

Стандартные ввод и вывод.
Под стандартным вводом и выводом представляют передачу данных. Ввод – вычисляет систему от внешнего объекта и наоборот. Но кроме фактического включена трансформация представления. Например, числа и данные в разрядном представлении преобразуют в десятичное. Добавляется форматирование. Реализованы в стандартном вводе, выводе.
Рекурсия в алгоритмах
Языки использующие стек записей для блоков запущенных на выполнение.
Пр. если обработчик А вызвал функцию Б а та процедуру С. Стек вызвал 3. Вверху стека запись для блока С, эта . Если в структуре блок С рекурсивный. В момент завершения работы С эта запись вытаскивается и вверху записывается для функции Б. Если блок С рекурсивный, тогда в стеке кроме записей для А и Б к+1 запись для С. Содержание самой записи - в ней хранится адрес возврата вызвавший блок и значение всех локальный переменных данного блока. Заполнения стека новыми записями при обращению к блоку С называется прямым кодом рекурсии, в конце которого завершается работа последней копии самого блока С. Далее обратный ход. В процессе которого заканчивается работа предыдущих копий С, при чем в порядке обратном вызову с возвратом результата от копии к копий С в конце обратного хода определяются результаты первого обращения к блоку С. Опасность переполнения стека проблема рекурсии.
Рекомендации к проблеме.
1) Не включайте в число локальных переменных вспомогательные данные. Можно писать глобально вне блока. Размер стека можно увеличить директивой {$M…} 2.147.483.647
 Рекурсивное
вычисление j
числа Фибаначи.
Рекурсивное
вычисление j
числа Фибаначи.
Function Fib(j:integer):integer; begin if j>2 then Result:=fib (j-1)+Fib(j-2) else Result:=1; end;
В примере в увеличение j работа замедляется. Т.к. работа рекурсии ветвящаяся. Кратность вычисление выполняют ряд Фибаначи. Для данного примера итерационный цикл был оптимален.
Алгоритмы поиска
Обычно тип описывает запись с некоторым полем, выполняющем роль ключа. Задача заключается в поиске элемента ключ которого равен заданному аргументу поиска х. Полученный в результате поиска индекс I удовлетворяет следующему условию.
S:array [0..N-1] of item; s[i].key=x
Далее будем считать, что тип item включает только ключ. Если нет никакой дополнительной информации о разыскивании данных, то осуществляем последовательный просмотр массива с увеличением шаг за шагом той его части, где элементы не обнаружены. (Линейный поиск). Условия окончания поиска:
Весь массив просмотрен, совпадений нет
I=0
ai=x

i>N
and (ai<>x)
Окончание
поиска




Ai=x





i=i+1 Поиск
найдет Не
найден

конец



*
Единственная возможность оптимизации - это упрощение двойного логического выражения. Это можно сделать выставив условие, если можно гарантировать, что совпадение будет. Тогда в конец массива можем записать дополнительный элемент равный х, который сыграет роль «барьера». Он будет «охранять» от перехода за пределы массива. Тогда уходит одна из проверок.
 a[N]:=x;
i=0
while a[i]<>x do i:=i+1
a[N]:=x;
i=0
while a[i]<>x do i:=i+1
Поиск деления пополам, бинарный поиск
Алгоритм основан на знание того, что массив упорядочен.
Ak:1<=k<=N: ak-1<=ak
Основная
идея. Выбрать случайно некоторые элементы
аm
и сравнить его с аргументом поиска х.
Если am
равно х поиск заканчивается. Если am<x
то делаем вывод, можем исключить из
поиска все элементы с индексами меньше
либо равными m.
am<x(k<=m)
am>x(k>=m)
1 2 3 4 5 6
1
5 21 34 145 147
I=left i=right m=(1+6)div2=3
Am<x(x<=m)=> left=m+1
Am>x(k=>m)=>right=m-1
Ввести 2 индексных переменных left и right, которые отмечают левые и правые концы секции массива, в которых поиск введен
Left=0 R=N-1
Found:=False
Left<=Right
and not found found Наиб


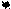
M=(left+right)div2 Am>x
Am<x


 +
+
Found=true

 +
+

 + -
+ -
Наим Left=m+1



Right=m-1

 -
-
конец



Можем отказаться от проверки на совпадение. Если откажемся, то выигрыш эффективности на каждом шаге превзойдет потери от сравнения несколькими дополнительными элементами, т.е. поиск продолжаем до тех пор, пока секции не накроют массив.

 L:=0;
R:=N
While L<R do begin
m:=(L+R)div 2
if a[m]<x
then
L=:=m+1 else R:=m;
end;
L:=0;
R:=N
While L<R do begin
m:=(L+R)div 2
if a[m]<x
then
L=:=m+1 else R:=m;
end;
В начале берем N для учета выхода за границы массива. Повторение заканчивается, когда l=R. В итоге, если R=m , то совпадений нет. Во всех остальных случаях по выхода из цикла нужна дополнительная проверка. Алгоритм как и в случае линейного поиска находит элемент с наименьшим индексом.