

-
Аналіз якості моделі: довірчі інтервали для оцінок параметрів економетричної моделі.





-
Аналіз якості моделі: перевірка загальної якості рівняння регресії.


-
Аналіз якості моделі: перевірка статистичної значущості оцінок параметрів економетричної моделі.
Перевіримо
значущість оцінок параметрів Â
і знайдемо для них довірчі інтервали,
припустивши для цього, що залишки u
нормально розподілені, тобто
 .
Тоді параметри моделі Â
задовольняють багатовимірний нормальний
розподіл:
.
Тоді параметри моделі Â
задовольняють багатовимірний нормальний
розподіл:
 (5.17)
(5.17)
Коли
відома величина
 ,
то цей результат можна бути використати
для перевірки значущості елементів
вектора
,
то цей результат можна бути використати
для перевірки значущості елементів
вектора
 та оцінювання довірчих інтервалів
елементів цього вектора. Проте дисперсія
та оцінювання довірчих інтервалів
елементів цього вектора. Проте дисперсія
 невідома, а отже, потрібно розглянути
методи її знаходження.Для цього визначимо
залишки:
невідома, а отже, потрібно розглянути
методи її знаходження.Для цього визначимо
залишки:  Таким
чином, залишки, які можна дістати на
підставі експериментальних даних,
записано у вигляді лінійних функцій
від невідомих залишків
Таким
чином, залишки, які можна дістати на
підставі експериментальних даних,
записано у вигляді лінійних функцій
від невідомих залишків
 .
Тоді суму квадратів відхилень подамо
у вигляді
.
Тоді суму квадратів відхилень подамо
у вигляді

де N — симетрична ідемпотентна матриця.
У цих
перетвореннях ми виходили з того, що N
є симетричною ідемпотентною матрицею,
оскільки En
— одинична матриця, а
 — симетрична розміром n m.Знайдемо
математичне сподівання для обох частин
рівняння (5.19) і застосуємо спочатку
властивість, яка полягає в тому, що
— симетрична розміром n m.Знайдемо
математичне сподівання для обох частин
рівняння (5.19) і застосуємо спочатку
властивість, яка полягає в тому, що
 ,
де
,
де
 — слід матриці N,
а далі — властивість комутативності
добутку матриць відносно операцій
обчислення сліду матриці.
— слід матриці N,
а далі — властивість комутативності
добутку матриць відносно операцій
обчислення сліду матриці.
З огляду на сказане маємо:
 (5.20)
(5.20)
У цьому
співвідношенні матриця
 має порядок
має порядок
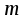 ,
добуток
,
добуток
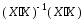 дорівнює
дорівнює
 ,
а її слід дорівнює
,
а її слід дорівнює
 .
Звідси
.
Звідси
 .
(5.21)
.
(5.21)
Співвідношення (5.21) дає нам незміщену оцінку дисперсії залишків.
Нарешті,
лишилося показати, що сума квадратів
залишків
 розподілена незалежно від Â.
Для цього знайдемо коваріацію залишків:
розподілена незалежно від Â.
Для цього знайдемо коваріацію залишків:
 (5.22)
(5.22)
Оскільки
 і Â
є лінійні функції від нормально
розподілених змінних, то вони також
розподілені нормально і, як було показано,
їх коваріації дорівнюють нулю.Це дає
нам змогу скористатися t-розподілом
для перевірки гіпотез відносно істотності
кожного з параметрів економетричної
моделі
і Â
є лінійні функції від нормально
розподілених змінних, то вони також
розподілені нормально і, як було показано,
їх коваріації дорівнюють нулю.Це дає
нам змогу скористатися t-розподілом
для перевірки гіпотез відносно істотності
кожного з параметрів економетричної
моделі
 Перевірку
гіпотези виконаємо згідно з
t-критерієм:
Перевірку
гіпотези виконаємо згідно з
t-критерієм:  , (5.23)
, (5.23)
де
 — діагональний елемент матриці
— діагональний елемент матриці
 .
Знаменник відношення (5.23)
.
Знаменник відношення (5.23)
 — називається стандартною
помилкою оцінки
параметра моделі.Обчислене значення
t-критерію
порівнюється з табличним при вибраному
рівні значущості і
— називається стандартною
помилкою оцінки
параметра моделі.Обчислене значення
t-критерію
порівнюється з табличним при вибраному
рівні значущості і
 ступенях свободи. Якщо t
факт > t
табл,
то відповідно оцінка параметра
економетричної моделі є достовірною.На
основі t-критерію
і стандартної помилки побудуємо довірчі
інтервали для параметрів
ступенях свободи. Якщо t
факт > t
табл,
то відповідно оцінка параметра
економетричної моделі є достовірною.На
основі t-критерію
і стандартної помилки побудуємо довірчі
інтервали для параметрів
 :
:  (5.24)
(5.24)
-
Визначення дисперсій оцінок параметрів та їх стандартних помилок.Щоб мати загальне судження про якість моделі, визначають стандартну похибку апроксимації:

