

курсовая работа / роман / рома-pentium2я часть
.docПроцессор Intel Pentium 4
Уважаемый Покупатель!!!
Компания Intel выражает благодарность за Ваш выбор и гарантирует высокое качество, и безупречное функционирование приобретенного Вами изделия при соблюдении правил его эксплуатации. Мы уверены, что впредь Вы будете отдавать предпочтение нашей продукции.
Введение
Прочтите, пожалуйста, данную инструкцию внимательно, для того, чтобы не допустить поломки процессора или неправильного его использования. Сохраните ее для дальнейшего использования. Инструкция пользователя содержит важную информацию по использованию данного изделия. Использование процессора способом, не описанным в данной инструкции может привести к неисправности, которая не будет устраняться в порядке гарантийного ремонта.
Архитектура процессора Intel Pentium 4
Отличительной особенностью процессоров семейства Intel Pentium 4 является их беспримерно длинный конвейер (Hyper-Pipelined Technology). Так, первоначально (в процессорах на ядре с кодовым названием Northwood) длина конвейера составляла 20 ступеней. Впоследствии (в процессорах на ядре с кодовым названием Prescott) она увеличена до 31 ступени.
Архитектура, заложенная в процессоре Intel Pentium 4, получила название Intel NetBurst. Структурная схема процессора изображена на рисунке 1.
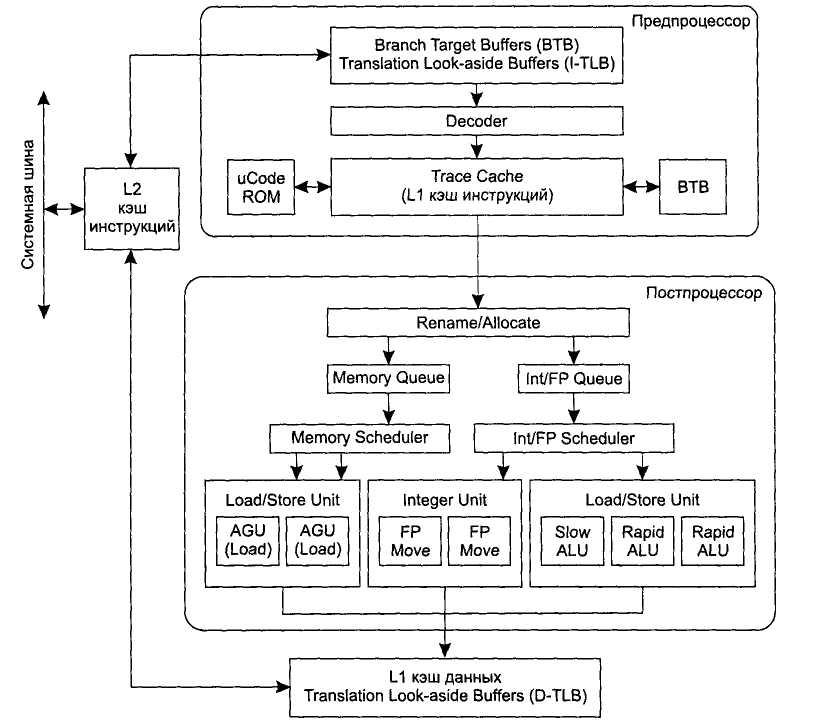
Рисунок 1. Структурная схема процессора Intel Pentium 4
Сравнивая схему классического процессора со схемой процессора Intel Pentium 4, можно заметить несколько конструктивных различий. Прежде всего, инструкции поступают в предпроцессор из кэша L2, а не из кэша L1, как в классической схеме.
Кэш второго уровня L2 процессоров семейства Pentium 4 получил название Advanced Transfer Cache. Имеющий 256-битную шину, работающую на частоте ядра, и усовершенствованную схему передачи данных, этот кэш обеспечивает высочайшую пропускную способность, столь важную для потоковых процессов обработки.
Кроме того, в схеме предпроцессора появился новый элемент — кэш L1 декодированных микроинструкций с отслеживанием исполнения (Trace Cache). Наличие такого кэша — одна из составляющих архитектуры NetBurst. (Кэш L1 данных размеров (8 Кбайт) также присутствует в процессоре, но разнесен с кэшем L1 инструкций).
