

Metoda_PAZ_PC-I
.pdf51
Merge – позволяет слить несколько разделов в один (рис. 3.5);
Рисунок 3.3 – Окно Resize/Move a) и окно Delete б)
а) |
б) |
Рисунок 3.4 – Окно Format a) и окно Convert б)
Split – позволяет разбить раздел на два раздела с переносом данных. Не позволяет переносить операционную систему (рис. 3.6);
Properties – выводит параметры выбранного раздела;
Check for Errors/Windows CheckDisk – проверка диска на
ошибки;
Windows Defragmenter – запускает программу дефрагментации;
Advanced – расширенные опции позволяют изменить букву раздела, проверить на бед-сектора, спрятать раздел, изменить размер кластеров данного раздела и пометить раздел как активный.

Рисунок 3.5 – Окно слияния разделов
Рисунок 3.6 – Окно разбиения раздела
Partition Magic так же позволяет: создавать дополнительные активные разделы для установки дополнительных операционных систем; перераспределять свободное пространство на диске; создавать копии разделов для их дальнейшего восстановления; копировать разделы на другие жесткие диски и т.д. (за дополнительной информацией обращаться на сайт производителя www.powerquest.com/support)
53
3.2Порядок выполнения работы
1.Рассмотреть вопросы подготовки НЖМД к работе.
2.Выполнить разбиение НЖМД на логические диски программой fdisk.exe по указанию преподавателя.
3.Изучить процесс разбиения НЖМД на логические диски, а также их высокоуровневое форматирование с помощью программы PQ Partition Magic 8.0.
3.3Контрольные вопросы
1.В чем заключается процесс подготовки НЖМД к работе?
2.Для чего применяется низкоуровневое форматирование?
3.Как выполнить низкоуровневое форматирование?
4.Что означает высокоуровневое форматирование?
5.Назначение и параметры команд: format и fdisk?
6.Преимущества и недостатки программы format?
7.Назначение и возможности программы PQ Partition Magic 8.0?
8.Преимущества и недостатки программы PQ Partition Magic 8.0?
54
4 ЛАБОРАТОРНАЯ РАБОТА №4
ТЕСТИРОВАНИЕ ПРОГРАММ АРХИВАЦИИ
Цель работы: Провести тестирование различных программ архивации.
4.1Краткие теоретические сведения
Любые методы сжатия данных основаны на поиске в файле избыточной информации и последующем ее кодировании с целью получения минимального объема. Существуют несколько основных методов сжатия данных, которые с теми или иными модификациями используются практически всеми упаковщиками. Обычно упаковщики осуществляют сжатие информации сразу несколькими способами. Такой прием применяется для получения наибольшей эффективности сжатия. Выбор способа зависит от типа данных, и определяется упаковщиком для каждого конкретного случая. Давайте рассмотрим, в каких случаях данные могут содержать избыточную информацию, и как от этого можно было бы избавиться.
Простейший способ сжатия данных основан на анализе требований, предъявляемых к ним со стороны конкретной прикладной задачи, и последующем сохранении только самой необходимой информации.
Например, латинский ASCII текст использует 7-битный код, однако каждый символ обычно записывается 8 битами. Этим с самого начала предопределяется избыточность старшего бита в байте кода символа. Гарантированный коэффициент сжатия 0.875 (отношение сжатого текста к не сжатому) может быть получен простым уплотнением данных. При этом неиспользуемый бит каждого байта будет заполнен данными из других байтов. Для большей наглядности можно себе представить, что каждые 8 латинских символов размещены в 7-байтовом блоке. Описанный метод сжатия легко запрограммировать с помощью любого процедурного языка.
Другой пример удаления избыточной информации можно найти среди приемов сжатия графических образов. Часто графические образы записываются в файлах в виде последовательности байтов, каждый из которых содержит информацию по одному элементу изображения. В действительности для кодирования одного элемента бывает достаточно лишь четырех бит. Мы можем, таким образом, получить гарантированный коэффициент сжатия 0.5 простым заполнением неиспользуемых четырех бит кодом из следующего байта. Такой способ сжатия особенно подходит для компьютеров с ограниченным
55
количеством цветов дисплея или оттенков серого цвета, таких как IBM PC или Atari ST.
