

C++ программы НОВИКОВ / Лекция 7
.pdf11
создается иллюзия существования множества копий этой процедуры, которые создаются активизацией процедуры. Эти активизации создаются способом, подобным выдвижению отдельных элементов телескопической антенны, и исчезают по мере выполнения алгоритма. В каждый момент времени работает только одна из существующих активизаций. Остальные находятся в состоянии неопределенности, ожидая завершения работы других активизаций процедуры.
Рекурсивные системы представляют собой циклические процессы и зависят от правильного управления ими. Их работа зависит от проверки условия завершения (для двоичного поиска – пустой список или найденное значение) и правильного их построения, которое обеспечивает выполнение этого условия завершения. [1, 10]
2.1.4. Эффективность и правильность алгоритмов.
Хотя современные машины способны выполнять миллионы команд в секунду, эффективность остается главной проблемой при построении алгоритмов. Один из разделов вычислительной техники называется анализ алгоритмов и занимается изучением ресурсов, таких как время, объем памяти, требующихся для выполнения алгоритмов. Такие исследования применяются при оценке относительных преимуществ использования того или иного алгоритма.
Рассмотрим задачу, стоящую перед секретарем университета, которому нужно просмотреть и обновить данные некоторого студента. Пусть файл студентов содержит информацию более чем о 30 000 человек. Предположим, что эти данные хранятся в компьютере секретаря в виде списка, упорядоченного по идентификационному номеру (номеру зачетки) студента. Для того чтобы найти информацию о каком-либо студенте, секретарь должен отыскать в этом списке заданный идентификационный номер.
При заданном идентификационном номере алгоритм последовательного поиска сравнивает этот номер с элементами списка с самого начала списка. Не зная ничего о происхождении искомого значения, мы не может сделать вывод, как далеко от
12
начала списка оно находится. Однако можно сказать, что средняя глубина поиска составляет половину списка, потому что некоторые номера находятся ближе к началу, другие ближе к концу списка. Мы заключаем, что за некоторый промежуток времени алгоритм последовательного поиска изучит примерно 15 000 записей. Если для извлечения идентификационного номера каждой записи требуется 10мс, то поиск одного номера займет в среднем 150с или 2,5мин. Для секретаря это означает достаточно долгое ожидание, пока информация появится на экране.
Алгоритм двоичного поиска начинает работу со сравнения заданного значения с элементом, находящимся в середине списка (список должен быть упорядочен). Если они не совпадают, то при дальнейшем поиске можно ограничиться только половиной списка. Следовательно, после рассмотрения среднего элемента списка, состоящего из 30 000 элементов, алгоритм должен обработать список из 15 000 записей. После второго запроса остается список из 7500 записей, а после третьего извлечения номера рассматриваемый список сократится до 3750 элементов. Таким образом, искомая запись будет найдена (или не найдена) после извлечения не более 15 элементов списка. Следовательно, если извлечение номера выполняется за 10мс, то процесс поиска отдельной записи займет только 0,15с. То есть доступ к отдельной записи секретарю покажется мгновенным. Из этого можно сделать вывод, что выбор между алгоритмами последовательного и двоичного поиска является существенным для решения данной прикладной задачи. [1]
В примере сравнивали средний случай работы алгоритма последовательного поиска с наихудшим случаем работы алгоритма двоичного поиска. Несмотря на то, что мы анализировали список определенной длины, не составит труда применить наши рассуждения к списку произвольной длины. В частности, если применить алгоритм последовательного поиска к списку, состоящему из N элементов, то в процессе работы он рассмотрит в среднем N/2 элементов. В то время как алгоритм двоичного поиска в наихудшем случае извлечет максимально lоg2N элементов.
13
Рассмотрим также алгоритм сортировки методом вставки. Этот алгоритм выбирает из списка элемент, который называется ведущим элементом, сравнивает его с предшествующими элементами, пока не поместит его в правильную позицию. Поскольку главным действием в алгоритме является сравнения двух элементов, мы будем подсчитывать число сравнений, которые выполняются в процессе сортировки списка, имеющего длину N.
