

5.2 Модели использования сверточной нейронной сети для классификации текстов
В данном разделе будут описаны основные подходы использования сверточных нейронных сетей для задачи классификации текстов.
5.2.1 Посимвольный подход
Посимвольных подход для классификации текстов с помощью сверточных нейронных сетей был предложен в статье [20]. Опишем данный метод подробнее. Назовем алфавитом упорядоченный набор символов. Пусть выбранный алфавит состоит из m символов. Каждый символ алфавита в тексте закодирован с помощью 1−m−кодировки. (т. е. каждому символу будет сопоставлен вектор длины m элемент которого равен единице, в позиции равной порядковому номеру символа в алфавите, а нулю во всех остальных позициях.) Если в тексте встретиться символ, который не вошел в алфавит, то необходимо закодировать его вектором длиныmсостоящим из одних нулей. Из текста выбираются первыеlсимволов. Параметрlдолжен быть большим, чтобы в первыхlсимволах содержалось достаточно информации для определения класса всего текста.

Рисунок 5.6: Посимвольный подход
Далее полученные
векторы составляются в матрицу размера
m × l, в которой в каждый столбец будет
иметь не более одной единицы. Каждая
строка полученной матрицы используется
как отдельная карта признаков. На вход
сверточной нейронной сети подается m
карт признаков размера1 × lаналогично изображению. Архитектуру
сети необходимо выбирать исходя из
задачи. На Рис. 5.6 приведен пример
посимвольного подхода для .
В примере показан один сверточный и
один субдискретизирующий слой.
.
В примере показан один сверточный и
один субдискретизирующий слой.
Опишем формально данный подход.
Пусть
 – векторi-го символа в тексте.
– векторi-го символа в тексте.
 (5.1)
(5.1)
Здесь ⊕операция объединения векторов.
Сверточный слой:
 (5.2)
(5.2)

f– функция активации нейронной сети
b– константа
MAX-pooling слой:
 (5.3)
(5.3)
Dropout слой:
 (5.4)
(5.4)
Здесь
 – посимвольное умножение.
– посимвольное умножение.
r– вектор состоящий из нулей и едениц.
5.2.2 Подход c использованием кодирования слов
В данном подходе каждому слову в тексте сопоставляется вектор фиксированной длины, затем из полученных векторов для каждого объекта выборки составляется матрица, которая аналогично изображениям подается на вход сверточной нейронной сети. На Рис. 5.7 приведен пример сверточной нейронной сети cиспользованием кодирования слов.

Рисунок 5.7: Кодирование слов
6 Использование сверточной нейронной сети для профилирования
При профилировании пользователей, а точнее классификации текстов с использованием сверточной нейронной сети:
1) фильтр имеет такую же ширину m, как матрица (на вход нейронной сети поступают целые слова);
2) можно применять одновременно разные фильтры с разными высотами для выделения различных признаков.
Сверточная нейронная сеть является очень эффективным методом представления текстов. Поэтому при работе с ней мы будем использовать два алгоритма классификации текстов: векторной репрезентации и семантической репрезентации.
6.1 Алгоритм при векторной репрезентации слов и текстов
Есть множество методов и технологий представления текстовой информации в виде векторного представления: GloVe, AdaGram, Text2Vec, Seq2Vec и другие, но наиболее популярной технологией является Word2Vec.
Word2Vec – технология от компании Google, которая заточена на статистическую обработку больших массивов текстовой информации. Он собирает статистику по совместному появлению слов в фразах, после чего методами нейронных сетей решает задачу снижения размерности и выдает на выходе компактные векторные представления слов, в максимальной степени отражающие отношения этих слов в обрабатываемых текстах. При этом Word2Vec максимизирует косинусную меру близости между векторами слов, которые встречаются в близких контекстах и минимизирует косинусную меру между словами, которые не встречаются рядом.
В Word2Vec можно использовать две различных архитектуры нейронной сети для перевода слова в вектор: Continuous Bag of Words и Skipgram. Модель Continuous Bag of Words(CBOW) представляет собой метод поиска ассоциированных слов. МодельSkipgram– поиска взаимозаменяемых слов.
Continuous
Bag of Words (CBoW) – мешок
слов. В данном подходе
весь текст просматривается окном ширины и в каждом окне нейронная сеть предсказывает
центральное слово окна
и в каждом окне нейронная сеть предсказывает
центральное слово окна ,
по всем остальным словам в этом окне
,
по всем остальным словам в этом окне ,
где
,
где [21]. Таким образом, при использовании
данной модели происходит выделения
слова вместе с его окружением, иначе
говоря, происходит поиск ассоциированных
слов для выбранного центрального слова.
[21]. Таким образом, при использовании
данной модели происходит выделения
слова вместе с его окружением, иначе
говоря, происходит поиск ассоциированных
слов для выбранного центрального слова.
В общем случае,
когда хотим предсказать слово по C словам
из текста, на входном уровне будет
 нейронов. Выходной сигнал на скрытом
уровне вычисляется по формуле:
нейронов. Выходной сигнал на скрытом
уровне вычисляется по формуле:
 (6.1)
(6.1)
Здесь
 − вектор соответствующийi−ому
входному слову.
− вектор соответствующийi−ому
входному слову.
На рисунке 6.1, что представлен ниже, показана архитектура модели CBoWв общем виде.

