

4. Строковые данные
Если элементы данных в списке представлены строками, можно использовать два различных варианта. Самый простой - применить двоичный поиск. При двоичном поиске значения элементов непосредственно сравниваются друг с другом, благодаря чему метод может легко обрабатывать строковые данные.
С другой стороны, интерполяционный поиск использует числовые значения данных элементов для вычисления индекса искомого элемента. Если элементы представляют собой строки, то алгоритм не может непосредственно по значениям данных вычислить местоположение искомого элемента.
Если строки слишком длинные, чтобы их можно было закодировать даже числами в формате Double, то все еще можно использовать для интерполяции строковые значения. Начните с определения первого символа, которым отличаются list^[min] и list^[max]. Закодируйте следующие три символа каждой строки и соответствующие три символа искомого значения. Затем используйте эти значения для интерполяции.
Например, предположим, что вы ищете строку TARGET в следующем списке: TABULATE, TANTRUM, TARGET, TATTERED, THEATRE. Если min = 1 и max = 5, то проверяются значения TABULATE и THEATRE. Эти значения отличаются, начиная со второго символа, поэтому необходимо рассматривать три символа, начиная с символа 2. Это АВU для list^[1],HEA для list^[5] и ARG для искомой строки.
Эти строки кодируются как 804, 5968 и 1222 соответственно. Подставляя эти значения для вычисления среднего значения в алгоритме интерполяционного поиска, получим:
Middle = min + (target - List (min)) *
((max - min) / (List(max) - List(min))) =
= 1 + (1222 - 804) * «5 - 1) / (5968 - 804)) = 1,3
Это значение округляется до 1, поэтому следующее среднее равно 1. Поскольку list^[1] = TABULATE меньше, чем TARGET, поиск продолжается для значений min = 2 и max = 5.
5. Следящий поиск
Если программа должна найти в списке много элементов, и известно заранее, что элементы будут близки друг к другу, то метод отслеживания может значительно ускорить поиск. Вместо того чтобы начинать поиск, проверяя весь список, можно использовать результаты предыдущего поиска, чтобы начать поиск поблизости от искомой позиции.
5.1 Двоичное отслеживание и поиск
Чтобы начать двоичный следящий поиск (binary hunt search), сравните искомое значение из предыдущего поиска с новым искомым значением. Если новое значение меньше, начните поиск слева, если больше - справа.
Для выполнения слежения влево возьмите значения min и max из предыдущего поиска. Затем установите min в min - 1 и сравните искомое значение с list^[min]. Если искомый элемент меньше, чем list^[min],задайте max = min, a min = min- 2 и попробуйте еще раз. Если элемент все же меньше, установите max = min, a min = min - 4 . Если и это не помогает, укажите max = min, a min = min - 8 и т.д. Продолжайте устанавливать max = min и вычитать из min следующую степень 2, пока вы не найдете значение, где list^[min] будет меньше искомого значения.
Убедитесь, что программа не вышла за нижнюю границу массива. Если же она достигла этой точки, установите значение min равным нижней границе массива. Если list^[min] все еще больше искомого элемента, то данного элемента в списке нет. На рисунке 4 показан следящий поиск элемента со значением 17 слева от предыдущего искомого элемента со значением 44.
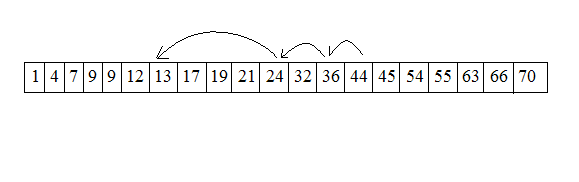 Рисунок
4 – Двоичный следящий поиск значения
17из значения 44
Рисунок
4 – Двоичный следящий поиск значения
17из значения 44
Поиск справа аналогичен поиску слева. Возьмите значения min и max от предыдущего поиска. Затем установите min = max и max = max + 1, min = max и max = max + 2, min = тахи max = max + 4 и т.д, пока не достигнете точки, где list^[max] будет больше искомого элемента. Еще раз проверьте, что программа не вышла за пределы массива.
По завершении фазы отслеживания уже известно, что индекс искомого элемента находится между min и max. После этого можно использовать обычный двоичный поиск для нахождения точной позиции элемента. Если новый элемент расположен близко к старому, алгоритм следящего поиска быстро отыщет правильные значения для min и max. Если индексы нового и старого элементов отличаются на Р, поиск займет приблизительно log(P) шагов.
Предположим, что вы начали двоичный поиск без фазы отслеживания. Чтобы сузить диапазон поиска до момента, где min и max будут в пределах Р позиций друг отдруга, потребуется приблизительно log (Numltems) - log(P) шагов. Это означает, что отслеживание и поиск будут быстрее, чем обычный двоичный поиск, если log (Р) < log (NumItems) - log (P). Добавляя log(P) к обеим частям этого уравнения, получим 2 * log(P) < log (Numltems). Если обе части уравнения возвести в степень, получим22 * log(P) < 2 1og (Numltems) или (21од(Р) ) 2 < Numltems. После упрощения результат будет следующим: Р2 < Numltems.
Из этого соотношения видно, что следящий поиск будет выполняться быстрее, если расстояние между двумя последовательно отыскиваемыми элементами меньше квадратного корня из числа элементов в списке. Если следующие друг за другом искомые элементы будут расположены далеко друг от друга, то лучше использовать обычный двоичный поиск.