

Структуры и объединения
Из основных типов языка Си++ пользователь может конструировать производные типы, двум из которых посвящена настоящая глава. Это структуры и объединения. Вместе с массивами и классами структуры и объединения отнесены к структурированным типам. В этой главе рассмотрим те их особенности, которые относятся к процедурным возможностям языка, т.е. рассмотрим структуры и объединения в том виде, какой они унаследовали от языка Си.
Структуры данных С++
В данной главе будем считать, что структура - это объединенное в единое целое множество поименованных элементов в общем случае разных типов. Сравнивая структуру с массивом, следует отметить, что массив - это совокупность однородных объектов, имеющая общее имя - идентификатор массива. Другими словами, все элементы массива являются объектами одного и того же типа. Это не всегда удобно. Пусть, например, библиотечная (библиографическая) карточка каталога должна включать сведения, которые приведены для книг в списке литературы, помещенном в конце нашей книги. Таким образом, для каждой книги будет указываться следующая информация:
фамилия и инициалы автора;
заглавие книги;
место издания;
издательство;
год издания;
количество страниц.
Если к библиографической карточке каталога нужно обращаться как к единому целому, то воспользоваться массивом для представления всех ее данных весьма сложно. Все данные имеют разные длины и разные типы. Объединить такие разнородные данные удобно с помощью структуры. Каждая структура включает в себя один или несколько объектов (переменных, массивов, указателей, структур и т.д.), называемых элементами структуры. Сведения о данных, входящих в библиографическую карточку, с помощью структуры можно представить таким структурным типом:
struct card { char *author; // Ф.И.0. автора книги char *title; // Заголовок книги char *city; // Место издания char *fim; // Издательство int year; // Год издания int pages; // Количество страниц };
Такое определение вводит новый производный тип, который будем называть структурным типом. В данном примере у этого структурного типа есть конкретное имя card.
В соответствии с синтаксисом языка определение структурного типа начинается со служебного слова struct, вслед за которым помещается выбранное пользователем имя типа. Описания элементов, входящих в структуру, помещаются в фигурные скобки, вслед за которыми ставится точка с запятой. Элементы структуры могут быть как базовых, так и производных типов. Например, в структурах типа card будут элементы базового типа int и производного типа char *.
Определив структурный тип, можно определять и описывать конкретные структуры, т.е. структурированные объекты, например, так:
card rec1, rec2, rec3;
Здесь определены три структуры (три объекта) с именами rec1, rec2, rec3. Каждая из этих структур содержит в качестве элементов свои собственные данные
char * title; char *city; ...
состав которых определяет структурный тип с именем card.
Если структура определяется однократно, т.е. нет необходимости в разных частях программы определять или описывать одинаковые по внутреннему составу структурированные объекты, то можно не вводить именованный структурный тип, а непосредственно определять структуры одновременно с определением их компонентного состава. Следующий оператор определяет две структуры с именами хх, YY, массив структур с именем ЕЕ и указатель pst на структуру:
struct ( char N[12] ; int value; ) XX, YY, EE[8], *pst;
В хх,уy и в каждый элемент массива ЕЕ [0], ..., ЕЕ [7] входят в качестве элементов массив char N [12] и целая переменная value. Имени у соответствующего структурного типа нет.
Для обращения к объектам, входящим в качестве элементов в конкретную структуру, чаще всего используются уточненные имена. Общей формой уточненного имени элемента структуры является следующая конструкция:
имя_структуры. имя_элемента_структуры
Например, для определенной выше структуры YY оператор
YY.value = 86;
присвоит переменной value значение 86.
Для ввода значения переменной value структуры ЕЕ [4] можно использовать оператор
cin >> EE[4].value;
Точно так же можно вывести в выходной поток cout значение переменной из любой структуры. Другими словами, элемент структуры обладает правами объекта того типа, который указан в конструкции (в определении) структурного типа. Например, для переменных с именем value из структур ЕЕ [0],..., ЕЕ [7], XX, YY определен тип int.