Рисунок 6.1: Общий случай модели CBoW
Обучаясь,
нейронная сеть максимизирует
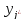 ,
где
,
где − номер предсказываемого слова в
словаре, или, что тоже самое в контексте
данной задачи, максимизирует вероятность
выходного слова
− номер предсказываемого слова в
словаре, или, что тоже самое в контексте
данной задачи, максимизирует вероятность
выходного слова при условии, что известны входное слово
при условии, что известны входное слово .
.
 (6.2)
(6.2)
 (6.3)
(6.3)
Skipgram– В
данном подходе весь текст просматривается
окном ширины и в каждом окне нейронная сеть предсказывает
слова в этом окне
и в каждом окне нейронная сеть предсказывает
слова в этом окне ,
где
,
где по центральному слову окна
по центральному слову окна [21].
[21].
Модель Skipgramпозволяет предсказывать близлежащие слова на основании центрального слова. В этом случае задача нейронной сети заключается в вычислении для данного слова вероятностей появления рядом с ним других слов, согласно словарю. Под словом «рядом» понимается фиксированный размер окна. Таким образом, при использовании данной модели, с точки зрения семантической составляющей, происходит поиск взаимозамяемых слов для выбранного центрального.
На Рис. 6.2 приведен пример архитектуры сети для skipgram модели. Согласно внешнему виду, данная модель напоминает «вывернутую наизнанку» модель CBoW.
В данной модели выходной сигнал на j−ом выходном нейроне для предсказываемого слова под номеромc:
 (6.4)
(6.4)
Предположим,
что нейронная сеть предсказывает Cслов. Обучаясь, она максимизирует ,
где
,
где −
вектор длины C, номера предсказываемых
слов в словаре, или, что тоже самое в
контексте данной задачи, максимизирует
вероятность выходных слов
−
вектор длины C, номера предсказываемых
слов в словаре, или, что тоже самое в
контексте данной задачи, максимизирует
вероятность выходных слов при условии, что известно входное слово
при условии, что известно входное слово .
.
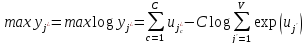 (6.5)
(6.5)
 (6.6)
(6.6)

Рисунок 6.2: Общий случай модели Skipgram
Из формулы Байеса
 (6.7)
(6.7)
понятно, что
увеличение
 повлечет за собой увеличение
повлечет за собой увеличение .
.
В вышеописанных моделях вычисление функции активации софтмакс линейно зависит по времени от объема словаря V. В реальных задачахVможет достигать нескольких сотен тысяч, тогда использование данной функции активации очень затратно по времени, поэтому в реализации Word2Vec используются метод для быстрого вычисления функции активации: иерархический софтмакс (Hierarchical Softmax).
В иерархическом софтмаксе в словаре строится дерево Хафмана по всем словам.
В полученном дереве Vвисячих вершин (листьев). Условная вероятность в этом случае вычисляется следующим образом:
 (6.8)
(6.8)
σ(·)−сигмоидная функция активации.
path(v)−путь от вершины до корня.
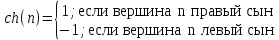
Оценим вычислительную сложность обучения моделей из Word2Vec.
Сложность модели Continuous Bag of Words
 (6.9)
(6.9)
Cложность модели Skipgram
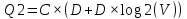 (6.10)
(6.10)
C− максимальное расстояние между словами в одном окне.
V− число слов в словаре.
N− число слов в обучающих данных.
D− число нейронов на скрытом уровне.
Skipgram модель работает медленнее, но обычно с помощью нее достигается лучшее качество классификации текстов.
Ниже представлены примеры работы алгоритмов Word2Vec:
Ассоциированные слова (модель CBoW)для слова «кофе»
зернах 0.757635
растворимый 0.709936
чая 0.709579
коффе 0.704036
mellanrost 0.694822
сублемированный 0.694553
молотый 0.690066
кофейные 0.680409
Взаимозаменяемые слова (модель Skipgram)для слова «кофе»
коффе 0.734483
чая 0.690234
чай 0.688656
капучино 0.666638
кофн 0.636362
какао 0.619801
эспрессо 0.599390
Обобщение нескольких слов (A+B): мобильный телефон
сотовый 0.811114
телефона 0.776416
смартфон 0.730191
телфон 0.719766
мобильного 0.717972
мобильник 0.706131
Преимуществами являются:
Нейронная сеть с данным алгоритмом учится весьма быстро на неподготовленных текстах.
Снижаемая размерность, т.е. словарь с 2.5 млн. токенов ужимается до 256 элементов вектора действительных чисел;
Негативным эффектом векторной репрезентации является быстрая деградация векторов при операциях над ними. Сложение векторов двух слов демонстрирует то общее, что есть между этими словами, при условии, что слова действительно связаны в реальном мире, но попытка увеличить количество слагаемых очень быстро приводит к потере какого-либо практически ценного результата. Сложить слова одной фразы ещё выполнимо, сложить слова нескольких фраз уже нет.