При работе процессора инструкции выбираются из кэша L2, транслируются в команды х86 и декодируются. При этом с учетом того, что конвейер имеет много ступеней и должен быть достаточно быстрым, при декодировании инструкции разбиваются на более мелкие микрокоманды, которые затем поступают в Trace Cache. Для выборки команд из кэша L2, их транслирования в команды х86 и последующего декодирования отводится несколько начальных ступеней конвейера (восемь ступеней). Соответственно, при выполнении фрагмента программного кода для декодирования команд будет использовано восемь процессорных тактов. Однако во многих современных (прежде всего, мультимедийных) приложениях один и тот же фрагмент кода может повторяться многократно. В этом случае тратить процессорные такты на повторную выборку, транслирование и декодирование было бы нерационально. Выгоднее хранить уже готовые к исполнению микроинструкции в специальном кэше L1, где из них формируются мини-программы, называемые отслеживаниями (traces). При попадании в кэш L1 происходит внеочередное выполнение команд; при этом значительно экономятся ресурсы процессора, так как по своей сути внеочередное выполнение команд подразумевает устранение восьми первых ступеней конвейера, фактическая длина которого в этом случае составляет уже 20 ступеней. В кэше с отслеживанием может храниться до 12 000 декодированных микрокоманд (при этом заметим, что в процессоре Intel Pentium 4 процент попадания в кэш составляет более 90%).
Если рассмотреть работу процессора Intel Pentium 4 при внеочередном выполнении команд, то есть когда происходит попадание в Trace Cache и используются уже декодированные команды, то схема работы процессора Intel Pentium 4 будет подобна схеме работы классического процессора. Режим работы процессора при внеочередном выполнении команд является естественным для процессора Intel Pentium 4, поэтому, когда мы говорим о длине конвейера в 20 ступеней, мы имеем в виду длину основного конвейера без учета восьми первых ступеней, которые используются при необходимости выборки команд, их трансляции, декодирования и сохранения в Trace Cache полученных микрокоманд. Общая же длина конвейера составляет 28 ступеней).
Для того чтобы обеспечить высокий процент попаданий в кэш L1 с отслеживаниями (Trace Cache) и построение в нем мини-программ, используется специальный блок предсказания ветвлений (Branch Targets Buffers, BTB и Instruction Translation Look-aside Buffers, I-TLB). Этот блок предсказания позволяет модифицировать мини-программы, основываясь на спекулятивном предсказании. Так, если в программном коде имеется точка ветвления, то блок предсказаний может предположить дальнейший ход программы вдоль одной из возможных ветвей и с учетом этого спекулятивного предсказания построить мини-программу. Кроме того, с кэшем L1 связан также буфер ветвлений (ВТВ) размером 4 Кбайт.
Кэш микроинструкций с отслеживаниями имеет еще одну особенность. Дело в том, что большинство команд х86 при декодировании преобразуются в две-три микроинструкции. Однако встречаются и такие команды, для декодирования которых потребовались бы десятки и даже сотни микрокоманд. Естественно, что сохранять такие декодированные команды в кэше L1 было бы нерационально. Для этих целей используется специальная ROM-память (uCode ROM), а в самом кэше L1 сохраняется лишь метка на область ROM-памяти, где хранятся соответствующие микрокоманды. При попадании на такую метку управление потоком инструкций передается ROM-памяти.
Теперь рассмотрим процесс продвижения микроинструкций по основному конвейеру, то есть когда процессор работает в режиме внеочередного выполнения инструкций. В течение первых двух тактов в Trace Cache передается указатель на следующие выполняемые инструкции — это первые две ступени конвейера, называемые Trace Cache next instruction pointer. После получения указателя в течение двух тактов происходит выборка инструкций из кэша (Trace Cache Fetch) — это две следующие ступени конвейера. После этого выбранные инструкции должны быть отосланы на внеочередное выполнение. Для того чтобы обеспечить продвижение выбранных инструкций по процессору, то есть доставить их из предпроцессора в постпроцессор, используется еще одна дополнительная, или передаточная, ступень конвейера, называемая Drive. На этой ступени не происходит обработки инструкции. Фактически такая «пустая» ступень конвейера представляет собой временную задержку и вводится для компенсации высоких тактовых частот.
