блоков текста и другие характеристики, обычные для управления видом изображения в текстовых редакторах. Можно вместо типа элемента указать имя оригинального вводимого стиля, имя стиля должно начинаться с точки.
Использование таблицы стилей подразумевает указание типа таблицы в разделе <HEAD>HTML-документа. Там же между тегами<STYLE>и</STYLE>записываются правила форматирования. Можно все правила форматирования записать в отдельном файле и тогда в HTML-документе достаточно сослаться на этот файл в специальном теге<LINK>. Если вводимый стиль относится лишь к части документа, используется тег<SPAN>с параметромCLASS, например:
<SPAN CLASS="имя_вводимого_стиля">Часть документа</SPAN>
Первые версии языка HTML были достаточно простыми, но не лишенными ряда недостатков. Прежде всего нужно отметить ограниченность набора тегов, что не соответствует потребностям многих приложений. Кроме того, в тегах HTML не отделены данные, задающие структуру документа, от данных по его изображению (форматированию) на экране дисплея при просмотре с помощью браузера, что затрудняет работу с документами. В результате в новые версии языка стали вводится усовершенствования, что заметно усложнило язык, но не устранило основные недостатки. Наиболее существенными недостатками HTML являются, во-первых, невозможность отделить информацию о структуре документа от информации о форматировании, во-вторых, отсутствие в языке HTML средств, позволяющих производить такие операции обработки текста, как сортировка, поиск фрагментов по определенным признакам и т.п.
Поэтому в 1996 г. был предложен новый язык разметки — язык XML(eXtensible Markup Language).
Кроме того, было разработано расширениеDHTML(Dynamic Hyper Text Markup Language) языка HTML, названное динамическим языком разметки гипертекста. С помощью DHTML можно создавать Web-страницы, включающие интерактивные элементы, анимацию, движущиеся объекты и фон, расположенный под основным содержимым документа, выпадающие меню и т.п. Стандарт DHTML используется для создания скриплетов -- сценариев, обрабатываемых браузером совместно с кодом HTML.
Язык XML
Язык разметкиXML (eXtensible Markup Language) разработан в 1996 г. Он, как иHTML, считается подмножествомязыка SGML.
В настоящее времяязык XMLпретендует на роль основного языка представления документов в информационных технологиях, его можно рассматривать как метаязык, служащий основой для создания частных языков разметки в различных приложениях. При этом XML более удобен, чем SGML, что обеспечивается устранением в XML некоторых второстепенных особенностей SGML. Описания на XML легче воспринимаются, приспособлены для использования в современныхWWW-браузерах при сохранении основных возможностей SGML.
Для конкретных приложений создаются свои варианты XML, называемые XML-словарями или XML-приложениями. Известны словари для химии (CML — Chemical Markup Language), географии GML (Geography Markup Language), математичеких текстов MathML (Mathematical Markup Language), синтаксиса и семантики естественных языков LGML (Linguistics Markup Language), обмена данными по аутентификациииавторизациимежду системами безопасности SAML (Security Assertion Markup Language), описания голосоввых диалогов между человеком и компьютером VoiceXML и др. ДляCALSинтерес представляют варианты Product Definition eXchange (PDX) и 3D XML, посвященные обмену данными вCAE/CAD/CAMсистемах.
XML-документ состоит из пролога, корневого элемента "Документ", собственно и являющегося размеченным документом, таблицы определения типов(декларации DTD) и сведений поформатированию. Документ, сформированный в соответствии с синтаксическими правилами языка XML, при отсутствии DTD называют корректным, а при наличии DTD — валидным. Процессор отказывается от обработки некорректных документов. Отсутствие DTD в корректном документе считается ошибкой, но не препятствует обработке документа.
Пролог начинается со строки:
<?xml version="1.0" дополнения ?>
Эта строка указывает используемую версию языка XML (в данном случае версия 1.0). В эту строку можно в качестве дополнения включить также объявление автономности документа, если не предполагается связывать с документом какие-либо внешние файлы:
<?xml version="1.0" standalone='yes'?>
В дополнениях (или в отдельной команде) может быть указана используемая кодировка, например,encoding='ISO 8859-1'. В пролог могут входить также одна или несколько пустых строк, строки комментария и командные строки. Форма комментария:
<!--текст комментария-->
Текст комментария может включать любые символы, кроме двух дефисов.
Командные строки являются указанием XML-процессору на обработку документа. Они имеют вид:
<?команда?>
Элемент "Документ" представляет собой иерархически организованное множество элементов, являющихся размеченными фрагментами исходного документа. Фрагменты документа помещаются вконтейнеры XML, обрамленные каждый открывающим<тип>и закрывающим</тип>тегами, где вместо слова "тип" записывается конкретный тип элемента. Типы элементов задаются в декларации DTD. Фрагменты могут иметь те или иные атрибуты (параметры), значения которых записываются внутри открывающего тега, т.е. тег имеет вид<тип атрибуты>.
Декларация DTD выполняет ту же роль, что и в языке SGML. В ней указываются средства разметки, с помощью которых структурируют исходный документ. Декларация может быть помещена в отдельный файл и тогда в прологе нужно указать XML-процессору имя этого файла с помощью строки
<!DOCTYPE имя_документа SYSTEM "имя_файла_DTD">
Но можно декларацию DTD записать непосредственно в эту строку вместо служебного слова SYSTEMи имени файла DTD, заключив ее в квадратные скобки. Возможно также разделение DTD на внешнюю и внутреннюю части, когда адрес первой из них записывается в поле имя файла DTD, а вторая часть помещается после этого в квадратных скобках.