При определении структур возможна их инициализация, т.е. задание начальных значений их элементов. Например, введя структурный тип card, можно следующим образом определить и инициализировать конкретную структуру:
card dictionary = { "Hornby A.S.", "Oxford students\ dictionary of Current English", "Oxford", "Oxford University", 1984, 769 };
Такое определение эквивалентно следующей последовательности операторов:
card dictionary; dictionary.author = "Hornby A.S."; dictionary.title = "Oxford students dictionary of Current English"; dictionary.city = "Oxford"; dictionary.firm = "Oxford University"; dictionary.year = 1984; dictionary.pages = 769;
Нужно еще раз обратить внимание на отличие имени конкретной структуры (в наших примерах dictionary, recl, rec2, гесЗ, XX, YY, ЕЕ [0],..., ЕЕ [7]) от имени структурного типа (в нашем случае card).
С именем структурного типа не связан никакой конкретный объект, и поэтому с его помощью нельзя сформировать уточненные имена элементов. Определение структурного типа вводит только шаблон (формат, внутреннее строение) структур. Идентификатор card в нашем примере - это название структурного типа, т.е. "ярлык" или "этикетка" структур, которые будут определены в программе. Чтобы подчеркнуть отличие имени структурного типа от имени конкретных структур, имеющих этот тип, в англоязычной литературе по языку Си++ для обозначения структурного типа используется термин tag (ярлык, этикетка, бирка). В переводе на русский язык книги Б.Кернигана, Д.Ритчи [3] для обозначения структурного типа использована транслитерация тег. Переводчики с английского и авторы русскоязычных книг по языку Си++ не решились украсить этим термином описание синтаксиса языка Си++, поэтому мы будем говорить о структурном типе, не употребляя терминатег.
Итак, в нашем примере внутренний состав объектов, представляющих библиографические карточки, определен с помощью структурного типа с именем card. Тем самым вводится формат (набор) данных, входящих в будущие однотипные структуры, и этот формат, обозначенный именем card, имеет права типа, введенного пользователем. С его помощью в качестве примера выше определены конкретные структуры (объекты) recl, rec2, reсЗ.
Определение структурного типа может быть совмещено с определением конкретных структур этого типа:
struct PRIM {char *nаmе; long sum;) А, В, С;
Здесь определен структурный тип с именем PRIM и три структуры А, B, C, имеющие одинаковое внутреннее строение.
Повторяю, что будет ошибкой использовать имя структурного типа для именования элемента структуры:
PRIM. sum = 800L; // Ошибочная конструкция С.sum = 800L; // Верная конструкция
Так как имя структурного типа обладает всеми правами имен типов, то разрешено определять указатели на структуры:
имя структурного_типа *имя_указателя_на_ структуру;
Как обычно, определяемый указатель может быть инициализирован. Значением каждого указателя на структуру может быть адрес структуры того же типа, т.е., грубо говоря, номер байта, начиная с которого структура размещается в памяти. Структурный тип задает ее размеры и тем самым определяет, на какую величину (на сколько байтов) изменится значение указателя на структуру, если к нему прибавить 1 (или из него вычесть 1).
Например, после наших определений структурного типа card и структуры rec2 можно так записать определение указателя на структуру типа card:
card *ptrcard = &rec2;
Здесь определен указатель ptrcard и ему с помощью инициализации присвоено значение адреса одной из конкретных структур типа card.