На следующих трех ступенях конвейера, называемых Allocate & Rename, происходит переименование и распределение дополнительных регистров процессора. В процессоре Intel Pentium 4 содержится 128 дополнительных регистров, которые не определены архитектурой набора команд. Переименование регистров позволяет добиться их бесконфликтного существования.
На 9-й ступени конвейера формируются две очереди микрокоманд: очередь микрокоманд памяти (Mem Queue) и очередь арифметических микрокоманд (Int/ FP Queue).
На следующих трех ступенях конвейера происходит планирование и распределение (Schedule) микрокоманд. Планировщик выполняет две основные функции: переупорядочивание микрокоманд и распределение их по функциональным устройствам. Суть переупорядочивания микрокоманд заключается в том, что планировщик (Scheduler) определяет, какую из микрокоманд уже можно выполнять, и в соответствии с их готовностью меняет порядок их следования. Распределение микрокоманд происходит по четырем функциональным устройствам, то есть формируются четыре очереди. Первые две из них предназначены для устройств памяти (Load/Store Unit). Эти очереди формируются из очереди памяти MemQueue. Микрокоманды из очереди арифметических микрокоманд (Int/FP Queue) также распределяются в очереди соответствующих функциональных устройств. Для этого предназначено три распределителя:
□ Fast ALU Scheduler — распределитель простых целочисленных операций.
Он собирает простейшие микроинструкции для работы с целыми числами, чтобы затем послать их на исполнительный блок ALU, работающий на двойной скорости. В процессоре Pentium 4 имеется два исполнительных блока ALU, работающих на удвоенной скорости. К примеру, если тактовая частота процессора составляет 3,8 ГГц, то эти два устройства ALU работают с частотой 7,6 ГГц и в параллельном режиме способны выполнять четыре целочисленные операции за один такт. Эти два блока ALU получили название Rapid Execution Engine (блоки быстрого исполнения).
□ Slow ALU/General FPU Scheduler — распределитель целочисленных операций/распределитель операций с плавающей точкой. Это устройство распределяет остальные операции ALU и операции с плавающей точкой.
□ Simple FP Scheduler — распределитель простых операций с плавающей точкой. Это устройство формирует очередь простых операций с плавающей точкой и операций по доступу к памяти с плавающей точкой.
Следующие две ступени конвейера — этап диспетчеризации (Dispatch). На этих ступенях инструкции попадают на один из четырех портов диспетчеризации (dispatch ports), которые выполняют функцию шлюзов к функциональным устройствам.
После того как инструкции пройдут порты диспетчеризации, они загружаются в блок регистров для дальнейшего выполнения Для этого предназначены следующие две ступени процессора, называемые Register Files.
Таким образом, после загрузки инструкций в блок регистров все готово для непосредственного выполнения команд Процесс непосредственного выполнения инструкций в исполнительных устройствах происходит на следующей, семнадцатой, ступени конвейера, которая называется Execute.
Следующие три ступени конвейера: ступень изменения состоянии флагов (Flags) — если результат выполнения инструкции этого требует; ступень проверки ветвления (Branch Check), на которой процессор узнает, сбылось ли предсказание ветвления. Последняя ступень процессора — еще одна передаточная ступень Drive, назначение которой мы уже рассматривали.
Как мы уже отмечали, в процессорах на ядре Prescott длина конвейера была увеличена с 20 до 31 ступени. Причина увеличения длины конвейера заключается в том, что поскольку многие команды являются довольно сложными и не могут быть выполнены за один такт процессора, особенно при высоких тактовых частотах, то каждая из четырех стадий обработки команд (выборка, декодирование, выполнение, запись) должна состоять из нескольких ступеней конвейера. Кроме того, в конвейер преднамеренно вставляются так называемые пустые ступени (Drive), на которых не происходит обработка инструкции.
