

Все эти действия реализуются в виде следующего нам

Здесь формулы (1) и (2) заменяют первый символ слова (вместе с *) на А или B. Формулы (3)-(6) перегоняют А и В в конец слова. Формулы (7) и (8) применяются только тогда, когда А и В окажутся в конце слова (когда за ними уже нет символов), и восстанавливают исходный вид первого символа. Формула (9) нужна на случай пустого входного слова. Формула же (10) ставит спецзнак * перед первым символом.
Проверим этот алгоритм на входном слове bаbа и на входном слове из одного символа:
10 2 6 5 6 5 8
bbaba -> * bbaba -> Bbaba -> bBaba -> baBba -> babBa -> babaB |-> babab
10 l 7
a -> *a -> A |-> a
Другое решение
Отметим, что в этом НАМ можно уменьшить число формул, если не вводить новые символы А и В, а использовать вместо них пары *а и *b. Это позволит исключить из НАМ формулы (1) и (2), которые вводят символы AиB, и формулы (7) и (8), которые восстанавливают первый символ. Что же касается «перепрыгивания» этих пар через какой-то символ то оно реализуется формулами вида *aξ -> ξ*a и *bξ -> ξ*b. При этом никакой путаницы между
первым символом слова и остальными символами не будет, т.к. только перед первым символом находится звёздочка.
Итак, возможен и следущий НАМ, решающий нашу задачу:

Проверим этот алгоритм на прежнем входном слове bbaba:
6 4 3 4 3 5
bbaba -> *bbaba -> b*baba -> ba*bba -> bab*ba -> baba*b |-> babab
Пример 8 (использование нескольких спецзнаков)
A={a,b}. Удвоить слово P т.е. приписать к Р (слева или справа) его копию. Например: abb -> abbabb
Решение.
Предлагается следующий план решения задачи:
Приписываем к концу слова Р символ =, справа от которого будем строить копию Р.
Просматриваем по очереди все символы слова Р и, не уничтожая их, переносим копию каждого символа в конец.
3. Удаляем символ =, который отделял слово Р от его копии, и останавливаем алгоритм.
Теперь уточним этот план.
Как приписать некоторый символ к концу слова, мы уже знаем: надо сначала приписать слева к слову какой-то спецзнак, скажем *, затем перегнать его направо через все символы слова и в конце, когда за * не окажется никакого символа, заменить на символ =:
abb -> *abb —> a*bb -> ab*b -> abb* —> abb=
Из предыдущего примера мы также знаем, как переносить символы слова в конец слова. Только теперь сами символы уничтожать уже не надо. Поэтому поступаем так: если надо скопировать символ а, то порождаем за ним новый символ А (заменяем а на аА),после чего этот символ А переставляем с каждым последующим символом (в том числе и с символом =), перенося тем самым А в конец слова, где и заменяем на а:
#abb= -> aAbb= -> abAb= -> abbA= -> abb=A -> abb=a Аналогично копируются и символы b.
Главный вопрос здесь: как узнать, какой именно символ исходного слова мы только что скопировали и какой символ надо копировать следующим? Для этого используем стандартный приём со спецзнаком - будем помечать новым спецзнаком # тот символ, который должен копироваться следующим (вначале это первый символ входного слова):
#abb= -> a#Abb= -> а#bАb= -> а#bbА= -> a#bb=A -> a#bb=a .Как только копия очередного символа окажется в конце, спецзнак # должен «запустить» процесс копирования следующего символа:
a#bb=a -> ab#Bb=a -> ab#bB=a -> ab#b=Ba -> ab#b=aB -> ab#b=ab ->
-> abb#B=ab -> abb#=Bab -> abb#=aBb -> abb#=abB -> abb#=abb
Когда справа от спецзнака # окажется символ =, это будет означать, что входное слово полностью скопировано. Осталось только уничтожить символы # и = после чего остановиться.
Теперь отметим, что в НАМ, реализующем такое копирование, важен взаимный порядок расположения формул (Aξ->ξA, Вξ->ξB, А->а и В->b), которые переносят символы А и В в конец и там восстанавливают символы а и b, и формулами (#а->а#А и #b->b#B), которые «вводят в игру» символы А и B. Поскольку последняя пара формул должна срабатывать только после того, как символ А или В будет полностью перенесён в конец и заменён на а или b, то эта пара формулы должна располагаться в НАМ ниже всех первых формул.
И ещё один момент. В этом НАМ используются два спецзнака * и #, первый из которых нужен для приписывания символа = справа к входному слову, а второй - для указания, какой символ слова должен копироваться следующим. Как ввести эти спецзнаки? Отметим, что использовать для этого две формулы —>* и -># нельзя, т.к. первая из них будет блокировать доступ ко второй. Оба этих спецзнака надо вводить сразу одной формулой ->#* . При этом надо учитывать, что формулы с * должны применяться самыми первыми, поэтому они должны располагаться в начале НАМ. Формулы же с #, А и В должны располагаться ниже, чтобы они работали только после того, как исчезнет * и появится символ =.
С учетом всего сказанного получаем следующий НАМ:
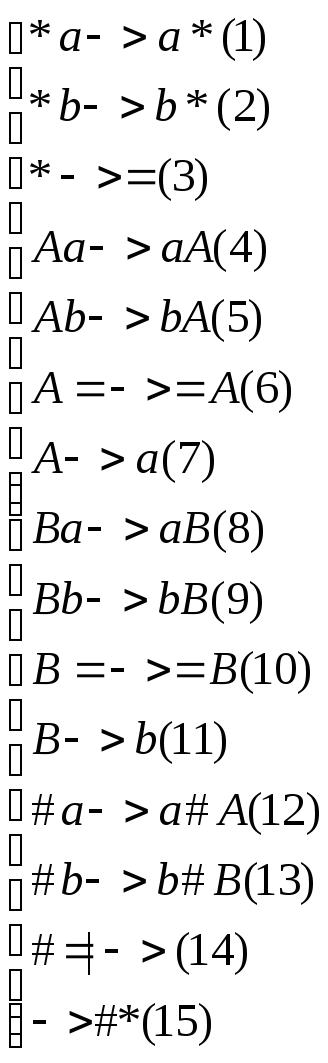
Здесь формулы (1)-(3) «перегоняют» звёздочку в конец входного слова и заменяют её на символ =. Формулы (4)-(7) перегоняют символ А в конец слова, после чего заменяют на a. Формулы (8)—(11) делают то же самое с В и b. Формулы (12 и (13) «вводят в игру» символы А и В, соответствующие тому символу входного слова, который должен быть скопирован следующим.
Формула (14) применяется только тогда, когда справа от # нет ни а, ни b, т.е. когда полностью просмотрено всё входное слово. И, наконец, формула (15) вводит сразу два спецзнака # и *.
Проверим данный алгоритм на двух входных словах - на пустом и на abb:
15 3 14
<пустое слово> —> #* -> #= |-> (т.е. получили <пустое слово><пустое слово>)
15 1,2 3 12 4-6 8 12
abb -> #*abb => #abb* -> #abb= -> a#Abb= -> a#bb=A -> a#bb=a ->
12 8-10 11 12 8-10 11
-> ab#Bb= -> ab#b=aB -> ab#b=ab -> abb#B=ab -> abb#=abB ->
14
->abb#=abb |-> abbabb
Другое решение
Приведём ещё одно решение задачи удвоения слова, в котором предлагается выполнить следующие действия.
1. Сначала за каждой (малой) буквой входного слова вставляем её двойник - соответствующую большую букву. Для этого приписываем слева к слову спецзнак *, а затем переносим его через каждую малую букву так, чтобы слева от него остались эта буква и её двойник. В конце слова заменяем * на новый спецзнак #, который нам ещё понадобится:
abb -> *abb -> aA*bb -> aAbB*b -> аАbВbВ* -> аАbВbВ#
2. В получившемся слове переставляем малые и большие буквы так, чтобы слева оказались все малые буквы, а справа - все большие, сохраняя при этом исходный взаимный порядок как среди малых, так и среди больших букв:
аАbВbВ# -> ... -> abbABB#
3. Как видно, справа мы получили копию входного слова, но записанную большими буквами. Осталось только заменить их на малые буквы. Вот здесь-то и понадобится спецзнак #: будем перемещать его влево через каждую большую букву с заменой её на малую. Когда слева от # уже не окажется большой буквы, надо уничтожить # и остановиться:
abbABB# -> abbAB#b -> abbA#bb -> abb#abb |-> abbabb
Все указанные действия описываются в виде следующего НАМ

2.3 Задачи для самостоятельного решения
Замечания:
В задачах рассматриваются только целые неотрицательные числа, если не сказано иное.
Под «единичной» системой счисления понимается запись неотрицательного целого числа с помощью палочек - должно быть выписано столько палочек, какова величина числа; например:
2-> ||,5->|||||,0-> <пустое слово>.
A={f,h,p}. В слове Р заменить все пары ph на f
A~{f,h,p). В слове Р заменить на f только первую пару ph, если такая есть.
А={а,b,с]. Приписать слово bас слева к слову Р.
А={а,b,с]. Заменить слово Р на пустое слово, т.е. удалить из Р все символы.
А={а,b,с}. Заменить любое входное слово на слово а.
Выписать НАМ, не меняющий входное слово (при любом алфавите А).
Альтернативный алгоритм
*a->aA* Bb->bA
*b->bB* A#->#a
*-># B#->#b
Aa->aA #->|
Ab->bA ->*
Ba->aB
_bbab->*bbab->bB*bab->bAbB*ab->bBbBaA*b->bBbBaAbB*->bBbBaAbB#
->bBbaBAbB#->bbBaBAbB#->bbaBBAbB#->bbaBBbAB#->bbaBbBAB#
->bbabBBAB#->bbabBBA#B->bbabBB#ab - >bbabB#bab->bbab#bbab
->bbabbbab
1.Создается копия каждого символа входного слова в виде альтернативного символа
Спец.символ * помечает тот символ входного слова, который еще не имеет копии. Когда созданы все копии * меняется на #
2.Копии символов перегоняются в конец исходного слова и размещаются перед #
3.Символы-копии заменяются на исходные символы. При этом # помечает ту копию, которая еще не преобразована.
Задачи теоретического характера
Обозначения:
Последовательность из n-подряд идущих одинаковых символов. Слово в алфавите А означает, что слово состоит только из символов входного алфавита.
Если некоторый алгоритм H применим к слову P, то результат-H(P)
Применимость алгоритмов-
Алгоритм считается применимым к входному слову P если при обр. этого слова он остановится через конечное слово шагов.
Областью применимости алгоритма относительно некоторого алфавита называется множество таких слов в алфавите к которым алгоритм применим.
Пример 1
Определить область применимости НАМ относительно алфавита А={a,b}
b->b a->|b
Областью применимости алгоритма являются слова, состоящие только из символов a
a->|b b->b
Областью применимости являются все слова, содержащие хотя бы 1 символ “a” или пустое слово
Пример 2
Построить НАМ который применим ко всем словам, кроме abc
baac
#a->a#
#b->b#
*abc#->*abc#
*baac#->*baac#
*->|
->*#
Самоприменимость- применимость алгоритмов к самим себе. Это не совсем корректно т.к на вход НАМ должны подаваться линейные последовательности символов, а НАМ таковой не является.
Для применения данного алфавита к НАМ его алгоритм необходимо вывести в линию.
Запись НАМ- словоЮ состоящее из последовательно записанных формул подстановки через ;
#a->a#; #b->b#;…
Тогда самоприменимость НАМ- применимость алгоритма к его записи.
Пример
#a-># 2) a->b
#->| b->bb
->#
Алгоритм самоприменим
#a->#; #->|; ->#; #->#; #->|; ->#; ->#; #->|; #->|; ->#;
Несамоприменимый алгоритм, т.к он заканичивается
a->b; b->bb b->b; b->bb bb->b; b->bb bbb->bb; b->bb;
Пример 3
Построить НАМ, который не самоприменим, но применим к любому слову b{a,b}
Для решения этой задачи необходимо чтобы в алгоритме команда, выполняющая замену символов, отсутствующих во входном алфавите. Тогда такой алгоритм зацикливатся на своей записи, но обраб. символы извходного алфавита
Например: *->*
Пример 4
Проблема самоприменимости алгоритмически неразрешима, т.е не существует единого алгоритма, позволяющего определить саморименим ли алгоритм. Однако в частных случаях эта задача разрешима, а именно, если алгоритм состоит из одной подстановки.
Доказательство:
Если алгоритм состоит из одной подстановки, то по его виду можно определить самоприменим ли он
£->ϐ £->|ϐ
Метод проверки самоприменимости
Если ед.форма алгоритма заключительная, то такой алгоритм всегда самоприменим. Если ед.форма алгоритма обычная, то такой алгоритм будет самоприменим, если левая часть подстановки не входит правую часть подстановки
Эквивалентность алгоритмов
Эквивалентными называются алгоритмы которые предлагают разные способы решения для одной и той же задачи, т.е для одинаковых входных слов эти алгоритмы выдают одинаковые выходные слова.
Необходимо учитывать, для оценки эквивалентности зацикливания алгоритма т.е если какой-то алгоритм зацикливается на некотором наборе слов, то эквив. след. также должен зацикливатся на таком же наборе слов.
H1(P)=H2(P)
Пример:
Являются ли эквив.
H1: a->|a
H2:a->|a
b->b
Данные
алгоритмы являются эквивалентны в
алгоритме A={a}
,но не эквивалентны в алфавите A={a,b}
,т.к при входном слове P=![]() алгоритмH1
остановится(является применимым к этим
словам), а алгоритм H2
зациклится
алгоритмH1
остановится(является применимым к этим
словам), а алгоритм H2
зациклится
Пример
Определить эквивалентны ли следующие пары НАМ относительно A={a,b}
1) H1: a->|b H2:*b->b*
*a->|b
->*
2) H1 : a->b H2: a->aa
b->a b->bb
3) H1: aa->a H2: *aa->a*
*b->b* *->|
->*
Необходимо установить:
Совпадают ли их области применимости
Если области применимости не совпадают, то алгоритмы не эквивалентны
Если области применимости совпадают необходимо проверить, что при одинаковых входных словах эти алгоритмы выдают одинаковые результаты
Область применимости H1-все слова в алфавите {a,b}
Алфавит H2 не применим к словам не содержащим “a” . Поскольку области применимости не совпадают -> алгоритм не эквивалентен
Область применимости H1- пустое слово. Область применимости H2-пустое слово.
Для данной пары алгоритмов совп. области применимости и результаты обработки <> алгоритмы эквивалентны.
Областью применимости H1- все слова из алфавита {a,b}
H2-также являются все слова
Не эквивалентны т.е дают разные результаты
Композиция алгоритмов
Композиция алгоритмов подразумевает использование следующих методов:
Суперпозиция алгоритмов
Алгоритм в n-й степени
Итерация
Суперпозиция аналогична выполнению функции над функцией. Например: Bin(cos x)
Композицией НАМ относительно алфавита A называется такой алгоритм H для которого при любом входном слове P алфавита A выполняются следующие условия:
Если H1 не применим к слову P, то и H к нему не применим
H=H1*H2-> H1(H2)
Если H1 применим к слову P, а H2 не применим к слову H1(P), то алгоритм H также не применим к слову P
Если H1 применим к P и H2 применим к H1(P) то H применим к P
H(P)==H2(H1(P))
Для суперпозиции НАМ нельзя выполнять простое дописывание операцией- подстановка одного алгоритма к операциям- подстановка другого, т.к в НАМ очень важна последовательность этих подстановок
Для любых нормальных алгоритмов Н1 и Н2 существует нормальный алгоритм Н, который является их композицией относительно соответствующего алфавита.
Способ построения списков формул подстановок для алгоритма Н на основании списков формул подстановок Н1 и Н2 существует, но чень громоздкий
Поэтому предложим выполнить композицию используя следующую методику:
Определить какую задачу решает каждый из алгоритмов Н1 и Н2
Последовательность этих задач объединить в одну общую задачу
Разработать НАМ для решения этой задачи
Пример:
H2:![]()
H=H1*H2->H1(H2)
H1: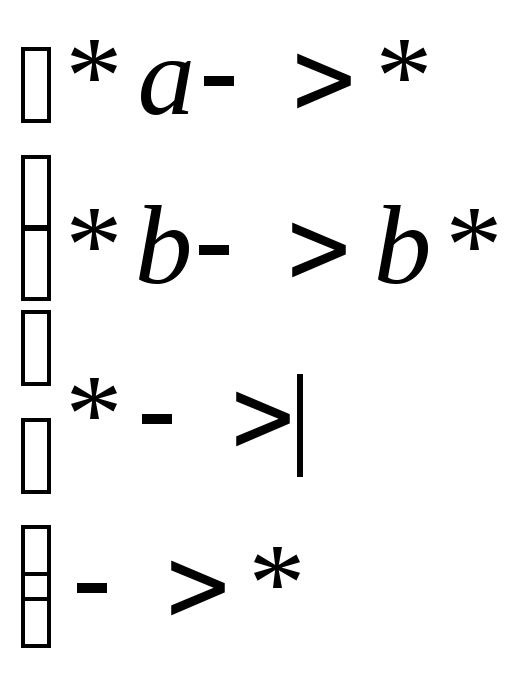
Алгоритм Н1 реализует удаление символов a
Алгоритм Н2 заменяет все “b” на “a”
Результирующий НАМ должен удалить все символы а и затем все символы b должны заменяться на a
_bbabaa -> *bbabaa ->a*babaa ->aa*abaa ->aa*baa ->aaa*aa ->aaa*a ->aaa*
->|aaa