После определения такого указателя появляется еще одна возможность доступа к элементам структуры rec2. Ее обеспечивает операция ' ->' доступа к элементу структуры, с которой в этот момент связан указатель. Формат соответствующего выражения таков:
имя_указателя -> имя_элемента_структуры
Например, количество страниц книги, информация о которой хранится в структуре rec2, будет значением выражения
ptrcard -> pages
Вторая возможность обращения к элементу структуры с помощью адресующего ее указателя - это разыменование указателя и формирование уточненного имени такого вида:
(*имя_ указателя).имя_ элемента_ структуры
Обратите внимание на круглые скобки. Операция разыменования ' * ' должна относиться только к имени указателя, а не к уточненному имени элемента структуры. Таким образом, следующие три выражения эквивалентны:
(*ptrcard).pages ptrcard->page rec2.pages
Все они именуют один и тот же элемент intpages конкретной структуры rec2, имеющей тип card.
Как и для других объектов, для структур могут быть определены ссылки:
имя_структурного_типа& имя_ссылки_на_структуру инициализатор;
Например, для введенного выше структурного типа PRIM можно таким образом ввести ссылки на структуры А, В:
PRIM& refA = А; PRIM& refB(B);
Для разнообразия ссылки refA и refB инициализированы по-разному.
После таких определений refA есть синоним имени структуры А, refB есть другое имя для структуры в. Теперь возможны, например, такие обращения:
А. sum эквивалентно refA. sum;
*B. nаme эквивалентно *refB. nаme;
А. NAME эквивалентно refA. name.
Вернемся к нашей задаче с библиотечными карточками и спроектируем простейшую базу данных, построив ее в виде двухсвязного списка структур (рис. 7.1), каждая из которых имеет такой формат:
struct record { card book; // Структура c датами о книге record *prior; // На предыдущий элемент списка record *next; // На следующий элемент списка };
Структурный тип record предусматривает, что в каждую структуру входят три элемента: структура типа card и два указателя на структуры типа record. Предполагается, что до определения структурного типа record уже определен структурный тип card.
Указатель на структуру может входить в определение того же структурного типа. Именно так в определение формата структуры record введены два указателя:
record *prior - указатель на предыдущий элемент в двухсвязном списке структур;
record *next - указатель на следующий элемент в двухсвязном списке структур.
Чтобы не усложнять нашу задачу создания библиотечной картотеки, примем следующие ограничения и упрощения. Чтобы не программировать процедур ввода исходных данных, подготовим сведения о книгах, включаемых в картотеку, в виде массива структур типа card. Массив структур типа card с исходными данными будем обрабатывать в цикле и включать каждую очередную запись о книге в двухсвязный список структур типа record. Включая записи о книгах в список, будем соблюдать алфавитный порядок по именам авторов. Чтобы не вводить средств для сравнения русских фамилий, а пользоваться стандартными библиотечными функциями сравнения строк, будем рассматривать только книги с фамилиями авторов на английском языке. Для каждой новой карточки, включаемой в двухсвязный список, будем запрашивать необходимый объем памяти, т.е. сформируем список с помощью средств динамического выделения памяти. Начало списка будем сохранять в отдельном указателе структурного типа record *. Указатель prior для первого элемента списка и указатель next для последнего элемента списка будут иметь значение NULL.

Рис. 7.1.Схема двухсвязного списка из трех элементов типа record:
Р - указатель prior; N - указатель next; 0 - значение NULL
Следующая программа соответствует приведенным соглашениям. До функции main () определены структурный тип card, функция printbook() для вывода на экран информации о выбранной книге, структурный тип record.
Здесь же, как внешние данные, доступные для всех функций программы, определены и инициализированы элементы массива book [] структур типа card.
