

37 Функция конкурентного сходства. Измерение компактности на основание конкурентного сходства.
Кратко напомним, что мы называем функцией конкурентного сходства, и какие предпосылки определяют её эффективность при решении задач анализа данных.
Человек является самой совершенной из ныне существующих распознающих систем. Если мы хотим, чтобы наши алгоритмы хорошо имитировали человеческие способности решать задачи распознавания, то мы должны использовать ту же меру сходства, которую использует человек. Человек считает сходство категорией не абсолютной, а относительной, и оценивает меру сходства в зависимости от конкурентной ситуации. Для ответа на вопрос «На сколько сильно объект а похож на объект b?», нужно знать ответ на вопрос «По сравнению с чем?»
Для измерения в шкале отношений меры сходства объекта z с конкурирующими объектами а и bпредлагается пользоваться следующими соотношениями:
Fa/b=(rb-ra)/(ra+rb) для сходства Z с объектом а
и Fb/a=(ra-rb)/(ra+rb) для сходства Z с объектом b.
Здесь ra и rb – расстояния от z до a и b, соответственно. Функцию F мы и называем функцией
конкурентного сходства или FRiS-функцией (от слов Function of Rival Similarity). Fa/b принимает значение
+1, если z и a неразличимы, -1, если z совпадает с b, и 0, если объект z равноудален от объектов a и b.
Задача естественной классификации и алгоритм NatClass
Особенности «естественных» классификаций:
Разбиение производится по небольшому числу «существенных» признаков.
Позволяет предсказывать неизвестные свойства объектов путем распространения единичных наблюдений на весь класс.
Часто представляет из себя не просто разбиение множества объектов на классы, а некую иерархическую структуру.
На каждом уровне иерархии используется свое, наиболее информативное подпространство признаков.
Алгоритм NatClass
Пространство существенных признаков Xb, Q(Xb)=Qr+Qt
Разделяющая способность Qt - через качество таксономии в Xb
Прогностическая способность Qr
Для каждого таксона вычисляется квадрат отклонения реального значения признака от спрогнозированного
![]()
![]()
, где
Эффективность таксономии для прогнозирования i-го признака:
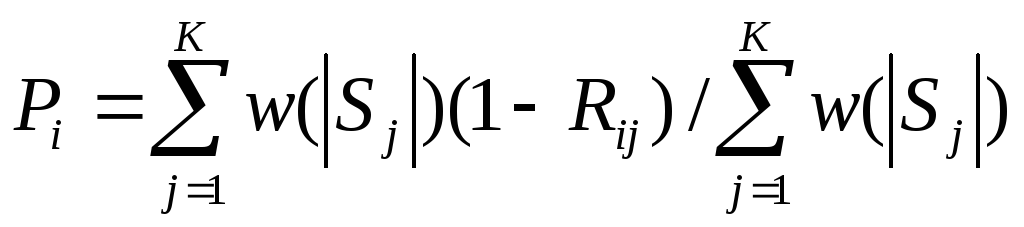
где К –число таксонов в таксономии, w(x) – монотонно возрастающая весовая функция.
![]()
Выбор наиболее информативной системы признаков может осуществляется посредством алгоритма AdDel.
Алгоритм ZET. Его модификации
Алгоритм ZET
Выявление компетентной подматрицы
Восстановление параметров зависимостей
Прогнозирование
Алгоритм WANGA для разнотипных признаков
Алгоритм ZET
Компетентность Lij=(1-rij)*tij
rij- расстояние между строками (столбцами)
tij – заполненность строк (столбцов)
Прогнозы по компетентным строкам и столбцам
строятся прогнозы по всем компетентным строкам и столбцам (линейная регрессия)
усредняются, с учетом Lij
Влияние компетентности оценивается на известных данных
На них же оценивается ожидаемая погрешность прогноза и дисперсия погрешности
Прогнозы по строкам и столбцам усредняются
Модификации ZET
Обнаружение грубых ошибок и выбросов в данных
Прогнозирование динамических процессов
В работе алгоритма ZET можно выделить три этапа.
1. На первом этапе для данного пробела из исходной матрицы «объект-свойство», столбцы которой нормированы по дисперсии, выбирается подмножество компетентных строк и затем для этих строк — компетентных столбцов.
2. На втором этапе автоматически подбираются параметры в формуле, используемой для предсказания пропущенного элемента, при которых ожидаемая ошибка предсказания достигает минимума.
3. На третьем этапе выполняется непосредственно прогнозирование элемента по этой формуле.
Под
компетентностью
![]() -й
строки по отношению к
-й
строки по отношению к
![]() -й
понимается величина
-й
понимается величина
![]()
Здесь
![]() ,
,
![]() —
евклидово расстояние между
—
евклидово расстояние между
![]() -й
и
-й
и
![]() -й
строками, a
-й
строками, a
![]() —
коэффициент комплектности, равный числу
свойств, значения которых известны как
для
—
коэффициент комплектности, равный числу
свойств, значения которых известны как
для
![]() -й,
так и для
-й,
так и для
![]() -й
строки. Компетентная строка не должна
иметь пробела в
-й
строки. Компетентная строка не должна
иметь пробела в
![]() -м
столбце.
-м
столбце.
Под
компетентностью
![]() -го
столбца по отношению к
-го
столбца по отношению к
![]() -му
столбцу понимается величина
-му
столбцу понимается величина
![]()
где
![]() —
модуль коэффициента корреляции между
—
модуль коэффициента корреляции между
![]() -м
и
-м
и
![]() -м
столбцами, a
-м
столбцами, a
![]() —
коэффициент комплектности, равный числу
объектов, у которых известны как
—
коэффициент комплектности, равный числу
объектов, у которых известны как
![]() -e,
так и
-e,
так и
![]() -е
свойства. Компетентный столбец не должен
иметь пробела в
-е
свойства. Компетентный столбец не должен
иметь пробела в
![]() -й
строке.
-й
строке.
По
указанию пользователя программа выбирает
компетентную подматрицу любого размера
в пределах от 2х2 до
![]() .
Обычно используется подматрица,
содержащая от 3 до 7 строк и столбцов.
.
Обычно используется подматрица,
содержащая от 3 до 7 строк и столбцов.
В
процессе предсказания значения пробела
с использованием зависимостей между
![]() -м
и всеми остальными (
-м
и всеми остальными (![]() -ми)
столбцами вырабатываются «подсказки»
-ми)
столбцами вырабатываются «подсказки»
![]() .
Для их получения используется уравнение
линейной регрессии между
.
Для их получения используется уравнение
линейной регрессии между
![]() -м
и
-м
и
![]() -м
столбцами (см. рис. 25). Если в подматрице
было
-м
столбцами (см. рис. 25). Если в подматрице
было
![]() столбцов,
то затем
столбцов,
то затем
![]() подсказок
усредняются с весом, пропорциональным
компетентности соответствующего
столбца. В итоге получается прогнозная
величина
подсказок
усредняются с весом, пропорциональным
компетентности соответствующего
столбца. В итоге получается прогнозная
величина
![]() ,
порожденная избыточностью, содержащейся
в столбцах:
,
порожденная избыточностью, содержащейся
в столбцах:
 (1)
(1)
Здесь
![]() —
коэффициент, регулирующий влияние
компетентности на результат предсказания.
При малых значениях
—
коэффициент, регулирующий влияние
компетентности на результат предсказания.
При малых значениях
![]() разница
в компетентности сказывается мало, при
больших
разница
в компетентности сказывается мало, при
больших
![]() более
компетентные столбцы влияют гораздо
больше других. Выбор
более
компетентные столбцы влияют гораздо
больше других. Выбор
![]() и
составляет суть этапа подбора формулы
для прогнозирования: все известные
элементы
и
составляет суть этапа подбора формулы
для прогнозирования: все известные
элементы
![]() -гo
столбца предсказываются при разных
значениях
-гo
столбца предсказываются при разных
значениях
![]() и
затем выбирается такое значение
и
затем выбирается такое значение
![]() ,
при котором ошибка прогноза
,
при котором ошибка прогноза
![]() была
минимальной.
была
минимальной.
Для различных прикладных задач были сделаны многочисленные модификации описанного выше базового алгоритма ZET, отличающиеся своим назначением и наборами разных режимов работы. Программы заполнения пробелов могут работать в одном из следующих режимов:
1. Заполнение всех пробелов.
2. Заполнение только тех пробелов, ожидаемая ошибка для которых не превышает заданной величины.
3. Заполнение пробелов только на базе информации, имеющейся в исходной таблице.
4. Заполнение каждого следующего пробела с использованием исходной информации и прогнозных значений ранее заполненных пробелов.
Для каждого из этих вариантов имеется несколько режимов выдачи промежуточных и окончательных результатов на печать.
Алгоритм k-means.
k-means (иногда называемый k-средних) - наиболее популярный метод кластеризации. Был изобретён в 1950-х математиком Г. Штейнгаузом[1] и почти одновременно С. Ллойдом[2]. Особую популярность приобрёл после работы МакКвина[3].
Действие алгоритма таково, что он стремится минимизировать суммарное квадратичное уклонение точек кластеров от центров этих кластеров:

где k -
число кластеров, Si - полученные
кластеры, ![]() и μi -
центры масс векторов
и μi -
центры масс векторов ![]() .
.
Алгоритм
Алгоритм представляет собой версию EM-алгоритма, применяемого также для разделения смеси гауссиан. Он разбивает множество элементов векторного пространства на заранее известное число кластеров k.
Основная идея заключается в том, что на каждой итерации перевычисляется центр масс для каждого кластера, полученного на предыдущем шаге, затем векторы разбиваются на кластеры вновь в соответствии с тем, какой из новых центров оказался ближе по выбраной метрике.
Алгоритм завершается, когда на какой-то итерации не происходит изменения кластеров. Это происходит за конечное число итераций, так как количество возможных разбиений конечного множество конечно, а на каждом шаге суммарное квадратичное уклонение V уменьшается, поэтому зацикливание невозможно.
Проблемы k-means
Не гарантируется достижение глобального минимума суммарного квадратичного уклонения V, а только одного из локальных минимумов.
Результат зависит от выбора исходных центров кластеров, их оптимальный выбор неизвестен.
Число кластеров надо знать заранее.
Алгоритм KRAB
Кратчайший незамкнутый путь
Мера близости объектов внутри таксона
Расстояние между таксонами
Мера локальной неоднородности
i= / min =
Однородность таксонов
h .

EM-алгоритм
A={x1,x2,…xm}
Восстановление смеси распределений:
(x) =w1ϕ(x, θ1 )+…+wkϕ(x, θk ), k < m.
Вводится дополнительный вектор переменных zij=p(θk |xi).
Е-Шаг
zij= wjϕ(xi, θj )/(x)
М-шаг
Максимизируется логарифм правдоподобия
ln((x1)*…* (xk))->max
θ1,…, θk
wj= (g1j+…+gmj) /m
θj=argmax{g1jln ϕ(x1, θ)+…+gmjln ϕ(xm, θ)}
θ
Останавливается при стабилизации параметров