Незміщена оцінка дисперсії залишків з поправкою на кількість ступенів свободи:
 Стандартна
похибка коефіцієнта регресії а1
визначається за формулою:
Стандартна
похибка коефіцієнта регресії а1
визначається за формулою: .
.
Стандартна похибка параметру a0 визначається за формулою:
 .
.
Величина
стандартної похибки разом з t-розподілом
Ст’юдента при n-2
ступенях свободи застос.для перевірки
значущості коеф.регресії і для розрахунку
їх довірчих інтервалів.Станд. похибка
рівняння харак/абсолютну величину
розкладу випад/складов/рівн.і обчисл/за
формулою 
Поправка
на число ступенів свободи дає незміщену
оцінку дисперсії залишків:  . (2.17)
. (2.17)
Зрозуміло, що перевага віддається моделям, у яких стандартна похибка рівняння менша порівняно з іншими моделями. Однак така оцінка якості має суттєвий недолік: через те, що для неї не визначено верхню межу, порівняння різних моделей за цим критерієм досить проблематичне.
-
Визначення параметрів вибраного рівняння.
Економічний
зміст параметрів рівняння лінійної
парної регресії: параметр
 характеризує середню зміну результату
характеризує середню зміну результату
 із зміною фактору
із зміною фактору
 на одиницю. Параметр
на одиницю. Параметр
 при
при
 .
Якщо
.
Якщо
 не може бути рівним нулю, то параметр
не може бути рівним нулю, то параметр
 не має економічного змісту. Інтерпретувати
можна лише знак при
не має економічного змісту. Інтерпретувати
можна лише знак при
 :
якщо
:
якщо
 ,
то відносна зміна результату відбувається
повільніше, ніж зміна фактора і навпаки,
якщо
,
то відносна зміна результату відбувається
повільніше, ніж зміна фактора і навпаки,
якщо
 ,
то відносна зміна результату відбувається
швидше, ніж зміна фактора. Численні
значення параметрів лінійного
програмування регресійного рівняння
можуть бути отримані й за допомогою
графічного подання рівняння регресії.
Параметр а0
визначає
точку перетину прямої Уt
з віссю ординат, а другий параметр
рівняння а1-
це тангенс кута нахилу прямої до осі
абсцис, що визначає наскільки сильно
буде нахилена ця пряма до осі абсцис.
,
то відносна зміна результату відбувається
швидше, ніж зміна фактора. Численні
значення параметрів лінійного
програмування регресійного рівняння
можуть бути отримані й за допомогою
графічного подання рівняння регресії.
Параметр а0
визначає
точку перетину прямої Уt
з віссю ординат, а другий параметр
рівняння а1-
це тангенс кута нахилу прямої до осі
абсцис, що визначає наскільки сильно
буде нахилена ця пряма до осі абсцис.


-
Випадкові збудники в рівнянні лінійної регресії.
Щоб урахувати наявність впливу факторів, які не входять до економ. моделі, ввод. стохаст. складова U. Математ. Аналіз цієї складової дає змогу зробити висновок про те чи можна її вваж. випадковою, чи містить вона системат част. відхилень, яка млже бути зумовлена наявністю тих чи інших помилок у моделюванні. У клас. лінійній економ. моделі змінна u інтерпрет. як випадк. Змінна, що має розподіл з мат мат сподів, яке =0, і пост. дисперсією. Це дає змогу розгляд змінну u як стохастичне збурення ( помилку, відхилення). Згідно з цент. Гоаничн. теоремою стохаст. складова економ. моделі розподілена за норм. законом.
Ut- випадкові збурювання ( помилки) , що характеризують відхилення фактичних значень ендогенної змінної від рівняння регресії ( теоретичної залежності). Джерелами виникнення помилок виступають труднощі у вимірювання у вимірі даних (помилки вимірів ендогенних і екзогенних змінних моделі), основна особливість процесу моделювання, яка полягає у тому, що будь-яка модель є спрощенням дійсності, та помилки специфікації моделі( включення несуттєвих регресорів у модель, включення істотних незалежних факторів і т.п).
Причини, що спонук. появу випадк. Збудника U:
1)будь-яка економ. модель. є спрощення реальн. ситуації, яка є переплетінням різних ф-цій, багато яких не можливо врахувати в можелі.
2) неправ. вибрана ф-ціон. залежн. Внаслілок недостат. Дослідження процесу. Так виробн. Ф-ція описує залежність У від Х може бути: У=β0+β1*х, та насправды не лыныйна. У=β0*х β1.
3)не вірно вибрані пояснювальні змінні.
4) Складна форма зв’язку між цілими компон. подібн. величин.
5)помилки при обробці та аналізі стат. даних.
6)будь-ка стат. функція обмежена, опис не перерв. факторами, але при використ. вибірк. даних з дискр. структурою.
7)людський фактор, який не можливо врахувати.
-
Економетричний аналіз лінійної функції парної регресії в MS Exel.
Для того, щоб здійснити аксонометричний аналіз лінійної функції парної регресії засобами МS Excel, необхідно спочатку увійти в меню Сервіс, потім необхідно вибрати пункт аналіз данних,і у вікну «Аналіз данних» вибрати Регресія. Після цього зявиться вікно, де необхідно ввести початкові вхідні данні та оставити певні додаткові мітки за потребою. Неохідно задати також рівень надійності, який, як правило, становить 95% Після натиснення на кнопку ОК, на новому робочому листі зявиться вивід підсумків, на якому відображаються всі парметри аналізу регресіїї, а саме: коефіцієнт кореляції, коеф. Детермінації, нормований R-квадрат,стандартна похибка, у розділі дисперсіональний аналіз приводяться данні про критерій F. А також за допомогою Аналізу даних можна легко і без зайвих зусиль порахувати T- статистку,P-значення, граничну похибку пробнозу та довірчі інтерали.
11.економетричний аналіз лінійнї фунцйії парної регресії і МС ЕКСЕЛЬ
Для того, щоб здійснити аксонометричний аналіз лінійної функції парної регресії засобами МS Excel, необхідно спочатку увійти в меню Сервіс, потім необхідно вибрати пункт аналіз данних,і у вікну «Аналіз данних» вибрати Регресія. Після цього зявиться вікно, де необхідно ввести початкові вхідні данні та оставити певні додаткові мітки за потребою. Неохідно задати також рівень надійності, який, як правило, становить 95% Після натиснення на кнопку ОК, на новому робочому листі зявиться вивід підсумків, на якому відображаються всі парметри аналізу регресіїї, а саме: коефіцієнт кореляції, коеф. Детермінації, нормований R-квадрат,стандартна похибка, у розділі дисперсіональний аналіз приводяться данні про критерій F. А також за допомогою Аналізу даних можна легко і без зайвих зусиль порахувати T- статистку,P-значення, граничну похибку пробнозу та довірчі інтерали.
-
Елементи класифікації економіко-математичних моделей.
Для класифікації е.м. моделей використовують різні класифікаційні ознаки.
За цільовим призначенням е.м. моделі поділ.на теоретико-аналітичні, що викор.під час досл.заг.вл-стей і закономірн. екон процесів, і прикладні, що застос.у розв’язанні конкретних еконо задач (моделі економічного аналізу, прогнозування).
Відповідно до загальної клас-ції мат моделей вони поділяються на функціональні та структурні, а також проміжні форми (структурно-функціональні). Типовими структурн.мод.є моделі міжгалузевих зв’язків. Прикл.функціон. моделі може слугувати модель поведінки споживачів в умовах товарно-гр.відносин.
Моделі поділяють на дескриптивні та нормативні. Прикладом дескриптивних моделей є вир.ф-ції та ф-ції купівельного попиту, побудовані на підставі опрацюв.статист.даних. Типовим прикладом нормативних моделей є моделі оптимального (раціонального) планування, що формалізують у той чи інший спосіб цілі екон розвитку, можливості і засоби їх досягнення.
За хар-ром відображення причинно-наслідкових аспектів розрізняють моделі жорстко детерміновані і моделі, що враховують випадковість і невизначеність.
За способами відображ чинника часу е.м. моделі поділяються на статичні й динамічні.
Моделі екон процесів надзвичайно різноманітні за формою матем залежностей. Важливо виокремити клас лінійних моделей, що набули значного пошир.завдяки зручності їх використання. Відмінності між лінійними і нелін.моделями є суттєвими не лише з математичного погляду, а й у теоретико-економ плані, адже багато залежностей в екон.мають принципово нелінійний хар-р.
За співвідношенням екзогенних і ендогенних змінних, які включаються в модель, вони поділяються на відкриті і закриті. Повністю відкритих моделей не існує; модель повинна містити хоча б одну ендогенну змінну. Повністю закриті економіко-математичні моделі, тобто такі, що не містять екзогенних змінних, надзвичайно рідкісні. Переважна більшість е.м. моделей посідає проміжну позицію і розрізняється за ступенем відкритості (закритості).
За способом реалізації виділяють:
- аналітичні
- комп’ютерні: а) чисельні, б) імітаційні, в) статистичні.
Для аналітичного моделювання хар-рним є те, що процеси функціонування елементів системи записують у вигляді деяких математичних співвідношень (алгебраїчних, інтегро-диференційних, кінцево-різницевих тощо) чи логічних умов.
Комп’ютерне моделювання хар-ризується тим, що матем модель системи (використовуючи основні співвідношення аналітичного моделювання) подається у вигляді деякого алгоритму та програми, придатної для її реалізації на комп’ютері, що дає змогу проводити з нею обчислювальні експерименти. Залежно від матем інструментарію (апарату), що використовується в побудові моделі, та способу організації експериментів можна виокремити три взаємопов’язані види моделювання: чисельне, алгоритмічне (імітаційне) та статистичне.
У чисельному моделюванні для побудови комп’ютерної моделі використовуються методи обчислювальної математики, а обчислювальний експеримент полягає в чисельному розв’язанні деяких математичних рівнянь за заданих значень параметрів і початкових умов.
Алгоритмічне (імітаційне) моделювання (може бути детермінованим та стохастичним) — це вид комп’ютерного моделювання, для якого хар-рним є відтворення на комп’ютері (імітація) процесу функціонування досліджуваної складної системи.
Статистичне моделювання — це вид комп’ютерного моделювання, який дозволяє отримати статистичні дані відносно процесів у модельованій системі
-
Емпірична модель множинної лінійної регресії.
На
будь-який екон.показник Y
впливає не один, а декілька факторів
(регресорів)
 .
Так попит населення на певний товар
буде визначатися не тільки ціною на
нього, але й цінами на його замінники,
дох.спожив.й іншими факторами. У низці
досл.аналіз.зв’язок доходу працівника
певної галузі виробництва з його рівнем
освіти, віком, стажем роботи в цій галузі.
.
Так попит населення на певний товар
буде визначатися не тільки ціною на
нього, але й цінами на його замінники,
дох.спожив.й іншими факторами. У низці
досл.аналіз.зв’язок доходу працівника
певної галузі виробництва з його рівнем
освіти, віком, стажем роботи в цій галузі.
В
подібних випадках маємо справу з
множинною лінійною моделлю (регресією),
що описує взаємний зв’язок між залежною
змінною Y
та регресорами
 і яку можна подати такому вигляді:
і яку можна подати такому вигляді:

