

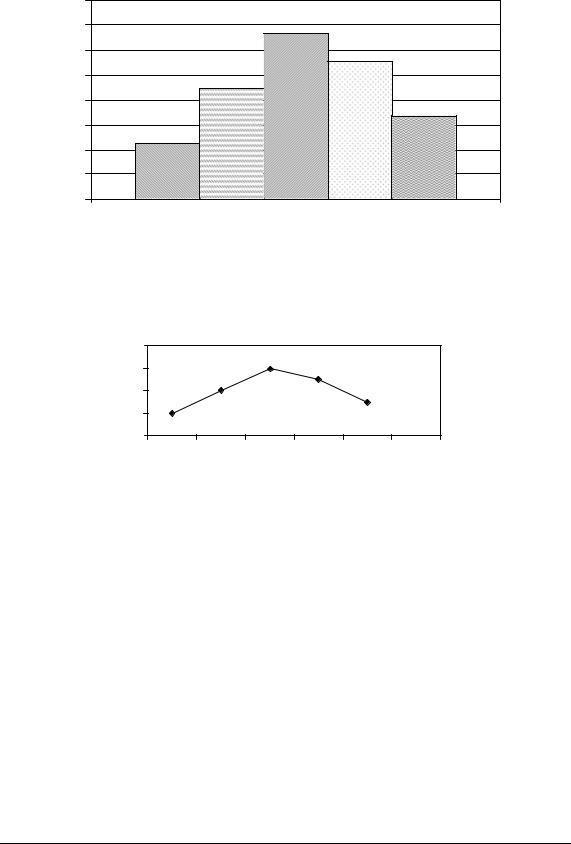
Побудуємо гістограму частот:
hi
8
7
6
5
4
3
2
1
0
[3,7; 4,6) |
[4,6; 5,5) [5,5; 6,4) [6,4; 7,3) [7,3; 8,2) |
x |
Рис. 3.1. Гістограма частот за даними прикладу 3.1
Накреслимо полігон частот:
ni
8
6
4
2
0
4,15 5,05 5,95 |
6,85 0,36 |
x |
Рис. 3.2. Полігон частот за даними таблиці 3.6
3.5. ЕМПІРИЧНА ФУНКЦІЯ РОЗПОДІЛУ. КУМУЛЯТА
Теоретичною функцією розподілу генеральної сукупності або просто функцією розподілу F (x) випадкової величини X називають функцію, яка визначається рівністю
F (x) = P{X < x}.
Емпіричною функцією розподілу випадкової величини X (функцією розподілу вибірки) називають функцію F * (x), що визначає для будьякого дійсного числа x відносну частоту події {X < x}, тобто
|
F * (x) = nx / n, |
(3.13) |
де x |
– зафіксоване довільне число; |
|
nx |
– кількість елементів вибірки, що менша за x; |
|
ДВНЗ “Українська академія банківської справи НБУ”
98

n – обсяг вибірки;
(nx / n) – відносна частота події {X < x}.
Властивості емпіричної функції розподілу F * (x):
1)значення емпіричної функції розподілу належать відрізку [0; 1];
2)F * (x) – неспадна функція;
3)якщо x1 – найменша варіанта, то F * (x) = 0 при x £ x1 ; якщо xk – най-
більша варіанта, то F * (x) =1 при x > xk ;
4)F * (x) – функція, неперервна зліва.
Зв’язок між функціями F (x) та F*(x) встановлює теорема Глівенка. Для будь-якого дійсного числа x за умови необмеженого зростання обсягу вибірки n функція розподілу F * (x) збігається за ймовірністю до теоретичної функції розподілу F (x) , тобто для "e > 0 і для " x Î R:
lim P{ |
|
F * (x) - F (x) |
|
< e } =1. |
(3.14) |
n®¥ |
|
|
|
|
|
|
|
|
Кумулятивна крива (кумулята) використовується для зображення варіаційних рядів, якщо кількість спостережень велика.
Накопиченими називаються частоти, які показують, скільки одиниць сукупності мають значення ознаки не більше ніж значення, що розглядається, і визначаються послідовним додаванням частот інтервалів.
Для побудови кумулятивної кривої необхідно розрахувати накопичені частоти так, що:
·межі першого інтервалу відповідає частота, що дорівнює нулю, а верхній межі – уся частота даного інтервалу;
·верхній межі другого інтервалу відповідає накопичена частота, що дорівнює сумі частот перших двох інтервалів тощо.
Кумуляту вважають наближеним графіком емпіричної функції розподілу.
Зображення варіаційного ряду у вигляді кумуляти особливо зручне при порівнянні варіаційних рядів.
Питання для самоконтролю
1.Що називається полігоном частот (відносних частот)?
2.Що називається гістограмою частот (відносних частот)?
3.Що називається емпіричною функцією розподілу?
4.Які властивості має емпірична функція розподілу F * (x)?
5.Яка теорема встановлює зв’язок між теоретичною функцією розподілу F (x) та емпіричною функцією розподілу F * (x)?
6.Що називається кумулятою?
7.Як побудувати кумуляту?
ДВНЗ “Українська академія банківської справи НБУ”
99

Вправи
1.Графічно зобразити статистичні розподіли, отримані у вправах1-4 пункту 3.3 за допомогою полігона або гістограми.
2.Накреслити емпіричну функцію розподілу випадкової величиниX – кількості покупців, що звернулися до каси за одну годину, використовуючи дискретний статистичний розподіл, отриманий при розв’язанні вправи 1 пункту 3.3.
3.У результаті дослідження зросту ста студентів(юнаків) отримано такі дані (вимірювання проводились з точністю до 1 см):
185 |
193 |
184 |
167 |
170 |
186 |
181 |
166 |
182 |
168 |
179 |
190 |
175 |
169 |
175 |
163 |
178 |
178 |
180 |
175 |
174 |
182 |
185 |
179 |
196 |
177 |
170 |
178 |
175 |
168 |
175 |
168 |
179 |
180 |
181 |
183 |
173 |
183 |
187 |
178 |
173 |
174 |
184 |
178 |
178 |
152 |
170 |
181 |
166 |
181 |
160 |
178 |
184 |
170 |
188 |
188 |
173 |
178 |
163 |
178 |
189 |
193 |
183 |
167 |
171 |
180 |
175 |
197 |
178 |
170 |
179 |
175 |
178 |
190 |
176 |
186 |
183 |
180 |
180 |
183 |
186 |
184 |
179 |
183 |
186 |
170 |
170 |
183 |
178 |
178 |
169 |
171 |
168 |
175 |
168 |
173 |
178 |
183 |
170 |
174 |
Накреслити кумулятивну криву.
4.Статистичне управління провело спостереження числа працівників у філіях ощадбанку та одержало такі дані: 5, 6, 9, 7, 6, 7, 4, 3, 5, 8, 4, 7, 7, 9, 4, 8, 7, 3, 5, 5, 5, 4, 9, 7, 4, 4, 3, 6, 7, 3. Згрупувати статистич-
ний ряд, побудувати полігон частот і відносних частот, гістограму частот (попередньо розбити проміжок на 4 рівні інтервали), гістограму відносних частот, емпіричну функцію розподілу та накреслити її графік.
3.6. ЧИСЛОВІ ХАРАКТЕРИСТИКИ СТАТИСТИЧНОГО РОЗПОДІЛУ ВИБІРКИ
На практиці часто замість повного вивчення даних вибірки буває достатньо обмежитися знаходженням їх числових характеристик. Припустимо, що статистичні дані згруповано в дискретний варіаційний ряд.
Вибірковим середнім x статистичного розподілу вибірки називається середнє арифметичне значення її варіантxi із урахуванням їх частот:
|
|
1 |
k |
n x |
+ n |
2 |
x |
2 |
+ ... + n |
k |
x |
k |
|
|
|
|
|
|
|||||||||||
x = |
|
åni xi = |
1 1 |
|
|
|
|
. |
(3.15) |
|||||
|
|
|
|
|
n |
|
|
|
||||||
|
|
n i=1 |
|
|
|
|
|
|
|
|
|
|||
ДВНЗ “Українська академія банківської справи НБУ”
100
Якщо всі елементи вибірки різні, то вибіркове середнє x є середнім арифметичним значенням ознаки вибіркової сукупності:
n
|
|
åxi |
|
x1 + x2 + ... + xn |
|
(3.16) |
x |
= |
i=1 |
= |
. |
||
n |
|
|||||
|
|
|
n |
|
||
Вибіркове середнє x є основною характеристикою статистичного розподілу вибірки. Його узагальненням є поняття початкового емпіричного моменту.
