Пример 2
key |
0 |
1 |
4 |
5 |
6 |
7 |
8 |
9 |
15 |
20 |
30 |
40 |
h(ke |
0 |
0 |
0 |
1 |
1 |
1 |
2 |
2 |
2 |
3 |
3 |
3 |
y) |
|
|
|
|
|
|
|
|
|
|
|
|
Номер |
|
|
0 |
|
1 |
2 |
|
|
3 |
|
|
|
входа |
|
|
25 |
|
25 |
25 |
|
25 |
|
|
||
% |
|
|
|
|
|
|
|
|||||
обращени й 



4x1,5x0,25 = 1,5

Открытая адресация
►хэш списков нет, все записи хранятся в самой хэш-таблице,
►каждая ячейка содержит либо значение динамического множества 







 либо NULL.
либо NULL.
 ►Число
►Число хранимых элементов не может быть больше размера таблицы: коэффициент заполнения таблицы не
хранимых элементов не может быть больше размера таблицы: коэффициент заполнения таблицы не  больше 1
больше 1

Алгоритм Insert (T, x)
►1. s = H(x ->key) адрес строки хэш-табл.
►2. Свободна ли строка c адресом s ?
►3. Если ( s ->key = NULL) , то в нее записывается x.
►4. Если (s ->key ≠ NULL), то проверяется
на занятость следующий элемент таблицы 
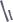 с
с


 адресом
адресом s + R (R - размер элемента).
s + R (R - размер элемента).
 Если строка свободна ((s = s + R) ->key = NULL), то в нее записывается x. Если снова занята,
Если строка свободна ((s = s + R) ->key = NULL), то в нее записывается x. Если снова занята, то повторяется процедура п.4
то повторяется процедура п.4
►5. Поиск свободной строки продолжается

►последовательность просматриваемых ячеек вычисляется, т.е. зависит от ключа
►к хэш-функции добавляем второй аргумент – номер попытки h(key, j), j
принадлежит {0,1,…m-1}-
 Недостаток : время поиска – большое, даже
Недостаток : время поиска – большое, даже  при
при низком коэффициенте заполнения
низком коэффициенте заполнения

Алгоритм Search(T, key)
►1. Вычисляется: H(key,0), адрес строки хэш-таблицы.
►2. Если s ->key = key, то s указывает на искомый элемент.
►3. Если s ->key = NULL, то искомого
 элемента нет.
элемента нет.
►4. Если s ->key ≠ key, то повторяем вычисление s = H(key, j), j = 1, 2… и
s ->key ≠ key, то повторяем вычисление s = H(key, j), j = 1, 2… и
переходим на п.2. 

алгоритм Delete(T,key)):
►при удалении элемента его просто помечают признаком deleted и в алгоритме
Insert (T,x) рассматривают






 признак deleted строки s, как s
признак deleted строки s, как s
->key = NULL, а в алгоритме
Search(T, x), как s ->key ≠ key.

Способы вычисления последовательности испробованных мест при открытой адресации
1. Линейный
h(key,i)=(h'(key)+i) mod 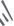
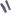
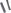

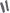




 hashTableSize
hashTableSize .
.

Пример
hashTableSize = 11 ключи:
8881234, 8882345,8883456,8884321, 8886543 hash(key)=key mod 11
hash(8881234) = 8881234 mod 11=10 hash(8882345) = 8882345 mod 11=10 (coll)



 p1=(p0+1)
p1=(p0+1) mod 11= 11 mod 11 =0
mod 11= 11 mod 11 =0  hash(8883456) = 8883456 mod 11=10 (coll) p1=(p0+1) mod 11= 11 mod 11 =0 (coll) p2=(p0+2) mod 11= 12 mod 11 =1
hash(8883456) = 8883456 mod 11=10 (coll) p1=(p0+1) mod 11= 11 mod 11 =0 (coll) p2=(p0+2) mod 11= 12 mod 11 =1

недостаток - приводит к образованию кластеров

2. Квадратичный
h(key,i)=(h'(key)+с1i +c2i2) mod hashTableSize
с1 ≠0 c2 ≠0 |
|
с1= (m+2)/2 |
c2 = -m/2 - > |
линейной |
|
недостаток – > эффект образования  вторичных кластеров
вторичных кластеров