При разработке систем с монохромными дисплеями учитывается то, что человеческий глаз в состоянии различать не более 64 оттенков серого цвета. Если разрешение сделать большим, то разница между ближайшими уровнями станет неразличимой и уже не будет влиять на общее восприятие картинки. Поэтому нецелесообразно хранить более 6 бит информации по оттенкам серого цвета, и оставшиеся 2 бита каждого байта могут быть использованы для других целей.
Первая задача, которую нужно решить перед выбором метода сжатиячетко определить, какая часть ваших данных должна быть сохранена, а какая может быть опущена. После этого могут быть применены специальные технические приемы для дальнейшего увеличения степени сжатия.
Рассмотрим более детально два метода сжатия данных: метод cжатия последовательностей одинаковых символов (Run Length Coding)
иалгоритм Хаффмана.
4.1.1Сжатие последовательностей одинаковых символов (Run
Length Encoding – RLE)
Технический прием сжатия последовательностей одинаковых символов является, пожалуй, самым известным среди всех прочих. Но известно также, что для большинства типов данных он обеспечивает лишь очень небольшую степень сжатия. Первоначально он разрабатывался специально для хранения и передачи графической информации. Метод основан на представлении последовательности одинаковых байтов в виде двух величин. Одна из них равна количеству повторяющихся символов, а вторая содержит код символа. Строка NNNMMMNNNNMMMMMMMM, например, может быть записана в виде 3N ЗМ 4N 8М, что дает значительное сокращение длины.
Метод достаточно прост в реализации и лучше всего работает в составе системы, учитывающей типы данных, подлежащих сжатию. Например, двоичный файл может быть записан в виде набора одних только длин битовых строк. Сами элементы могут и не сохраняться, поскольку для двоичных данных существуют лишь два возможных варианта состояний. Каждая новая величина в записи будет означать изменение состояния битовой строки. Таким образом, двоичная строка 111100011000001111 будет записана просто пятью числами 43254.
Главный недостаток рассматриваемого метода кодирования состоит в следующем. Если большая часть документа содержит данные в виде последовательностей отдельных символов, то выходной архивный файл будет больше чем входной. Это объясняется тем, что для
56
записи любой строки, даже единичной длины, всегда требуются два байта.
Программа, использующая метод сжатия последовательностей одинаковых символов, должна четко отслеживать последовательности единичной длины. Это может быть достигнуто с помощью небольшого увеличения объема сжимаемых данных. Если предположить, что мы работаем со стандартным 7-битным ASCII кодом на 8-битных системах, мы можем достаточно просто реализовать подобный алгоритм. В случае последовательности длиной в 1 или 2 байта нужно просто записывать эти последовательности в выходной файл. Если длина последовательности равна трем байтам и более, следует записывать длину в первом байте, а сам символ - во втором байте выходного кода. Чтобы показать, что текущий байт содержит длину последовательности, нужно установить его старший бит (прибавить 128).
Используя такой прием, мы несколько увеличиваем объем кодируемых данных, однако получаем гарантию, что выходной файл будет меньше, чем входной. При декодировании архивного файла вначале нужно осуществлять проверку старшего бита первого байта каждой пары, затем, если бит установлен, записывать второй байт в выходную строку необходимое количество раз.
Описанный метод является простым и очень эффективным способом сжатия файлов. Однако он не обеспечивает большой экономии объема, если обрабатываемый текст содержит мало последовательностей одинаковых символов длиной более двух байтов. Более изощренный метод сжатия данных, используемый в том или ином виде практически любым архиватором — это оптимальный префиксный код и, в частности, алгоритм Хаффмана.
4.1.2 Алгоритм Хаффмана
Алгоритм Хаффмана (Huffman Encoding), или кодирование символами переменной длины, предлагает отказаться от обычного представления файлов в виде последовательностей 7- или 8-битных символов. Главный недостаток такого способа записи файлов состоит в том, что в нем не делается различий между кодированием символов, с разной частотой встречающихся в файлах. Так, наиболее частые в английском языке Е или I, имеют ту же самую длину, что и относительно редкие Z, Х или Q. Код переменной длины позволяет записывать наиболее часто встречающиеся символы и фразы всего лишь несколькими битами, в то время как редкие символы и фразы будут записаны более длинными битовыми строками.