Сначала алгоритм выбирает в качестве ведущего второй элемент списка, затем извлекает последовательно все элементы до тех пор, пока не достигнет конца списка. В наилучшем случае каждый ведущий элемент уже находится на своем месте и, следовательно, его нужно сравнить только с одним элементом. Таким образом, в наилучшем случае для сортировки списка методом вставки потребуется (N-1) сравнений. В наихудшем случае каждый ведущий элемент сравнивается со всеми элементами, расположенными до него. Так происходит в том случае, когда элементы сортируемого списка расположены в обратном порядке. В этом случае общее число сравнений в процессе сортировки списка из N элементов, равно 1 + 2 + 3 + ... + (N-1)=1/2(N2-N). В среднем в случае сортировки методом вставки каждый ведущий элемент сравнивается с половиной элементов, предшествующих ему. В результате требуется в два раза меньше сравнений, чем в наихудшем случае, чтобы упорядочить список.
Полученные нами результаты имеют большое значение, поскольку по количеству сравнений, выполненных в процессе работы алгоритма, можно определить приблизительное количество времени, необходимое для его выполнения. Зависимость времени выполнения сортировки методом вставки от длины списка показана на рисунке 1.4. Этот график построен с помощью данных, полученных при анализе наихудшего случая, когда мы пришли к выводу, что для сортировки списка, имеющего длину N, потребуется, по большей мере, 1/2(N2-N) сравнений. На графике через равные промежутки отмечены несколько значений длины списка и значения интервала времени, соответствующего каждой длине. Из графика видно, что при изменении длины списка на одинаковое количество элементов промежуток време-

14
ни, необходимый для его сортировки, возрастает на значительно больший интервал. Следовательно, при увеличении длины списка эффективность алгоритма снижается.
Рис. 2.4. График зависимости времени сортировки методом вставки от длины списка.
Приращение
времени
уменьшается
Рис. 2.5. График зависимости времени поиска с помощью алгоритма двоичного поиска от длины списка

15
Рассматривая алгоритм двоичного поиска, мы при-
шли к выводу, что для нахождения какого-либо элемента в списке, длина которого равна N, нужно рассмотреть максимально lоg2N элементов. График зависимости времени поиска от длины списка изображен на рис. 1.5. В данном случае время выполнения алгоритма увеличивается на меньшие интервалы при возрастании длины списка на равное количество элементов. То есть при увеличении длины списка эффективность алгоритма двоичного поиска повышается.
Главное различие между этими двумя графиками (рис. 1.4 и 1.5) состоит в форме кривой, которая в свою очередь определяется типом функции, изображенной на графике, а не ее параметрами. Форма графика, получаемого путем соотнесения времени, необходимого для выполнения алгоритмом задачи, и количества входных данных, отражает эффективность алгоритма. Поэтому принято классифицировать алгоритмы согласно форме графика, который обычно строится на анализе наихудшего случая. Система представления, которая используется для определения вышерассмотренных классов алгоритмов, иногда называется « - представлением» (тета-представлением). По этому представлению можно разделить алгоритмы на два класса: (N2) и (lgN). Зная класс, к которому относится алгоритм, который предполагается использовать при решении задачи, можно предсказать его эффективность и сделать выбор в пользу того или иного алгоритма. [1]
2.2.Языки программирования.
2.2.1.История языков программирования.
Языки программирования разработаны так, чтобы они поз-
воляли записать алгоритм в форме, понятной человеку и легко преобразуемой в команды машинного языка. Языки программирования позволяют избежать лабиринта регистров, адресов памяти и машинных циклов в процессе разработки программы сосредоточиться на решаемой задаче.
Воснове ранних ПК лежал принцип хранимой программы, и
впроцессе программирования программист записывал все алгоритмы на машинном языке (языки программирования первого
16
поколения). При программировании на машинном языке все элементы, входящие в команду, записываются в виде двоичных кодов. Так записываются и выполняемые операции, и адреса ячеек, в которых содержатся команды, и исходные данные, и результаты.