//Р7-01.СРР - библиографическая картотека - двухсвязный // список // Для функции strсmp() сравнения строк: #include < string.h > #include < iostream.h > struct card { // Определение структурного типа для книги char *author; // Ф.И.0. автора char *title; // Заголовок книги char *city; // Место издания char *firm; // Издательство int year; // Год издания int pages; // Количество страниц }; // Функция печати сведений о книге: void printbook(card& car) { static int count = 0; cout <<"\n" <<++count <<". " << car.author; cout <<' ' << car. title "".-"<< car.city; cout <<": " << car.finm <<", "; cout <<"\n" << car.year <<".- " << car.pages <<" c."; } struct record { // Структурный тип для элемента списка card book; record *prior; record *next; }; // Исходные данные о книгах: card books[] = { // Инициализация массива структур: { "Wiener R.S.", "Язык Турбо Си", "М", "Мир", 1991, 384 }, {"Stroustrup В."," Язык Си++", "Киев", "ДиаСофт", 1993, 560 }, {"Turbo C++.", "Руководство программиста", "М", "ИHТКВ", 1991, 394 }, {"Lippman S.B.", "C++ для начинающих", "М", "ГЭЛИОН", 1993, 496 } }; void main() {record * begin = NULL, // Указатель начала списка *last = NULL, // Указатель на очередную запись *list; // Указатель на элементы списка // n - количество записей в списке: int n = sizeof(books) / sizeof(books[0]); // Цикл обработки исходных записей о книгах: for (int i = 0; i < n; i++) { // Создать новую запись (элемент списка): last = new(record); // Занести сведения о книге в новую запись: (*last).book.author = books[i].author; (*last).book.title = books[i].title; last->book.city = books[i].city; last->book.firm = books[i].firm; last->book.year = books[i].year; last->book.pages = books[i].pages; // Включить запись в список (установить связи): if (begin = NULL) // Списка еще нет { last->prior = NULL; begin = last; last->next = NULL; } else { // Список уже существует list = begin; // Цикл просмотра списка - поиск места для // новой записи: while (list) { if (stranp(last->book.author, list->book.author) < 0) { // Вставить новую запись перед list: if (begin == list) { // Начало списка: last->prior = NULL; begin = last; } else { // Вставка между записями: list->prior->next = last; last->prior = list->prior; } list->prior = last; last->next = list; // Выйти из цикла просмотра списка: break; } if (list->next == NULL) { // Включить