Простейший способ кодирования информации символами переменной длины осуществляется при помощи таблицы соответствий (translation table). Например, анализируя любой английский текст, можно
57
установить, что буква Е встречается гораздо чаще, чем Z, а Х и Q относятся к наименее часто встречающимся. Таким образом, используя таблицу соответствий, мы можем закодировать каждую букву Е меньшим числом бит, используя более длинный код для более редких букв.
Пример:
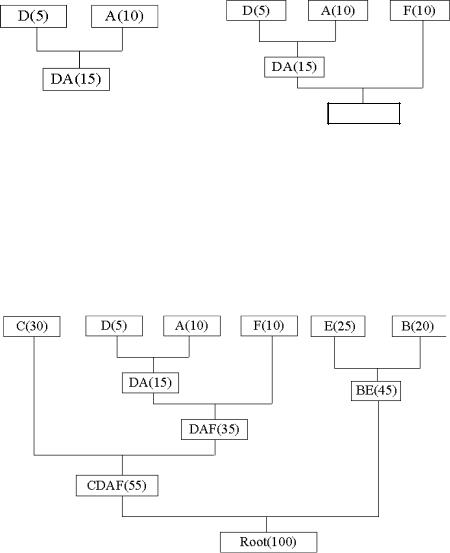
Мы имеем файл длинной в 100 байт. В файле имеется 6 различных символов. Мы подсчитали вхождение каждого из символов в файл и получили следующее : A – 10; B – 20; C – 30; D – 5; E – 25; F – 10.
Теперь эти числа будем называть частотой вхождения для каждого символа.
Мы возьмем из последовательности 2 символа с наименьшей частотой. В нашем случае это D (5) и какой либо символ из F или A (10), можно взять любой из них, например A. Сформируем из "узлов" D и A новый "узел", частота вхождения которого будет равна сумме частот D и A (рис. 4.1, а).
DAF(25)
а) |
б) |
Рисунок 4.1 – Формирование дерева частот вхождения символов
Теперь снова ищем два символа с самыми низкими частотами вхождения, исключая из просмотра D и A и рассматривая вместо них новый "узел" с суммарной частотой вхождения. Самая низкая частота теперь у F и нового "узла". Снова сделаем операцию слияния узлов
(рис. 4.1, б).
Рисунок 4.2 – Формирование дерева частот вхождения символов
58
Рассматриваем таблицу снова для следующих двух символов (B и E). И т.д. Продолжаем пока все "дерево" не сформировано, т.е. пока все не сведется к одному узлу (рис. 4.2).
Теперь, когда дерево создано, можем кодировать файл. Кодирование всегда начинается из корня (Root). Прослеживаем вверх по дереву все повороты ветвей и если делаем левый поворот, то запоминаем 0-й бит, и аналогично 1-й бит для правого поворота. Так для C, необходимо свернуть влево по дереву к 55 (и запомним 0), затем снова влево (0) к самому символу. Код Хаффмана для нашего символа C – 00. Для следующего символа (А) у получается – лево, право, лево, право, что выливается в последовательность 0101. Выполнив выше сказанное для всех символов получим:
C= 00 (2 бита)
A= 0101 (4 бита)
D= 0100 (4 бита)
F= 011 (3 бита)
B= 11 (2 бита)
E= 10 (2 бита)
При кодировании заменяются символы на полученные последовательности.
Хотя такой прием пригоден для текстов любого типа, большинство практических программ вычисляют свою таблицу соответствий для каждого нового документа. Таким образом исключаются случайные отклонения каждого конкретного текста от среднестатистического, и устраняются связанные с этим потери эффективности сжатия.
При разработке реальных программ сжатия данных составление словаря кодирования оказывается несколько более сложным. Кроме того, при кодировании и декодировании информации возникают проблемы, связанные с переменной длиной получаемого кода. Для решения всех этих задач используются специальные технические приемы, которые, однако, не представляют самостоятельного интереса, поскольку не влияют на эффективность сжатия.
4.1.3 Алгоритм Лемпеля-Зива-Велча (Lempel-Ziv-Welch – LZW)
Данный алгоритм отличают высокая скорость работы (как при упаковке, так и при распаковке), достаточно скромные требования к памяти и простая аппаратная реализация.
Hедостаток – низкая степень сжатия по сравнению со схемой двухступенчатого кодирования.
Предположим, что у нас имеется словарь, хранящий строки текста и содержащий порядка от 2-х до 8-ми тысяч пронумерованных гнезд.
59
Запишем в первые 256 гнезд строки, состоящие из одного символа, номер которого равен номеру гнезда.
Алгоритм просматривает входной поток, разбивая его на подстроки и добавляя новые гнезда в конец словаря. Прочитаем несколько символов в строку s и найдем в словаре строку t – самый длинный префикс s.
Пусть он найден в гнезде с номером n. Выведем число n в выходной поток, переместим указатель входного потока на length(t) символов вперед и добавим в словарь новое гнездо, содержащее строку t+c, где с – очередной символ на входе (сразу после t). Алгоритм преобразует поток символов на входе в поток индексов ячеек словаря на выходе.
При практической реализации этого алгоритма следует учесть, что любое гнездо словаря, кроме самых первых, содержащих односимвольные цепочки, хранит копию некоторого другого гнезда, к которой в конец приписан один символ. Вследствие этого можно обойтись простой списочной структурой с одной связью.
4.1.4Обзор программ архивации
Внастоящее время существует очень много различных программ архивации, но наиболее широкое распространение получили только некоторые из них. Это такие программы как:
|
ZIP |
(DOS) |
|
RAR |
(DOS) |
|
AIN |
(DOS) |
|
ARJ |
(DOS) |
|
HA |
(DOS) |
WinZip (Windows)
WinRar(Windows)
|
WinAce |
(Windows) |
|
7-Zip (Windows) |
|
Для каждой программы архивации существует гибкая система настроек, которая позволяет пользователю найти оптимальное соотношение между такими критическими параметрами как время сжатия и коэффициент сжатия.
Время сжатия – время, которое программа архивации затрачивает на сжатие данных.
Коэффициент сжатия – это отношение размера данных после сжатия, к объему данных до сжатия. Чем меньше этот коэффициент, тем более плотно произведена упаковка данных.
60
Каждая программа архивации имеет ряд своих достоинств и недостатков, которые определяют ее отличие от остальных программ архивации.
Например, программа RAR и программа ZIP отличаются тем, что для извлечения произвольного файла из архива RAR извлекает все предыдущие файлы, и только после этого нужный, а программа ZIP извлекает сразу необходимый файл, в результате чего в среднем распаковка данных производится значительно быстрее с помощью программы ZIP.
4.2Порядок выполнения работы
1.Рассмотреть методы сжатия данных.
2.Протестировать программы-архиваторы для различных типов файлов: текст (*.txt, *.doc), видео (*.avi, *.dat), графика (*.gif, *.bmp,
*.jpg, *.djvu, *.pdf), выполняемые файлы (*.ехе, *.сом). Для выполнения тестирование необходимо предварительно создать по одному файлу для указанных выше типов файлов. Размер созданных файлов должен быть больше одного мегабайта.
3.Сравнить между собой тестируемые программы. Для этого необходимо представить в виде диаграмм значения параметров: степень сжатия, время сжатия, время распаковки. Построение диаграмм выполнить в Microsoft Word или в Microsoft Excel.
4.Определить лучшие программы архивации данных. Объясните свой выбор.
5.Описать особенности тестируемых программ.
4.3Контрольные вопросы
1.Какие методы сжатия Вы знаете. Чем они отличаются?
2.Опишите основные параметры программ архиваторов. Как они влияют на время и качество сжатия?
3.Какие программы архивации данных Вы знаете?
4.Сравните известные Вам программы архивации данных.