

190
Паттерн Interpreter
Название
Интерпретатор
Также известен как
-
Классификация
По цели: поведенческий По применимости: к классам
Частота использования
Низкая |
- 1 2 3 4 5 |
Назначение
Паттерн Interpreter – позволяет сформировать объектно-ориентированное представление грамматики для заданного языка, а также описывает правила создания механизма интерпретации (толкования) предложений этого языка.
Введение
Паттерн Interpreter описывает способы и правила построения объектно-ориентированного представления грамматики для заданного формального языка. Формальные языки классифицируются в соответствии с типами грамматик, которыми они задаются. Грамматики классифицируются по иерархии Хомского, согласно которой они разделяются на четыре категории. Иерархия Хомского классифицирует грамматические формальные системы по их порождающей способности – то есть по тому множеству языков, которые они позволяют представить.
Список типов грамматик по классификации Хомского:
Рекурсивно перечислимые грамматики.
Эти грамматики имеют неограниченные правила и по своей выразительной мощи эквивалентны машинам Тьюринга. Практического применения в силу своей сложности такие грамматики не имеют.
Контекстно-зависимые грамматики.
Эти грамматики могут использоваться при анализе текстов на естественных языках, но для построения компиляторов практически не используются в силу своей сложности.
Контекстно-свободные грамматики.
Эти грамматики широко применяются для описания синтаксиса компьютерных языков.
Регулярные грамматики.
Это самые простые из формальных грамматик. Регулярные грамматики применяются для описания простейших конструкций: идентификаторов, строк, констант, а также языков ассемблера (представления мнемоник), языков регулярных выражений, командных процессоров и др.
Первые две грамматики в иерархии Хомского имеют большую выразительную мощь, но алгоритмы для работы с такими грамматиками являются сложными и малоэффективными. Долгое время усилия лингвистов, в том числе и Аврама Ноама Хомского были в основном направлены на исследование
191
контекстно-свободных и контекстно-зависимых языков. Но в итоге стали чаще применяться регулярные грамматики в силу простоты обращения с ними. Все регулярные грамматики могут быть разделены на два эквивалентных класса: леволинейные и праволинейные регулярные грамматики.
Регулярные грамматики определяют в точности все регулярные языки, и поэтому эквивалентны конечным автоматам и регулярным выражениям (Регулярный язык - это формальный язык, который может быть выражен средствами регулярных выражений, а Регулярные выражения – это формальный язык поиска и осуществления манипуляций с подстроками в тексте).
Важной особенностью регулярных грамматик является то, что регулярные грамматики эквивалентны по своей вычислительной мощи конечным автоматам (КА).
Определим язык формально. Есть и другие определения, но мы остановимся на этом.
ОПРЕДЕЛЕНИЕ: Конечное множество элементов будем называть словарем, элементы словаря – символами, а последовательности символов словаря – цепочками или предложениями. Множество предложений назовем языком. Язык над словарем V будем обозначать LV, или просто L, если V очевидно.
Пусть V – словарь. Обозначим V* - множество всех возможных цепочек, составленных из символов словаря V. Если V= {a, b, c}, то V*= {ε, a, b, c, aa, ab, ac, … aaa, aab, … abacbcaacbcacb..., …}, где ε – пустая цепочка, не содержащая символов. Очевидно, что хотя V конечно, V* - бесконечное счетное множество. Всего языков над словарем V (как подмножеств, счетного множества V*), бесконечное число: это множество мощности континуум.
Один из распространенных методов задания языка использует «определитель множества» вида: {ω|утверждение о цепочке ω}, где ω – это обычно выражение с параметрами, а утверждение о цепочке ω –
определяет некоторые условия, налагаемые на параметры. Во многих случаях использовать этот метод трудно или невозможно. Например, как задать L - множество правильных скобочных выражений, как определить множество всех идентификаторов языка программирования, как задать сам язык программирования? Для упрощения решения большинства таких задач существует два типа грамматик: порождающие и распознающие. Эти два типа грамматик аналогичны двум формам речи человека: распознающая грамматика аналогична импрессивной речи, а порождающая грамматика аналогична экспрессивной речи. Импрессивная (сенсорная) речь — это восприятие и понимание речи (В коре головного мозга имеется зона сенсорной речи, которая называется зоной Вернике.). Экспрессивная (моторная) речь
— произнесение звуков речи самим человеком (В области второй и третьей лобной извилины головного мозга имеется зона моторной речи, которая называется зоной Брока. У правшей зона Брока находится в левом полушарии мозга, а у левшей в большинстве случаев — в правом.).
Под порождающей грамматикой языка L понимается конечный набор правил, позволяющий строить все «правильные» предложения языка L и ни одного «неправильного».
Распознающая грамматика задает критерий принадлежности произвольной цепочки данному языку. Это алгоритм, принимающий в качестве входа символ за символом произвольную цепочку над словарем V и дающий на выходе один из двух возможных ответов: «данная цепочка принадлежит языку L» либо «данная цепочка НЕ принадлежит языку L». В действительности этот алгоритм должен разделить все возможные входные цепочки на два класса: один – принадлежащие языку L, а другой – не принадлежащие языку L.