запись в конец списка: last->nеxt = NULL; last->prior = list; list->next = last; // Выйти из цикла просмотра списка: break; } // Перейти к следующему элементу списка: list = list->next; } // Конец цикла просмотра списка // (поиск места для новой записи) } // Включение записи выполнено } // Конец цикла обработки исходных данных // Печать в алфавитном порядке библиографического списка: list = begin; cout <<'\n' ; while (list) { printbook(list->book); list = list->next; } }
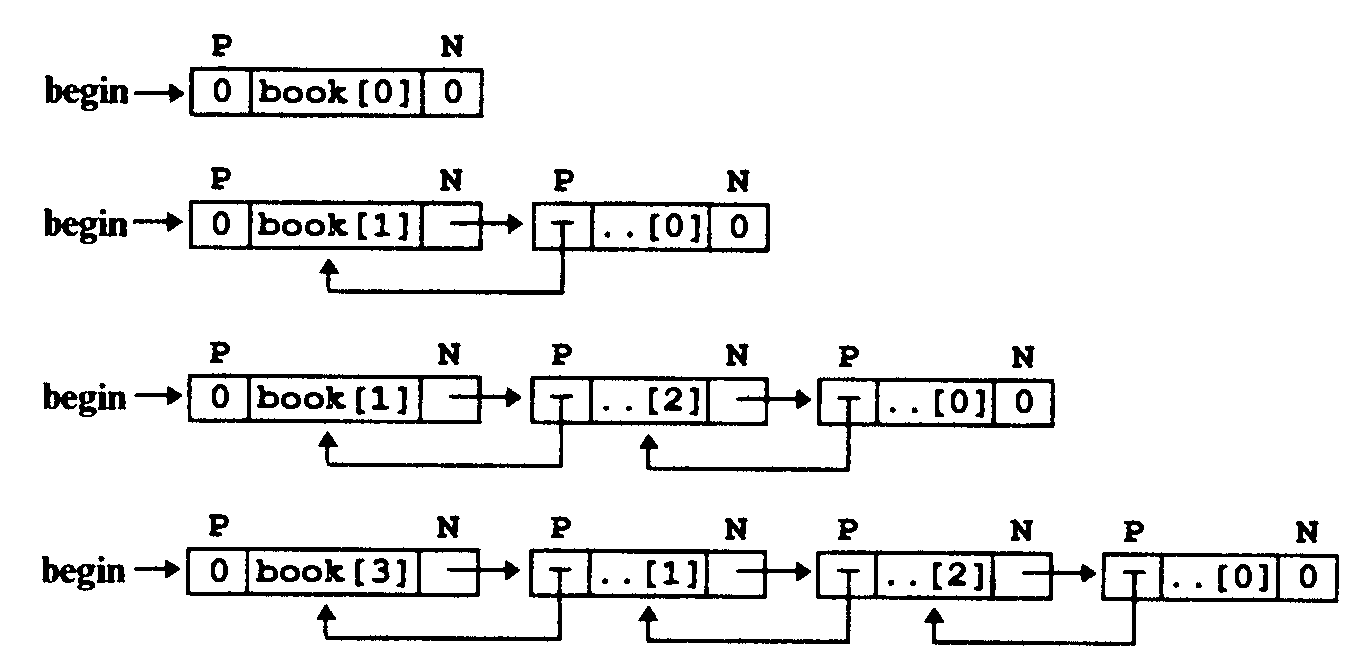
Рис. 7.2.Последовательное формирование двухсвязного списка библиографической картотеки для программы Р7-01. СРР
Результаты выполнения программы Р7-01 .СРР:
1. Lippman S.B. C++ для начинающих. - M: ГЭЛИОН, 1993.- 496с.
2. Stroustrup В. Язык Си++.- Киев: ДиаСофт, 1993.- 560с.
3. Turbo C++. Руководство программиста. - М: ИНТКВ, 1991.- 394 с.
4. Wiener R.S. Язык Турбо Си. - М: Миp, 1991.- 384с.
Изучая структуры, имеет смысл обратить внимание на их представление в памяти ЭВМ. В следующей программе определена структура STR и выведены значения адресов ее элементов:
//Р7-02.СРР - размещение в памяти элементов структуры #include < iostream.h > void main () {struct {long L; int i1, i2; char c[4]; } STR = (10L, 20, 30, 'а', 'b', 'с', 'd'); cout <<"\nsizeof(STR) = " << sizeof(STR) << hex; cout <<"\n&STR.L = " <<&STR.L; cout <<"\n&STR.i1 = " <<&STR.i1; cout <<"\n&STR.i2 = " <<&STR.i2; cout <<"\n&STR.c = " <<&STR.c; }
Результат выполнения программы:
sizeof(STR) = 12 &STR.L = Ox8d800ff4 &STR.il = Ox8d800ff8 &STR.i2 = Ox8d800ffa &STR.C = Ox8d800ffc
Результаты программы и соответствующая им схема на рис. 7.3 иллюстрируют основные соглашения о структурах: все элементы размещаются в памяти подряд и сообща занимают именно столько места, сколько отведено структуре в целом.

Рис. 7.3.Размещение в памяти конкретной структуры из программы Р7-02. СРР
Размещение элементов структуры в памяти может в некоторых пределах регулироваться с помощью опций компилятора. Например, в компиляторах ТС++ и ВС++ [4, 9] имеется возможность "выравнивания" структур по границам слов. При этом каждая структура размещается в памяти с начала слова, т.е. начинается в байте с четным адресом. Если при этом структура занимает нечетное количество байтов, то в ее конец добавляется дополнительный байт, чтобы структура занимала целое количество слов.