Цей
математичний запис інформує про
функціональну залежність умовного
математичного сподівання залежної
змінної Y
від
m
регресорів змінних Х .
.
Отже, постає задача виявлення статис.взаємозв’язку між Y та Х.
Загальний запис теоретичної лінійної множинної регресії може бути зроблений в такому вигляді:

де

 – теоретичні коефіцієнти регресії
(часткові коефіцієнти) або параметри
теоретичної регресії, які характеризують
реакцію залежної змінної
– теоретичні коефіцієнти регресії
(часткові коефіцієнти) або параметри
теоретичної регресії, які характеризують
реакцію залежної змінної

 на зміну кожного регресора
на зміну кожного регресора

 ;
;
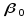 – вільний член, який визначає значення
– вільний член, який визначає значення
 за умови, коли значення регресорів
дорівнюють нулеві;
за умови, коли значення регресорів
дорівнюють нулеві;

 – значення
– значення
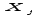 -го
регресора при і-ому
спостереженні;
-го
регресора при і-ому
спостереженні; – випадковий збудник при і-ому
спостереженні.
– випадковий збудник при і-ому
спостереженні.
Для
однозначного визначення параметрів
 моделі (12.1) необхідно, щоб виконувалась
нерівність
моделі (12.1) необхідно, щоб виконувалась
нерівність
 де
n
– число спостережень; m
– число регресорів в моделі.
де
n
– число спостережень; m
– число регресорів в моделі.
У
векторно-матричній формі теоретичну
модель (12.1) можна подати так:
 (16.2)
(16.2)
де