Эти пустые (или передаточные) ступени необходимы для того, чтобы при высоких тактовых частотах сигнал успевал во время одного такта распространиться от одного исполнительного блока к другому. Напомним, что при частотах свыше 3 ГГц время одного такта составляет менее 3 не. За столь короткий промежуток времени свет в вакууме успевает пройти расстояние менее 1 см, а поскольку скорость распространения сигналов в кристалле существенно ниже скорости света, то при высоких тактовых частотах неизбежно приходится вводить пустые ступени конвейера для передачи сигнала.
Характеристики процессоров
Когда заходит речь о процессоре, то в качестве его основных характеристик, указывают тактовую частоту, микроархитектуру ядра и количество ядер, технологический процесс производства, частоту системной шины, размер кэша, тепловыделение процессора и поддерживаемые технологии. Все эти характеристики так или иначе определяют самую главную характеристику любого процессора - его производительность.
Тактовая частота
До недавнего времени тактовая частота процессора напрямую связывалась с его производительностью, то есть чем выше тактовая частота процессора, тем он более производительнее. Собственно, сама микроархитектура NetBurst, положенная в основу процессоров Intel Pentium 4, изначально была ориентирована на то, что основным средством увеличения производительности процессоров будет рост тактовой частоты. Действительно, за пять лет существования процессоров Intel Pentium 4 их тактовая частота была увеличена почти в три раза. Стартовав с отметки чуть больше 1 ГГц, за пять лет тактовая частота достигла значения 3,8 ГГц. Конечно, увеличение тактовой частоты — это далеко не единственное нововведение, которое сопутствовало появлению новых процессоров семейства Intel Pentium 4. В то же время можно сказать, что для процессора Intel Pentium 4 повышение тактовой частоты являлось одним из основных способов (причем довольно эффективным) увеличения его производительности. Зависимость между тактовой частотой процессора и его производительностью достаточно простая. Производительность процессора принято отождествлять со скоростью выполнения им инструкций программного кода; таким образом, производительность -это количество инструкций, выполняемых процессором в единицу времени:
![]()
Переписав это выражение в виде произведения количества инструкций, выполняемых за один такт процессора (Instruction Per Clock, IPC), на количество тактов процессора за единицу времени (тактовая частота процессора):
![]()
получаем, что производительность процессора прямо пропорциональна его тактовой частоте.
Микроархитектура процессора
Из приведенной формулы вытекает, что кроме тактовой частоты производительность процессора зависит и от количества инструкций, выполняемых за один такт процессора, которое, в свою очередь, определяется микроархитектурой процессора, то есть от количества исполняемых блоков, от длины конвейера и от эффективности его заполнения, от блока предвыборки и т. д. Кроме того, естественно, существует также зависимость от оптимизации программного кода к данной микроархитектуре процессора.
Технологический процесс производства
Казалось бы, технологический процесс производства никак не отражается на производительности процессора. Действительно, прямой зависимости между проектной нормой процессора и его производительностью нет, однако от технологии производства процессоров, определяющей минимальные размеры используемых транзисторов, их быстродействие и время задержки передачи сигнала в межуровневых соединениях, зависит и его тактовая частота и размер кэша. Увеличение тактовой частоты просто невозможно без изменения технологического процесса производства процессора. То есть в пределах одного семейства процессоров, определяемого технологическим процессом производства, потенциальный запас по наращиванию тактовой частоты ограничен, и дальнейшее увеличение тактовой частоты возможно только при уменьшении проектной нормы производства процессоров.
Частота системной шины
Частота системной шины определяет пропускную способность шины, связывающей процессор с чипсетом. Естественно, что чем выше частота системной шины, тем выше и производительность процессора. Если говорить о процессорах Intel, то частоту системной шины называют частотой FSB. К примеру, если частота FSB составляет 800 МГц, то ее пропускная способность (с учетом 64-битной или 8-байтной ширины шины) составляет 6,4 Гбайт/с. Для шины FSB с частотой 1066 МГц пропускная способность составит уже 8,5 Гбайт/с. Для процессоров Intel частота FSB может быть равной 400, 533, 800 и 1066 МГц.