Приведем еще некоторые сведения о структурах, которые не сразу бросаются в глаза. Начнем с сопоставления структурного типа с типами, вводимыми с помощью служебного слова typedef. Напомним, что конструкция
typedef тип данных идентификатор;
вводит новое обозначение (идентификатор) для типа_данных, который может быть как базовым, так и производным. В качестве такого производного типа можно использовать структурный тип:
typedef struct PRIM { char *name; long SUB; } NEWSTRUCT; NEWSTRUCT st, *ps, as[8]; PRIM prim_st, *prim_ps, prim_as[8];
В этом примере введен структурный тип PRIM, и ему дополнительно с помощью typedefприсвоено имя NEWSTRUCT. В дальнейшем это новое имя типа использовано для определения структуры st, указателя на структуру ps и массива структур as [8]. С помощью структурного типа PRIM определены такие же объекты: структура prim_st, указатель prim_ps, массив структур prim_as[8]. Таким образом, основное имя структурного типа (PRIM) и имя, дополнительно введенное для него с помощьюtypedef(NEWSTRUCT), совершенно равноправны. При определении с помощьюtypedefимени для структурного типа у последнего может отсутствовать основное имя. Например, структурный тип можно ввести и следующим образом:
typedef struct { char *name; long sum; } STRUCT; STRUCT struct_st, *struct_ps, struct_as[8];
В данном примере имя типа STRUCT вводится с помощью typedefдля структуры, тип которой не поименован. Затемимятипа STRUCT используется для определения объектов.
Таким образом, имеются две возможности определения имени структурного типа, и программист вправе выбирать любую из них.
В отношении элементов структур существует практически только одно существенное ограничение - элемент структуры не может иметь тот же самый тип, что и определяемый структурный тип. Таким образом, следующее определение структурного типа ошибочно:
struct mistake { mistake s; int m; ); // Ошибка!
В то же время элементом определяемой структуры может быть указатель на структуру определяемого типа:
struct correct ( correct *pc; long f; ); // Правильно!
Элементом определяемой структуры может быть структура, тип которой уже определен:
struct begin { int k; char *h; } strbeg; struct next {begin beg; float d;};
Если в определении структурного типа нужно в качестве элемента использовать указатель на структуру другого типа, то разрешена такая последовательность определений [9,21]:
struct A; // Неполное определение структурного типа struct В { struct А *рa; }; struct A { struct В *рb; };
Неполное определение структурного типа А можно использовать в определении структурного типа в, так как определение указателя ра на структуру типа А не требует сведений о размере структуры типа А.
Последующее определение в той же программе структурного типа А обязательно. Использование в структурах типа А указателей на структуры уже введенного типа в не требует пояснений.
Рассматривая "взаимоотношение" структур и функций, видим две возможности: возвращаемое функцией значение и параметры функции.
Функция может возвращать структуру как результат:
struct help { char *name; int number;}; help fund(void); // Прототип функции
Функция может возвращать указатель на структуру:
help *func2(void); // Прототип функции Функция может возвращать ссылку на структуру: help& func3(void); // Прототип функции
Через аппарат параметров информация о структуре может передаваться в функцию либо непосредственно, либо через указатель, либо с помощью ссылки:
void func4 (help str); // Прямое использование void func5 (help *pst); // С помощью указателя void func6 (help& rst); // С помощью ссылки
Напомним, что применение ссылки на объект в качестве параметра позволяет избежать дублирования объекта в памяти.
В программе Р7-01.СРР при формировании двухсвязного списка, объединяющего структуры с данными о книгах, для новых записей память выделялась динамически, т.е. во время выполнения программы:
struct record { card book; record *prior; record *next }; record *last; ... last = new (record); ...
Это позволяет обратить внимание на применение операции newк структурам. Итак, операндом для операцииnewможет быть структурный тип. В этом случае выделяется память для структуры использованного типа, и операция new возвращает указатель на выделенную память. Память может быть выделена и для массива структур, например, так:
last = new record[9]; // Память для массива структур
В этом случае операция newвозвращает указатель на начало массива.
Дальнейшие действия с элементами массива структур подчиняются правилам индексации и доступа к элементам структур. Например, разрешен такой оператор:
last[0].next = NULL;