Компоненти
 вектора
вектора
 є величинами сталими (
є величинами сталими ( ),
але невідомими. Їх необхідно оцінити
шляхом обробки вибірки, а тому надалі
будемо мати справу із емпіричною моделлю,
яка є прообразом теоретичної (16.1), (16.2):
),
але невідомими. Їх необхідно оцінити
шляхом обробки вибірки, а тому надалі
будемо мати справу із емпіричною моделлю,
яка є прообразом теоретичної (16.1), (16.2):
 (16.3)
(16.3)
де

Тут
вектор
 є статистичною оцінкою теоретичного
вектора
є статистичною оцінкою теоретичного
вектора
 лінійної множинної регресії
лінійної множинної регресії
Вектор
похибок
 є статистичною оцінкою випадкового
вектора
є статистичною оцінкою випадкового
вектора
 цієї ж моделі.
цієї ж моделі.
Емпірична
модель являє собою статистичний аналог
теоретичної моделі (16.1). За її допомогою
визначаються статистичні оцінки
параметрів
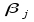 .
При цьому використовується статистична
обробка вибірки.
.
При цьому використовується статистична
обробка вибірки.
В загальному вигляді емпірична модель записується як:
 (16.4)
(16.4)
У
векторно-матричній формі система (16.4)
має вигляд:
 (16.5)
(16.5)
де

Компоненти
 вектора
вектора
 є статистичними оцінками компонент
є статистичними оцінками компонент
 теоретичного вектора
теоретичного вектора
 лінійної множинної регресії (16.2), а
компоненти
лінійної множинної регресії (16.2), а
компоненти
 вектора похибок
вектора похибок
 – статистичні оцінки випадкових
збудників
– статистичні оцінки випадкових
збудників
 вектора
вектора
 .
.
Якщо
теоретичний вектор
 є величиною сталою і нам невідомою, то
емпіричний вектор
є величиною сталою і нам невідомою, то
емпіричний вектор
 ми можемо визначити шляхом обробки
статистичної інформації вибірки обсягом
n.
Враховуючи те, що вибірка складає лише
незначну частину генеральної сукупності
(n≤N),
то інформація, яку одержимо при
статистичній обробці, про регресори Xj
моделі буде не повною і для кожної іншої
вибірки буде потерпати певні зміни.
Отже, компоненти
ми можемо визначити шляхом обробки
статистичної інформації вибірки обсягом
n.
Враховуючи те, що вибірка складає лише
незначну частину генеральної сукупності
(n≤N),
то інформація, яку одержимо при
статистичній обробці, про регресори Xj
моделі буде не повною і для кожної іншої
вибірки буде потерпати певні зміни.
Отже, компоненти
 емпіричного вектора
емпіричного вектора
 будуть містити елемент випадковості.
Таким чином,
будуть містити елемент випадковості.
Таким чином,
 ,
як і сам вектор
,
як і сам вектор
 будуть випадковими величинами, які
мають певні закони розподілу ймовірностей
із відповідними числовими характеристиками.
будуть випадковими величинами, які
мають певні закони розподілу ймовірностей
із відповідними числовими характеристиками.
Із
вище наведеного можемо тепер стверджувати,
що
 є статистичною оцінкою для теоретичного
вектора
є статистичною оцінкою для теоретичного
вектора
 .
А тому постають питання математичної
статистики: зміщена чи незміщена ця
статистична оцінка; в якому довірчому
інтервалі із заданою надійністю γ
можуть перебувати теоретичні компоненти
(параметри)
.
А тому постають питання математичної
статистики: зміщена чи незміщена ця
статистична оцінка; в якому довірчому
інтервалі із заданою надійністю γ
можуть перебувати теоретичні компоненти
(параметри)
 і сама функція регресії; як здійснити
перевірку на статистичну значущість
теоретичних параметрів
і сама функція регресії; як здійснити
перевірку на статистичну значущість
теоретичних параметрів
 по заданому рівню значущості α.
по заданому рівню значущості α.
Для
вирішення цих питань нам необхідно
визначити числові характеристики для
параметрів
 (j=0,1,2,...,m)
і для самої функції регресії, використовуючи
при цьому елементи матричної алгебри
як інструментарію, застосовуючи який
ми можемо без громіздких викладок
отримати необхідні результати.
(j=0,1,2,...,m)
і для самої функції регресії, використовуючи
при цьому елементи матричної алгебри
як інструментарію, застосовуючи який
ми можемо без громіздких викладок
отримати необхідні результати.
14Етапи економіко-математичного моделювання.