Первым шагом в устранении этих сложностей был отказ от использования чисел для представления кода операций и операнда, используемых в машинном языке. С этой целью кодам операций стали назначать мнемонические имена. Например, вместо кода загрузки программист мог написать LD (от LOAD). Для операндов были созданы правила, по которым можно были присваивать описательные имена (идентификаторы) ячейкам памяти и использовать их вместо адресов ячеек памяти в командах. Но затем программу все равно переводили на машинный язык вручную.
Потом были созданы программы, транслирующие программу, записанную в мнемонической форме, в машинный код. Та-
кие программы называются ассемблерами (язык программи-
рования второго поколения). Название ассемблер (сборщик) происходит от основной функции этих программ – собирать машинные команды, переводя мнемонические имена операций и идентификаторы операндов в коды команд и коды операндов. Мнемонические системы для представления программ были признаны языками программирования и названы языками ассемблера. Когда появились первые языки ассемблера, они казались гигантским шагом по направлению к более совершенным методам программирования.
Хотя языки второго поколения и имели большое преимущество перед машинными языками, им все же не удалось стать окончательной средой программирования. Примитивы, которые использовались в языках ассемблера, в сущности, ничем не отличались от примитивов, применяемых в соответствующих машинных языках. Различие заключалось только в синтаксических структурах, использовавшихся для их представления. Поэтому программа, написанная на языке ассемблера, является машиннозависимой, то есть команды программы выполняются в соответствии с характеристиками отдельной машины. Программу,
17
написания на языке ассемблера, нельзя перенести на машину с другой архитектурой. Для этого ее нужно переписать, чтобы она соответствовала конфигурации регистров и набору команд новой машины.
Другой недостаток языков ассемблера заключается в том, что хотя программисту и не приходится записывать команды в виде последовательности битов, он все-таки вынужден мыслить в небольших шагах машинного языка. Данная ситуация аналогична использованию при проектировании дома таких понятий, как доска, гвоздь, кирпич и т. д., вместо понятий комната, окно и т.п.
Говоря проще, элементарные примитивы, из которых, в конце концов, строится продукт, не обязательно должны использоваться при разработке этого продукта. В процессе проектирования лучше применять примитивы более высокого уровня, каждый из которых представляет собой понятие, связанное с одной из главных характеристик продукта. По окончании проектирования эти примитивы можно перевести в понятия более низкого уровня, имеющие отношение к деталям выполнения.
Следуя этим принципам, специалисты в области вычислительной техники начали разрабатывать языки программирования, более подходящие для создания программного обеспечения, чем языки ассемблера. В результате возникли языки программирования высокого уровня, которые отличались от своих предшественников тем, что в них использовались машиннонезависимые примитивы высокого уровня. Известным примерами таких языков являются FORTRAN, разработанный для создания научных и инженерных прикладных программ, и COBOL, созданный военно-морским ведомством США для прикладных программ в бизнесе. Главным при разработке языков третьего поколения было создание набора примитивов высокого уровня, с помощью которых можно создавать программное обеспечение. Каждый из примитивов был построен так, что его можно выполнить как последовательность примитивов низкого уровня, входящих в машинный язык.
После определения (разработки) набора примитивов была написана программа, преобразующая программу, записанную с
18
помощью этих примитивов, в программу на машинном языке. Такая программа называется транслятором. Трансляторы были очень похожи на ассемблеры второго поколения, только им приходилось объединять несколько машинных команд в короткие последовательности, чтобы имитировать действия, выраженные одним примитивом высокого уровня. Такие транслирующие программы часто называют компиляторами.
Интерпретатор, в отличие от компилятора, выполняет программу по мере ее ввода и не записывает транслируемую программу для последующего выполнения. То есть интерпретатор выполняет команды, как только они получены, а не создает копию программы, записанную на машинном языке, чтобы выполнить ее позже.
Современные трансляторы способны работать в режиме и интерпретатора, и компилятора. При разработке и отладке программы транслятор работает обычно в режиме интерпретатора, а при получения готовой исполняемой программы - в режиме компилятора.