Размер кэша
Как уже отмечалось, современный процессор имеет несколько типов кэша, интегрированных на кристалл процессора: кэш первого уровня L1 и кэш второго уровня L2. Кэш L1, который делится на кэш команд и кэш данных, используется непосредственно ядром процессора. Кэш L2 представляет собой своеобразный буфер между оперативной памятью и кэшем L1. В пределах одного семейства процессоры могут отличаться размером кэша L2. Непосредственного влияния размер кэша не оказывает на производительность процессора, однако при недостаточном размере кэша увеличивается время простоя процессора, в течение которого в кэш загружаются данные из оперативной памяти. Это, в свою очередь, отражается и на производительности процессора. Поэтому чем больше размер кэша L2, тем лучше.
Технологии, поддерживаемые процессорами
Технология Intel Hyper-Threading
Как уже отмечалось, кроме увеличения тактовой частоты существуют и другие способы увеличения производительности процессора, связанные с изменением его архитектуры. К примеру, можно увеличить число исполнительных блоков (Execution Units) внутри самого процессора. В этом случае возможно параллельное выполнение нескольких процессорных инструкций одновременно. Такая многозадачность реализована в том или ином виде во всех современных процессорах. Отход от последовательного выполнения команд, использование нескольких исполняющих блоков в одном процессоре позволяют одновременно обрабатывать несколько процессорных микрокоманд, то есть организовывать параллелизм на уровне инструкций (Instruction Level Parallelism, ILP), что, естественно, увеличивает общую производительность.
Поясним все вышесказанное на примере. Представьте себе гипотетический процессор, в котором имеется всего три исполнительных блока: блок для работы с целыми числами (арифметико-логическое устройство, ALU), блок для работы с числами с плавающей точкой (FPU) и блок для записи и чтения данных из памяти (Store/Load, S/L). Пусть, кроме того, каждая операция осуществляется за один такт процессора.

Рисунок 2. Последовательное выполнение инструкций в гипотетическом процессоре
Предположим, что выполняется программа, состоящая из трех инструкций: первые две — арифметические действия с целыми числами, а последняя — сохранение результата. В этом случае вся программа будет выполнена за три такта процессора. В первом такте задействуется блок ALU процессора (темный квадрат на рисунке 2), во втором — также блок ALU, а в третьем — блок записи и чтения данных из памяти S/L. В этом случае мы имеем дело с классическим последовательным вариантом выполнения программы.
В современных приложениях в любой момент времени, как правило, выполняется не одна, а несколько задач или несколько потоков (threads) одной задачи, называемых также нитями. Давайте посмотрим, как будет вести себя наш гипотетический процессор при выполнении двух разных потоков задач (рисунок 3).
Допустим, что первый поток включает две независимые инструкции с использованием блока ALU и одну инструкцию по сохранению результата. Задача второго потока — загрузить необходимые данные из памяти (работа с блоком S/L), произвести операцию с действительными числами (числами с плавающей запятой) при помощи блока FPU и сохранить результат с использованием блока S/L. Если бы оба потока исполнялись изолированно, то для выполнения первого потребовалось бы два такта процессора, а для второго — три. При одновременном исполнении обоих потоков процессор будет постоянно переключаться между обоими потоками так, что за один такт процессора выполняются только инструкции какого-либо одного из потоков. Для исполнения обоих потоков всего потребуется пять процессорных тактов.
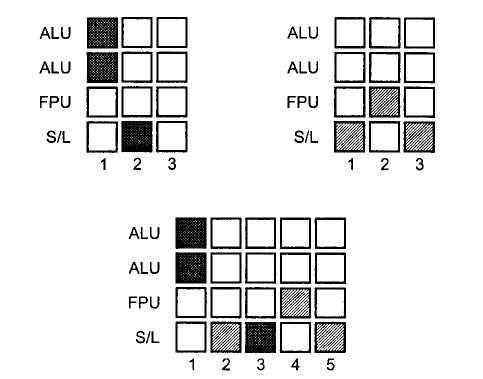
Рисунок 3. Выполнение двух потоков на процессоре без Hyper-Threading
Теперь давайте подумаем над тем, как можно повысить скорость выполнения задачи в рассмотренном примере. Для этого нужно по возможности не только выполнять параллельно независимые инструкции одного потока, но и совместить выполнение инструкций различных потоков. В нашем примере выполнение двух арифметических операций с целыми числами первого потока молено совместить с загрузкой данных из памяти второго потока и выполнить все три операции за один такт процессора. Аналогично на втором такте процессора можно совместить операцию сохранения результатов первого потока с операцией с действительными числами (с плавающей запятой) второго потока (рисунок 2).