Гол.проблемою для практ.заст. мат мод.в ек.є проблема наповнення розроблених моделей конкретною та якісною інф-єю. Точність і повнота перв.інф-ї, реальні можл.її збору й опрацюв.справляют визнач. вплив на вибір типів моделей.
1. Постановка екон проблеми та розроблення концептуальної моделі. Головне на цьому етапі — чітко сформулювати сутність проблеми (цілі дослідження), припущення, що приймаються, і ті питання, на які необхідно одержати відповіді. З урахуванням цілей досл.проводиться якісний аналіз об’єкта; виокремл., абстрагуючись від другорядних, найважливіші риси і власт.об’єкта, що моделюється. На цьому етапі модел-ня широко застос-ся якісні методи опис.систем, знакові та мовні моделі. Таке зображ.системи називають концептуальною моделлю.
2. Розроблення матем моделей. Це етап формалізації екон проблеми, вираження її у вигляді конкретних математичних залежностей і відношень . На цьому етапі провод.теоретдосл.моделі, обир.методи досл. й розв..Метою теоретдосл.є з’ясування заг.вл.моделі. Гол.момент — доведення існув.розв’язку для моделі.
3. Реаліз.моделі у вигляді ППП та проведення розрахунків. Цей етап включає розробку алгоритмів для числового розв’язування задачі, складання програм на ЕОМ (можливе використання існуючих ППП з відповідною адаптацією) і безпосереднє проведення розрахунків. Труднощі зумовлені великою розмірністю економічних задач, необхідністю опрацювання значних масивів інформації. Клас економічних задач, які можна розв’язувати числовими методами, значно ширший, ніж клас задач, доступних аналітичному дослідженню.
4. Перевірка адекватності моделі. Вимога адекватності є суперечною вимозі простоти, і це слід враховувати, перевіряючи модель на адекватність. Початковий варіант моделі попередньо перевіряється за такими основними аспектами: чи всі суттєві параметри включені в модель; чи містить модель несуттєві параметри; чи правильно відображені функціональні зв’язки між параметрами; чи правильно визначені обмеження на значення параметрів тощо.
Для встановлення відповідності створюваної моделі оригіналу використовують такі методи:
-
порівняння рез-тів моделювання з окремими експериментальними рез-тами, одержаними за однакових (подібних) умов;
-
використання інших схожих моделей;
-
порівняння структури і функціонування моделі з прототипом.
Головним шляхом перевірки адекватності моделі досліджуваного об’єкта виступає практика. Але вона потребує накопичення статистики, котра не завжди буває достатньою для отримання надійних даних. Для багатьох моделей перші два методи виявляються менш прийнятними. Тоді залишається лише один шлях: висновок про подібність моделі та прототипу робити на підставі порівняння їхніх структур і виконуваних ф-й. Такі висновки не мають формального хар-ру, оскільки ґрунтуються на досвіді та інтуїції дослідника.
Згідно з рез-тами перевірки моделі на адекватність приймається рішення про можливість її практичного використання чи проведення коригування.
-
Аналіз числових рез-тів та прийняття відповідних рішень. Рез-ти досліджень подаються у вигляді, зручному для огляду, і на основі обробки отриманих рез-тів проводиться аналіз матеріалів дослідження моделі. На цьому, завершальному, етапі виникає питання про правильність і повноту рез-тів моделювання, про можливість практичного застосування останніх, і, найголовніше, про досягнення цілей дослідження.
15Етапи побудови економетричної моделі.
Побудова економетричної моделі можлива за таких умов:
1) наявність достатньо великої сукупності спостережень вихідних даних;
2) однорідність сукупності спостережень;
3) точність і вірогідність вихідних даних;
4) висунення гіпотези про набір змінних і структуру зв’язків.
Процес економ. Моделювання склад. з наст. кроків:
1)Вибір конкр.форми аналіт. залежн. між економ. показн. ( специфік. моделі) на підставі відпов. економ. теорії.
2)Сбір та підготовка статист. Інформ.
3) Оцінюв. парам. Моделі
4)Перевірка на адекватн. Та достовірність її параметрів.
6)застосув. Моделі для прогнозування та розвитку економ. процесів з метою подальшого керування ними.
Побудова будь-якої економетричної моделі, незалежно від того, на якому рівні і для яких показників вона будується, здійснюється як послідовність певних кроків.
Крок 1. Знайомство з економічною теорією, висунення гіпотези взаємозв’язку. Чітка постановка задачі.
Крок 2. Специфікація моделі. Використовуючи всі ті форми функцій, які можуть бути застосовані для вивчення взаємозв., необх.сформ. теоретичні уявлення і прийняті гіпотези у вигляді матем.рівнянь. Ці рівняння встановлюють зв’язки між основними визначальними змінними за припущення, що всі інші змінні є випадковими.
Крок 3. Формування масивів вихідної інформації згідно з метою та завданнями дослідження.
Крок 4. Оцінка параметрів економетр.моделі методом найм.квадратів, що дає змогу проаналіз. залишки і відпов.на запитання: чи не суперечить специф.моделі передумовам “класичної” моделі лінійної регресії?
Крок 5. Якщо деякі передумови моделі не вик., то для прод.аналізу треба замінювати специф.або застос.інші методи оцінюв.параметрів.
Крок 6. Проведення аналізу вірогідності моделі та визначення прогнозу за побудованою моделю.
Схематично всі кроки можна зобразити так:

17Метод найменших квадратів.
Застосування методу найменших квадратів до загальної лінійної багатофакторної моделі передбачає наявність таких передумов:
1) кожне значення випадкової складової рівняння щ, і = 1,2,...,п, є випадковою величиною і математичне сподівання залишків щ до-рівнює нулю:
М(и) = 0;
2) компоненти вектора залишків некорельовані (лінійно неза-лежні) між собою і мають сталу дисперсію:

3) пояснюючі змінні (регресори, фактори моделі) некорельовані із залишками;
4) пояснюючі змінні некорельовані між собою.
Наявність залежності між залишками та незалежними змінними найчастіше пов’язана з тим, що в моделі присутні лагові (затримані в часі) змінні або вона будується на базі одночасних структурних рівнянь. Для оцінювання параметрів і в цьому разі застосовують інші методи.
Залежність між незалежними змінними може значною мірою впливати на якість оцінок, отриманих за МНК. Якщо між незалежними змінними моделі існують тісні лінійні зв'язки, це явище називають мультиколінеарністю.
Важливе значення має припущення про нормальний розподіл залишків моделі. Це припущення забезпечує нормальний розподіл коефіцієнтів регресії й дає змогу використовувати відомі критерії для перевірки статистичних гіпотез відносно отриманих оцінок, а також визначати їх довірчі інтервали.
-
Методи прогнозування часових рядів: прогнозування тенденцій часового ряду за аналітичними методами.
Аналітичні методи згладжування часових рядів ґрунтуються на припущенні, що відомий загальний вигляд невипадкової складової часового ряду. Вони реалізуються за допомогою регресійних та адаптивних методів.
Адаптивні методи прогнозування
Адаптивні методи прогнозування застосовуються в ситуації зміни зовнішніх умов, коли найбільш важливими стають останні реалізації досліджуваного процесу. Загальна схема побудови адаптивних методів може бути подана так:
1) за кількома першими рівнями ряду будується модель і оцінюються її параметри;
2) на основі побудованої моделі розраховується прогноз на один крок вперед, причому його відхилення від фактичного рівня ряду розцінюється як помилка прогнозування, яка враховується відповідно до прийнятої схеми коригування моделі;
3) за моделлю з відкоригованими параметрами розраховується прогнозна оцінка на наступний момент часу тощо.
20Методи прогнозування часових рядів: прогнозування тенденцій часового ряду за середніми характеристиками.
Найпростішим способом прогнозування вважається підхід, який визначає прогнозову оцінку від фактично досягнутого рівня за допомогою середнього рівня, середнього приросту, середнього темпу зростання.
Екстраполяція
на основі середнього рівня ряду.
Під час екстраполяції соціально-економічних
процесів на основі середнього рівня
ряду прогнозоване значення беруть як
середнє арифметичне значення попередніх
рівнів ряду, тобто точковий прогноз
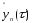 ,
зроблений у момент часу
,
зроблений у момент часу
 на період упередження
на період упередження
 ,
розраховують за формулою:
,
розраховують за формулою:
 .
.
Інтервал надійності для прогнозованої оцінки ряду дорівнює:
 .
.
Екстраполяцію
за середнім абсолютним приростом можна
бути виконати в тому разі, коли загальна
тенденція розвитку вважається лінійною.
Прогнозову оцінку
 одержують за формулою:
одержують за формулою:
 ,
,
де  –
середній абсолютний приріст.
–
середній абсолютний приріст.
Екстраполяцію
за середнім темпом зростання
можна виконувати у разі, коли є підстави
вважати, що загальна тенденція динамічного
ряду характеризується експоненціальною
кривою. Прогноз
 ,
зроблений у момент часу
,
зроблений у момент часу
 на період випередження
на період випередження
 ,
у цьому разі розраховують за формулою:
,
у цьому разі розраховують за формулою:
 ,
,
де  –
середній темп зростання, розрахований
за середньою геометричною.
–
середній темп зростання, розрахований
за середньою геометричною.
Інтервал надійності прогнозу за середнім абсолютним приростом і середнім темпом зростання можна одержати лише тоді, коли ці середні визначаються за допомогою статистичного оцінювання параметрів відповідно лінійної та експоненціальної кривої.
21Методи прогнозування часових рядів: прогнозування тенденцій часового ряду за механічними методами.
Механічні методи згладжування часових рядів використовують фактичні значення сусідніх рівнів ряду і не досліджують аналітичний вид згладженої функції. Вони мають механізм автоматичного налагодження на зміну досліджуваного показника. Завдяки цьому модель постійно пристосовується до зміни інформації й наприкінці інтервалу прогнозової бази відображає тенденцію, що склалася на поточний момент. До механічних методів належать: згладжування по двох точках, метод простої ковзкої середньої, метод зваженої ковзкої середньої, метод експоненційного згладжування.
Метод
ковзної середньої
( –
«moving average»).
–
«moving average»).
Згладжування за допомогою ковзної середньої ґрунтоване на тому, що в середніх величинах взаємно гасяться випадкові відхилення. Саме зменшення випадкового розкиду (дисперсії) якраз і означає згладжування відповідної траєкторії.
При
згладжуванні за допомогою ковзної
середньої початкові рівні часового
ряду
 замінюють його середніми (згладженими)
величинами
замінюють його середніми (згладженими)
величинами
 ,
розрахованими для певної кількості
рівнів ряду. Кількість даних, які входять
до інтервалу, називають порядком ковзної
середньої.
,
розрахованими для певної кількості
рівнів ряду. Кількість даних, які входять
до інтервалу, називають порядком ковзної
середньої.
 .
.
Для
визначення згладжених значень
 у
у
 перших і
перших і
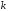 останніх крайніх точках усього часового
ряду можна використати відповідні
значення локально апроксимаційних
поліномів, побудованих, відповідно, за
останніх крайніх точках усього часового
ряду можна використати відповідні
значення локально апроксимаційних
поліномів, побудованих, відповідно, за
 першими та
першими та
 останніми точками часового ряду
останніми точками часового ряду
 .
.
Точніші
результати згладжування дає застосування
зваженої
ковзної середньої.
Її оцінку
 в середині кожного інтервалу згладжування
описує поліном р-го
ступеня:
в середині кожного інтервалу згладжування
описує поліном р-го
ступеня:
 .
.
Параметри цього рівняння знаходять за методом найменших квадратів. Ковзну середню в обраному інтервалі визначають як зважене середнє усіх попередніх рівнів, причому ваги спостережень мають неоднакові значення.
Наприклад,
якщо в інтервал згладжування входять
п’ять спостережень, а тенденцію можна
представити поліномом другого ступеня,
то згладжений середній рівень у взятому
інтервалі виражатиме значення тенденції
на початку відліку. За
