

Void main()
{ int A[] = {4, 7, 3, 4, 8, 2, 3, 6, 6, 4, 9, 2, 3};
int n = sizeof(A) / sizeof(int);
InsertSort(a, n);
for (int i = 0; i < n; i++)
cout<<A[i]<<' ';
}
Алгоритм эффективен на небольших наборах данных (на наборах данных до десятков элементов может оказаться лучшим) и на наборах данных, которые уже частично отсортированы.
Это устойчивый алгоритм сортировки (не меняет порядок элементов, которые уже отсортированы).
Ввиду своих особенностей хорош для списков.
Не требует дополнительной памяти.
Общее быстродействие - O(n2), но ввиду простоты метода является наиболее быстрым для малых (12-20 элементов) массивов.
Если использовать двоичный поиск для определения места элемента, то трудоемкость алгоритма составляет n * log(n). Однако эта трудоемкость не учитывает затрат на перемещение элементов при сдвиге.
Cортировка Шелла
В 1959 году американский ученый Дональд Шелл опубликовал алгоритм сортировки, который получил его имя.
Метод состоит в том, что массив разделяется на группы элементов, каждая из которых упорядочивается методом вставки.
В процессе сортировки размеры групп увеличиваются до тех пор, пока все элементы не войдут в упорядоченную группу.
Здесь группа это последовательность элементов, номера которых образуют арифметическую прогрессию с разностью h (шаг группы).
В начале процесса упорядочения выбирается первый шаг группы h1, который зависит от размера таблицы.
Шелл предложил брать h1 = n / 2, hi = hi -1 / 2.
В более поздних работах Хиббард показал, что для ускорения процесса целесообразно определить шаг h1 по формуле: h1 = 2k + 1, где 2k < n <= 2k + 1.
После выбора h1 методом вставки упорядочиваются группы, содержащие элементы с номерами позиций:
i, i + h1, i + 2 * h1, . . . , i + mi * h1
где i = 1, 2, . . . , h1;
mi - наибольшее целое, удовлетворяющее неравенству i + mi * hi <= n
Затем выбирается шаг h2 < h1 и упорядочиваются группы, содержащие элементы с номерами позиций
i, i + h2, . . . , i + mi * h2
Эта процедура со все уменьшающимися шагами продолжается до тех пор, пока очередной шаг hi не станет равным единице (h1 > h2 > ... > hi).
Этот последний этап представляет собой упорядочение массива методом вставки.
Так как исходная таблица упорядочивалась отдельными группами с последовательным объединением этих групп, то общее количество сравнений меньше, чем n /4, требуемое при методе вставки.
Число операций сравнения пропорционально n*(log2(n))2
Пример. Элементы одной группы выделены одинаковым цветом. Первое значение h равно 10/2=5.
Н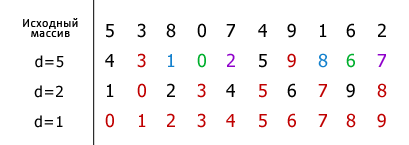 а
каждом шаге оно уменьшается вдвое.
Элементы, входящие в одну группу,
сравниваются и если значение элемента,
стоящего левее того, с которым он
сравнивается, оказывается больше (сорт.
по возрас.), тогда они меняются местами.
Так, элементы путем внутригрупповых
перестановок постепенно становятся на
свои позиции, и на посл. шаге (d
= 1)
сортировка сводится к проходу по одной
группе, включающей в себя N
элементов.
а
каждом шаге оно уменьшается вдвое.
Элементы, входящие в одну группу,
сравниваются и если значение элемента,
стоящего левее того, с которым он
сравнивается, оказывается больше (сорт.
по возрас.), тогда они меняются местами.
Так, элементы путем внутригрупповых
перестановок постепенно становятся на
свои позиции, и на посл. шаге (d
= 1)
сортировка сводится к проходу по одной
группе, включающей в себя N
элементов.
#include <iostream>
using namespace std;
int i, j, n, d, c;
void Shell(int A[], int n) //сортировка Шелла
{ d = n; d = d / 2;
while (d > 0)
{ for (i = 0; i < n - d; i++)
{ j = i;
while (j >= 0 && A[j] > A[j + d])
{ c = A[j];
A[j] = A[j + d];
A[j + d] = c;
j--;
}
}
d = d / 2;
}
}