Початковим емпіричним моментом s-го порядку M S статистичного розподілу вибірки називається середнє арифметичне значення степенів порядку s варіант xi :
|
|
1 |
k |
|
|
M s |
= |
åni xi s . |
(3.17) |
||
|
|||||
|
|
n i=1 |
|
||
Зокрема, M1 = x.
Перейдемо до означенняосновних характеристик розсіювання
значень випадкової величини навколо її середнього значення. Найпростішим показником розсіювання варіаційного ряду є розмах R.
Розмахом вибірки R називають різницю між найбільшим і найменшим значенням її варіант:
R = xmax - xmin . |
(3.18) |
Вибірковою дисперсією DB статистичного розподілу вибірки називається середнє арифметичне значення квадратів відхилень варіант
xi від вибіркового середнього x :
|
|
|
1 |
k |
|
||||||
DB |
= |
|
å(xi - |
|
)2 ni . |
(3.19) |
|||||
x |
|||||||||||
|
|
||||||||||
|
|
|
n i =1 |
|
|||||||
Для обчислення вибіркової дисперсії зручніше використовувати |
|||||||||||
іншу формулу: |
|
|
|
|
|
|
|
|
|
|
|
|
|
1 |
|
k |
|
||||||
DB |
= |
åni xi2 - ( |
|
)2. |
(3.20) |
||||||
x |
|||||||||||
|
|||||||||||
|
|
n i=1 |
|
||||||||
Розмірність дисперсії дорівнює квадрату розмірності значень випадкової величини, що містить у собі деяку незручність, для усунення якої за характеристику розсіювання значень випадкової величини при-
ймають вибіркове середнє квадратичне відхилення s B , яке визначається рівністю:
sB = DB . |
(3.21) |
ДВНЗ “Українська академія банківської справи НБУ”
101

Коефіцієнтом варіації V статистичного розподілу вибірки називається виражене у відсотках відношення вибіркового середнього квадратичного відхилення до вибіркового середнього
V = |
s B |
×100 %. |
(3.22) |
||
|
|
|
|||
|
|
x |
|
||
Центральним емпіричним моментом s-го порядку mS |
статистич- |
||||
ного розподілу вибірки називається середнє арифметичне значення
степенів порядку s відхилень варіант xi від |
середнього вибіркового |
||||||
значення: |
|
|
|
|
|
|
|
|
|
1 |
k |
|
|||
mS |
= |
å(xi - |
|
)S ni . |
(3.23) |
||
x |
|||||||
|
|||||||
|
|
n i =1 |
|
||||
Зокрема, m1 = 0, m2 = DВ .
Для оцінки відхилення статистичного розподілу вибірки від норма-
льного розподілу використовують числові характеристики– асиметрію та ексцес.
Асиметрією (коефіцієнтом асиметрії) As* статистичного розподілу вибірки називається відношення центрального емпіричного моменту 3-го порядку m3 до середнього квадратичного відхилення в кубі sB3
A* = |
m3 |
. |
(3.24) |
s sB3
Ексцесом Ex* статистичного розподілу вибірки називається різниця між відношенням центрального емпіричного моменту4-го порядку m4
до середнього квадратичного відхилення в четвертому степеніs A4 та трійкою:
E* = |
m4 |
- 3. |
(3.25) |
x sB4
Якщо випадкова величина X розподілена за нормальним законом, то її асиметрія та ексцес дорівнюють нулю.
У випадках, коли емпіричні дані згруповані за допомогою інтервального варіаційного ряду для обчислення відповідних числових характеристик вибірки використовують формули(3.15)-(3.25) залишаються без змін, якщо вважати, що в них xi – середини частинних проміж-
ків [ai -1; ai ), i =1, m.
ДВНЗ “Українська академія банківської справи НБУ”
102