Процесс преобразования программы с языка высокого уровня в машинные команды называется трансляцией. Программа в первоначальной форме называется исходной программой, преобразованная программа называется объектной. Процесс трансляции включает в себя три стадии: лексический анализ (лексический анализатор), синтаксический анализ (синтаксический анализатор) и генерацию объектного кода (генератор объектного кода). В процессе лексического анализа распознаются цепочки символов, которые представляют собой отдельные элементы, и классифицируются согласно тому, являются ли они числовыми значениями, арифметическими операторами, словами и т.д. (например, число 347, слово for). По мере классификации элементов лексический анализатор порождает цепочки битов – лексемы, и передает их синтаксическому анализатору. Синтаксический анализатор рассматривает программу как совокупность лексем и его задача состоит в том, чтобы сгруппировать эти элементы в отдельные высказывания. В большинстве языков программирования для обозначения конца высказывания используются знаки пунктуации, а для обозначения отдельных
19
конструкций – ключевые (зарезервированные) слова. Последняя стадия трансляции программы – это генерация кода, т.е. создание команд машинного языка, выполняющих выражения, распознанные синтаксическим анализатором. Процессы лексического и синтаксического анализа и генерации кода в ЭВМ протекают одновременно.
Объектная программа, полученная после трансляции исходной программы, часто является только кусочком целой программы. Соединение объектных программ выполняется компоновщиком. Компоновщик связывает объектные программы, полученные в результате трансляции, процедуры операционной системы и другое обслуживающее программное обеспечение и создает исполняемую программу (загрузочный модуль, обычно с расширением .exe), которая сохраняется на запоминающем устройстве ЭВМ. Для выполнения оттранслированной программы загрузочный модуль помещается в память программой, которая называется загрузчиком и часто является частью планировщика операционной системы.
Таким образом, подготовка программы на языке высокого уровня к выполнению состоит из трех этапов: трансляции, компоновки и загрузки. После завершения трансляции и компоновки программу можно загрузить и выполнять, не возвращаясь к ее исходной версии. Если программу необходимо изменить, то все изменения производятся в исходной программе, которая затем снова транслируется и создается новый загрузочный модуль, содержащий внесенные изменения.
Существует тенденция группировать транслятор и другие программы, использующиеся в процессе разработки программного обеспечения, в пакеты, которые функционируют как одна система. Такую систему можно отнести к прикладному программному обеспечению. Используя такую систему, программист получает доступ к редактору для написания программ, транслятору для перевода программы на машинный язык и большому количеству инструментов отладки. Редактор обычно структурирует текст программы согласно правилам используемого языка, иногда распознает и дописывает зарезервированные слова. [1, 8]
20
2.2.2.Парадигмы программирования.
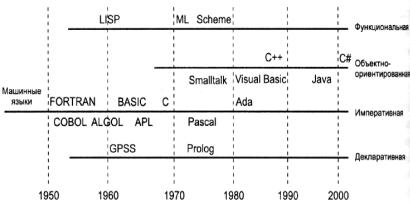
Воснове разделения языков программирования на поколения лежит линейная шкала. Позиция языка на этой шкале определяется тем, насколько пользователь свободен от ненужной информации и в какой степени данный язык позволяет программисту мыслить в понятиях, связанных с решаемой задачей. В действительности развитие языков программирования происходит не только в этом направлении, существуют и другие подхо-
ды к процессу программирования - парадигмы программи-
рования. Поэтому историческое развитие языков программирования лучше изображать с помощью диаграммы (рис. 2.6). На этой диаграмме показано, что разные направления развития языков являются результатом разных парадигм (подходов), развивающихся независимо друг от друга. В частности, на рисунке изображены четыре направления, представляющие функцио-
нальную, объектно-ориентированную, императивную и де-
кларативную парадигмы. Языки, относящиеся к каждой парадигме, расположены на временной шкале, показанной внизу (но из этого не следует, что один язык развивался из другого).[1]
Рис. 2.6. Эволюция парадигм программирования.
Следует заметить, что хотя парадигмы, изображенные на рисунке, и называются парадигмами программирования, их влияние выходит за рамки процесса программирования. Они представляют собой совершенно разные подходы к решению задач и,