Собственно, в таком параллельном выполнении двух потоков и заключается основная идея технологии Hyper-Threading, которая реализована в современных процессорах Intel. Итак, технология Hyper Threading — это реализация одновременной многопоточности (Simultaneous Multi-Threading, SMT). Технология Hyper-Threading является промежуточной между многопоточной обработкой, осуществляемой в мультипроцессорных системах, и параллелизмом на уровне инструкций, реализованном в однопроцессорных системах.
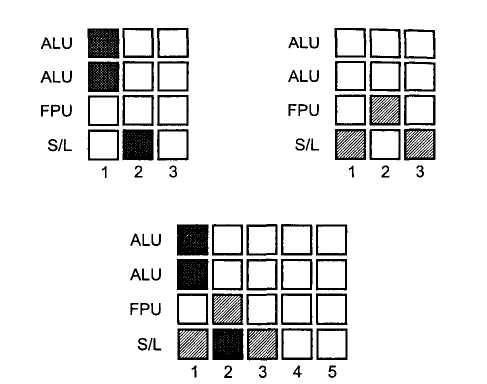
Рисунок 4. Параллельное выполнение двух потоков на процессоре с реализацией технологии Hyper-Threading
Конечно, ждать двукратного увеличения производительности процессора от использования технологии Hyper-Threading не приходится, и па практике выигрыш куда более скромен.
Дело в том, что возможность одновременного выполнения на одном такте процессора инструкций от разных потоков ограничивается тем, что эти инструкции могут задействовать одни и те же исполнительные блоки процессора.
Для реализации технологии Hyper-Threading процессор должен иметь два «входа» для отдельных потоков, как если бы существовало два физических процессора, но при этом всего один конвейер обработки команд, как в реальном физическом процессоре, который использует оба потока. В этом случае один физический процессор представляется операционной системе как два логических.
С конструктивной точки зрения процессор с поддержкой технологии Hyper-Threading состоит из двух логических процессоров, каждый из которых имеет свои регистры и контроллер прерываний (Architectural State, AS), то есть две параллельно исполняемые задачи работают со своими собственными независимыми регистрами и прерываниями, но при этом используют одни и те же ресурсы процессора для выполнения задач. Таким образом, от реальной двухпроцессорной конфигурации технология Hyper-Threading отличается только тем, что оба логических процессора используют одни и те же исполняющие ресурсы, одну и ту же разделяемую между двумя потоками кэш-память и одну системную шину.
Технологии тепловой защиты
Как уже отмечалось, современные процессоры рассеивают такую тепловую мощность, что для ее эффективного отвода требуется использовать очень мощные кулеры. Однако даже мощные кулеры не гарантируют, что в периоды 100% загрузки процессора локальная температура процессора не превысит допустимых значений. Поэтому все современные процессоры (и Intel, и AMD) имеют встроенные средства тепловой защиты. Наиболее сложный механизм, предотвращающий перегрев, используется в процессорах Intel. Именно с рассмотрения этих механизмов мы и начнем. Итак, в современных процессорах компании Intel (включая новейшие двухъядерные процессоры Intel Pentium D) используется три типа тепловой защиты: технологии Thermal Monitor, Thermal Monitor 2 и режим аварийного отключения.
Технология Thermal Monitor
Технология Thermal Monitor реализована следующим образом: при нагревании процессора до некоторой критической температуры генерируется специальный сигнал, в результате чего активируется режим тепловой защиты процессора, при котором он остывает. При достижении нормальной температуры процессор возвращается к нормальному режиму работы. Естественно, что в режиме активации тепловой защиты процессор работает не на полную мощность, то есть остывание процессора происходит за счет потери производительности.
Рассмотрим данную технологию более подробно. Для контроля температуры во всех современных процессорах Intel встроены два термодатчика (термодиода), один из которых сообщает системе аппаратного мониторинга материнской платы температуру ядра процессора, а еще один является частью схемы Thermal Monitor и расположен в самой «горячей» точке ядра процессора — возле блоков ALU.
