

Регулирование и стандартизация штрих-кодов
Как уже отмечалось выше, присвоением штрих-кодов занимается международная некоммерческая и неправительственная организация — Ассоциация EAN, созданная в 1977 году.
Ассоциация автоматической идентификации ЮНИСКАН/GS1 Russia как член GS1 является единственной организацией товарной нумерации — представителем GS1 на территории Российской Федерации. GS1 предоставила ЮНИСКАН/GS1 Russia право использования товарного знака «GS1» в Российской Федерации.
Ассоциация ЮНИСКАН/GS1 Russia — добровольная некоммерческая организация, существующая исключительно на членские взносы её участников. Присвоение номеров GS1 для членов Ассоциации осуществляется бесплатно.
Техническим комитетом ГОСТ Р/ТК 355 разработаны государственные (ГОСТ Р) и межгосударственные (ГОСТ) стандарты, определяющие требования для символик штриховых кодов, в частности, такие как:
ГОСТ ИСО / МЭК 15420-2001 «Автоматическая идентификация. Кодирование штриховое. Спецификация символики EAN/UPC (ЕАН/ЮПиСи)»;
ГОСТ Р 51001-96 “Автоматическая идентификация. Штриховое кодирование. Требования к символике штрихового кода “2 из 5” чередующийся”;
ГОСТ Р 51002-96 “Автоматическая идентификация. Штриховое кодирование. Требования к символике штрихового кода 39”;
ГОСТ Р 51003-96 “Автоматическая идентификация. Штриховое кодирование. Требования к символике штрихового кода 128”;
ГОСТ Р 51201-98/EN 797 “Автоматическая идентификация. Штриховое кодирование. Требования к символике кода EAN/UPC”;
ГОСТ Р 51294.6-2000 (ИСО/МЭК 16023-2000) "Автоматическая идентификация. Кодирование штриховое. Спецификация символики MaxiCode (Максикод)";
ГОСТ Р 51294.9-2002 (ИСО/МЭК 15438-2001)"Автоматическая идентификация. Кодирование штриховое. Спецификации символики PDF417 (ПДФ417)";
ГОСТ 30742-2001 (ИСО/МЭК 16388-99)"Автоматическая идентификация. Кодирование штриховое. Спецификация символики Code 39 (Код 39)";
ГОСТ 30743-2001 (ИСО/МЭК 15417-2000)"Автоматическая идентификация. Кодирование штриховое. Спецификация символики Code 128 (Код 128)";
Стандарты ААИ ЮНИСКАН/EAN РОССИЯ/AIM РОССИЯ:
СТО ЮНИСКАН/ENV 606“Автоматическая идентификация. Штриховое кодирование. Этикетки со штриховыми кодами для транспортирования и отгрузки продукции из стали”;
СТО ЮНИСКАН/ENV 1649“Автоматическая идентификация. Штриховое кодирование. Факторы, влияющие на считывание символов штрихового кода”;
СТО ЮНИСКАН/EN 1556 “Автоматическая идентификация. Штриховое кодирование. Термины и определения”;
СТО ЮНИСКАН/EN 1635 “Автоматическая идентификация. Штриховое кодирование. Требования к контролю символов штрихового кода”;
СТО ЮНИСКАН/EN 798 “Автоматическая идентификация. Штриховое кодирование.
Принципы построения штриховых кодов
Существует свыше 200 конфигураций штриховых кодов, занесенных в каталог, и, вероятно, намного больше конфигураций, которые используются только разработчиками. Информация, подлежащая кодированию, представляет собой то, что бы люди хотели выразить устно. Штриховой код есть язык, несущий информацию и данные. Различные виды кодов создаются для того, чтобы добиться определенной цели, например, простоты ввода данных, легкости сканирования, ограничения длины кода или использования чисел, букв или специальных знаков. В некотором смысле это игра по созданию новых конфигураций в целях выполнения специальных работ.
Штриховое кодирование и штрих-коды бывают линейными, двухмерными или матричными, круговыми и композитными.
Линейное кодирование —это метод автоматизированного сбора данных, при котором источником информации является линейный код, представляющий собой чередование штрихов и пробелов разной ширины (рис. 2.1).

Рис. 2.1. Линейный штрих-код
Линейные символики позволяют кодировать небольшой объём информации (до 20—30 символов, обычно цифр). Наиболее распространенными линейными кодами являются:
ЕAN 13 (используются 13 цифр);
EAN-8 (состоит из 8 цифр);
UPC (UPC-A, UPC-D, UPC-E);
Code39;
Code128 (UCC/EAN-128);
Codabar;
«Interleaved 2 of 5» и т.д.
Двухмерными называются символики, разработанные для кодирования большого объёма информации. Расшифровка такого кода проводится в двух измерениях (по горизонтали и по вертикали). Данный код может включать в себя гораздо больший объем информации (до нескольких страниц текста). Разработано более 20 различных символик двухмерных штрих-кодов. Наиболее популярны коды Aztec,Datamatrix,PDF417. На рис. 2.2 представлен пример двухмерного кода.

Рис.2.2. Двухмерный штрих-код
В настоящее время наиболее распространён вид двухмерного штрих-кода Aztec. В каждом символе можно выделить область мишени и область данных. Мишень представляет собой набор концентрических квадратов и служит для определения геометрического центра символа в процессе его декодирования.
Существуют три основных формата символа Aztec Code:
«Compact» (Компактный) символ с мишенью из двух квадратов
«Full-Range» (Полный) символ с мишенью из трех квадратов.
Datamatrix
Код Datamatrixэто двумерный матричный штрих-код, содержащий чёрно-белые элементы или элементы двух различных степеней яркости в форме квадрата, размещённые в прямоугольной или квадратной группе. Таким образом может быть закодирован текст или строковые данные. Размер закодированных данных может составлять от нескольких байтов до 2 килобайтов. Преимуществами этого кода является возможность нанесения перманентной гравировки (лазером, механическим способом и т.п.) на металлические поверхности позволяет маркировать кодом изделия и устройства, подвергающиеся воздействиям критических температур, давлений или химических веществ.
Композитный кодобъединяет в себе двухмерный и линейный код, позволяя, таким образом, использовать для считывания различное оборудование. Пример такого кода - Aztec Mesa.
Штриховой символ кодового словалинейного штрих-кода, как правило, состоит из четырех частей:
комбинации элементов «Начало», обозначающей начало слова и определяющей направление считывания;
серии информационных элементов, т.е. элементов, которыми представлены данные;
комбинации элементов одного или нескольких контрольных знаков, обеспечивающей автоматическую проверку правильности считывания и надежность дешифрации закодированных данных;
комбинации элементов «Конец», обозначающей конец слова.
Каждый штриховой код вне зависимости от версии характеризуется следующими показателями: числом и высотой знаков, шириной модуля и др.
Число знаков N в кодовом обозначении определяет длину кода. Естественно, желание проектировщика и производителя, наносящего знак на упаковку, — минимизировать число знаков, так как это позволяет:
свести к минимуму площадь упаковки, выделяемую для размещения и нанесения штрихового кода;
обеспечить надежность считывания информации;
строго ограничить объем выносимой на упаковку информации необходимым минимумом.
Как правило, каждое кодовое обозначение на упаковке товара сопровождается пробной цифрой, которая предназначена, повышения надежности считывания кода. В спецификации код всегда указываются вид и положение пробной цифры. При этом необходимо помнить, что положение пробной цифры известно только поставщику считывающего устройства, и оно не расшифровывается. Кроме того, в каждом кодовом обозначении обязательно присутствует пробная цифра, подлежащая расшифровке после считывания.
При этом высота штриха выбирается только из соображений легкости считывания, которое осуществляется при помощи специальных оптических устройств — сканеров, называемых зачастую бар-сканерами. Луч считывающего устройства должен пересечь все штрихи кода для того, чтобы прочитать закодированную в нем информацию. Это достигается при достаточной высоте штриха.
Для удобства построения самый узкий штрих, который называют модулем,принимается в качестве базового. Другие штрихи и пробелы составляют 2 и 3 модуля, т.е. 2 или 3 толщины самого узкого штриха или пробела. Таким образом, все остальные линейные поперечные размеры штрихов и пробелов кратны целому числу этих модулей. Ширина модуля для конкретного штрихового кода является величиной постоянной, хотя для одного и того же стандарта штрихового кода могут применяться различные по размеру модули, что в свою очередь позволяет получать различные изображения. Такой метод построения штрихового кода существенно облегчает его печать и последующее считывание. В частности, в уже упомянутой символике кодаEAN-13 модуль может меняться от 0,264 мм до 0,66 мм.
Ширина модуля Х представляет собой ширину наименьшего штриха или интервала между штрихами. Значение этого параметра двояко. С одной стороны, чем меньше модуль, тем более компактно кодовое обозначение, с другой — излишний малый модуль затрудняет считывание кода. Для выбора типа считывающего устройства требуется знание ширины модуля. Так, если модуль Х равен 0,4 мм, то разрешающая способность считывающего устройства должна быть менее чем 0,4 мм. Для кодов с двумя видами элементов по ширине важным параметром является соотношение этих двух элементов V, которое, как правило, принимается равным соотношению 3:1 или 2:1.
Всякое кодовое обозначение должно иметь ограничители. В штриховом кодировании таким ограничителем в конце и в начале кода является спокойная зона R. В том случае, если считывающее устройство ручное, то R = 10%, т.е. примерно 2,5 мм, а при использовании сканирующего устройства или считывающей камеры R = 15%, т.е. приблизительно 6,5 мм.