Инструкции по форматированию документа, необходимые для его визуализации с помощью браузера, могут быть заданы несколькими способами. Один из них — использованиекаскадных таблиц стилейCSS, таких же, какие используют для HTML-документов. В этих таблицах для каждого типа элемента указаны способы визуализации — тип, размер, цвет шрифта, расположение на экране дисплея при просмотре. Таблица CSS помещается в отдельный файл. Ссылка на этот файл в XML-документе размещается в прологе и имеет вид:
<?xml-stylesheet type="text/css" href="имя_файла"?>
Здесь имя_файла — имя файла с таблицей CSS, это имя должно иметь расширение .css.
Пример пролога XML-документа:
<?xml version="1.0" ?>
<!-- Это заголовок документа dictionary -->
<?xml-stylesheet type="text/css" href="dict.css"?>
<!DOCTYPE dictionary SYSTEM "dict.dtd">
В заголовке записаны номер используемой версии языка XML (version="1.0"), имя документа (в нашем примере dictionary), ссылки на файлы, в которых размещены таблицы CSS (файл dict.css) и DTD (файл dict.dtd):
Основные рассмотренные свойства XML-документов поясним следующим примером. Пусть исходный неразмеченный документ представляет собой фрагмент словаря, состоящий из трех пунктов (в нашем примере названия пунктов CALS, Ethernet, PDM). Каждый пункт относится к одному из понятий определенной предметной области и включает название понятия, его краткое определение и возможно некоторые поясняющие примеры.
Целесообразно использовать иерархическую структуру документа: верхний уровень относится к пунктам словаря, нижний уровень относится к элементам пункта. Принятая структура отражается в DTD.
После разметки исходного текста получаем XML-документ следующего вида:
<?xml version="1.0" ?>
<?xml-stylesheet type="text/css" href="dict.css"?>
<!DOCTYPE dictionary [
<!ELEMENT dictionary (item)>
<!ELEMENT item (termin,description,examples?)>
<!ELEMENT termin (#PCDATA)>
<!ATTLIST termin number ID #REQUIRED>
<!ATTLIST termin group (technology|networks|software|other) #REQUIRED>
<!ELEMENT description (#PCDATA)>
<!ELEMENT examples (#PCDATA)>
<!ENTITY ЛВС "локальная вычислительная сеть">
]>
<dictionary>
<item>
<termin number ='_14' group='technology'> CALS </termin>
<description> - Continuous Acquisition and Lifecycle Support,
информационное сопровождение и поддержка этапов жизненного цикла
промышленных изделий. Технология взаимодействия различных
автоматизированных систем в промышленности.
</description>
</item>
<item>
<termin number ='_24' group='networks'> Ethernet </termin>
<description> - &ЛВС с методом доступа МДКН/ОК.
</description>
<examples> Варианты реализации 10Base-5, 10 Base-T, 100Base-X. Gigabit Ethernet.
</examples>
</item>
<item>
<termin number ='_52' group='technology'> PDM </termin>
<description> - Product Data Management, управление проектными данными.
Системы PDM, называемые также системными средами, входят в состав
программного обеспечения CALS-технологий.
</description>
<examples> Windchill eSeries,iMAN, SmartTeam, Optegra.
</examples>
</item>
</dictionary>
В приведенном примере XML-документа атрибут number относится к маркерному типу. Его идентификатор ID означает, что этот атрибут должен иметь уникальные значения для каждого элемента termin, т.е. number является ключевым атрибутом (значения типа ID не должны начинаться с цифры, поэтому в примере используется знак подчеркивания).
В нашем примере XML-документа dictionary используютсякаскадные таблицы стилей. Пусть мы хотим элементы типа termin выделить полужирным шрифтом (bold) 12-го размера с отступом первой строки на 5 мм, а элементы типа examples — курсивом (italic) 10-го размера с отступом на 10 мм. Тогда таблица CSS, помещаемая в файл dict.css, должна быть задана в виде:
item
{display:block;}
termin
{font-weight:bold; font-size:12pt; text-indent:5mm; font-style:normal;}
description
{font-size:12pt;}
examples
{display:block; font-style:italic; font-size:10pt; text-indent:10mm;}
Обращение к браузеру для просмотра нашего документа позволит увидеть текст, представленный на рис. 1.
|
|

Рис. 1. Пример XML-документа
Часто возникает необходимость включения в XML-документ символов, отсутствующих на клавиатуре компьютера (например, буквы греческого алфавита) или на символы, относящиеся к служебным символам языка. На них следует ссылаться с помощью записи &#код_символа_по_ISO/IEC10646;.
Кроме того, для символов &, <, >, ', " можно использовать ссылки &,<,>,',"соответственно.
В языке XML расширены возможности гиперсвязей. Механизм связей в XML изложен в спецификациях XLinkиXPointer.
Программная поддержка языка XML обеспечивается XML-процессорами. В состав XML-процессора входит синтаксический анализатор, который проверяет правильность соблюдения правил языка, но не производит форматирования. Для форматирования документа используется другая компонента XML-процессора, поддерживающая каскадные таблицы стилей или язык форматирования XSL.
К функциям программного обеспечения, поддерживающего XML, кроме синтаксического анализа и визуализации, относятся поиск заданных фрагментов, создание, удаление, модификация элементов в XML-документе. Для поддержки этих функций в рабочей группе W3C, занимающейся вопросамиWeb-технологий, разрабатывается объектная модель HTML и XML-документовDOM(Document Object Model), предназначенная для создания прикладного интерфейса API (Application Program Interface) к XML-документам, и соответствующиеязыки запросов XPath(XML Path Language),XQuery, XSLT, позволяющие ссылаться на части XML-документов..
Технология SOAP
В настоящее время все более широкое распространение приобретает технология интеграции Internet-ресурсов, основанная напротоколе SOAP(Simple Object Access Protocol). SOAP —транспортный протокол, предназначенный для организации взаимодействия удаленных систем при помощи асинхронного обменаXML-документами. Первоначально SOAP предназначался, в основном, для реализации удалённого вызова процедур (RPC).
SOAP — объектная технология, в которой объектами являются Web-службы (Web Services), а для представления обращений к Web-службам используется язык XML. Язык разметки XML распознается разными системами, и потому технология SOAP значительно проще реализуется, чем такие технологии какCORBAилиDCOM.
Протокол SOAP обеспечивает взаимодействие распределенных систем независимо от типа объектной модели, операционной системы или языка программирования. Благодаря использованию XML, сообщения SOAP могут передаваться посредством транспортногопротокола HTTP, как правило, не закрываемогосетевыми экранами.
В стандарте, описывающем протокол SOAP, изложены принципы, по которым может быть осуществлена привязка SOAP-сообщений к абстрактному транспортному протоколу, общая схема создания SOAP-оболочек для RPC-ориентированных интерфейсов, способы возврата сообщений о сбоях, а также конкретная реализация способа оформления сообщений SOAP в качестве содержимого команд GET и POST протокола HTTP.
Структура SOAP-сообщения показана на рис. 1.
|
|

Рис. 1. Структура SOAP-сообщения
Заголовок HTTP может иметь вид:
POST/OrderEntry HTTP/1.1
Host: www.xmlbus.com
Content-Type: text/xml; charset="utf-8"
Content-Length: ...
SOAPAction: ...
В строке SOAPAction указывается URI получателя запроса или посредника.
SOAP-заголовок необязателен (но заголовков может быть несколько). Заголовки могут содержать любую информацию, связанную с приложением. В теле сообщения указываются запрашиваемый метод с его аргументами либо XML-документ.
SOAP-заголовок и тело вложены в конверт, имеющий вид:
<soap-env:Envelope
xmlns:soap-env="http://www.w3.org/2001/06/soap-envelope">
<!-- Далее следует заголовок -->
<soap-env:Header>
...
</soap-env:Header>
<!-- Далее следует тело -->
<soap-env:Body>
. . .
</soap-env:Body>
</soap-env:Envelope>
Прием информации, содержащейся в теле SOAP-сообщения, выполняется SOAP-процессором, который пересылает сведения из тела сообщения в запрошенную службу (например, EJB).
Кроме языка XML и Интернет-протоколов, таких как HTTP, в технологии Web-служб входят следующие компоненты:
язык WSDL(Web Service Description Language) — язык объявления возможностей (функций) Web-службы, описания на WSDL являются XML-документами;
стандарт UDDI(Universal Description, Discovery and Integration), служащий для фиксации возможностей Web-службы.
Стандарт UDDI помогает Web-сервис найти, WSDL — его охарактеризовать, а SOAP — взаимодействовать с ним.
Механизм взаимодействия клиентаисерверав технологии SOAP можно представить в виде последовательности следующих процедур (рис. 2):
Клиентское приложение создает экземпляр объекта SOAPClient;
SOAPClientпросматривает UDDI, тем самым определяется нужный метод Web-сервиса;
SOAPClientформирует SOAP-сообщение и отправляет его серверу;
Серверная программа Listener принимает SOAP-сообщение, создает объект SOAPServerи передает ему это сообщение;
SOAPServerвызывает метод Web-сервиса;
Результаты помещаются объектом SOAPServerв ответное сообщение и передаются клиенту;
Объект SOAPClientпроводит разбор принятого сообщения и возвращает клиентскому приложению результаты работы Web-сервиса.
|
|

Рис. 2. Взаимодействие клиента и сервера в SOAP
Пример системы интеграции Internet-ресурсов — платформа .NET Framework компании Microsoft. В нее входят семейство .NET Enterprise Servers, представляющее собой набор корпоративных серверных приложений, и визуальная среда VisualStudio.NET, поддерживающая все основные языки программирования и используемая для разработки и потребления Web-сервисов.
Компания IBM предлагает сервер приложений WebSphereApplication Server, MQ Series для управления сообщениями для объединения систем, включая поддержку SOAP и Web-сервисов на уровне СУБД DB2.
Список литературы
1. Понимание SOAP. — http://archival.ru/?q=node/469 2. SOAP 1.1 — http://www.w3.org/TR/SOAP/ 3. SOAP 1.2 — http://www.w3.org/TR/soap12-part1/
GRID-технологии
Не секрет, что вычислительные ресурсы предприятий и офисов используются с малой загрузкой. Например, персональные компьютерыирабочие станциипростаивают значительную часть времени. С другой стороны, имеется ряд особо сложных задач, решение которых на отдельном компьютере практически невозможно из-за чрезмерно большого времени решения. Для рационального использования сетевых ресурсов и для их концентрации для решения сложных задач предназначены GRID-технологии (GRID-вычисления). При этом под ресурсами понимаются вычислительные мощности, определяемые производительностью компьютеров, объемы памяти и сетевые средства.
GRID-технологии— это технологиираспределенных вычислений, имеющие целью рациональную загрузку ресурсов и/или совместное использование распределенных ресурсов вычислительных сетей для реализации сложных ресурсоемких приложений.
GRID-технологии можно трактовать как способы создания сверхмощных виртуальных суперкомпьютеров, которые могут превосходить реальные суперкомпьютеры по показателям производительности, масштабируемости, доступности при существенно меньших затратах средств.
Создание GRID-систем подразумевает прежде всего стандартизацию в области учета и доступа к ресурсам, обеспечения требуемого качества и безопасности обслуживания. Далее требуется разработка соответствующих инструментальных средств.
К началу 2003 г. развитие GRID-технологий прогнозировалось на базе высокоскоростных сетей (не ниже 1 Гбит/с), ОС Linux, интеграцииWeb-служб(протокол SOAP). В это время началась разработка совокупностипротоколов OGSA(Open Grid Service Architecture) под эгидой организации Grid Forum. В марте 2004 г. была выпущена первая версия стандарта (OGSA 1.0). В OGSI 1.0 определяется набор принципов и расширений для использованияWSDLиXML Schemaпри организации Web-сервисов. Наиболее популярным программным обеспечением стал инструментарий Globus Toolkit, основанный на использовании Web-служб.
В настояще время (к началу 2008 г.) прдолжается развитие стандартов OGSA организациями Global Grid Forum и Globus Project, объединяющими ряд научных учреждений, занятых развитием гетерогенных сетей. Стандарт OGSA предусматривает интеграцию поддержки языка XML и будущих стандартов Web-сервисов, их встраивание в Grid-системы. Группа Globus Project выпустила предварительную версию инструментального набора Globus Toolkit 3.0, поддерживающего OGSA.
Ведутся работы и по развитию альтернативной спецификации WSRF (WS-Resource Framework) Этот документ состоит из набора спецификаций для выражения связи между ресурсами, обладающими состояниями, и Web-сервисами. В спецификациях определяются конкретные форматы сообщений и связанные определения на XML. В WSRF предусмотрены спецификации WS-Resource Lifetime (определяются способы управления жизненным циклом ресурса и специфицируются Web-сервисы для ликвидации ресурса); WS-Resource Properties (определяются способы запрашивания и модификации ресурсов, описываемых XML-документами Resource Property); WS-ServiceGroup (определяются способы представления и управления коллекциями Web-сервисов и/или WS-ресурсами); WS-BaseFaults (определяется базовый XML-тип, используемый при обмене сообщениями в Web-сервисах для информирования о сбоях) и др.
Однако одного наличия стандартов недостаточно для развития технологии, необходимо, чтобы они обрели поддержку индустрии. Необходимо дополнить стандартные протоколы всевозможными вспомогательными средствами: защитой данных и коммуникаций, мощными механизмами аутентификации, универсальными форматами данных (например, XML), методами управления распределением ресурсов, учета потребления ресурсов пользователями и приложениями, обработки отказов и распределенного администрирования.
В OGSA выделяют несколько иерархических уровней. На нижнем уровне, называемом адаптацией ресурсов, производится управление пакетной обработкой на конкретном ресурсе, обеспечивается унифицированное представление ресурсов в виде совокупности абстрактных типов и операций. На следующем уровне — уровне связи — с помощью известных протоколов Internet выполняется передача (маршрутизация) сообщений с обеспечением безопасности и нужного качества обслуживания (QoS — Quality of Service). К функциям уровня доступа к ресурсам относится сбор сведений о состоянии ресурсов. Эти функции выполняютслужба GRIP(Grid Resource Information Protocol) мониторинга за состоянием ресурсов ислужба GRRP(Grid Resource Registration Protocol), периодически передающая сведения, собираемые с помощью GRIP,серверу GIIS(Grid Index Information Server). Наконец, на уровне кооперации данные, имеющиеся в сервере GIIP, используются для выбора ресурсов для конкретных заданий. На этом уровне используются брокеры, определяющие свободные ресурсы, и диспетчеры, распределяющие задания между ресурсами. Одновременно ведется учет использования ресурсов для начисления платы за предоставляемые услуги.
Web-сценарии и создание интерактивных Web-страниц
Доступ к гипертекстовым документам, расположенным на сервере, осуществляет программное средство, называемоеWWW-сервером(Web-сервером). С его помощью осуществляются также обращения к программам, таким как СУБД, электронная таблица, программы моделирования и т.п., организуется интерактивная работа пользователей. Для использования в WWW-серверах предлагается несколько технологий.
Интерактивная работа пользователей сопровождается визуализацией меняющихся изображений, реакцией системы на определенные действия пользователя или иными операциями по обработке информации при просмотре документов. Эти операции выполняются по сценариям, задаваемым на языке программирования. Применяемые при этом технологии различаются как по типу используемого языка, так и по месту исполнения программ, реализующих сценарии, а также по затратам вычислительных ресурсов. К используемым средствам относятся языки HTML, XML, JavaScript, PHP (Personal Home Pages), VBScript, Perl, Java, технологии CGI, ISAPI (Internet Services Application Program Interface), ASP (Active Server Pages) и др.
Сравнительно простые сценарии обычно представляют на языках типа JavaScript, PHP, VBScript или их разновидностях. Язык PHP близок по своему назначению и сложности освоения к языку JavaScript, но мощнее последнего по функциональности (разнообразие типов данных, поддержка ODBC). Очевидно, что браузер должен поддерживать используемый язык сценариев.
Обычно команды сценария непосредственно включаются в HTML-документ, например, c помощью следующего фрагмента
<SCRIPT LANGUAGE = "javascript">
<!-- сценарий //-->
</SCRIPT>
<!-- сценарий //-->— собственно текст сценария, представленный в виде комментария. Браузеры, не имеющие JavaScript-обработчиков, просто игнорируют комментарий, а современные браузеры исполняют записанные в сценарии команды. Характерной особенностью такого сценария является интерпретация и исполнение команд на клиентском узле.
Технология ASPпоявилась в связи с стремлением сделать интерактивность страниц платформно независимой, поскольку в браузерах может не быть поддержки того языка сценариев, который применен вWeb-странице. Для этого нужно перенести обработку сценария склиентана сервер, что и выполнено в ASP. Обычно в ASP обмен данными между браузером и сервером включает запрос из браузера, передачу формы (таблицы) из сервера для ее заполнения пользователем, пересылку заполненной таблицы на сервер, обработку по сценарию в сервере и возвращение в браузер результата в виде HTML-текста без вставок команд сценария. Следует отметить, что ASP — технология компании Microsoft и связана с использованием компонентов AcniveX, что часто неудобно. В Web-порталах преимущественно используется Java и потому чаще используется аналогичная ASP технологияJSP(Java Server pages).
Обращение к мультимедийным объектам возможно способом связывания, т.е. использованием обычной ссылки на мультимедийный файл, при этом выбор данной ссылки пользователем означает переход к демонстрации визуальной или воспроизведению звуковой мультимедийной информации. Чаще требуется визуальную мультимедийную информацию внедрять в Web-страницу, отводя для показа данных видео или мультипликации часть изображения (экрана). Для внедрения используют компонентыActiveX— программы управления некоторыми операциями, например, визуализацией документа, доступом к базе данных и т.п.
Компонент ActiveX добавляется в Web-страницу с помощью элемента <OBJECT>. В элементе указывают код, по которому будет найден нужный компонент ActiveX, и параметры, такие как адрес мультимедийного файла и расположение поля вывода мультимедийной информации на экране дисплея. Средства обработки мультимедийной информации, представленной в файлах большинства известных форматов таких, как AVI, MOV, MPG, МР3, WAV, MID, обычно встроены в браузеры.
Более сложные сценарии требуют использования прикладных программ, написанных на языках программирования Java, C, C++ и т.п. Если прикладная программа специально создается для использования в Web-среде, целесообразно использовать язык Java.
В ряде случаев используемые прикладные программы не являются платформно независимыми и по этой или иным причинам должны исполняться на сервере. В этих случаях используется технология CGI(Common Gateway Interface — простой шлюзовой интерфейс) или ISAPI (Internet Server Application Program Interface).
В CGI и ISAPI прикладная программа исполняется на сервере. Допустимо использовать программы на различных языках программирования (C/C++, Fortran, Perl, Java, Visual Basic, Apple Script и др.). Но для обеспечения интерфейса Web-сервера с прикладной программой необходимо иметь программу-шлюз (посредник), обрабатывающую запросы, которые поступают от браузера, и передающую обработанные запросы браузеру в нужной для него форме. После исполнения прикладной программы (ПП) шлюз преобразует результаты в приемлемую для визуализации форму (в HTML-документ) и передает результаты обратно браузеру, т.е. для каждой ПП нужно иметь соответствующий обработчик.
Если сервер создан на базе Microsoft Internet Information Server, то вместо CGI лучше использовать технологию ISAPI, как более быстродействующую.
Дальнейшее развитие Web-технологий связано с появлением объектно-ориентированного языка программирования Java. Язык Java позволяет создавать аппаратно независимые приложения, ориентированные на применение в системах распределенных вычислений. Программы на языке Java обладают достаточно высокой вычислительной эффективностью. Эти свойства достигнуты за счет двухэтапной обработки исходных модулей. На первом этапе на сервере производится преобразование исходных модулей в платформно независимый промежуточный байт-код методом компиляции. Благодаря использованию компиляции потеря эффективности, присущая интерпретации, оказывается незначительной. На втором этапе программа, представленная в виде байт-кода и называемаяаплетом(applet), передается на компьютер клиента вместе с Web-страницей. Браузер клиента начинает выполнение аплета при его обнаружении в полученном HTML-файле.
Обращение к Java-аплетам из браузера возможно с помощью специального элемента <APPLET>или заменяющего его элемента<OBJECT>, например:
<APPLET CODE="имя_файла_аплета">
элементы <PARAM>
</APPLET>
Элементы <PARAM>, задают параметры, передаваемые в аплет. В одном HTML-файле можно предусмотреть обращения к нескольким аплетам, находящимся в разных узлах сети. Следует однако отметить, что обычно в целях повышения информационной безопасности загружаемому аплету запрещается обновлять и читать файлы, кроме тех, которые находятся на хосте самого аплета.
Чтобы выполнить Java-программу, необязательно передавать ее браузеру. Как и в технологии CGI, она может исполняться на сервере, в этом случае она называетсясервлетом. Поскольку использование технологии CGI имеет много ограничений, связанных с проблемами производительности и безопасности, технологии сервлетов и JSP получили более широкое распространение.
Сервлет можно определить как серверную версию аплета, используемую для обработки клиентских запросов на Web-сервере. С точки зрения языка, сервлет можно считать классом Java, не имеющим привязки к конкретным платформе или Web-серверу и взаимодействующим с клиентом по стандартной схеме запрос-ответ. Отличиями технологии сервлетов от технологии CGI являются, во-первых, большая простота реализации сервлетов, благодаря присущей языку Java платформенной независимости. Во-вторых, большая эффективность, связанная с тем, что сервлет в процессе транзакции загружается один раз, в то время как в CGI каждое обращение к прикладной программе из обработчика генерирует новый процесс, на что тратится значительное время работы серверного узла.
Для реализации технологии сервлетов на Web-сервере необходимо иметь виртуальную Java-машину и программу связи Web-сервера с сервлетом (аналогично шлюзам в CGI), называемую Web-контейнером (servlet engine). Функциями Web-контейнера являются управление циклом жизни сервлетов — их создание, установка, активизация/деактивизация, сохранение состояния, уничтожение. Web-контейнер обеспечивает интерфейсы "запрос" и "ответ" с сервлетом. Он заносит данные запроса в некоторый объект reqи передает этот объект сервлету вместе с пустым объектомresp. Сервлет обрабатывает информацию, заключенную вreq, и оформляет ответ, заполняя объектresp. Контейнер отправляет ответ клиенту через Web-сервер.
Примерами Web-контейнеров могут служить программы Resin, Tomcat, JRun, JServ. Для создания самих сервлетов используется набор инструментальных средств, например JSDK 1.4 (Java Software Development Kit) фирмы Sun Microsystems.
Поиск информации в Internet
В сетиInternetсуществует уже несколько миллионовсайтов, их число и объем накопленной в Web-сайтах информации продолжают увеличиваться. Большой объем информации имеет как положительную, так и негативную стороны, так как затрудняет поиск данных, требующихся конкретному пользователю в конкретное время. Для облегчения поиска на открытых для доступа сайтах в Internet используютинформационно-поисковые системы(ИПС) иэлектронные каталоги.
Информационно-поисковые системы могут быть документальными, фактографическими или гипертекстовыми.
В документальных ИПС собирается, индексируется и регистрируется информация о документах, имеющихся в обслуживаемой системой группеWeb-серверов. Индексирование включает создание поисковых образов документов. Обычно впоисковый образвходят или все значащие слова, имеющиеся в документе, или только слова из заголовка. Информационно-поисковая система выполняет анализ документов, создание и хранение поисковых образов документов, анализ запросов пользователей, поиск и выдачу пользователю данных о месте расположения в сети запрашиваемых документов. В основе поиска лежит сопоставление запроса пользователя с поисковыми образами документов, в результате отбираются релевантные документы, т.е. документы, чьи поисковые образы соответствуют запросу. Во многих ИПС пользователю предоставляется возможность обращаться к серверу с запросами на естественном языке, со сложными запросами, включающими логические связки. Примерами таких ИПС могут служить системы Excite, Lycos, Altavista и др. Для функционирования Altavista в свое время фирма DEC выделила несколько компьютеров, в том числе 10-процессорную ЭВМ Alpha-8400.
Поисковые образы, называемые также метаописаниями или метаданными, могут представлять собой значения атрибутов документов или множествоключевых слов. Поиск на основе этих двух вариантов поисковых образов называют атрибутивным и контекстным поиском соответственно. Часто используют сочетание этих двух способов поиска.
В фактографических системах хранится структурированная информация в виде фактов, относящихся к определенной предметной области. Примером может служить реляционная БД.
В гипертекстовых системаххранятсягипертекстовые документы.
Поиск в электронных каталогах основан на сопоставлении запроса с разделами информации в иерархической структуре ее классификации.
Классификацию информации называют рубрикацией. Наиболее сложной является разработка тематической рубрикации. В мире существует и применяется ряд систем тематической рубрикации. Так, в России широко известны иерархические системы УДК (Универсальная десятичная классификация) и ГРНТИ (Государственный реестр научно-технической информации). Однако в силу своей громоздкости и естественной консервативности они не всегда удобны для использования в электронных каталогах и информационно-поисковых системах. Поэтому существует ряд частных систем рубрикации с несколькими уровнями иерархии, например, в образовательных порталах.
Отметим, что если в ИПС создание поисковых образов осуществляется автоматически, то в электронных каталогах структура информационных ресурсов определяется квалифицированными людьми.
Примерами поисковых систем, работающих по принципу электронного каталога, служат системы Yahoo!, Galaxy, Looksmart, Yandex. Так, в Yahoo! на верхнем уровне иерархии выделены 14 категорий (например, искусство и гуманитарные науки, образование, бизнес и экономика, наука и др.). Пользователь при поиске осуществляет навигацию по разделам иерархического дерева, спускаясь от верхнего уровня до искомого конечного, на котором он получает сведения об адресах сайтов с нужными информационными ресурсами.
Технологии поиска, основанные на упорядочении метаинформации наподобие библиотечных каталогов (классификации по содержанию), продолжают развиваться, например в создаваемой технологии RDF(Resource Definition Format).
Однако поиск по ключевым словам во всем пространстве Internet не всегда оказывается эффективным. Поиск нужной информации в множестве документов, на которые указывает ИПС в ответ на запрос пользователя, может потребовать слишком много времени. Сделать работу пользователя корпоративной системы в Internet более эффективной позволяет технология порталов, применение языка разметкиXMLи языков поискаXPathилиXQueryв базахXML-документов.
Портал
Концепция порталов появилась в процессе развитияWeb-сайтов.Порталесть ориентированная на пользователя информационная Web-система с единой для каждого конкретного пользователя точкой доступа к разнообразной информации, относящейся к определенному приложению. Порталы, в основном, базируются на технологиях Web-приложений, таких какWeb-серверыи Java 2 Platform Enterprise Edition (J2EE). Если Web-сайты в большинстве случаев представляют собой наборы статическихWeb-страниц, то порталы являются совокупностями программных средств и заранее неструктурированной информации, которую эти средства превращают в структурированные данные по запросу конкретных пользователей.
Типы порталов варьируются в зависимости от пользователей, которым они адресованы, и служб, которые они предлагают.
Общедоступные порталы, такие как Yahoo, открыты для всех и объединяют информацию из различных источников и приложений и поступающую от разных людей, предлагая персонифицированные Web-сайты для произвольных категорий посетителей.
Корпоративные порталы предоставляют сотрудникам предприятий доступ к характерным приложениям и информации, используемым внутри организации.
Порталы в сфере образования создают в образовательных учреждениях. Различают порталы университетские, образовательные, административные, приложений и др. Университетские порталы содержат наиболее общую информацию о вузе, обеспечивают доступ к информации о кафедрах, специальностях, учебных планах, условиях приема абитуриентов и т.п. Другие порталы образовательных учреждений можно рассматривать как части университетского портала. Так, образовательные порталы содержат электронные учебные материалы, методические указания, расписания занятий и консультаций и другие данные, относящиеся непосредственно к учебному процессу.
Торговые порталы, такие как eBay и ChemWeb, — это торговые площадки, которые связывают продавцов и покупателей.
Специализированные порталы, такие как портал MySAP.com, предлагают путь доступа к приложениям определенного вида.
Названные типы порталов предполагают различные сценарии работы, однако все они обладают некоторыми общими характеристиками. Технология сервера порталов предусматривает реализацию порталов с общим набором служб.
Особенности порталов, отличающие их от обычных Web-сайтов:
Программное обеспечение портала позволяет настраивать портал. В порталах обеспечивается автоматическая настройка, заключающаяся в запоминании маршрутов предыдущих обращений пользователя к информационным ресурсам и на этой основе в сокращении числа поисковых шагов при последующих обращениях к аналогичным ресурсам, т.е. автоматическая настройка сокращает путь к неоднократно используемым источникам данных. Ссылки на нужные источники как в базах данных своей корпоративной системы, так и во внешних Web-серверах сохраняются на странице пользователя. Средства портала автоматически собирают информацию из разных источников по результатам настройки и предоставляют ее пользователю. Настройка экрана и фильтров для получения релевантной информации называетсякастомизацией(при настройке на потребности конкретного пользователя) илиперсонализацией(при настройке на класс пользователей).
Пользователю предоставляются удобные средства для настройки (конфигурирования) вида личной страницы в соответствии с его предпочтениями.
Программное обеспечение портала обеспечивает необходимую защиту данных, доступ к приложениям, возможность совместной работы нескольких пользователей и др.
Возможности порталов определяются следующими основными функциями и сервисами (рис. 1):
Поиск как по атрибутам (например, предмет, тип материала, уровень образования), так и по ключевым словам.
Средства публикации и рубрикации материалов.
Персонализация и кастомизация. Служба настройки (customization) распознает различных пользователей и предлагает им информационное наполнение, сконфигурированное с учетом их специфических требований. Эта служба основана на сборе информации о пользователях и сообществах пользователей и должна предоставлять нужное информационное наполнение в нужное время.
Наличие раздела новостей, списков рассылки, средства опроса
Доступ к форумам, справочным базам данных, телеконференциям.
Служба агрегирования информационного наполнения (content aggregation) готовит информацию, полученную из различных источников для различных пользователей. Она учитывает ориентированный на конкретного человека контекст, идентифицируя пользователя с помощью службы защиты и службы настройки.
Служба получения информационного наполнения (content syndication) накапливает информацию из различных источников. Поставщики коммерческого информационного наполнения часто предоставляют информацию в стандартизованных форматах, например, распространенная операция — "клиппировать" (вырезать) копирует информацию с существующих Web-сайтов в формате HTML. Портал для сотрудников, к примеру, может вырезать информацию из внутрикорпоративной интранет-сети.
Служба поддержки устройств (multidevice support) готовит информационное наполнение для различных каналов коммуникаций (например, проводные и беспроводные телефоны, пейджеры и факсы), анализируя их характеристические особенности. Как правило, для этого необходимо фильтровать информационное наполнение (скажем, из информации, предназначенной для беспроводного телефона, при этом удаляют все изображения, а для беспроводных соединений WML — преобразуют HTML в нужный язык разметки).
|
|
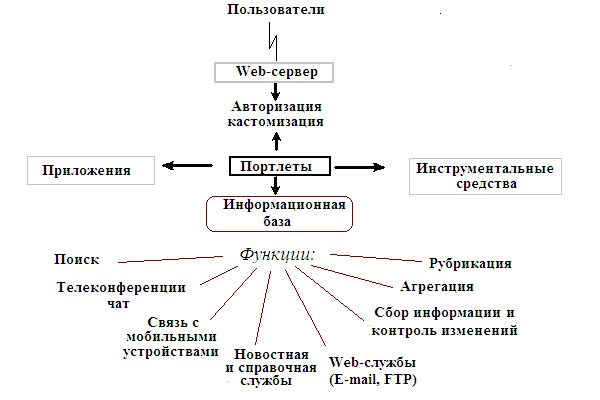
Рис. 1. Основные части и функции порталов
Пользовательский портал должен предоставлять средства коммуникации такие, как электронная почта,файловый обмен, различные видыконференц-связи, участие втелеконференцияхи т.п. В образовательных порталах эти средства успешно используются при реализации связей "студент-преподаватель", "студент-деканат", "студент-студент". Особенно они необходимы при дистанционном обучении.
Дополнительно подразумевается наличие в порталах средств индикации изменений, происходящих в источнике используемой информации. В частности, необходимы средства постоянного контроля доступности ресурсов, расположенных на разных серверах в распределенной ИОС. В образовательном портале необходимо также иметь средства ведения каталога учебных ресурсов, специфического интерфейса авторов и редакторов учебных материалов, фиксируемых в каталоге.
Среда для корректного выполнения и взаимодействия всех сервисов портала обеспечивается ядром –сервером приложений(Application Server). В ядро системы интегрированы функции поддержки авторизации и персональной настройки сервисов портала. Логика работы всех сервисов портала реализуется на основепортлетов– специализированных программных модулей на языке Java (преимущество которого – многоплатформность). Портлетами могут являться как самостоятельные компоненты портала, реализующие конкретный сервис, так и интерфейсы (коннекторы) к интегрированным в портал приложениям и источникам данных. Портал может представлять собой мультиагентную систему, тогда функции управления порталом выполняют программныеагенты.
В основе портала лежит концепция разделения внутренних и внешних функций системы по блокам и модулям. Любой запрос пользователя к порталу проходит через блок, ответственный за авторизацию,аутентификациюи персонализацию. Далее он поступает в блок маршрутизации, где определяется, с какими параметрами должен быть вызван соответствующий функциональный модуль (портлет). Портлет интерпретирует запрос пользователя и выполняет его, обращаясь к программным подсистемам, базам данных, внешним приложениям и другим источникам черезDCOM, JDBC, API,CORBA,HTTPи т. д. Так как в качестве входных данных портлет использует информацию о клиенте и его правах доступа, работа происходит с учетом разделения прав доступа.
Результаты работы портлета представляют собой описание сведений на расширяемом языке разметки данных XML, которое передается блоку, ответственному за их предоставление. Последний форматирует результаты работы портлета с использованием XSL-трансформации на основе различных XSL-шаблонов с учетом персональных предпочтений и типа используемого им клиента: Web-браузер, карманный компьютер, мобильный телефон с поддержкой WAP или какое-либо другое устройство.
Каждый портлет помимо модуля, отвечающего за взаимодействие с пользователями, содержит также административную компоненту, которая позволяет администратору системы определять режимы работы, информационное наполнение и права доступа на работу с конкретным сервисом.
Физически различные портлеты могут выполняться на разных серверах в единой программной среде. Это позволяет балансировать нагрузку и обеспечить высокий уровень безопасности. "Открытые" сервисы портала, к защищенности которых не предъявляются высокие требования, выделяются в одну группу и размещаются на сервере, включенном в общуюкорпоративную сеть. Сервисы, которые нуждаются в большей защищенности от несанкционированного доступа, устанавливаются на выделенном сервере со специальными мерами безопасности на нем.
Аутентификация пользователей при входе в систему и их авторизация при доступе к различным ресурсам выполняется отдельными компонентами портала, служащими элементами системы безопасности. Аутентификация основывается на информации LDAP-сервера. Для обеспечения доступа через Web-интерфейс к корпоративной Интранет-сети может учитываться информация о правах доступа домена Windows NT.
Примером системы создания и поддержки порталов может служить системаWebSpherePortal Server, предлагаемая корпорацией IBM. В IBM разработан также продукт под названием WebSphere Portal — Express Plus. Дополнительно к типичным функциям пакета WebSphere Portal Server, таким как индивидуальная настройка интерфейса, однократная регистрация для доступа к нескольким приложениям, единый механизм аутентификации и взаимодействия для всех компонентов портала, пакет WebSphere Portal-Express Plus поддерживает коллективное обсуждение вопросов (чат), виртуальные комнаты для семинаров, ведение архива различных материалов с возможностями обмена ими и совместной работы над документами.
Список литературы