При достижении некоторого критического значения температуры (по состоянию термодатчика, расположенного возле блоков ALU) генерируется специальный сигнал PROCHOT#, который активирует специальный модуль Thermal Control Unit. Температура, при которой «выставляется» сигнал PROCHOT#, индивидуально калибруется для каждого процессора в процессе производства исходя из величины рассеиваемой им мощности. Однажды заданное значение температуры для сигнала PROCHOT# уже не может быть изменено.
Задача модуля Thermal Control Unit заключается в том, чтобы модулировать номинальную тактовую частоту процессора. Смысл модуляции заключается в том, что в период действия сигнала PROCHOT* на номинальный сигнал тактовой частоты процессора накладывается еще один служебный сигнал, частота которого существенно ниже тактовой частоты процессора. В результате частота, которая подается на вычислительные блоки процессора, является прореженной, и можно говорить о том, что ядро процессора работает на пониженной частоте. Важно отметить, что технология Thermal Monitor никак не влияет на частоту тактирования процессора, а лишь модулирует частоту тактирования вычислительных блоков процессора.
В результате образования «холостых» тактов процессор будет иметь меньшую производительность и меньшее тепловыделение, а температура процессора начнет уменьшаться. С понижением температуры ядра количество холостых циклов начнет уменьшаться, и как только температура ядра процессора снизится ниже порогового значения примерно на 1°С, сигнал PROCHOT# исчезнет, а номинальная частота процессора совпадет с эффективной.
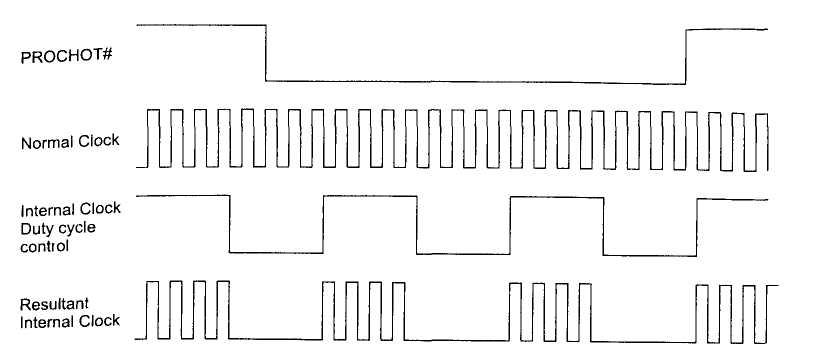
Рисунок 5. Модуляция частоты в технологии Thermal Monitor
Важно отметить, что сигнал PROCHOT может быть «выставлен» при достижении критической температуры не только процессором, но и системами тепловой защиты других компонентов, например модуля регулировки напряжения (Voltage Regulation, VR) или модулей памяти.
Технология Thermal Monitor 2
В новых процессорах компании Intel к технологии Thermal Monitor добавился еще один инструмент теплового контроля — технология Thermal Monitor 2, которая позволяет в еще большей степени влиять на энергопотребление процессора при достижении им критической температуры.
При использовании технологии Thermal Monitor 2, когда рабочая температура процессора достигает критического значения, активируется служебный сигнал PROCHOT#, в результате чего происходит снижение тактовой частоты процессора и напряжение питания (VID). Это, в свою очередь, приводит к снижению потребляемой процессором мощности, а следовательно, и к снижению его рабочей температуры. Снижение тактовой частоты процессора происходит за счет уменьшения коэффициента внутреннего умножения до минимального значения. Технология Thermal Monitor 2 во многом напоминает технологию Enhanced Intel SpeedStep с той лишь разницей, что в технологии Enhanced Intel SpeedStep переход на меньшую тактовую частоту и напряжение питания осуществляется в период слабой активности процессора, а в технологии Thermal Monitor 2 — при достижении критической температуры. Кроме того, если в технологии Enhanced Intel SpeedStep определяются несколько возможных рабочих точек (несколько возможных тактовых частот и напряжений), то в технологии Thermal Monitor 2 определены только две рабочие точки, соответствующие максимальной и минимальной частотам процессора.