Высота кодового обозначения Н при применении ручных считывающих устройств должна быть равной 15% от длины штрихового кода, но не менее 6,5 мм, а при считывании сканером или камерой — не менее 25% от его длины. Эти рекомендации по высоте кода даны для статических операций считывания. В случае же считывания кода с движущегося товара Н должна корректироваться опытным путем.
Каждая символика штрихового кода имеет алфавит — соответствие набора цифр кода определенному сочетанию пробелов и штрихов. Так, если расшифровать алфавит кода EAN-13применительно к товарам потребительского назначения, то каждая цифра (разряд) кода представляет собой сочетание двух штрихов и двух пробелов (рис. 2.3).

Рис. 2.3. Алфавит штрихового кода EAN-13
Первые две-три цифры, называемые обычно флагом,обозначают страну происхождения товара (табл. 2.1, рис. 2.4). Присвоение кода внутри любой страны производится торгово-промышленной палатой, где регистрируется каждый производитель товаров. Следующие четыре-пять цифр указывают на фирму-производителя товара. Затем наносятся еще пять цифр, обозначающих код товара.
Таблица 2.1
Структура кода EAN-13
|
ХХХ |
ХХХХХ |
ХХХХ |
Х |
|
Код страны происхождения товара
|
Код фирмы-производителя товара
|
Код товара (артикул)
|
Контрольный знак
|
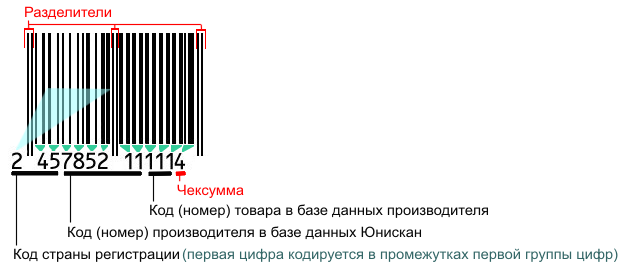
Рис 2.4. Разбор кода EAN13
Последняя цифра контрольная и используется для правильного считывания предшествующих цифр, обеспечивая тем самым надежность штрихового кода. Рассчитывается она по следующей методике:
складываются цифры, стоящие на четных позициях кода;
результат первого действия умножается на 3;
складываются цифры, стоящие на нечетных позициях кода;
складываются результаты 2-го и 3-го действий;
определяется контрольное число, представляющее собой разность между полученной суммой и ближайшим к нему большим числом, кратным 10.
Так, медицинский препарат имеет код 4601026034169 (рис. 2.3). Судя по флагу, данный продукт является российским товаром. Так ли это? Просчитаем контрольную цифру. У кода 4601026034169 она равна 9.
1. 6 + 1 + 2 + 0 + 4 + 6 = 19.
2. 19 х 3 = 57.
3. 4 + 0 + 0 + 6 + 3 + 1 = 14.
4. 57 + 14 = 71.
5. 80 – 71 = 9.
Итак, в результате расчетов мы получили контрольное число 9, что соответствует товару из России.
Таблица 2.2
Флаг кода, присвоенный странам мира Международной ассоциацией EAN
|
Страна-носитель кода
|
Флаг кода EAN
|
Страна-носитель кода
|
Флаг кода EAN
|
|
США
|
00-09
|
Мальта
|
535
|
|
Франция
|
30-37
|
Ирландия
|
539
|
|
Япония
|
45,49
|
Португалия
|
560
|
|
Великобритания,
|
|
Исландия
|
569
|
|
Северная Ирландия
|
50
|
Польша
|
590
|
|
Люксембург, Бельгия
|
54
|
Венгрия
|
599
|
|
Дания
|
57
|
ЮАР
|
600-601
|
|
Финляндия
|
64
|
Марокко
|
611
|
|
Норвегия
|
70
|
Китай
|
690
|
|
Швеция
|
73
|
Израиль
|
729
|
|
Швейцария
|
76
|
Гватемала, Гондурас,
|
|
|
Италия
|
80-83
|
Никарагуа, Панама
|
740-745
|
|
Испания
|
84
|
Мексика
|
750
|
|
Нидерланды
|
87
|
Венесуэла
|
759
|
|
Австрия
|
90-91
|
Колумбия
|
770
|
|
|
|
Перу
|
775
|
|
Австралия
|
93
|
Уругвай
|
773
|
|
Новая Зеландия
|
94
|
Аргентина
|
779
|
|
Болгария
|
380 .
|
Чили
|
780
|
|
Словения
|
383
|
Эквадор
|
786
|
|
Хорватия
|
385
|
Бразилия
|
789
|
|
Германия
|
400-440
|
Куба
|
850
|
|
Россия
|
460-490
|
Чехия и Словакия
|
859
|
|
(для книг код ISBN)
|
978
|
|
|
|
Латвия
|
4605
|
Югославия
|
860
|
|
Тайвань
|
471
|
Турция
|
869
|
|
Эстония
|
474
|
Южная Корея
|
880
|
|
Филиппины
|
480
|
Таиланд
|
885
|
|
Гонконг
|
489
|
Сингапур
|
888
|
|
Греция
|
520
|
Индонезия
|
899
|
|
Кипр
|
529
|
Малайзия
|
955
|
Необходимо помнить, что флаг кода закреплен за страной-производителем товара, но может обозначать и страну регистрации дочернего предприятия-изготовителя. Кроме того, он может указывать на страну-партнера, если предприятие совместное, или на страну, куда поставляется большая часть продукции. По существующим в нашей стране правилам, импортное изделие, реализуемое в торговой сети, может и не иметь на упаковке кода своей страны. Если какая-либо иностранная фирма зарегистрировала свой товар, например, в «Юнискам», то по существующим правилам штрихового кодирования он получает индекс 46, т. е. российский код EAN. Но это не означает, что товар изготовлен в России. Поэтому при чтении штрихового кода лучше посмотреть на дополнительную надпись на упаковке товара, указывающую на страну его изготовления. Необходимо также помнить, что каких-либо указаний о дате изготовления товара большинство кодов, в том числе и EAN-13, не имеет.
В том случае, если габаритные размеры маркируемого товара не позволяют разместить на нем штриховую версию EAN-13, можно воспользоваться версиейEAN-8 (табл. 2.3). Использование кодаEAN-8характерно для товаров, продаваемых вразвес.
Таблица 2.3
Структура кода EAN-8
|
ХХ |
ХХХ |
ХХ |
Х |
|
Код страны происхождения товара
|
Код фирмы-производителя товара
|
Код товара (артикул)
|
Контрольный знак
|
При печатании штриховых символов кода на продаваемых в розничной торговле товарах возникает необходимость с учетом формы упаковки и ее габаритных размеров увеличивать или уменьшать размеры штрихового кода по отношению к базовым размерам. При этом стараются изменить высоту кода, оставляя неизменной ширину. Однако такая мера требует соблюдения следующего условия: высота штрихов должна быть равной половине ширины штрихового символа кодового слова.
Все разновидности кода UPC/EANнаиболее распространены для кодирования товаров в пищевой промышленности. Кроме того, он широко используется в оптовой и розничной торговле, являясь комплексным кодом с точки зрения считывания и печатания.
Bпромышленности чаще всего прибегают ккоду 39,содержащему как цифровую, так и алфавитную информацию, с помощью которой можно закодировать 42 характеристики продукта. Во многих странах мира данный код является промышленным стандартом. Предыстория его появления на рынке такова.
До середины 1970-х гг. технология штрихового кодирования распространялась только на 10 цифровых знаков — от 0 до 9. Низкая разрешительная способность данной технологии потребовала усовершенствования, и в 1974 г. в США был разработан штриховой код, предназначенный для машиночитаемого представления буквенно-цифровых данных. Он получил название «код 39» (Code39). Начиная с 1981 г., код 39 был рекомендован к использованию в сфере распределения товаров применительно к машиночитаемой маркировке транспортных контейнеров. В настоящее время он широко распространен как в розничной, так и оптовой торговле.
По замыслу авторов, код 39 предназначался для машиночитаемого представления 39 графических знаков, отсюда и его название. Штриховой символ каждого знака алфавита кода состоит из 5 темных штрихов и 4 светлых полос (пробелов). Из этих 9 элементов 3 — широкие, а остальные — узкие, что объясняет другое название кода — «З из 9». 2 из 5 темных штрихов и 1 пробел широкие, а остальные штрихи и пробелы узкие. На основе такого соотношения можно составить 40 комбинаций для штрихового, представления 10 цифровых знаков от 0 до 9, 26 букв латинского алфавита, тире, точки, интервалов,— разрядов и звездочек, являющихся признаком начала и конца кодового слова. Четыре дополнительные знака (S, /, +, %) изображаются пятью узкими штрихами, тремя широкими пробелами и одним узким пробелом. Отношение ширины широкого элемента кода (штриха или пробела) к ширине узкого может быть разным, но обычно составляет 3:1.
Код 39 является дискретным, т. е. промежутки между штриховыми символами не несут в себе информации, а являются лишь разделителями. Штриховые символы всех знаков алфавита кода 39 самоконтролирующиеся, что предполагает автоматическое обнаружение дефектов при считывании кода сканером.