Роль распознающей грамматики может выполнить конечный автомат (КА) без выхода. Если связать с некоторыми состояниями автомата метку «ДА», а с остальными метку «НЕТ», тогда все множество входных цепочек автомата разобьется на два класса: одни - приводящие автомат в одно из состояний, помеченных «ДА», а все другие в одно из состояний, помеченных «НЕТ».
Определим автомат-распознаватель формально.
ОПРЕДЕЛЕНИЕ: Конечным автоматом-распознавателем называется пятерка объектов:
192
• = < , , , , >, где:
•S - конечное непустое множество (состояний);
•X - конечное непустое множество входных сигналов (входной алфавит)
•- начальное состояние
•: × → - функция переходов
•- множество заключительных (финальных) состояний
ОПРЕДЕЛЕНИЕ: Конечный автомат-распознаватель = < , |
, |
, |
, > допускает входную цепочку |
|
|
|
|
|
|
, если переводит его из начального в одно из заключительных состояний, то есть если |
( , ) . |
|||
Множество всех цепочек, допускаемых автоматом А, образуют язык, допускаемый А.
Роль порождающей грамматики может выполнить конечный автомат-преобразователь. Конечный автомат-преобразователь (транслятор) - это просто распознающий автомат, дополненный семантическими действиями, выполняемыми при анализе очередного входного символа.
Реализация распознающей и порождающей грамматик не ограничивается использованием конечных автоматов. Паттерн Interpreter дает возможность реализации распознающих и порождающих грамматик без использования «конечно-автоматного» подхода. Объектная структура грамматики, составленная и реализованная по правилам паттерна Interpreter «теоретически» эквивалентна по своей вычислительной мощи конечным автоматам (КА). В большинстве случаев предпочтительно использовать КА, но для очень (!) простых грамматик есть смысл использовать подход описываемый паттерном Interpreter. Для сложных грамматик иерархия классов становится слишком громоздкой и практически неуправляемой.
Важно помнить, что не все языки представимы конечными автоматами, а если язык не автоматный, то такой язык практически невозможно реализовать при помощи паттерна Interpreter. Поэтому прежде чем преступить к реализации грамматики определенного языка, требуется проверить, является ли этот язык автоматным. «Лемма о накачке», является важным «теоретическим инструментом» позволяющим во многих случаях проверить является ли язык автоматным (Лемма – это готовое доказательство теоремы, использующееся для доказательства других теорем). Термин «накачка» в названии леммы оттеняет возможность многократного повторения некоторой подстроки в любой строке подходящей длины любого бесконечного автоматного языка.
Более формально лемма о накачке формулируется так:
Лемма о накачке (1). Пусть L – автоматный язык над алфавитом V. Тогда:
( )( : | | ≥ )( , , ):
[ = &|| ≤ &|| ≥ 1&( )( )]
Другая форма леммы о накачке, которую иногда удобно применять чтобы показать «неавтоматность» некоторого языка, записывается так:
Лемма о накачке (2). Пусть L – автоматный язык над алфавитом V. Если:
( )( : | | ≥ )( , , ):
[ = &|| ≤ &|| ≥ 1&( )( )]
то L - не автоматный.
193
Предлагается рассмотреть пример доказательства теоремы, устанавливающей неавтоматность конкретного языка, с помощью леммы о накачке:
ТЕОРЕМА: Язык = { | { , } } – неавтоматный (здесь - это цепочка обратная к ).
ДОКАЗАТЕЛЬСТВО: Предположим противное, а именно, что язык L - автоматный и он распознается конечным автоматом A с n состояниями. Рассмотрим цепочку этого языка, такую что | | ≥ . Эта цепочка по предположению допускается автоматом A, и поскольку путь, помеченный этой цепочкой на графе переходов A, содержит по крайней мере один цикл, то цепочку можно представить, как конкатенацию трех подцепочек, = , причем цепочка не пуста. Язык L будет автоматным, если A вместе с = допускает также и , и и т.д. В какую из подцепочек , или может входить символ с? Если с входит в подцепочки иди , то «накачка» нарушает симметрию допускаемой цепочки, если с входит в, то «накачка» приведет к удвоению, утроению и т.п. символа с, что также недопустимо. Таким образом, в допускаемой автоматом A достаточно длинной цепочке не существует непустой подцепочки, повторение которой произвольное число раз сохраняет структуру , то есть также дает цепочку, допускаемую этим автоматом. Следовательно, язык L - неавтоматный.
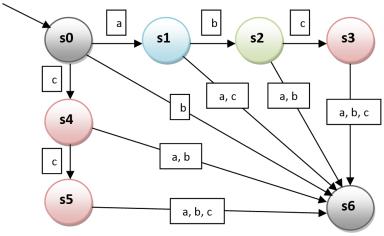
Зададим для примера простой автоматный язык = { , , }; = { , }; и построим для него конечный автомат. Построим граф переходов автомата, распознающего L. Входные цепочки и (и только они) переводят автомат из начального, в одно из заключительных состояний S5 или S3.
Предлагается самостоятельно реализовать грамматику для заданного языка = { , , }; = { , }; с использованием подхода предоставляемого паттерном Interpreter.