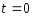 початок відліку, як виходить із формули
(5.6), дорівнює
початок відліку, як виходить із формули
(5.6), дорівнює
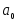 .
.
Для цього випадку:
 ,
,
де
коефіцієнти за
 (позначимо їх
(позначимо їх
 )
характеризують «вагу», що надається
рівню ряду, розташованому на відстані
)
характеризують «вагу», що надається
рівню ряду, розташованому на відстані
 від моменту
від моменту
 .
Наприклад,
.
Наприклад,
 .
.
Обчислені
значення вагових коефіцієнтів
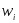 ,
,
 для різної довжини відрізків усереднення
для різної довжини відрізків усереднення
 (або порядку згладжування
(або порядку згладжування
 )
і порядку апроксимаційного полінома
)
і порядку апроксимаційного полінома
 наведено в таблиці 19.1 [24]. Зазначимо, що,
по-перше, значення
наведено в таблиці 19.1 [24]. Зазначимо, що,
по-перше, значення
 для додатних
для додатних
 не наводяться, оскільки коефіцієнти
симетричні стосовно середини відрізка
згладжування, тобто
не наводяться, оскільки коефіцієнти
симетричні стосовно середини відрізка
згладжування, тобто
 ;
по-друге, за однакової довжини інтервалів
згладжування
;
по-друге, за однакової довжини інтервалів
згладжування
 ,
ваги
,
ваги
 для поліномів парного ступеня будуть
такими самими, що й для поліномів ступеня,
більшого на одиницю (непарного).
для поліномів парного ступеня будуть
такими самими, що й для поліномів ступеня,
більшого на одиницю (непарного).
Метод
ковзної середньої набув поширення для
короткотермінового прогнозування. За
невеликої кількості спостережень метод
часто призводить до викривлення
тенденцій, а вибір величини інтервалу
згладжування важко обґрунтувати, хоча
від цього залежить форма кривої. Одночасно
зі зменшенням дисперсії у згладженому
ряду можуть з’явитися систематичні
коливання, зумовлені автокореляцією
його послідовних значень аж до порядку
 (ефект Слуцького-Юла), тобто методи
ковзної середньої можуть спричинити
автокореляцію залишків, навіть якщо
вона була відсутня у початкових даних.
(ефект Слуцького-Юла), тобто методи
ковзної середньої можуть спричинити
автокореляцію залишків, навіть якщо
вона була відсутня у початкових даних.
Метод експоненціального згладжування.
Метод
експоненціального згладжування
дає можливість описати такий перебіг
процесу, коли найбільшої ваги надають
останньому спостереженню, а вага решти
спостережень спадає геометрично. Так,
для спостережень
 ,
,
 прогноз наступного значення
прогноз наступного значення
 має вигляд:
має вигляд:
 ,
,
 ,
,
де
підсумок усіх ваг дорівнює 1, а
 –
параметр згладжування.
–
параметр згладжування.
Практичний розрахунок експоненціальної середньої здійснюють за рекурентною формулою:
 або
або
 ,
,
тобто
в розрахунку нової експоненціальної
середньої беруть попередню експоненціальну
середню та частку
 від різниці між попереднім спостереженням
і його згладженим значенням, тобто
похибки
від різниці між попереднім спостереженням
і його згладженим значенням, тобто
похибки
 .
.
Використання
методу експоненціального згладжування
передбачає розв’язання трьох питань:
вибір постійної згладжування
 ,
вибір початкового рівня згладжування
ряду
,
вибір початкового рівня згладжування
ряду
 ,
вибір початкового моменту згладжування
(довжини бази згладжування). Аналітичного
розв’язку поставлених завдань наразі
не існує, і він навряд чи можливий. Вибір
характеристик згладжування має
ґрунтуватися на експериментальних
розрахунках і здійснюватися в кожному
конкретному випадку по-різному.
,
вибір початкового моменту згладжування
(довжини бази згладжування). Аналітичного
розв’язку поставлених завдань наразі
не існує, і він навряд чи можливий. Вибір
характеристик згладжування має
ґрунтуватися на експериментальних
розрахунках і здійснюватися в кожному
конкретному випадку по-різному.
Вибір
параметра згладжування
 є основною та доволі складною проблемою.
Для різних значень
є основною та доволі складною проблемою.
Для різних значень
 результати прогнозування відрізнятимуться.
Якщо значення
результати прогнозування відрізнятимуться.
Якщо значення
 близьке до одиниці, то під час прогнозування
зважають здебільшого на основному вплив
останніх спостережень; якщо близьке до
нуля то вплив рівнів ряду спадає повільно,
що вможливлює врахування попередніх
значень.
близьке до одиниці, то під час прогнозування
зважають здебільшого на основному вплив
останніх спостережень; якщо близьке до
нуля то вплив рівнів ряду спадає повільно,
що вможливлює врахування попередніх
значень.
Від
вибору початкового рівня згладжування
 залежить поведінка наступної згладженої
послідовності. Найчастіше він або
дорівнює значенню першого рівня ряду
залежить поведінка наступної згладженої
послідовності. Найчастіше він або
дорівнює значенню першого рівня ряду
 ,
або береться на рівні середньої
арифметичної ряду. Зазначимо, що чим
довший ряд, тим менший вплив на результат
згладжування справляє вибір
,
або береться на рівні середньої
арифметичної ряду. Зазначимо, що чим
довший ряд, тим менший вплив на результат
згладжування справляє вибір
 .
.
Вибір
початкового моменту згладжування
(довжини бази згладжування). Проблема
вибору початкової точки згладжування
зумовлена від проблемою вибору сталої
згладжування
 .
Чим ближче початкова точка до поточної,
тим менше інформації знадобиться для
побудови прогнозу і тим ближче
.
Чим ближче початкова точка до поточної,
тим менше інформації знадобиться для
побудови прогнозу і тим ближче
 до 1; чим далі початкова точка до поточної,
тим менш чутливим буде прогноз до нових
даних, і тим ближче
до 1; чим далі початкова точка до поточної,
тим менш чутливим буде прогноз до нових
даних, і тим ближче
 до 0.
до 0.
Метод
експоненціального згладжування
застосовують під час короткотермінового
прогнозування. Для побудови прогнозу
необхідно задати лише початкову оцінку
прогнозу, подальші розрахунки здійснюються
автоматично мірою надходження нових
даних спостережень, і прогноз не потрібно
обчислювати спочатку. За цим методом
згладжування не втрачаються ані
початкові, ані останні рівні заданого
часового ряду, тут немає точки, на якій
ряд обривається. Чутливість експоненціально
зваженого середнього з метою підвищення
адекватності прогнозової моделі можна
в будь-який момент змінити, якщо зробити
іншою величину