Код «2 из 5 с чередованием»разработан американской фирмой «Intermec». Он является уплотненным вариантом одного из наиболее простых штриховых кодов, носящего название «2 из 5». Последний был предназначен для автоматизации сортировки грузопотоков в складском хозяйстве, но вследствие недостаточной информационной емкости широкого распространения не получил. Иногда этот код еще называютInterleawedTwoofFive(ITF).
Название кода «2 из 5 с чередованием» полностью соответствует его структуре, включающей 5 элементов (штрихов и пробелов), два из которых широкие. Информационные знаки, находящиеся на нечетных позициях кода, изображаются штрихами и расположены слева направо, а знаки, занимающие четные позиции, представлены пробелами. Вследствие этого элементы штриховых символов, относящихся к двум смежным информационным знакам кодового слова, чередуются. В отличие от кода «2 из 5», имеющего в качестве значащих элементов лишь штрихи, дополняемые разноширокими пробелами только как разделителями, без какой-либо информационной нагрузки, код «2 из 5 с чередованием» использует штрихи и пробелы как носители информации, что делает его более плотным и информационно насыщенным, а также позволяет кодировать большой объем информации на малых площадях упаковки товара, поскольку, применяя Линии для кодирования одной цифры, он кодирует следующую цифру в промежутках, что сокращает площадь кода наполовину. Его преимущество и в том, что он имеет прямоугольный контур, технологичен в исполнении (легко наносится на гофрированную упаковку). Как правило, данный код используется при кодировании партий товаров.
Довольно часто применяется и код 128, позволяющий кодировать номер партии товара, дату его изготовления, срок реализации, гарантийные условия, и пр.
В медицинской промышленности широко распространен кодКодбар (Codabar), имеющий высокую надежность и сочетающий в себе цифровой код и алфавитную идентификацию. Его используют, как правило, при кодировании операций по переливанию крови.
Кроме перечисленных, в практике используются коды 93,460,469, 978, ISSN(для газет),ISBN(для книг) и др.
Существует понятие «высота» штрихового кода. Спецификация отдельных символов определяет требуемую или оптимальную высоту кода в отношении соответствующего считывания с хорошим результатом. Код 39 обычно является длинным, а высота его небольшая. Код EAN/U.P.C. является относительно коротким, но высоким, ибо считывается в любом направлении, что является положительным с точки зрения неопытного персонала, использующего фиксированные сканеры для контроля предметов различных размеров. Поперечные (стеллажные) коды состоят из строк, штрихов и пробелов, располагаемых сверху других строк. Матричные коды включают в себя несколько строк, формирующих изображения из черного и белого.
Штриховые коды могут располагаться горизонтально (лестнично) или вертикально (частокольная изгородь). Методы печатания кодов и методы их сканирования помогают определить, какой из них использовать.
Лестничная форма считывается лучше при округлой поверхности, такой, как банка. Сканирующий луч при этом окажется всегда в одной и той же плоскости.
На конвейере нет необходимости использовать растровые сканеры, ибо движение банки дает благоприятную возможность считывания фиксированным лучом. Лестничная форма кода обеспечивает хорошее качество в случае использования некоторых методов печати. Например, если печатание точки не функционирует, принтер будет оставлять линию по всей длине штриха. Плохо пропечатанная точка в случае кода «частокольной изгороди», может оставить весь штриховой код неотпечатанным.
Код типа частокольной изгороди оказывается наилучшим в случае, когда совокупность кодов располагается один над другим. Этот код лучше проглядывается на коробках, ибо оказывается расположенным параллельно краю коробки.
В некоторых штриховых кодах каждый набор штрихов и кодов располагается по отдельности, а между этими наборами размещаются так называемые «межзнаковые интервалы». Эти штриховые коды называют дискретными кодами. Например, код 39 был создан так, чтобы его можно было печатать отдельными (индивидуальными) штампами, такими, как пишущая машинка. В 1970 г. он был основным методом односторонней печати. Код 39 был особенно успешным в случае, когда информация, закладываемая в штриховой код, накладываемый на каждый предмет, была различной, например, при кодировании автомобильных частей для прослеживания их прохождения.
Непрерывные коды не имеют межзнаковых промежутков, и все штрихи и пробелы участвуют в формировании данных. Код U.P.C. (универсальный код продукции) был разработан для того, чтобы печатание осуществлялось печатающими прессами при помощи квалифицированных специалистов и обычных специалистов по обработке пленок без изменения информации от одного кода к другому. Код 128 является непрерывным кодом. Современные термические или точечно-матричные принтеры могут на выбранном месте печатать любую конфигурацию, дискретную или непрерывную.
Большинство штриховых кодов являются линейчатыми, хотя новейшие конфигурации представляют собой двухразмерные коды. Прочие коды — это просто вертикальные линии, как, например, почтовые коды США. Существует много специальных конфигураций, позволяющих добиться специфических приложений, например, иллюминаторные коды с оптическим увеличением.
Линейчатые коды являются наиболее распространенными кодами вследствие простоты их печати и считывания. Хотя большое количество других методов автоматической идентификации весьма полезны, линейчатые штриховые в среднем очень распространены. Они дают возможность хорошо сочетать выгоду и некоторые недостатки. Они легко формируются для выполнения специфических работ. Большое количество методов печати может обеспечить печатание кодов при удовлетворительном уровне качества осуществления сканирования. В большинстве случаев нет необходимости в большом количестве данных, ибо они могут нести информацию в пределах ограниченного пространства. Линейчатые штриховые коды могут считываться почти всеми методами сканирования, как контактными, так и на расстоянии (в зависимости от сканирующего устройства и размера штрихов).
Двухразмерные штриховые коды обладают высокими потенциальными возможностями. Важным здесь является размер символов, необходимое количество информации и методы печатания. С точки зрения использования сканирующих устройств двухразмерных кодов, необходимо учитывать пригодность сканера и правильность считывания. На решение существенное влияние могут оказать условия сканирования. Двухразмерные штриховые коды особенно полезны в условиях, где пространство представляет собой проблему, где база данных недоступна или где требуется весьма высокая скорость сортировки. Двухразмерные штриховые коды могут использоваться для малых деталей, таких, как драгоценности или микрочипсы электронных устройств, или для случаев большого объема данных. Когда база данных оказывается недоступной, двухразмерный код весьма полезен и иногда называется портативным файлом данных. Некоторые двухразмерные коды могут нести обширное количество информации, такое, как история болезни пациента, которая при необходимости может считываться. В случае ошибочного определения, ошибочного контроля, реконструкции данных избыточности характеристик двухмерный код усиливает защиту заложенной в него информации. Фирма «Юнайтед Парцел Сервис» разработала «МаксиКод», предназначенный для высокоскоростной сортировки пакетов различных размеров и формы. Он оказался способным превосходно управлять функциями сортировки и стал доминирующим методом автоматической идентификации прохождения упаковок.
Некоторые штриховые коды являются полностью цифровыми (только цифровыми), в то время, как другие — буквоцифровые. Обычно цифровые коды занимают мало пространства. Если требуется полный набор данных стандарта ASCII ( совокупность знаков и кодов, состоящая из 128 знаков, включая как знаки управления, так и знаки печати ), то код становится очень сложным и запутанным.
Большинство штриховых кодов имеют «скрытую зону» определения. Это области, расположенные спереди и сзади штрихового кода, не имеющие запечаток. Они необходимы для того, чтобы сканер имел беспомеховую зону самоустановки. Скрытая зона подготавливает сканер для захвата штрихового сигнала.
«Контрольные знаки» или «контрольные цифры» усиливают защищенность данных. Они представляют собой знаки, которые показывают, как правильно должен считываться данный символ. Наиболее известной является последняя цифра в звене EAN (европейского эквивалента универсального кода продукции). Согласно математической формуле происходит сложение знаков символа с последующим делением суммы с целью получения результирующего числа. Это число добавляется к звену, и если звено считывается, расчет повторяется снова. Если же результат оказывается отличным от указанного в звене, то это означает ошибку, т.е. что штриховой код был считан неверно и данные отвергаются.
Защищающие коды, такие, как код 39, являются кодами, которые либо успешно считываются, либо не считываются вовсе. Поэтому типичной является малая вероятность ошибочного считывания или вероятность допущения существенных ошибок. При использовании защищающих кодов нет необходимости в контрольных цифрах.
Несчитывание происходит в том случае, если сканирующая система не способна произвести декодирование того, что она воспринимает ввиду отсутствия этой информации в запоминающем устройстве.
Ошибочное считывание происходит в том случае, когда одна буква или число интерпретируется другой буквой или числом. Другим понятием, требующим обсуждения, является понятие «скорость исправления ошибки». Это свойственно ситуации, когда считывается один знак, а должен был считываться другой. Изучение появления такого рода ошибок показало соотношение 1 к 3 000 000 случаев. Эти ошибки обычно свойственны человеческому зрению при написании и считывании. Цифра 4 подобна цифре 9, цифра 5 — букве S, а цифра 1 (единица) подобна букве S (малой L) или S. Некоторые из этих проблем случаются при написании текста, а некоторые — при его считывании. Эти проблемы не свойственны штриховым кодам.
«Интерпретация считываемости человеком» или «информативность» есть информация, закодированная в штриховом коде, но представленная в приблизительной форме, воспринимаемой человеком. Эта информация может располагаться выше кода, вдоль него или под ним. При этом специальные знаки могут быть, а могут и не присутствовать. Многие стандарты кодов и стандарты их применения определяют правило считываемое информации человеком.
Некоторые коды могут преобразовываться в случае, если возникают проблемы, связанные с ущербом или другими случаями неудовлетворительного считывания. Это особенно свойственно двухразмерным кодам. Для обнаружения таких проблем существуют методы обнаружения ошибок. Коррекция ошибок с применением кода коррекции ошибок позволяет локализовать проблему и обеспечить гарантию, что все данные будут правильно считаны.
«Суффиксы» есть дополнительные штриховые коды, располагаемые после основного кода. Например, на журналы наносится код EAN (европейский эквивалент унифицированного кода продукции), но может быть и другой код, состоящий из цифр от 2 до 5. Суффиксы часто присутствуют в таких кодах, как код 128 или код «Интерливд 2-5». Эти дополнительные коды могут обеспечить весьма ценную информацию, необходимую для решения многих проблем. Например, такому производству, как автомобильное или электронное, свойственно изменение вида используемых деталей, но при этом неизменным остается число элементов. Суффиксный код может позволить произвести изменение технического наименования деталей, для которых существующий код остается работоспособным для поставляющей системы. Суффиксный код обеспечивает смену месяца выпуска журнала, где смена номера самого предмета от месяца к месяцу не производится. Суффиксный код задается производителем, например на купонах, обозначая либо дату, либо информацию о цене выкупа.
«Автоматическое распознавание» означает, что сканирующее устройство способно считывать и декодировать более одного символа. До момента появления в 1990-х годах компьютеров с большим объемом памяти не было достаточных мощностей для того, чтобы в системах хранить программы с большим количеством символов. Кроме того, обработка их была слишком медленной. В настоящее время большинство компьютеров способно считывать и интерпретировать различного рода коды. «Автоматическое распознавание» и трафаретные таблицы являются выгодными там, где организация функционирует в области мультипроизводства при использовании собственных символов. Это существенно с точки зрения усиления жизнеспособности используемых многознаковых кодов. Гибридно-эталонные системы, использующие трафаретные таблицы в пределах компьютера, могут позволить использование номерных и кодовых систем различных организаций.
Большинство новых систем способны опознавать определенное множество кодов. В США кода EAN (европейского эквивалента универсального кода продукции) практически не существует, но большинство новых систем способны их сканировать (считывать).
В процессе создания новых систем в первую очередь следует учитывать перечень индустриальных стандартов и методы символогии. Когда определенная организация является промышленной и совершенствует методы идентификации или она работает с несколькими производствами, то бок о бок должны рассматриваться различные методы кодирования.
Европейский эквивалент универсального кода продукции (U.P.C.)
EAN-13 и ЕАN-8
Стандартные характеристики символов европейского эквивалента кода продукции. Существует несколько вариантов символов европейского эквивалента универсального кода продукции (включая универсальный код продукции), 13-цифровой символ показан на рис. 2.5, а восьмицифровой — на рис. 2.6. Все эти варианты имеют следующие общие характеристики.
В общем случае все символы имеют прямоугольную форму, образованную последовательностью светлых и черных параллельных штрихов, перпендикулярных воображаемой линии основания или опорной линии со светлыми краями со всех сторон.
Светлые и черные штрихи образуют (составляют) модули одинаковой формы светлого и черного цвета. В дальнейшем будет описано, что в EAN-символах (символах европейского эквивалента кода продукции) черный модуль представляет единицу (1), а светлый модуль — ноль (0).
Штрих черного цвета или светлый пробел могут образовывать от одного до четырех модулей.

Рис. 2.5. Форма 13-цифроврго символа европейского эквивалента универсального
кода продукции EAN.

Рис. 2.6. Форма восьмицифрового символа европейского эквивалента
универсального кода продукции EAN
Знаки штрихового кода, представленные в виде числовых цифр, образуются семью модулями светлого или черного цвета. В знаках модули сгруппированы в штрихи, где каждая цифра представляется при помощи двух черных и двух белых штрихов.
Кроме того, цифровые знаки имеют вспомогательные знаки, образующие новые модули, используемые в качестве штрихов защиты или центральных штрихов, служащих для обозначения начала, окончания и разделения (отделения и выбора).
Символ формируется так, чтобы обеспечить всенаправленное считывание фиксированным сканером. Кроме того, при помощи портативного (ручного) считывающего устройства он может считываться с двух сторон.
Размер символа меняется в пределах величин, определяющих возможности качественной их печати различными методами.
Пространственные размеры определяются основным размером символа, известным под названием «номинального размера». Предельные величины находятся в диапазоне от 0,8 до 2,0 кратности номинального размера.
Идентификация при помощи европейского эквивалента унифицированного кода продукции EAN является «исключительно номерной» и имеет общую структуру, показанную на рис. 2.7.
В показанной структуре (рис. 2.7, 2.8 и 2.9) PI, P2, РЗ представляют префикс (три цифры), который определяет организацию нумерации. Каждая организация включает в себя один или несколько префиксов PI, P2, РЗ. EAN является ответственным за присвоение этих префиксов.
Приставка Идентификация Контрольная
(префикс) элемента цифра
|
P1 P2 РЗ |
X X .................. |
С |
Рис. 2.7. Структура EAN-13
Идентификация элемента (XX...) есть структура, которая всецело вводится Организацией нумерации, определяемой используемым префиксом. Однако присвоенная структура должна подчиняться определенным базовым правилам.
Имеются две отдельные серии стандартных чисел EAN:
Наиболее общая серия использует вариант, который определяет данные 8 знаков данных в поле «идентификации элемента». В этом случае полный номер элемента включает в себя 13 числовых позиций. Впредь она будет называться как Эта серия называется EAN-13.
В короткоразмерном варианте в поле «идентификации элемента» используется четыре знака данных. В этом случае полный номер элемента включает в себя 8 числовых позиций. Впредь она будет называться как Эта серия называется EAN-8. В файлах «сканирование — оборудование» числа серии EAN-8 должны всегда правильно подтверждаться при помощи введения пяти ведущих нулей так, чтобы число, определяющее деталь, всегда состояло из 13 цифр.
|
Позиция |
13 |
12 |
11 |
10 |
9 |
8 |
7 |
6 |
5 |
4 |
3 |
2 |
1 |
|
EAN-13 Полноразмерный вариант |
Р1 |
Р2 |
Р3 |
Х |
Х |
Х |
Х |
Х |
Х |
Х |
Х |
Х |
С |
|
EAN-8 Короткоразмерный вариант |
|
|
|
|
|
Р1 |
Р2 |
Р3 |
Х |
Х |
Х |
Х |
С |
Рис. 2.7. Структуры штриховых кодов EAN-13 и EAN-8
На рис. 2.8-2.12 представлены кодирование цифровых величин в символе кода EAN, логические структуры и размеры элементов кодов EAN-13 и EAN-8.
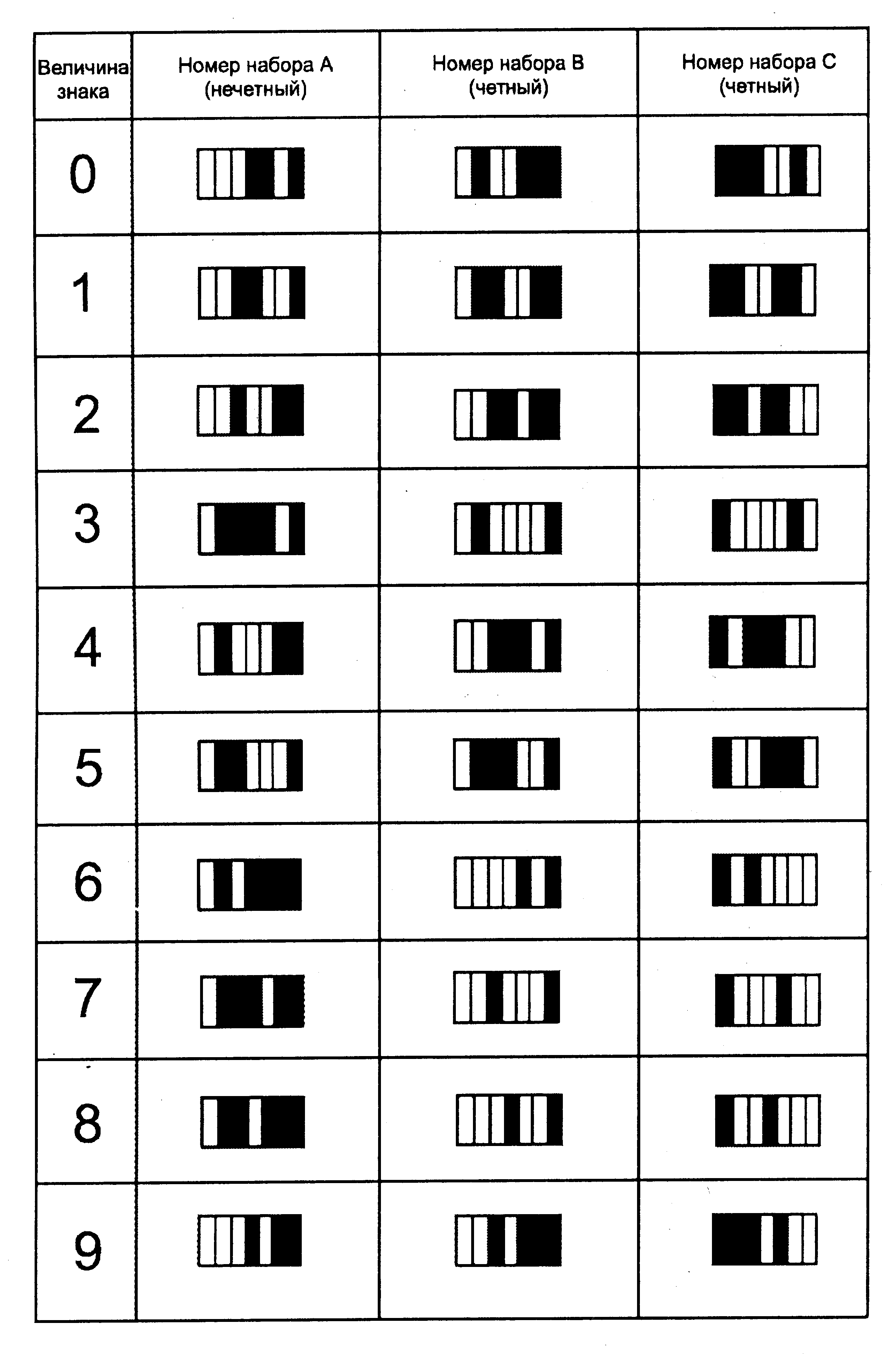
Рис. 2.8. Кодирование цифровых величин в символе кода EAN
(серийный эквивалент универсального кода продукции)
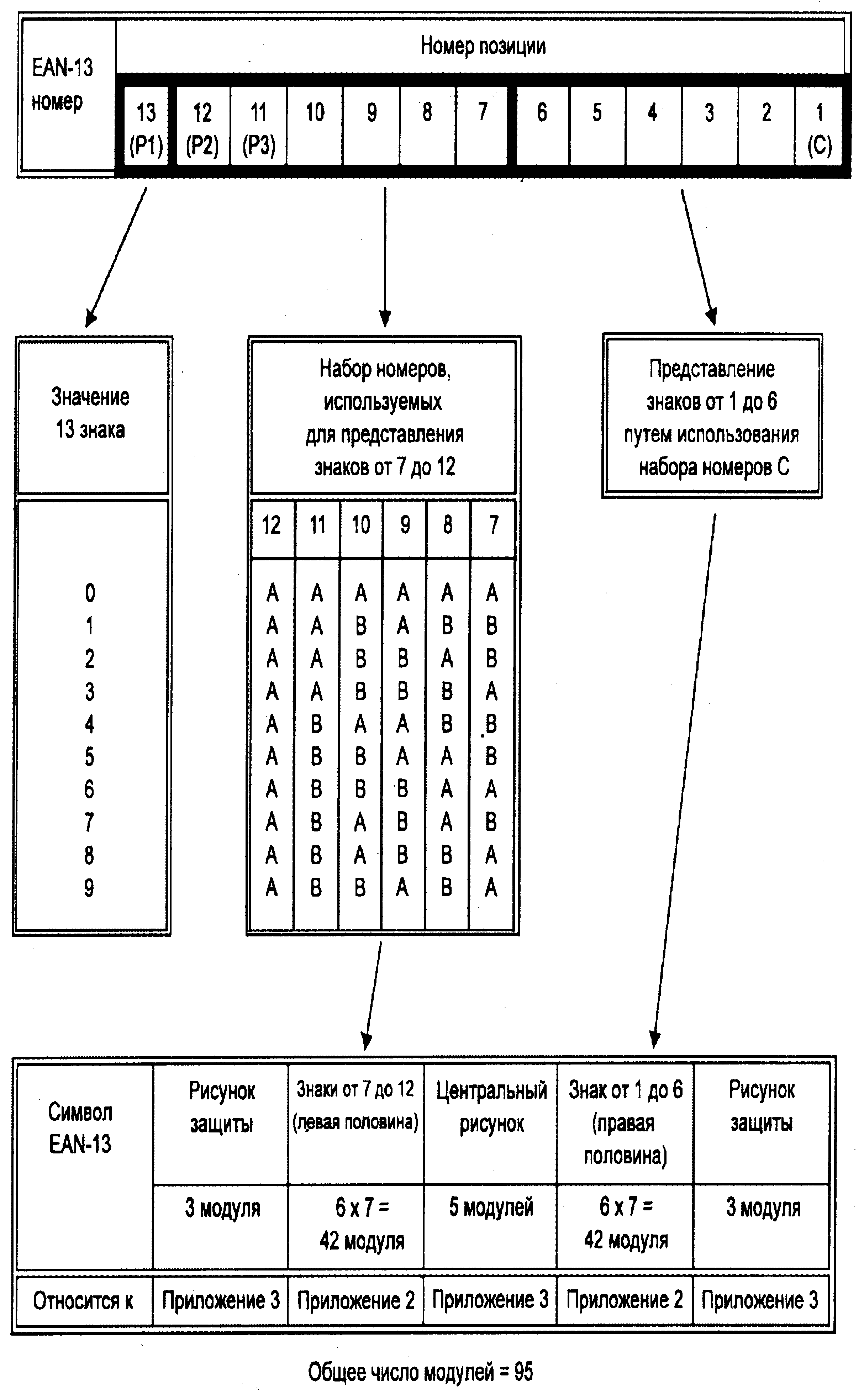
Рис. 2.9. Логическая структура EAN-13
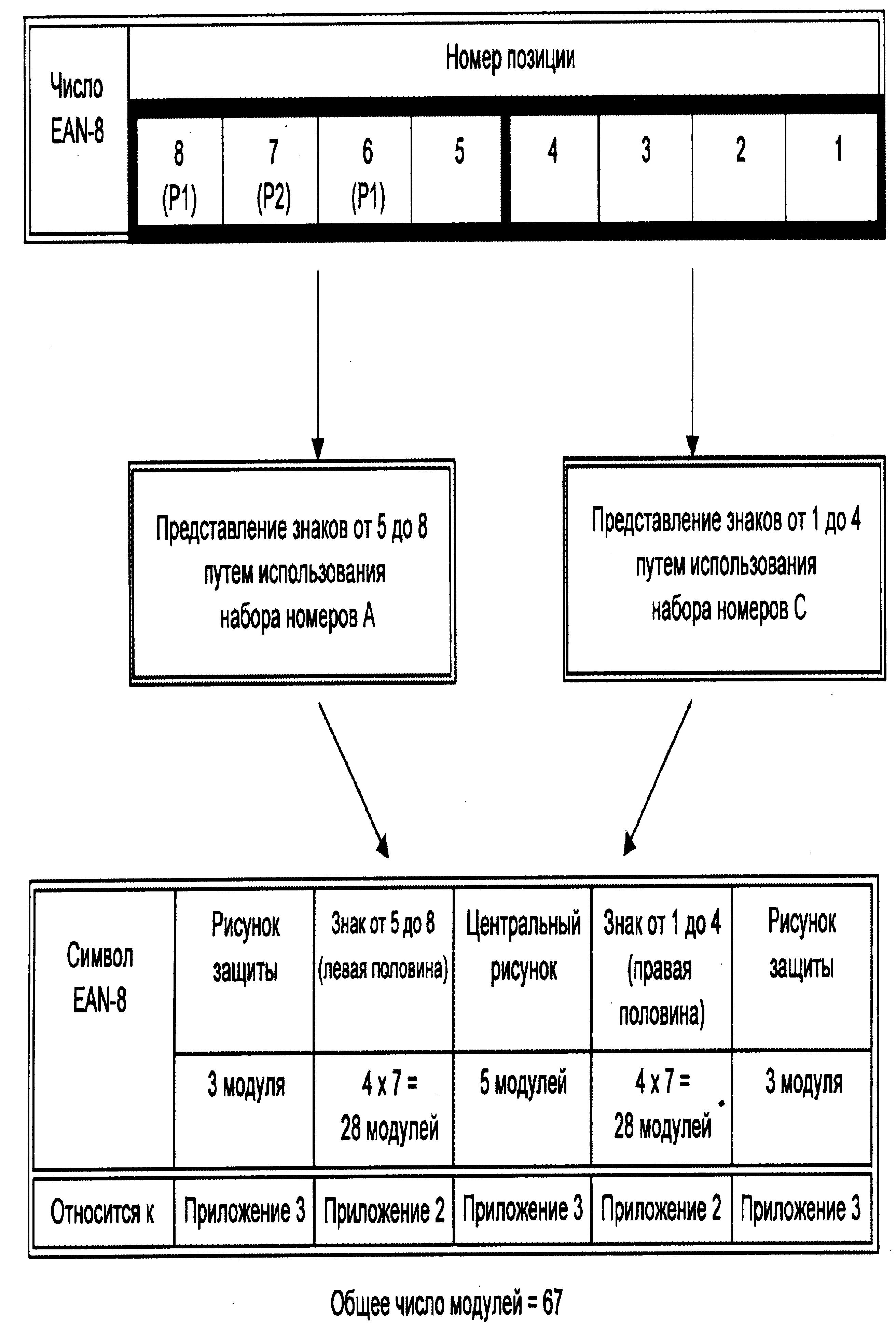
Рис. 2.10. Логическая структура EAN-8
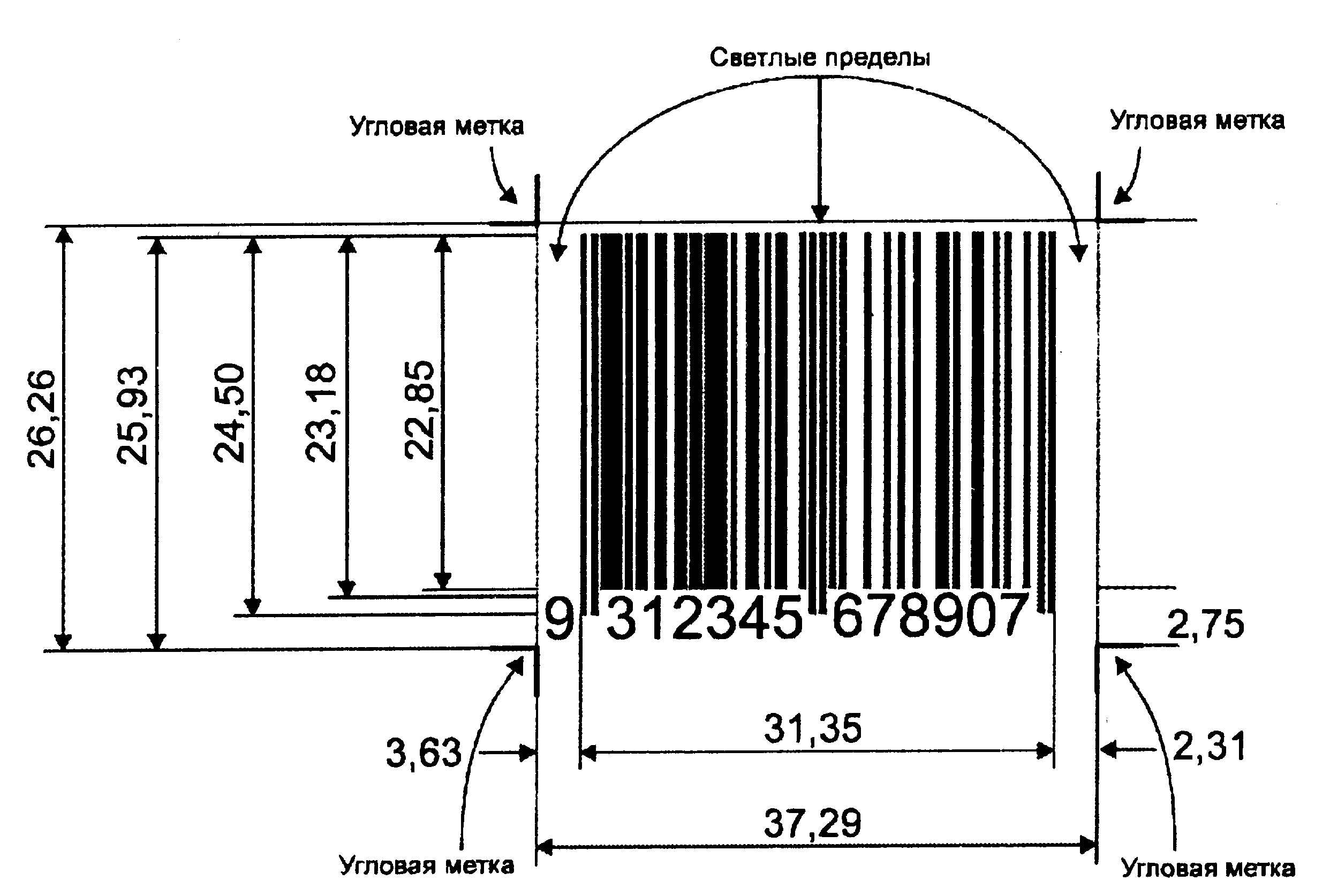
Рис. 2.11. Измерения 13-цифрового символа EAN при минимальном размере
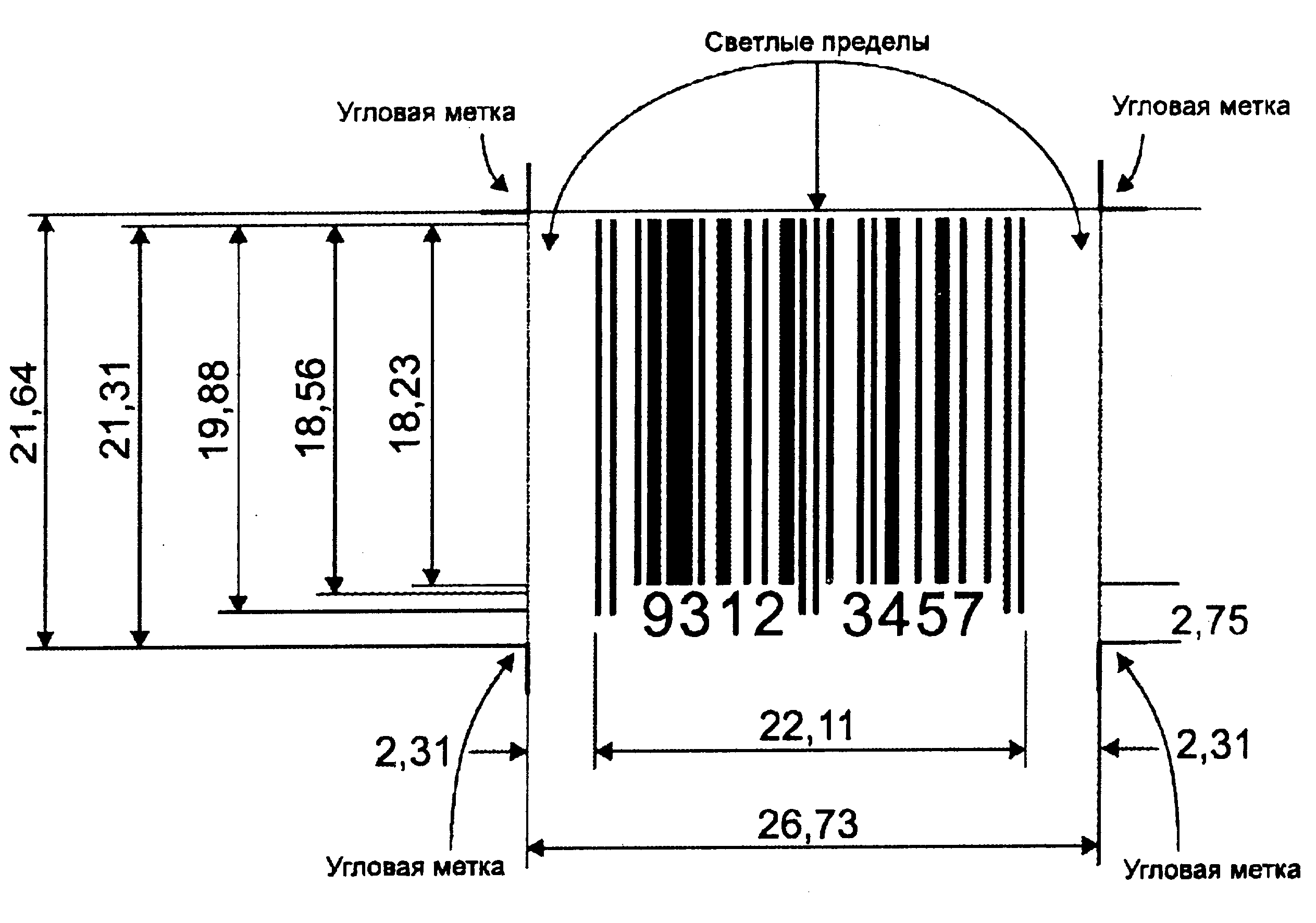
Рис. 2.12. Измерения 8-цифрового символа EAN при номинальном размере
Международная стандартная серийная нумерация серийных изданий
Система международной стандартной серийной нумерации (ISBN), основанная на ISO 329/1975, по всему миру используется для нумерации серийных публикаций. При этом должны существовать договоренности и координация между «Интернейшенел Артикел Намберинг Асотиейшел БАМ», «Интернейшенел Центр Регистратион оф Сериал Ривликатион».
С этой целью цифры префикса 977 агентством ISS были определены только лишь для кодирования журнальных и периодических изданий всего мира. Таким образом, номер EAN состоит из:
1) трех цифр префикса (977);
2) семи цифр номера, определенного для публикаций (без их контрольной цифры);
3) двух запасных цифр;
4) одной контрольной цифры, подсчитываемой в соответствии со стандартным алгоритмом.
Код 128. Код 128 является пприхкодовым символом, способным кодировать весь набор знаков ASCII128, набор 128 знаков, распространенных ASCII и четыре функциональных знака, не относящихся к данным. Этот код позволяет представлять цифровые данные в компактном виде двойной плотности, по две цифры данных на каждый знак символа, как это показано на рис. 4.20.

Рис. 2.13. Код 128
Каждый символ кода 128 использует две независимые самоконтролирующиеся характеристики, знак самоконтроля через посредство контроля четности и знак контроля модуля 103. Это минимизирует вероятность ошибочного считывания. Двухмодульное построение штрихового пространства облегчает считывание символов высокой плотности при помощи обширного множества считывающих устройств.
Структура символа. Каждый символ кода 128 состоит из ведущей скрытой зоны, стартового знака символа, знака, представляющего данные, контрольного знака, стопового знака символа и оконечной скрытой зоны. Характеристики кода 128 приведена ниже, а структура символа показана на рис 4.22.
Характеристики кода 128:
1 — набор кодируемых знаков данных — все 128 знаков ASCII — все 128 расширительных знаков, ASCII — 4 функциональных знака, не относящиеся к данным;
2 — тип кода — непрерывный;
3 — элементов на знак символа (2 цифры) — 6 (3 штриха и 3 пробела);
4 — модулей на знак символа — 11 (стоповый знак имеет 13 модулей);
5 — плотность знаков данных — 9,1 знака на дюйм, 18,2 знака на дюйм (числа) (основание X = 0,010 дюйма (0,25 мм);
6 — перекрытие исчезновения данных — эквивалентно 3,18 алфавитно-цифровым знакам;
7 — знаковый самоконтроль — имеется;
8 — длина символа — меняется;
9 — контрольная цифра символа — меняется;
10 — контрольный знак символа — один, задаваемый;
11 — двунаправленное декодирование — есть;
12 — варианты — FNC 3-считыватель.

Рис. 2.14. Структура символа кода 128
Структура знака символа. Каждый знак кода 128 состоит из одиннадцати модулей ширины X ширина наиболее узкого элемента. Каждый знак символа включает в себя три штриха, перемещающихся тремя пробелами, начинающихся со иггриха. Каждый штрих или пробел (элемент) может состоять из четырех модулей, как это показано на рис. 4.23.
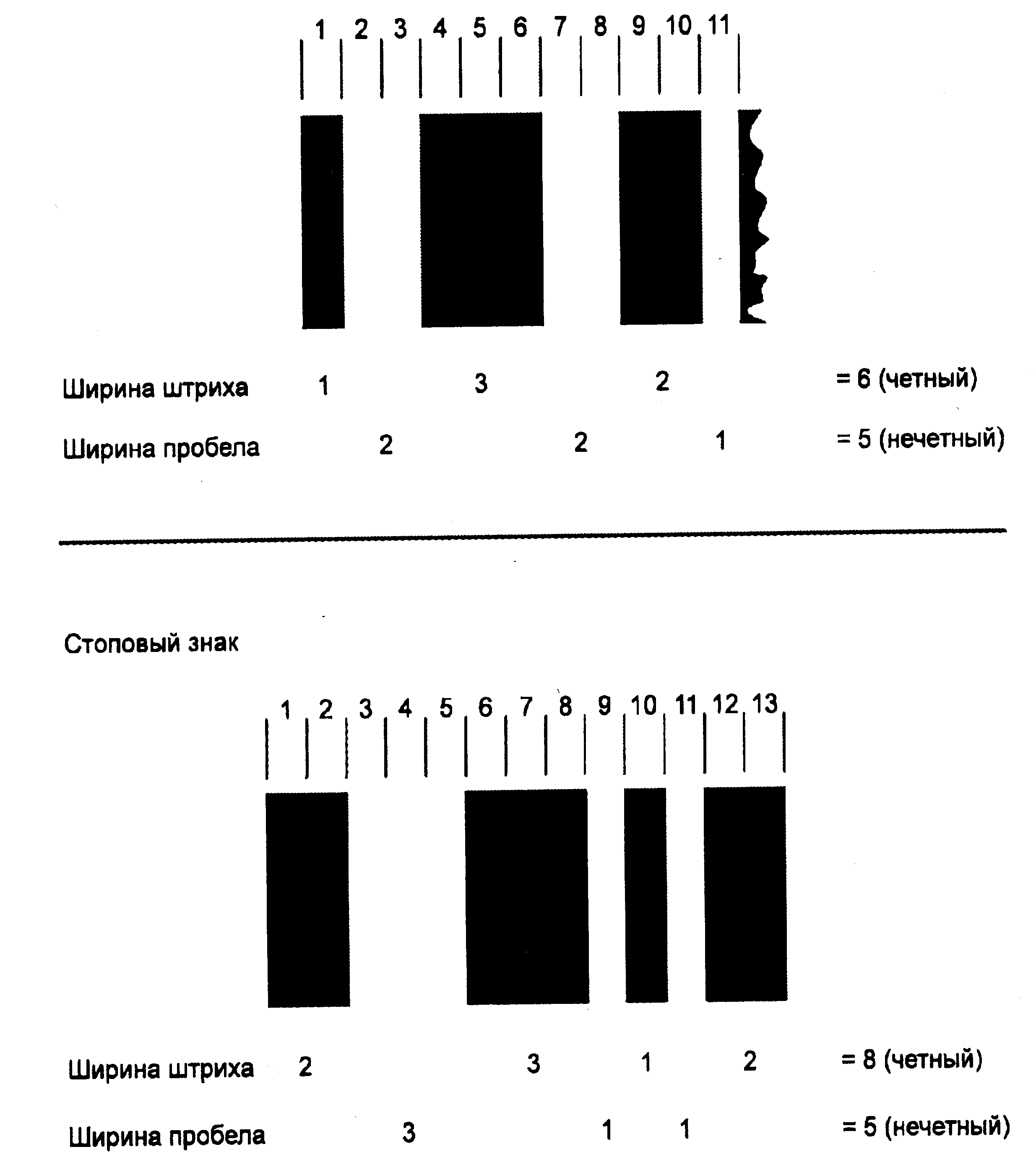
Рис. 2.15. Структура знака кода 128
Сумма штриховых модулей в каждом знаке символа всегда должна быть четной (четная пара), а пробельные модули были, поэтому, нечетными. Данный характер четности пары позволяет осуществлять знаковый самоконтроль. Каждый знак символа определяет номерную величину. Эта величина используется при подсчете контрольного знака.
Знаки символа и кодирование данных. Код 128 имеет три набора уникальных знаков данных, показанных на рис. 2.16. Это наборы кодов А, В и С. Эти знаки символов эквивалентны знакам данных, перечисленных ниже.
Кодовый набор А. Кодовый набор включает в себя все алфавитно-цифровые знаки клавиатуры вместе с контрольными знаками ASCII (знаки ASCII состоят из цифр от 1 до 95) и семь специальных знаков.
Кодовый набор В. Кодовый набор В включает в себя все алфавитно-цифровые знаки клавиатуры вместе со знаками нижнего алфавитного регистра (знаки ASCII состоят из цифр от 32 до 127) и семь специальных знаков.
Кодовый набор С. Кодовый набор С включает в себя 100 парных цифр от 00 до 99 включительно, а также три специальных знака. Это позволяет кодировать числовые данные по две цифры на символ при двухплотностной эффективности стандартных данных.
Функциональные знаки. Код 128 имеет четыре различных функциональных знака: FNC 1 до FNC 4, которые дают возможность варьировать функциями, расширяя способности кода 128.
Скрытая зона. Скрытая зона в конце каждого символа должна быть шириной минимум 10 Z, где Z есть средняя измеряемая ширина узкого элемента.
Стартовые и стоповые знаки. Один из трех стартовых знаков используется вначале символа, для того чтобы определить выбор кодового набора А, В или С. В конце символа всегда используется стоповый знак. В пределах собственно самого символа стартовый и стоповый знаки не должны использоваться, Эти знаки также не должны передаваться куда-либо считывающим устройством или использоваться для показа человеку.
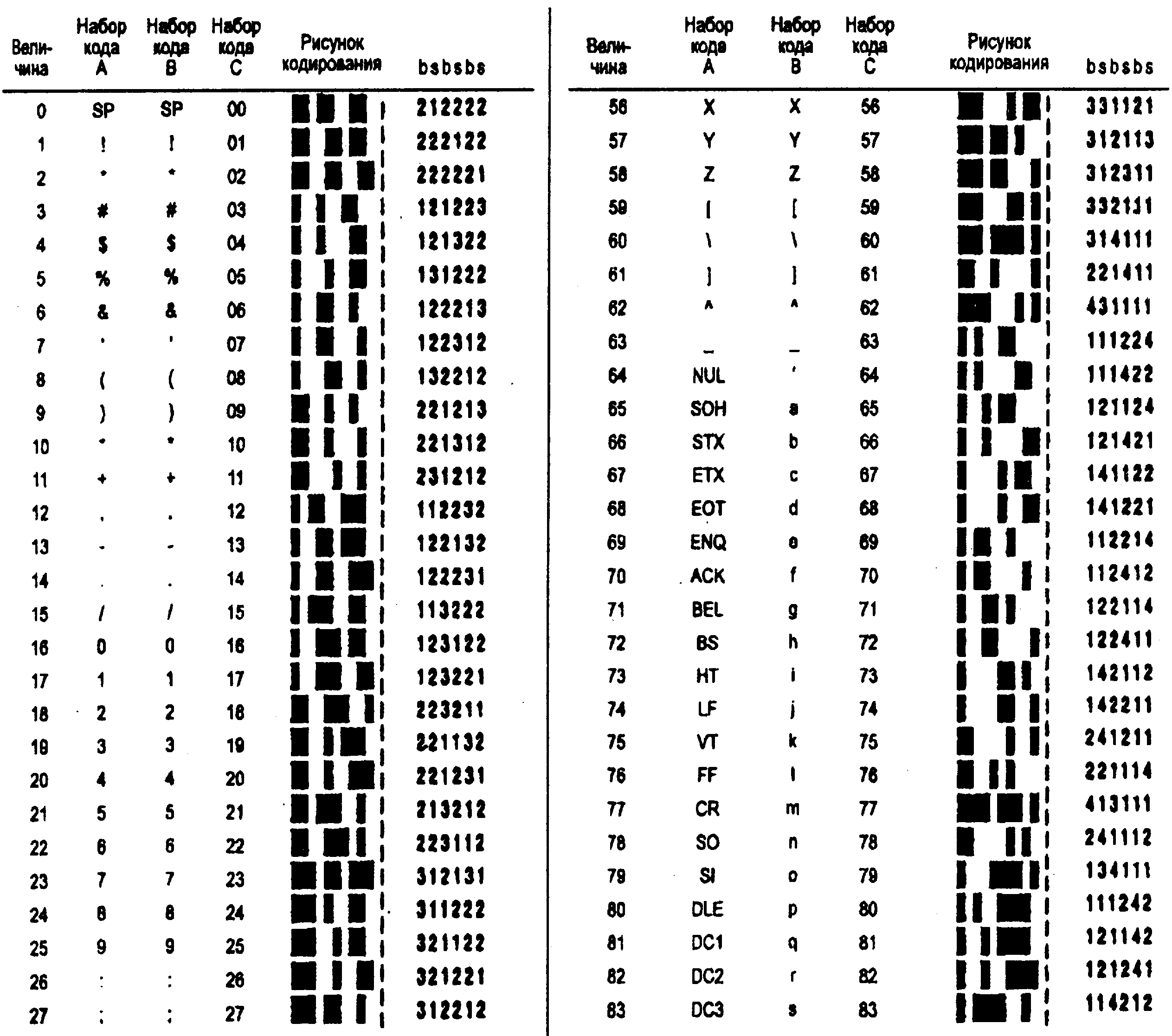

Рис. 2.16. Набор знаков символа кода 128
Главные двухразмерные символы (матрично-стеллажно-рядовые коды). Максикод. Этот высоковместимый (высокоемкостный) двухразмерный машино-считываемый код создан для грузоотправительных и грузоприемных систем. Код сводится к одному стандартному размеру — дюйм на дюйм (25,4-25,4) при допустимых отклонениях, соответствующих термической и лазерной печати. Он может вместить в себя 100 знаков информации, столько же, сколько содержит 19-дюймовый стандарт Кода 128. Пример приведен на рис. 2.17.

Рис. 2.17. Используемые символы Максикода и диаграмма, показывающая детали увеличения и ориентационный рисунок: В — темное пространство фиксируемого места, дающего ориентацию; W — пробелы, дающие ориентацию; М — характеристические биты (двоичные элементы) кодируемой информации; черные элементы означают кодируемую информацию
В показанное может быть включена любая информация, касающаяся рассматриваемой продукции, а именно ее вес, порядковый номер, качество, тип материала, классификация, степень опасности. Если этого недостаточно, то может быть использовано вплоть до восьми Максикодов вместе. При этом для формирования этикетки на детали портативно может быть помещено необходимое количество информации. Это в любом случае грузоотправления дает возможность иметь всю информацию о деталях, которая в любой момент доступна без наличия базы данных. Аналогичным образом сказанное позволяет использовать код при работах на движущемся конвейере. Этот код может обеспечить:
1) определенный пользователем файл данных;
2) разумную защиту информации;
3) всенаправленное, высокоскоростное считывание;
4) возможность декодирования при любой ориентации;
5) увеличение продуктивности;
6) высокую эффективность;
7) получение своевременной информации.
Спецификации:
1) размерность — дюйм на дюйм;
2) конструкция шестигранника с 386 ячейками используется для хранения данных;
3) считываемость при любой ориентации;
4) фокусировка с увеличением по центру используется для того, что. бы этикетку можно было размещать в любом месте;
5) код включает в себя примерно 100 знаков данных;
6) данные в двоично-кодовом исчислении хранятся в псевдослучайном порядке;
код может быть отпечатан на принтере с разрешающей способностью, равной 200 точек на дюйм (1 дюйм = 25,4 мм) или с большей разрешающей способностью;
8) коррекция ошибок Соломоновым решением;
9) обладает высокой способностью приоритетного (относительной срочности) сообщения, которое может быть принято в том случае, если до 25% этикетки окажется поврежденной.
Рассмотренный код был принят в США как один из основных (базовых) символов, рекомендуемых производителям в качестве основы построения автоматической системы идентификации и стандарта машинной считываемости данных.
Матрица данных. Матрица данных активно внедряется в различные производственные процессы. Она оказывается особенно полезной в производстве малоразмерных элементов, таких, как электронные чипсы, используемые при передаче информации в системах обработки данных. Она успешно используется фармацевтическими предприятиями, а также в случаях высокоскоростной сортировки, идентификации паспортов, виз и лицензий.
Описание символа. Матрица данных является двухразмерным матричным символом, как это показано на рис. 2.18. Матрица данных имеет следующие основные характеристики:
1) Набор знаков кодирования:
A) 128 знаков, соответствующих ISO 646;
B) набор определяемых знаков потребителем составляет 256 знаков;
2) Представление данных в символе матрицы данных:
А) зависит от схемы кодирования, при этом либо данные преобразуются в двоичные (бинарные) коды, либо данные преобразуются в 8-битовые байты, возможна коррекция ошибок, Потребитель способен сделать выбор между конволюционным кодом (кодом со сверткой расположений) или Соломоновым решением. Это позволяет выбрать тип и уровень (степень) коррекции ошибки в соответствии с приложением.
3) Размер символа:
А) количество строк и колонок для представления данных от 7 до 132;
Б) высота и ширина модулей от 9Х до 144Х.
4) Число знаков данных на символ (для максимального размера символа):
семибитовые ASCII данные, вплоть до 2334 знаков;
Б) восьмибитовые данные: 1555 знаков;
B) количество данных: 4030 цифр.
5) Выборочная коррекция ошибки: пятиуровневое исключение ошибки до нуля;
6) Тип кода: матрица;
7) Независимость ориентации: существует

Рис. 2.18. Примеры символов матрицы данных
Обобщение дополнительных характеристик. Матрице данных свойственны следующие дополнительные выборочные характеристики:
1) Компактность данных: схемы матриц данных способны вмещать в себя большое количество информации с плотностью более 8 бит на знак.
2) Кодовые страницы (выборки ЕСС Левел 200): определяют возможность пользоваться символикой из арабского, кириллицы, греческого, иврита и другими интерпретациями или механизмами, свойственными особенностям промышленного декодирования. Потенциальная вместимость большинства отдельных кодовых страниц — 256.
3) Формы (свойственные ЕСС Левел 200): формы определяют механизм определения различных структур и характеристик символов.
4) Коррекция ошибок (собственных): символы матрицы данных (ЕСС от 050 до 140) сочетают в себе использование алгоритмов свертки кодов и коррекции ошибок.
5) Прямоугольность символов (варианты ЕСС Левел 200): характерны четыре формата символов прямоугольной формы, позволяющие обеспечить выбор потребителями особенностей техники печати и сканирования.
6) Структурное присоединение (варианты ЕСС Левел 200): это позволяет файлы данных представлять в логической и непрерывной форме вплоть до 16 символов. Они могут сканироваться в любой последовательности, что позволяет корректно производить реконструирование оригинальных первоначальных данных. Выбор производится пользователем в соответствии с возникающими потребностями этих характеристик.
Структура символа. Каждый символ матрицы данных состоит из области данных, которая включает в себя набор квадратов, располагаемых в пространстве квадратной формы. Область данных обрамлена поисковым рисунком, который, в свою очередь, со всех четырех сторон окружен пограничной скрытой зоной.
Поисковый рисунок. Поисковый рисунок является периметром области размещения данных. Его ширина составляет размер одной ячейки. Смежные стороны должны быть контрастно черными линиями. Это необходимо в первую очередь для того, чтобы определить физический размер, ориентацию и искажение символа. Две противоположные стороны должны быть альтернативно черной и белой. Это делается главным образом для того, чтобы определить структуру ячейки символа, но, кроме того, помогает выделить размеры.
В табл. 4 представлена сравнительная различных видов кодирования: RFID, штрихового линейного и матричного кодирования.
Таблица 2.4
Сравнительная характеристика RFID, штрихового линейного и матричного кодирования
|
Характеристики технологии |
RFID |
Штрих-код |
Data Matrix |
|
Необходимость в прямой видимости метки |
Чтение даже скрытых меток |
Чтение без прямой видимости невозможно |
Чтение без прямой видимости невозможно |
|
Объём памяти |
От 10 до 10 000 байт |
До 100 байт |
До 2000 байт |
|
Возможность перезаписи данных и многократного использования метки |
Есть |
Нет |
Нет |
|
Дальность регистрации |
До 100 м |
До 4 м |
Н/д |
|
Одновременная идентификация нескольких объектов |
До 200 меток в секунду |
Невозможна |
Зависит от считывателя |
|
Устойчивость к воздействиям окружающей среды: механическому, температурному химическому, влаге |
Повышенная прочность и сопротивляемость |
Крайне легко повреждается |
Зависит от материала, на который наносится |
|
Срок жизни метки |
Более 10 лет |
Короткий |
До 20 лет и более (зависит от материала, на который наносится) |
|
Безопасность и защита от подделки |
Подделка практически невозможна |
Подделать легко |
Подделать возможно |
|
Работа при повреждении метки |
Невозможна |
Затруднена |
Возможна |
|
Идентификация движущихся объектов |
Да |
Затруднена |
Возможна |
|
Подверженность помехам в виде электромагнитных полей |
Есть |
Нет |
Нет |
|
Идентификация металлических объектов |
Возможна |
Возможна |
Возможна |
|
Использование как стационарных, так и ручных терминалов для идентификации |
Да |
Да |
Да |
|
Возможность введения в тело человека или животного |
Да |
Затруднена |
Невозможна |
|
Габаритные характеристики |
Средние и малые |
Малые |
Малые и сверхмалые |
|
Стоимость |
Средняя |
Низкая |
Низкая |