22.Моделі з порушенням передумов використання звичайного методу найменших квадратів.
Під час реалізації регресійного аналізу за допомогою звичайного МНК особливу увагу необхідно звернути проблеми, пов’язані виконанням необхідних умов для випадкових відхилень, оскільки властивості статистичних оцінок параметрів лінійна регресія (ЛР) перебуває у прямій залежності від цих відхилень. Для одержання якісних статистичних оцінок, необхідно уважно стежити за виконанням передумов,що сформульовані в теоремі Гаусса-Маркова, бо їх порушення, при використанні … дає статистичні оцінки, яким притаманні небажанні властивості.

Однією
з передумов Г-М є:
Виконання цієї умови наз.гомоскедастичністю залишків. Порушення цієї умови є головною ознакою наявності гетероскедастичності моделі.
Моделі, для яких не виконуються передумови Г-М можна поділ на 3 групи:
Перша
група:

Вони між собою є парно не корельованими.
В
цьому випадку коваріаційна матриця
випадкового вектора буде мати вигляд:
Такі моделі наз економетричними моделями з озн гетероскед залишків.
Друга
група:


Вони є парно корельованими.
В цих моделях між випадковими відхиленнями існує кореляційний зв’язок, хоча дисперсії їх є статистичними величинами.
В
цьому випадку коваріаційна матриця
випадкового вектора буде мати вигляд:
Матриця є симетричною, тому в цих моделях викор 1МНК не рекомендується внаслідок існування коваріаційних моментів між випадковими залишками.
Третя
група:

Для моделей 1-ої групи статистична оцінка параметрів здійснюється шляхом використання ЗМНК, для моделей 2-3-оїгруп – УМНК.
23. Основні дефініції економіко – матем. Моделювання.
Економетрія – це порівняно новий напрямок економ.. науки, що утворився від поєднання теоретичної економіки, математики та статистики.
Слово «економетрія» означ.. «вимірювання в економіці»
Поняття економетрія було загальноприйнятим терміном тільки в період його зародження. В подальшому, поч.. швидко розвиватися 3 окремі напрямки економетрії:
1. теоретичні дослідження, які ґрунтувались на вик-ні математики та статистики
2. абстрактно – теоретичні дослідження матем.. моделей економіки, які не вик-ть емпіричних даних
3. дослідження емпірично – статистичного спрямування
Економетрія (в широкому розумінні) – це сукупність різного ряду економ.. досліджень, що здійснюється з вик-ням матем..методів.
Економетрія (в вузькому розумінні) – це вик-ня статистич.. методів в економ.. дослідженнях, а саме, побудова математико – статистичних моделей економ.. процесів, оцінка параметрів моделей.
Економетрія – це самостійна наукова дисципліна, яка об’єднує сукупність теоретичних результатів, засобів, прийомів, методів і моделей, призначених для того, щоб на базі економ.. теорії, економ.. статистики та математико – статистичного інструментарію надавати конкретних к-них значень загальним закономірностям, обґрунтованими економ.. теорією.
Економіко – математична модель – це математичний опис економічного процесу або явища з метою його дослідження та управління.
Оптимізаційна модель дозволяє з декількох альтернативних варіантів вибрати найкращий варіант за будь-якою ознакою
24. Основні задачі економетрії
Дослідження розвитку економ. Процесів і прогнозування їх динаміки.
Правильний вибір факторів при побудові математико – статистичних моделей.
Вибір та побудова матем.-статистичних моделей, здійснення ряду модельних експериментів, аналіз одержаних результатів і перенесення їх на реальну економ. Систему (процес) як основу для прийняття належних управлінських рішень.
25-26. Основні поняття та попередній аналіз рядів динаміки: основні характеристики динаміки ЧР
Для аналізу соціально-економічних показників абсолютні рівні моментальних або інтервальних часових рядів, а також рівні середніх величин часто доводиться перетворювати на відносні величини. Найпоширеніші характеристики динаміки розвитку соціально-економічних процесів та їхні розрахунки наведено в табл. 1.
Таблиця 1
ХАРАКТЕРИСТИКИ ДИНАМІКИ ЧАСОВОГО РЯДУ
|
Характеристики |
Розрахункові формули |
|
1. Абсолютний приріст |
|
|
2. Коефіцієнт зростання |
|
|
3. Коефіцієнт приросту |
|
|
4. Темп зростання |
|
|
5. Темп приросту |
|
|
6. Середня арифметична |
|
|
7. Середня хронологічна |
|
|
8. Середній абсолютний приріст |
|
|
9. Середній темп зростання |
|
|
10. Середній темп приросту |
|




 ,
або
,
або
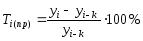





Для визначення змін, що відбув.з .явищем, передусім обчислюють швидкість розвитку цього явища за часом. Показником шв.слугує абс.приріст, який хар. величину зміни показника за інтервал часу між порівнюваними періодами.Точніше, швидкість зміни показника хар.приріст за одиницю часу; ця вел.має назву сер.абс.приросту:
Зокрема,
сер.абс.приріст за весь період спост.для
заданого часового ряду хар.сер.шв.зміни
часового ряду, де
 — індекс останнього спос..
— індекс останнього спос..
Для визн.відносної шв.зміни екон.явища як одиницю часу вик.відносні показники: коеф.зростання й приростуНа практиці часто застосовують показники темпу зростання й темпу приросту:Темп приросту показує, на скільки % рівень одного періоду зб.стосовно рівня іншого періоду, тобто цей показник хар.відносну вел.приросту у %.
Порівняння абс.приросту та темпу приросту за той самий інтервал часу показує, що в реальних економічних процесах уповільнення темпу приросту часто не супроводжується зм.абсолютних приростів.
Абс.знач.одного
% приросту
визнач.як
відношення абс.приросту
 до темпу приросту у %.Сер.шв.зміни
показника, що вивчається, за певний
період характеризує також середній
темп зростання.
до темпу приросту у %.Сер.шв.зміни
показника, що вивчається, за певний
період характеризує також середній
темп зростання.
Показник сер.темпу зростання, обчисл.за формулою сер.геометричної має суттєві недоліки, оскільки ґрунтується на зіставленні останнього та початкового рівнів часового ряду, проміжні рівні до уваги не беруться. У разі суттєвого коливання рівнів вик.сер.геометричного темпу зростання для стат.аналізу може призвести до серйозних помилок, внаслідок чого реальна тенденція часового ряду буде викривлена.
Сучасні способи розрахунків середнього темпу зростання певною мірою позбавлені недоліків середньої геометричної.
Якщо тенденція часового ряду не змінюється, використовують характеристику середнього рівня ряду. В інтервальному ряду динаміки з однаково розташованими в часі рівнями середній рівень ряду обчислюють за формулою простої середньої арифметичної
Якщо інтервальний ряд має неоднаково розташовані в часі рівні, тоді середній рівень ряду (так звану середню хронологічну) обчислюють за формулою зваженої арифметичної середньої, де вагою є тривалість часу (наприклад, кількість років), упродовж якого рівень постійний: